Ottimizza in modo interattivo Falcon-40B e altri LLM su Amazon SageMaker Studio notebooks utilizzando QLoRA
Utilizza QLoRA per ottimizzare in modo interattivo Falcon-40B e altri LLM su Amazon SageMaker Studio notebooks.
La messa a punto dei modelli di linguaggio di grandi dimensioni (LLM) consente di regolare i modelli fondamentali open-source per ottenere prestazioni migliorate nelle vostre attività specifiche. In questo post, discutiamo dei vantaggi dell’utilizzo dei notebook di Amazon SageMaker per la messa a punto dei modelli open-source all’avanguardia. Utilizziamo la libreria di messa a punto efficiente dei parametri di Hugging Face (PEFT) e tecniche di quantizzazione attraverso bitsandbytes per supportare la messa a punto interattiva di modelli estremamente grandi utilizzando una singola istanza di notebook. In particolare, mostriamo come mettere a punto Falcon-40B utilizzando una singola istanza ml.g5.12xlarge (4 GPU A10G), ma la stessa strategia funziona anche per mettere a punto modelli ancora più grandi su istanze di notebook p4d/p4de.
Di solito, le rappresentazioni a piena precisione di questi modelli molto grandi non entrano in memoria su una singola o anche su diverse GPU. Per supportare un ambiente di notebook interattivo per la messa a punto e l’esecuzione di inferenze su modelli di questa dimensione, utilizziamo una nuova tecnica nota come Modelli di Linguaggio di Grandi Dimensioni Quantizzati con Adattatori di Basso Rango (QLoRA). QLoRA è un approccio efficiente alla messa a punto che riduce l’utilizzo della memoria dei LLM mantenendo alte prestazioni. Hugging Face e gli autori del paper menzionato hanno pubblicato un post dettagliato che copre i fondamenti e le integrazioni con le librerie Transformers e PEFT.
Utilizzo dei notebook per la messa a punto dei LLM
SageMaker offre due opzioni per avviare notebook completamente gestiti per esplorare i dati e costruire modelli di machine learning (ML). La prima opzione è il lancio rapido, notebook collaborativi accessibili all’interno di Amazon SageMaker Studio, un ambiente di sviluppo integrato (IDE) per ML. È possibile lanciare rapidamente notebook in SageMaker Studio, aumentare o diminuire le risorse di calcolo sottostanti senza interrompere il proprio lavoro e persino collaborare in tempo reale sulla modifica dei notebook. Oltre alla creazione dei notebook, è possibile eseguire tutte le fasi dello sviluppo di ML per costruire, addestrare, eseguire il debug, tracciare, distribuire e monitorare i propri modelli in una singola interfaccia grafica in SageMaker Studio. La seconda opzione è un’istanza di notebook di SageMaker, una singola istanza di calcolo ML completamente gestita che esegue notebook nel cloud, che offre un maggiore controllo sulle configurazioni dei propri notebook.
Per il resto di questo post, utilizziamo i notebook di SageMaker Studio perché vogliamo utilizzare il tracciamento degli esperimenti gestito di SageMaker Studio con il supporto di Hugging Face Transformer per TensorBoard. Tuttavia, gli stessi concetti mostrati nel codice di esempio funzioneranno anche sulle istanze di notebook utilizzando il kernel conda_pytorch_p310. Vale la pena notare che il volume Amazon Elastic File System (Amazon EFS) di SageMaker Studio significa che non è necessario prevedere una dimensione predefinita del volume Amazon Elastic Block Store (Amazon EBS), il che è utile dato le dimensioni dei pesi del modello nei LLM.
- Diffusione stabile Intuizione di base dietro l’IA generativa
- Costruzione di modelli linguistici Una guida passo-passo all’implementazione di BERT
- 5 Libri Gratuiti su Elaborazione del Linguaggio Naturale da Leggere nel 2023
L’utilizzo di notebook supportati da grandi istanze GPU consente di prototipare e risolvere rapidamente i problemi di debug senza avviare container a partire da zero. Tuttavia, significa anche che è necessario arrestare le istanze di notebook quando si ha finito di utilizzarle per evitare costi aggiuntivi. Altre opzioni come Amazon SageMaker JumpStart e i container SageMaker Hugging Face possono essere utilizzati per la messa a punto, e vi consigliamo di fare riferimento ai seguenti post sui metodi sopra citati per scegliere la migliore opzione per voi e il vostro team:
- Messa a punto di adattamento di dominio dei modelli fondamentali in Amazon SageMaker JumpStart con dati finanziari
- Allenare un grande modello di linguaggio su una singola GPU Amazon SageMaker con Hugging Face e LoRA
Prerequisiti
Se è la prima volta che si lavora con SageMaker Studio, è necessario creare un dominio di SageMaker. Utilizziamo anche un’istanza gestita di TensorBoard per il tracciamento degli esperimenti, anche se questo è opzionale per questo tutorial.
Inoltre, potrebbe essere necessario richiedere un aumento del limite di servizio per le applicazioni di Studio KernelGateway di SageMaker corrispondenti. Per la messa a punto di Falcon-40B, utilizziamo un’istanza ml.g5.12xlarge.
Per richiedere un aumento del limite di servizio, nella console delle quote di servizio AWS, passare a AWS services, Amazon SageMaker e selezionare Studio KernelGateway Apps running on ml.g5.12xlarge instances. 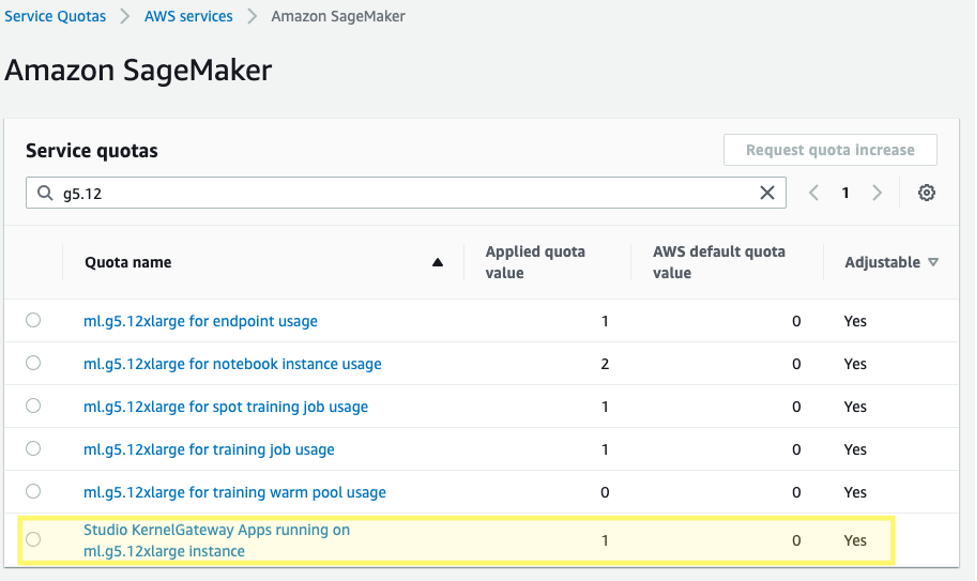
Iniziare
Il codice di esempio per questo post può essere trovato nel seguente repository GitHub. Per iniziare, scegliamo l’immagine Data Science 3.0 e il kernel Python 3 di SageMaker Studio in modo da avere un ambiente Python 3.10 recente per installare i nostri pacchetti.

Installiamo PyTorch e le librerie richieste Hugging Face e bitsandbytes:
%pip install -q -U torch==2.0.1 bitsandbytes==0.39.1
%pip install -q -U datasets py7zr einops tensorboardX
%pip install -q -U git+https://github.com/huggingface/transformers.git@850cf4af0ce281d2c3e7ebfc12e0bc24a9c40714
%pip install -q -U git+https://github.com/huggingface/peft.git@e2b8e3260d3eeb736edf21a2424e89fe3ecf429d
%pip install -q -U git+https://github.com/huggingface/accelerate.git@b76409ba05e6fa7dfc59d50eee1734672126fdbaSuccessivamente, impostiamo il percorso dell’ambiente CUDA utilizzando CUDA installato che era una dipendenza dell’installazione di PyTorch. Questo è un passaggio necessario affinché la libreria bitsandbytes possa trovare e caricare correttamente il binario condiviso CUDA corretto.
# Aggiungi l'esecuzione del runtime CUDA installato al percorso per bitsandbytes
import os
import nvidia
cuda_install_dir = '/'.join(nvidia.__file__.split('/')[:-1]) + '/cuda_runtime/lib/'
os.environ['LD_LIBRARY_PATH'] = cuda_install_dirCaricare il modello fondamentale pre-addestrato
Utilizziamo bitsandbytes per quantizzare il modello Falcon-40B in precisione a 4 bit in modo da poter caricare il modello in memoria su 4 GPU A10G utilizzando la parallelismo di pipeline ingenuo di Hugging Face Accelerate. Come descritto nel post di Hugging Face precedentemente menzionato, l’ottimizzazione QLoRA viene mostrata per corrispondere ai metodi di raffinamento a 16 bit in una vasta gamma di esperimenti perché i pesi del modello vengono memorizzati come NormalFloat a 4 bit, ma vengono dequantizzati al bfloat16 di calcolo in avanti e all’indietro se necessario.
model_id = "tiiuae/falcon-40b"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)Quando si caricano i pesi preaddestrati, specificare device_map="auto" in modo che Hugging Face Accelerate determini automaticamente su quale GPU posizionare ciascun layer del modello. Questo processo è conosciuto come parallelismo del modello.
# Falcon richiede di consentire l'esecuzione del codice remoto. Questo perché il modello utilizza un'architettura nuova che non fa parte di transformers ancora.
# Il codice è fornito dagli autori del modello nel repository.
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True, quantization_config=bnb_config, device_map="auto")Con la libreria PEFT di Hugging Face, è possibile congelare la maggior parte dei pesi del modello originale e sostituire o estendere i layer del modello addestrando un insieme aggiuntivo molto più piccolo di parametri. Ciò rende l’addestramento molto meno costoso in termini di calcolo richiesto. Impostiamo i moduli Falcon che vogliamo raffinare come target_modules nella configurazione LoRA:
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=[
"query_key_value",
"dense",
"dense_h_to_4h",
"dense_4h_to_h",
],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)
print_trainable_parameters(model)
# Output: trainable params: 55541760 || all params: 20974518272|| trainable%: 0.2648058910327664Si noti che stiamo raffinando solo lo 0,26% dei parametri del modello, il che rende questo fattibile in un tempo ragionevole.
Caricare un dataset
Utilizziamo il dataset samsum per il nostro raffinamento. Samsum è una raccolta di 16.000 conversazioni simili a messaggi con riassunti etichettati. Di seguito è riportato un esempio del dataset:
{
"id": "13818513",
"summary": "Amanda ha fatto dei biscotti e li porterà a Jerry domani.",
"dialogue": "Amanda: Ho fatto dei biscotti. Ne vuoi qualcuno?\r\nJerry: Certamente!\r\nAmanda: Te li porterò domani :-)"
}Nella pratica, vorrai utilizzare un dataset che abbia conoscenze specifiche per il compito su cui desideri ottimizzare il tuo modello. Il processo di creazione di un tale dataset può essere accelerato utilizzando Amazon SageMaker Ground Truth Plus, come descritto in Feedback umano di alta qualità per le tue applicazioni di intelligenza artificiale generativa da Amazon SageMaker Ground Truth Plus.
Modellare il modello
Prima di ottimizzare il modello, definiamo gli iperparametri che vogliamo utilizzare e alleniamo il modello. Possiamo anche registrare le nostre metriche su TensorBoard definendo il parametro logging_dir e richiedendo al transformer Hugging Face di report_to="tensorboard":
bucket = ”<YOUR-S3-BUCKET>”
log_bucket = f"s3://{bucket}/falcon-40b-qlora-finetune"
import transformers
# Impostiamo num_train_epochs=1 semplicemente per eseguire una dimostrazione
trainer = transformers.Trainer(
model=model,
train_dataset=lm_train_dataset,
eval_dataset=lm_test_dataset,
args=transformers.TrainingArguments(
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
logging_dir=log_bucket,
logging_steps=2,
num_train_epochs=1,
learning_rate=2e-4,
bf16=True,
save_strategy = "no",
output_dir="outputs",
report_to="tensorboard",
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)Monitorare l’ottimizzazione
Con la configurazione precedente, possiamo monitorare in tempo reale l’ottimizzazione. Per monitorare l’utilizzo della GPU in tempo reale, possiamo eseguire nvidia-smi direttamente dal contenitore del kernel. Per avviare un terminale che funzioni nell’immagine del contenitore, basta scegliere l’icona del terminale in alto nel tuo notebook.

Da qui, possiamo utilizzare il comando Linux watch per eseguire ripetutamente nvidia-smi ogni mezzo secondo:
watch -n 0.5 nvidia-smi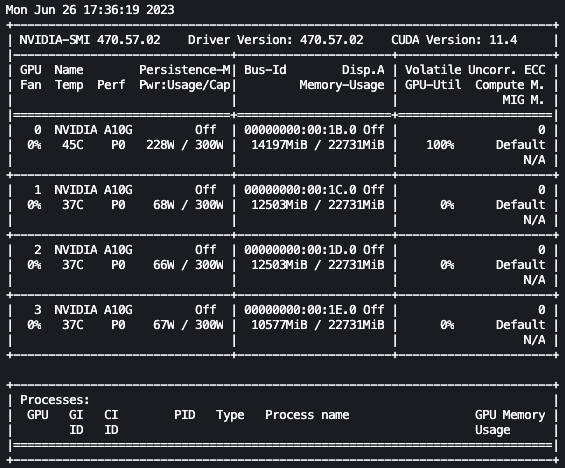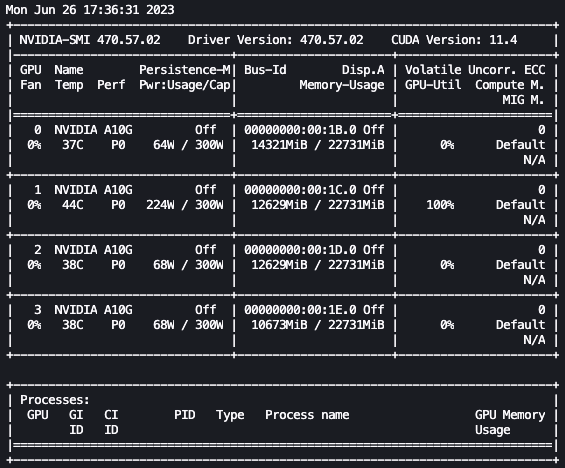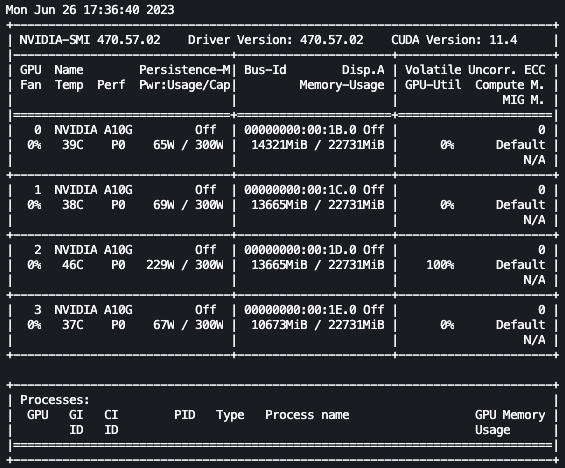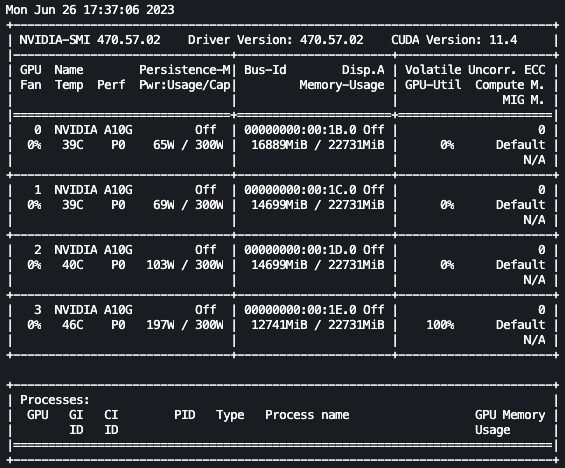
Nell’animazione precedente, possiamo vedere che i pesi del modello sono distribuiti tra le 4 GPU e il calcolo viene distribuito tra di esse mentre i livelli vengono elaborati in serie.
Per monitorare le metriche di allenamento, utilizziamo i log di TensorBoard che scriviamo nel bucket specificato di Amazon Simple Storage Service (Amazon S3). Possiamo avviare TensorBoard dell’utente del dominio di SageMaker Studio dalla console di AWS SageMaker:
Dopo il caricamento, puoi specificare il bucket S3 a cui hai istruito il transformer Hugging Face di registrare per visualizzare le metriche di allenamento e valutazione.
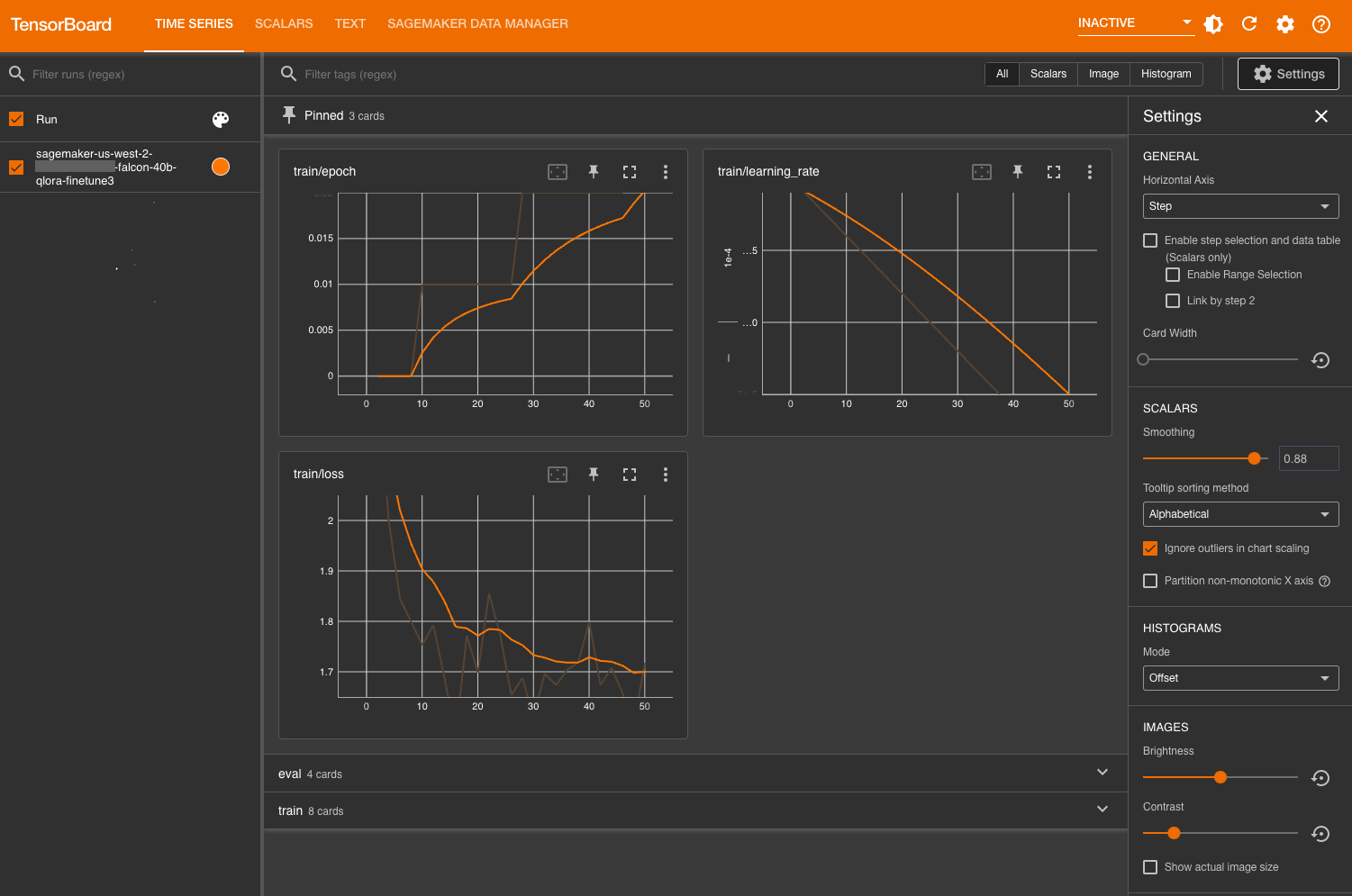
Valutare il modello
Dopo che il nostro modello ha finito l’addestramento, possiamo eseguire valutazioni sistematiche o semplicemente generare risposte:
tokens_for_summary = 30
output_tokens = input_ids.shape[1] + tokens_for_summary
outputs = model.generate(inputs=input_ids, do_sample=True, max_length=output_tokens)
gen_text = tokenizer.batch_decode(outputs)[0]
print(gen_text)
# Esempio di output:
# Riassumi il dialogo della chat:
# Richie: Pogba
# Clay: Pogboom
# Richie: che colpo incredibile!
# Clay: ero fuori dalla sedia appena ha girato la palla col piede destro
# Richie: anche io, amico
# Clay: speriamo che la sua forma duri
# Richie: questa stagione è più maturo
# Clay: sì, Jose ha fiducia in lui
# Richie: tutti hanno fiducia in lui
# Clay: sì, ha davvero meritato di segnare dopo i primi 60 minuti
# Richie: è una ricompensa
# Clay: sì, amico
# Richie: allora, tutto ok
# Clay: tutto ok
# ---
# Riassunto:
# Richie e Clay hanno discusso del gol segnato da Paul Pogba. La sua forma questa stagione è migliorata e entrambi sperano che duri a lungoDopo essere soddisfatti delle prestazioni del modello, è possibile salvarlo:
trainer.save_model("percorso_da_salvare")È anche possibile scegliere di ospitarlo in un endpoint dedicato di SageMaker.
Pulizia
Completa i seguenti passaggi per pulire le risorse:
-
Spegnere le istanze di SageMaker Studio per evitare costi aggiuntivi.
-
Spegnere l’applicazione TensorBoard.
-
Pulire la directory EFS cancellando la directory della cache di Hugging Face:
rm -R ~/.cache/huggingface/hub
Conclusione
I notebook di SageMaker permettono di ottimizzare i LLM in modo rapido ed efficiente in un ambiente interattivo. In questo post, abbiamo mostrato come utilizzare Hugging Face PEFT con bitsandbytes per ottimizzare i modelli Falcon-40B utilizzando QLoRA su notebook di SageMaker Studio. Provalo e facci sapere cosa ne pensi nella sezione dei commenti!
Ti incoraggiamo anche a scoprire di più sulle capacità di intelligenza generativa di Amazon esplorando SageMaker JumpStart, i modelli Amazon Titan e Amazon Bedrock.






