TaatikNet Apprendimento sequenza-sequenza per la trascrizione ebraica
'TaatikNet Seq2Seq Learning for Hebrew Transcription'
Una semplice dimostrazione di apprendimento seq2seq a livello di caratteri applicata a un compito complesso: la conversione tra testo ebraico e trascrizione latina

Questo articolo descrive TaatikNet e come implementare facilmente modelli seq2seq. Per il codice e la documentazione, consultare il repository TaatikNet su GitHub. Per una demo interattiva, vedere TaatikNet su HF Spaces.
Introduzione
Molte attività di interesse nell’elaborazione del linguaggio naturale coinvolgono la conversione tra testi in diversi stili, lingue o formati:
- Traduzione automatica (ad esempio, dall’inglese al tedesco)
- Riassunto del testo e parafrasando (ad esempio, da un testo lungo a un testo breve)
- Correzione ortografica
- Risposta alle domande astrattiva (input: contesto e domanda, output: testo della risposta)
Tali attività sono note collettivamente come apprendimento sequenza a sequenza (Seq2seq). In tutte queste attività, l’input e l’output desiderato sono stringhe, che possono avere lunghezze diverse e che di solito non sono in corrispondenza uno a uno tra loro.
Supponiamo di avere un dataset di esempi accoppiati (ad esempio, elenchi di frasi e le loro traduzioni, molti esempi di testi con errori ortografici e corretti, ecc.). Oggi è abbastanza facile addestrare una rete neurale su questi dati, purché ci sia abbastanza dati in modo che il modello possa imparare a generalizzare a nuovi input. Vediamo come addestrare modelli seq2seq con uno sforzo minimo, utilizzando PyTorch e la libreria Hugging Face transformers.
- Incontra ChatGLM2-6B la versione di seconda generazione del modello di chat open-source bilingue (cinese-inglese) ChatGLM-6B.
- Trasformazione della formazione specializzata di intelligenza artificiale – Incontra LMFlow un promettente toolkit per ottimizzare ed personalizzare in modo efficiente grandi modelli di base per prestazioni superiori.
- Un’introduzione all’Ingegneria delle Proposte
Ci concentreremo su un caso d’uso particolarmente interessante: imparare a convertire tra testo ebraico e trascrizione latina. Forniremo una panoramica di questo compito di seguito, ma le idee e il codice presentati qui sono utili al di là di questo caso particolare: questo tutorial dovrebbe essere utile per chiunque voglia eseguire l’apprendimento seq2seq da un dataset di esempi.
Il nostro compito: Trascrizione ebraica
Per dimostrare l’apprendimento seq2seq con un caso d’uso interessante e abbastanza nuovo, lo applichiamo alla trascrizione. In generale, la trascrizione si riferisce alla conversione tra diversi sistemi di scrittura. Mentre l’inglese è scritto con il sistema di scrittura latino (“ABC…”), le lingue del mondo utilizzano molti sistemi di scrittura diversi, come illustrato di seguito:
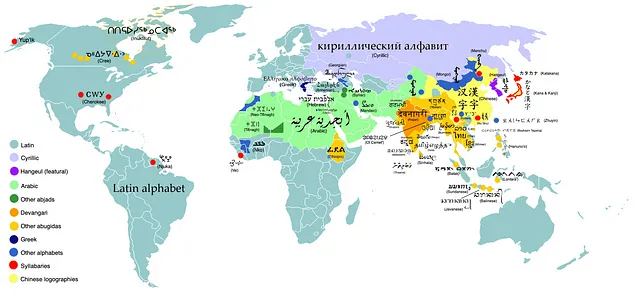
Cosa succede se vogliamo utilizzare l’alfabeto latino per scrivere una parola di una lingua originariamente scritta in un sistema di scrittura diverso? Questa sfida è illustrata dai molti modi di scrivere il nome della festa ebraica di Hanukkah. L’attuale introduzione del suo articolo su Wikipedia recita:
Hanukkah (/ˈhɑːnəkə/; ebraico: חֲנֻכָּה, Moderna: Ḥanukka, Tiberiana: Ḥănukkā) è una festa ebraica che commemora il recupero di Gerusalemme e la successiva ridedicazione del Secondo Tempio all’inizio della rivolta dei Maccabei contro l’Impero seleucide nel II secolo a.C.
La parola ebraica חֲנֻכָּה può essere trascritta in caratteri latini come Hanukkah, Chanukah, Chanukkah, Ḥanukka o una delle molte altre varianti. In ebraico, così come in molti altri sistemi di scrittura, ci sono diverse convenzioni e ambiguità che rendono la trascrizione complessa e non una semplice corrispondenza uno a uno tra i caratteri.
Nel caso dell’ebraico, è in gran parte possibile traslitterare il testo con i nikkud (segni vocali) in caratteri latini utilizzando un complesso insieme di regole, anche se ci sono vari casi limite che rendono questo processo in modo ingannevolmente complesso. Inoltre, il tentativo di traslitterare il testo senza segni vocali o di eseguire la mappatura inversa (ad esempio Chanukah → חֲנֻכָּה) è molto più difficile poiché ci sono molte possibili uscite valide.
Fortunatamente, con l’apprendimento approfondito applicato ai dati esistenti, possiamo fare grandi progressi nel risolvere questo problema con solo una quantità minima di codice. Vediamo come possiamo addestrare un modello seq2seq – TaatikNet – per imparare a convertire autonomamente il testo ebraico in traslitterazione latina. Notiamo che si tratta di un compito di livello carattere poiché comporta il ragionamento sulle correlazioni tra diversi caratteri nel testo ebraico e nelle traslitterazioni. Discuteremo l’importanza di questo in modo più dettagliato di seguito.
A proposito, potresti aver sentito parlare di UNIKUD, il nostro modello per aggiungere punti vocali al testo ebraico non vocalizzato. Ci sono alcune somiglianze tra questi compiti, ma la differenza chiave è che UNIKUD ha eseguito una classificazione a livello di carattere, in cui per ogni carattere abbiamo imparato se inserire uno o più simboli vocali adiacenti ad esso. Al contrario, nel nostro caso il testo di input e output potrebbe non corrispondere esattamente in lunghezza o in ordine a causa della complessa natura della traslitterazione, ecco perché qui utilizziamo l’apprendimento seq2seq (e non solo la classificazione per carattere).
Raccolta dei dati
Come per la maggior parte dei compiti di apprendimento automatico, siamo fortunati se possiamo raccogliere molti esempi di input e output desiderati del nostro modello, in modo da poterlo addestrare utilizzando l’apprendimento supervisionato.
Per molti compiti riguardanti parole e frasi, una grande risorsa è Wiktionary e i suoi corrispondenti multilingue – pensa a Wikipedia che incontra un dizionario. In particolare, l’ebraico Wiktionary (ויקימילון) contiene voci con informazioni grammaticali strutturate come mostrato di seguito:
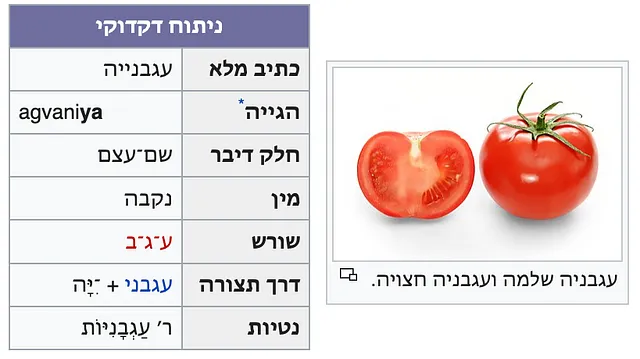
In particolare, questo include la traslitterazione latina ( agvani ya , dove il grassetto indica lo stress). Insieme ai titoli di sezione contenenti nikkud (caratteri vocali), ciò ci fornisce i dati (con licenza libera) di cui abbiamo bisogno per addestrare il nostro modello.
Per creare un set di dati, preleviamo questi elementi utilizzando l’API REST di Wikimedia ( esempio qui ). Si prega di notare che i testi originali nelle voci di Wiktionary hanno licenze permissive per opere derivate (licenze CC e GNU, dettagli qui ) e richiedono una licenza di condivisione simile (licenza TaatikNet qui ); in generale, se si esegue lo scraping dei dati, assicurarsi di utilizzare dati con licenze permissive, eseguire lo scraping correttamente e utilizzare la licenza corretta per il proprio lavoro derivato.
Eseguiamo vari passaggi di preprocessing su questi dati, tra cui:
- Rimuovere il markup e i metadati di Wiki
- Sostituire il testo in grassetto per rappresentare lo stress con accenti acuti (ad esempio agvani ya → agvaniyá)
- Normalizzazione Unicode NFC per unificare glifi che appaiono in modo identico come בּ (U+05D1 Lettera ebraica Bet + U+05BC Punto ebraico Dagesh o Mapiq) e בּ (U+FB31 Lettera ebraica Bet con Dagesh). Puoi confrontarli da solo copiandoli nel tool Mostra carattere Unicode . Unifichiamo anche segni di punteggiatura che appaiono in modo simile come geresh ebraico (׳) e apostrofo (’).
- Separare le espressioni di più parole in parole individuali.
Dopo lo scraping dei dati e il preprocessing, rimangono quasi 15k coppie di parole-traslitterazione ( file csv disponibile qui ). Di seguito sono mostrati alcuni esempi:

Le trascrizioni non sono affatto coerenti o prive di errori; ad esempio, lo stress è contrassegnato in modo incoerente e spesso in modo errato, e vengono utilizzate diverse convenzioni di ortografia (ad es. ח può corrispondere a h, kh o ch). Piuttosto che cercare di pulirli, li alimentiamo direttamente al modello e lo facciamo capire da solo.
Formazione
Ora che abbiamo il nostro set di dati, passiamo alla “carne” del nostro progetto: formare un modello seq2seq sui nostri dati. Chiamiamo il modello finale TaatikNet dalla parola ebraica תעתיק taatik che significa “traslitterazione”. Descriveremo qui la formazione di TaatikNet a un livello elevato, ma ti consigliamo vivamente di consultare il notebook di formazione annotato. Il codice di formazione stesso è abbastanza breve ed istruttivo.
Per ottenere risultati all’avanguardia nelle attività di elaborazione del linguaggio naturale (NLP), un paradigma comune è prendere una rete neurale trasformatore preaddestrata e applicare il trasferimento di apprendimento continuando a sintonizzarla su un set di dati specifico per l’attività. Per le attività seq2seq, la scelta più naturale del modello di base è un modello encoder-decoder (enc-dec). I modelli enc-dec comuni come T5 e BART sono eccellenti per le attività seq2seq comuni come la sintesi del testo, ma poiché tokenizzano il testo (lo suddividono in token di sottostringhe, approssimativamente parole o gruppi di parole), questi sono meno adatti per la nostra attività che richiede ragionamento a livello di singoli caratteri. Per questo motivo, utilizziamo il modello enc-dec ByT5 senza tokenizzatore (paper, pagina del modello HF), che esegue calcoli a livello di byte individuali (approssimativamente caratteri, ma vedi l’eccellente post di Joel Spolsky su Unicode e i set di caratteri per una migliore comprensione di come i glifi Unicode si mappano su byte).
Creiamo innanzitutto un oggetto Dataset di PyTorch per incapsulare i nostri dati di formazione. Potremmo semplicemente avvolgere i dati dal nostro file csv del set di dati senza modifiche, ma aggiungiamo alcune modifiche casuali per rendere più interessata la procedura di formazione del modello:
def __getitem__(self, idx): row = self.df.iloc[idx] out = {} if np.random.random() < 0.5: out['input'] = row.word if np.random.random() < 0.2 else row.nikkud out['target'] = row.transliteration else: out['input'] = randomly_remove_accent(row.transliteration, 0.5) out['target'] = row.nikkud return outQuesta modifica insegna a TaatikNet ad accettare sia lo script ebraico che lo script latino come input e a calcolare l’output corrispondente. Lasciamo anche cadere casualmente segni vocali o accenti per allenare il modello a essere robusto alla loro assenza. In generale, l’augmentazione casuale è un trucco utile quando si desidera che la rete impari a gestire vari tipi di input senza calcolare in anticipo tutti gli input e gli output possibili dal set di dati.
Carichiamo il modello di base con l’API del pacchetto Hugging Face utilizzando una singola riga di codice:
pipe = pipeline("text2text-generation", model='google/byt5-small', device_map='auto')Dopo aver gestito la raccolta dei dati e impostato gli iperparametri (numero di epoche, dimensione batch, tasso di apprendimento), formiamo il nostro modello sul nostro set di dati e stampiamo alcuni risultati selezionati dopo ogni epoca. Il ciclo di formazione è standard PyTorch, ad eccezione della funzione evaluate(…) che definiamo altrove e che stampa le previsioni attuali del modello su vari input:
for i in trange(epochs): pipe.model.train() for B in tqdm(dl): optimizer.zero_grad() loss = pipe.model(**B).loss losses.append(loss.item()) loss.backward() optimizer.step() evaluate(i + 1)Confronta alcuni risultati delle prime epoche e alla fine della formazione:
Epoca 0 prima della formazione: kokoro => okoroo-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oEpoca 0 prima della formazione: יִשְׂרָאֵל => אלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאEpoca 0 prima della formazione: ajiliti => ajabiliti siti siti siti siti siti siti siti siti siti siti siti siti siti siti siti siti siti sitEpoca 1: kokoro => מְשִׁיתEpoca 1: יִשְׂרָאֵל => maráEpoca 1: ajiliti => מְשִׁיתEpoca 2: kokoro => כּוֹקוֹרְבּוֹרוֹרEpoca 2: יִשְׂרָאֵל => yishishálEpoca 2: ajiliti => אַדִּיטִיEpoca 5: kokoro => קוֹקוֹרוֹEpoca 5: יִשְׂרָאֵל => yisraélEpoca 5: ajiliti => אֲגִילִיטִיEpoca 10 dopo la formazione: kokoro => קוֹקוֹרוֹEpoca 10 dopo la formazione: יִשְׂרָאֵל => yisraélEpoca 10 dopo la formazione: ajiliti => אָגִ'ילִיטִיPrima di addestrare il modello, produce risultati senza senso, come previsto. Durante l’addestramento vediamo che il modello impara prima come costruire un ebraico e traslitterazioni che sembrano valide, ma impiega più tempo per imparare la connessione tra di loro. Impiega anche più tempo per imparare elementi rari come ג׳ (gimel + geresh) corrispondente a j.
Un avvertimento: non abbiamo cercato di ottimizzare la procedura di addestramento; gli iperparametri sono stati scelti in modo piuttosto arbitrario e non abbiamo riservato set di validazione o di test per una valutazione rigorosa. Lo scopo di ciò era solo quello di fornire un semplice esempio di addestramento seq2seq e una prova di concetto di apprendimento delle traslitterazioni; tuttavia, l’ottimizzazione degli iperparametri e una valutazione rigorosa sarebbero una direzione promettente per lavori futuri insieme ai punti menzionati nella sezione delle limitazioni di seguito.
Risultati
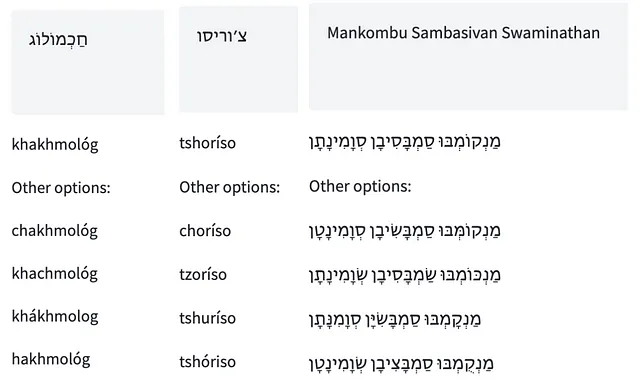
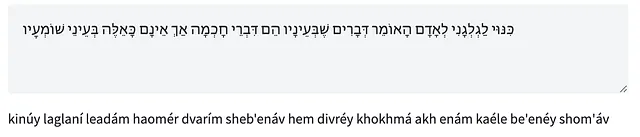
Sono mostrati di seguito alcuni esempi che dimostrano la conversione tra testo ebraico (con o senza vocali) e traslitterazione latina, in entrambe le direzioni. Puoi provare a giocare con TaatikNet tu stesso nella demo interattiva su HF Spaces. Nota che utilizza la ricerca a fascio (5 fasci) per la decodifica e l’inferenza viene eseguita su ogni parola separatamente.
Limitazioni e Possibili Sviluppi Futuri
Per semplicità, abbiamo implementato TaatikNet come un modello seq2seq minimo senza un’ottimizzazione approfondita. Tuttavia, se sei interessato a migliorare i risultati nella conversione tra testo ebraico e traslitterazione, ci sono molte direzioni promettenti per lavori futuri:
- TaatikNet cerca solo di indovinare l’ortografia appropriata (in ebraico o traslitterazione latina) in base alle corrispondenze lettera o suono. Tuttavia, potresti voler convertire da traslitterazione a testo ebraico valido dato il contesto (ad esempio, zot dugma → זאת דוגמא anziché l’ortografia incorretta *זות דוגמע). Possibili modi per realizzare ciò potrebbero includere la generazione arricchita da recupero (accesso a un dizionario) o l’addestramento su coppie di frasi ebraiche e relative traslitterazioni latine al fine di apprendere gli indizi contestuali.
- Inserimenti insoliti possono causare l’impasse della decodifica di TaatikNet in un ciclo, ad esempio drapapap → דְּרַפָּפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּ. Questo potrebbe essere gestito tramite l’augmentation durante l’addestramento, dati di addestramento più diversi o utilizzando la coerenza ciclica nell’addestramento o nella decodifica.
- TaatikNet potrebbe non gestire alcune convenzioni che sono piuttosto rare nei suoi dati di addestramento. Ad esempio, spesso non gestisce correttamente ז׳ (zayin+geresh) che indica il suono straniero raro zh. Ciò potrebbe indicare un sottoadattamento o che sarebbe utile utilizzare pesi campione durante l’addestramento per enfatizzare gli esempi difficili.
- La facilità dell’addestramento seq2seq comporta un compromesso in termini di interpretabilità e robustezza: potremmo voler sapere esattamente come TaatikNet prende le sue decisioni e assicurarci che siano applicate in modo coerente. Un’interessante possibile estensione potrebbe essere quella di sintetizzare la sua conoscenza in un insieme di condizioni basate su regole (ad esempio, se il carattere X viene visto nel contesto Y, allora scrivi Z). Forse gli LLM preaddestrati di recente potrebbero essere utili per questo.
- Non gestiamo la “scrittura completa” e la “scrittura difettiva” (כתיב מלא / חסר), in cui le parole ebraiche sono scritte leggermente diversamente quando scritte con o senza segni vocali. Idealmente, il modello dovrebbe essere addestrato su ortografie “complete” senza vocali e ortografie “difettive” con vocali. Vedi UNIKUD per un approccio a gestire queste ortografie in modelli addestrati su testo in ebraico.
Se provi queste o altre idee e scopri che portano a un miglioramento, sarei molto interessato a sentirti e a darti credito qui – non esitare a contattarmi tramite le mie informazioni di contatto sotto questo articolo.
Conclusione
Abbiamo visto che è abbastanza facile addestrare un modello seq2seq con apprendimento supervisionato – insegnandogli a generalizzare da un ampio insieme di esempi accoppiati. Nel nostro caso, abbiamo utilizzato un modello a livello di caratteri (TaatikNet, ottimizzato a partire dal modello di base ByT5), ma la stessa procedura e il codice potrebbero essere utilizzati per un compito seq2seq più standard come la traduzione automatica.
Spero che tu abbia imparato tanto da questo tutorial quanto io ho imparato mettendolo insieme! Non esitare a contattarmi per qualsiasi domanda, commento o suggerimento; le mie informazioni di contatto possono essere trovate sul mio sito web, collegato qui sotto.
Morris Alper, MSc è uno studente di dottorato presso l’Università di Tel Aviv che si occupa di apprendimento multimodale (NLP, Computer Vision e altre modalità). Per ulteriori informazioni e informazioni di contatto, si prega di visitare la sua pagina web: https://morrisalp.github.io/






