T5 Trasformatori di Testo in Testo (Parte Uno)
T5 Text-to-Text Transformers (Part One)
Creazione di un framework unificato per la modellizzazione del linguaggio

Il paradigma di apprendimento trasferito è composto da due fasi principali. In primo luogo, pre-adiestriamo una rete neurale profonda su un mucchio di dati. Quindi, affiniamo ulteriormente questo modello (cioè lo addestriamo ancora di più) su un dataset più specifico. L’implementazione esatta di queste fasi può assumere molte forme diverse. Nell’elaborazione delle immagini, ad esempio, spesso pre-adiestriamo i modelli sul dataset ImageNet utilizzando un obiettivo di apprendimento supervisionato. Quindi, questi modelli eseguono il raffinamento supervisionato sul dataset downstream (cioè il compito che stiamo effettivamente cercando di risolvere). In alternativa, nell’elaborazione del linguaggio naturale (NLP), spesso eseguiamo il pre-addestramento auto-supervisionato su un corpus testuale non etichettato.
La combinazione di grandi reti neurali profonde con enormi dataset (pre-)formati spesso porta a risultati impressionanti. Questa scoperta si è rivelata particolarmente vera per NLP. Dato che i dati testuali grezzi sono liberamente disponibili su Internet, possiamo semplicemente scaricare un corpus testuale massiccio, pre-addestrare una grande rete neurale su questi dati, quindi raffinare ulteriormente il modello su una varietà di compiti downstream (o semplicemente utilizzare tecniche di apprendimento zero/pochi colpi). Questo approccio di apprendimento trasferito su larga scala è stato inizialmente esplorato da BERT [2], che ha pre-addestrato un codificatore trasformatore su dati non etichettati utilizzando un obiettivo di mascheramento, quindi lo ha raffinato sui compiti di lingua downstream.
Il successo di BERT [2] non può essere sopravvalutato (cioè nuove prestazioni di stato dell’arte su quasi tutti i benchmark linguistici). Di conseguenza, la comunità NLP ha iniziato ad indagare pesantemente sull’argomento dell’apprendimento trasferito, portando alla proposta di molte nuove estensioni e miglioramenti. A causa dello sviluppo rapido in questo campo, il confronto tra le alternative era difficile. Il modello transformer di testo-su-testo (T5) [1] ha proposto un framework unificato per lo studio degli approcci di apprendimento trasferito in NLP, consentendoci di analizzare diverse impostazioni e derivare un insieme di migliori pratiche. Questo insieme di migliori pratiche comprende T5, un modello di stato dell’arte e un framework di addestramento per compiti di comprensione del linguaggio.
![(da [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*35oRo7jb3y7B8Fhw.png)
Storia e contesto rilevanti
T5 riformula le tecniche di apprendimento trasferito esistenti in un formato unificato, le confronta e determina le migliori pratiche per arrivare a un risultato ad alta performance. Ma cosa significa questo? Che cos’è l’apprendimento trasferito e perché dovremmo preoccuparcene? Per rispondere a queste domande, esamineremo prima un paio di idee importanti, tra cui l’apprendimento trasferito e diverse varianti dell’architettura del transformer, che saranno fondamentali per la comprensione dell’analisi in [1]. Da qui, forniremo un po’ di contesto storico spiegando l’architettura BERT [2], che ha reso popolare l’apprendimento trasferito per compiti di elaborazione del linguaggio naturale (NLP).
- Dalla teoria alla pratica Costruire un classificatore k-Nearest Neighbors
- Perché c’è una sorta di pranzo gratis
- 8 Cose Potenzialmente Sorprendenti Da Sapere Sui Grandi Modelli Linguistici (LLM)
Cos’è l’apprendimento trasferito?
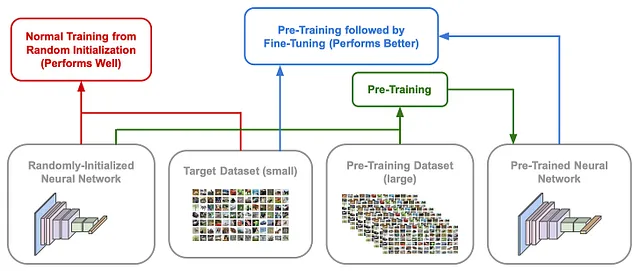
Se vogliamo addestrare una rete neurale per risolvere un determinato compito, abbiamo due opzioni di base.
- Addestramento da zero : inizializzare casualmente la rete neurale e addestrarla (in modo supervisionato) sul compito di destinazione.
- Apprendimento trasferito : pre-adiestrare la rete su un dataset separato, quindi affinarla ulteriormente (cioè addestrarla di più) sul compito di destinazione.
In genere, il pre-addestramento viene eseguito su un dataset molto più grande del dataset di destinazione downstream. In generale, il pre-addestramento migliora drasticamente l’efficienza dei dati. Il modello apprende più velocemente durante il raffinamento e potrebbe persino eseguire meglio. Il processo di apprendimento trasferito può assumere molte forme diverse. Nell’elaborazione delle immagini, ad esempio, potremmo pre-adiestrare un modello su ImageNet (utilizzando l’apprendimento supervisionato), quindi affinare su un dataset più piccolo come CIFAR-10/100. Per i compiti di elaborazione del linguaggio naturale (NLP), la storia è un po’ diversa. In genere, utilizziamo obiettivi di pre-addestramento auto-supervisionati (ad esempio, modellizzazione del linguaggio mascherato o modellizzazione del linguaggio causale) con testo non etichettato.
Diverse Architetture dei Transformer
![(da [6])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*dm-rGt0qMdxeytOK.png)
Il transformer, come proposto originariamente in [1], utilizza un’architettura codificatore-decodificatore, come mostrato sopra. Per una panoramica più approfondita di questa architettura, controlla il link qui . Tuttavia, l’architettura del transformer codificatore-decodificatore non è la nostra unica opzione! BERT utilizza un’architettura solo-codificatore, mentre la maggior parte dei moderni modelli di linguaggio (LLM) si basano su transformer solo-decodificatore . Dedichiamo un minuto per capire le differenze tra ciascuna di queste varianti architettoniche.
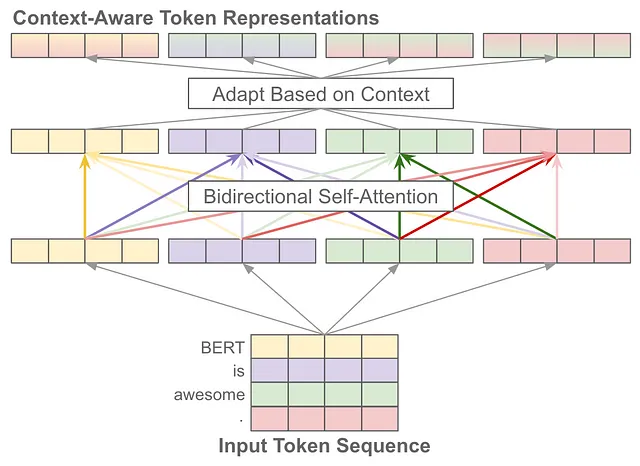
una guida all’auto-attenzione. L’operazione di auto-attenzione prende in input una sequenza di vettori di token e produce una nuova sequenza di vettori di token trasformati con la stessa lunghezza in uscita; vedi sopra. Ogni elemento di questa nuova sequenza è una media pesata dei vettori nella sequenza di input. In particolare, calcoliamo ciascun vettore di token nella sequenza di output come segue, dove y_i e x_j sono elementi delle sequenze di output e di input, rispettivamente.
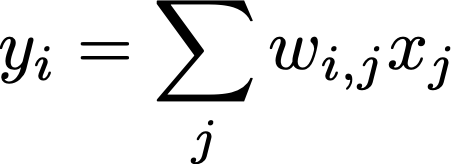
Il peso w_{i, j} sopra è uno score di attenzione che viene prodotto come funzione di x_i e x_j . In parole semplici, questo punteggio cattura quanto il token corrente dovrebbe “prestare attenzione a” un altro token nella sequenza durante il calcolo della sua nuova rappresentazione.
![(da [6])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*OD0iqN8ZiopLVa-S.png)
una pila singola o doppia? L’architettura originale del transformer utilizza due “pile” di livelli di transformer; vedi sopra. La prima pila (il modulo codificatore) è composta da diversi blocchi che contengono auto-attenzione bidirezionale e una rete neurale feed-forward . La seconda pila (il modulo decodificatore) è abbastanza simile, ma utilizza auto-attenzione mascherata e ha un meccanismo di “cross-attenzione” aggiunto che considera le attivazioni all’interno del livello di codificatore corrispondente durante l’auto-attenzione. Il transformer è stato originariamente utilizzato per compiti di sequenza-su-sequenza (ad esempio, la traduzione del linguaggio). Per altri compiti, i modelli di transformer a pila singola sono diventati popolari:
- I modelli di linguaggio utilizzano un’architettura solo-decodificatore
- i modelli di tipo BERT utilizzano un’architettura solo-codificatore
![(da [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*2dL9oU4rDV9IMZ_v.png)
maschere di attenzione. Le varianti dell’architettura del transformer hanno una distinzione principale: il tipo di mascheramento utilizzato nei loro strati di attenzione . Qui, quando diciamo “mascheramento”, ci riferiamo a determinati token che vengono mascherati (o ignorati) durante il calcolo dell’auto-attenzione. In parole semplici, alcuni token possono guardare solo una porzione selezionata di altri token nella sequenza di input completa. La figura sopra rappresenta diverse opzioni di mascheramento per l’auto-attenzione.
I modelli solo-codificatore sfruttano l’auto-attenzione bidirezionale (o completamente visibile), che considera tutti i token all’interno dell’intera sequenza durante l’auto-attenzione. Ciascuna rappresentazione del token nell’auto-attenzione viene calcolata come una media pesata di tutti gli altri token nella sequenza. Al contrario, i modelli solo-decodificatore utilizzano auto-attenzione causale, dove ciascun token considera solo i token che lo precedono nella sequenza.
![(da [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*8hM0xviv2hk-fwa8.png)
Possiamo anche adottare un approccio ibrido definendo un “prefisso”. Più specificamente, possiamo eseguire l’auto-attenzione bidirezionale per un gruppo di token all’inizio della sequenza (cioè un prefisso), poi eseguire l’auto-attenzione causale per il resto dei token nella sequenza; vedere sopra. L’auto-attenzione completamente visibile (o bidirezionale) è utile per l’attenzione su un prefisso o per eseguire compiti di classificazione. Tuttavia, alcune applicazioni (ad esempio, il modellamento del linguaggio) richiedono l’auto-attenzione causale durante l’addestramento per impedire al transformer di “guardare nel futuro” (cioè copiare solo il token corretto durante la generazione di output).
cosa usa T5? Sebbene l’analisi in [1] consideri molti architetti transformer, il modello primario utilizzato per T5 è un’architettura standard encoder-decoder. A parte alcune piccole modifiche, questo modello è abbastanza simile al transformer come proposto originariamente [6]. Le architetture solo encoder non vengono esplorate in [1] perché sono progettate per la classificazione a livello di token o sequenza e non per compiti generativi come la traduzione o la sintesi. T5 mira a trovare un approccio unificato (basato sul trasferimento di apprendimento) per risolvere molti compiti di comprensione del linguaggio.
BERT: Transfer Learning per NLP
Nelle prime fasi, il trasferimento di apprendimento in NLP utilizzava tipicamente reti neurali ricorrenti pre-addestrate con un obiettivo di modellazione del linguaggio causale. Tuttavia, tutto è cambiato con la proposta di BERT [2], un modello basato su transformer [6] che viene pre-addestrato utilizzando un obiettivo auto-supervisionato. BERT può essere pre-addestrato su grandi quantità di testo non etichettato, quindi raffinato per classificare frasi (e persino singoli token in una frase) con un’accuratezza incredibilmente alta. Al momento della sua proposta, BERT ha stabilito un nuovo stato dell’arte su quasi tutti i compiti di NLP che sono stati considerati, solidificando il trasferimento di apprendimento come l’approccio da utilizzare in NLP.
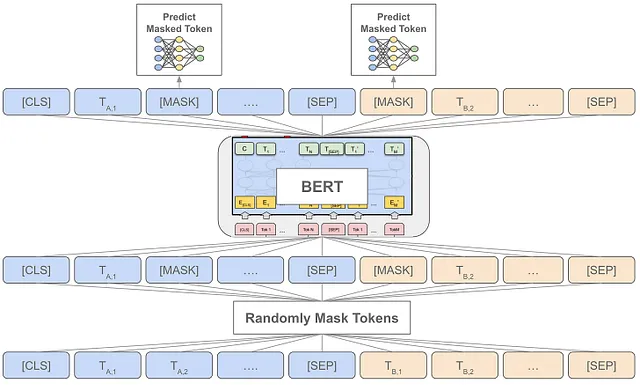
Per renderlo un po’ più specifico, BERT si basa su un obiettivo di “denoising”, chiamato modellizzazione del linguaggio mascherata (MLM), durante il pre-addestramento; vedere sopra. Anche se potrebbe sembrare un po’ complicato, l’idea è semplice, basta:
- Mascherare alcuni token nella sequenza di input sostituendoli con un token speciale
[MASK] - Elaborare la sequenza corrotta/modificata con BERT
- Addestrare BERT per prevedere con precisione i token mascherati
L’implementazione esatta è un po’ più complicata. Selezioniamo il 15% dei token a caso, quindi li sostituiamo con il token [MASK] (probabilità del 90%) o un token casuale (probabilità del 10%). Utilizzando questo obiettivo su un corpus di pre-addestramento sufficientemente grande, BERT può apprendere molte conoscenze linguistiche generali che lo rendono un modello altamente efficace per il trasferimento di apprendimento.
in che modo T5 è correlato a BERT? La proposta di BERT ha dimostrato che il trasferimento di apprendimento è un approccio utile per risolvere i problemi di NLP. Molte persone hanno iniziato rapidamente ad utilizzare BERT, cercando nuove tecniche e proponendo miglioramenti. Di conseguenza, il campo è stato sommerso da diverse opzioni per eseguire il trasferimento di apprendimento con modelli simili a BERT. T5 [1] continua in questa linea di ricerca, ma cerca di analizzare tutte queste diverse proposte utilizzando un framework unificato, dando una visione molto più chiara delle migliori pratiche per il trasferimento di apprendimento in NLP. Il modello finale T5 è addestrato utilizzando tutte queste migliori pratiche per raggiungere prestazioni all’avanguardia.
in che modo T5 è correlato ai LLM? Attualmente, stiamo assistendo a una massiccia rivoluzione nello spazio dell’AI generativo, in cui i LLM (basati su architetture solo decoder) vengono utilizzati per risolvere compiti linguistici tramite pre-addestramento del modello del linguaggio seguito da apprendimento zero/pochi colpi. I LLM sono ottimi, ma T5 esiste in un’area relativamente distinta di strumenti e ricerca. In particolare, T5 si concentra principalmente su modelli che elaborano esplicitamente l’input con un encoder prima di generare l’output con un decoder separato. Inoltre, T5 adotta un approccio di trasferimento di apprendimento (cioè pre-addestramento seguito da raffinamento su ciascun compito target) invece di apprendimento zero/pochi colpi.
Altri link utili
- L’architettura transformer [ link ]
- L’auto-attenzione [ link ]
- Il modello BERT [ link ]
- I fondamenti dei modelli del linguaggio [ link ]
T5: Il trasformatore unificato di testo in testo
Il contributo di T5 non è una nuova architettura o metodologia di formazione. Piuttosto, lo studio svolto in [1] si basa interamente su tecniche esistenti. T5 considera tutti gli aspetti del pipeline di apprendimento di trasferimento in NLP, come diversi dataset (non contrassegnati), obiettivi di pre-formazione, benchmark e metodi di messa a punto. Tuttavia, tutti questi aspetti sono studiati tramite un formato di testo in testo unificato. Lo scopo di T5 è di i) analizzare le impostazioni di apprendimento di trasferimento e ii) determinare gli approcci più efficaci.
Quadro di riferimento Testo in Testo
T5 converte tutti i problemi di elaborazione del testo in un formato “testo in testo” (ovvero, prende il testo in input e produce il testo in output). Questa struttura generica, che è anche sfruttata da LLM con zero/pochi colpi, ci consente di modellare e risolvere una varietà di diverse attività con un approccio condiviso. Possiamo applicare lo stesso modello, obiettivo, procedura di formazione e processo di decodifica a ogni attività che consideriamo! Adottiamo solo un approccio di sollecitazione e chiediamo al nostro modello linguistico di generare la risposta in un formato testuale.
![(da [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*YmbQ5UMlUzGu3eVE.png)
Per rendere tutto questo un po’ più concreto, tutte le attività risolte da T5 possono essere convertite in formato testo in testo come segue:
- Aggiungere un prefisso specifico dell’attività alla sequenza di input originale
- Alimentare questa sequenza nel trasformatore
- Formulare l’obiettivo del modello come una sequenza testuale
Utilizzando questo formato, possiamo facilmente eseguire attività come la sintesi o la traduzione (ovvero, l’obiettivo è naturalmente una sequenza). Inoltre, possiamo eseguire la classificazione semplicemente addestrando il modello a generare il testo associato alla classe corretta. Questo processo diventa un po’ complicato per problemi come la regressione (ovvero, dobbiamo arrotondare le uscite a valori reali al decimale più vicino e trattarlo come un problema di classificazione), ma tende a funzionare bene per la maggior parte delle attività linguistiche. Gli esempi sono mostrati nella figura sopra.
“Sorge un problema se il nostro modello fornisce in uscita del testo in un compito di classificazione del testo che non corrisponde a nessuna delle etichette possibili… In questo caso, consideriamo sempre l’output del modello come sbagliato, anche se non abbiamo mai osservato questo comportamento in nessuno dei nostri modelli addestrati.” — da [1]
T5 viene messo a punto su ogni attività che risolve. Questo è in contrasto sia con LLM, che utilizzano il learning few-show, sia con il decathlon NLP [3], che utilizza il multi-task learning per risolvere molte attività contemporaneamente.
Come viene studiato T5?
Tutte le analisi svolte in [1] utilizzano il quadro di riferimento testo in testo unificato descritto sopra, poiché consente di convertire una varietà di diverse attività di comprensione del linguaggio in un formato condiviso. Inoltre, l’analisi di T5 utilizza lo stesso archivio di trasformatori e il dataset di pre-formazione sottostante.
![(da [6])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*s8IHAOz3BOOx6p4p.png)
il modello. Come discusso in precedenza, l’architettura del trasformatore, come proposta originariamente in [6], contiene sia un modulo di codifica che un modulo di decodifica. Il recente lavoro sulla modellizzazione del linguaggio ha esplorato varianti architettoniche che sono solo codificatore o solo decodificatore; ad esempio, BERT utilizza solo il codificatore [2], mentre la maggior parte dei modelli di lingua (grandi) utilizza solo il decodificatore. T5 utilizza un’architettura codificatore-decodificatore che assomiglia molto al trasformatore originale. Le differenze sono:
- LayerNorm viene applicato immediatamente prima di ogni attenzione e trasformazione di avanzamento (ovvero, al di fuori del percorso residuo)
- Non viene utilizzato alcun bias additivo per LayerNorm (ovvero, vedi qui; utilizziamo solo la scala e eliminiamo il bias additivo)
- Viene utilizzato un semplice schema di incorporamento della posizione che aggiunge uno scalare al logit corrispondente utilizzato per calcolare i pesi di attenzione
- Viene applicata la disconnessione in tutto il network (ad esempio, pesi di attenzione, rete di avanzamento di feed, connessione di salto, ecc.)
Queste modifiche sono illustrate nella figura sopra. Utilizzando questo modello (e alcuni altri), T5 può testare molte diverse impostazioni di apprendimento di trasferimento per derivare un insieme di migliori pratiche.
Dataset di pre-training. T5 è pre-addestrato sul Corpus C4 (Colossal Clean Crawled), un corpus di 750 Gb di testo inglese “relativamente pulito” creato in [1]. Mentre una varietà di dataset di pre-training sono stati proposti in precedenti lavori, gli autori in [1] hanno scelto di costruire il proprio dataset a causa del fatto che i dataset precedenti non erano disponibili pubblicamente, utilizzavano un insieme limitato di regole di filtraggio, avevano un ambito limitato (ad esempio, solo Creative Commons), o si concentravano solo sui dati paralleli per la traduzione automatica (cioè versioni della stessa frase in molte lingue diverse).
![(da [4])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*YMNBqqph9KCpLCUF.png)
È interessante notare che C4 è stato successivamente utilizzato come sottoinsieme del dataset MassiveText utilizzato per il pre-addestramento di Gopher e Chinchilla [4, 5]. Consultare la tabella sopra per le metriche di dimensione di questo dataset, che fornisce una migliore comprensione della dimensione di C4 rispetto ai dataset di pre-training utilizzati per addestrare i moderni LLMs. Con i LLMs, abbiamo visto che il pre-addestramento di modelli decoder-only su dataset sufficientemente grandi è cruciale per il loro successo. Lo stesso vale per i transformer con diverse architetture, come T5. Un esteso pre-addestramento su un grande dataset non etichettato è propizio per una migliore performance a valle.
Setup sperimentale. T5 è pre-addestrato su C4 e quindi fine-tuned per risolvere una varietà di task a valle. Tuttavia, le impostazioni esatte utilizzate all’interno di questo framework sono variabili. In particolare, possiamo cambiare:
- L’architettura del Transformer
- L’impostazione del pre-addestramento (cioè il task o la quantità di dati)
- L’impostazione di fine-tuning
- La dimensione / scala del modello
Cambiando ciascuna di queste impostazioni una alla volta e valutando i risultati, possiamo sviluppare un insieme di best practice per il transfer learning in NLP, distillando le molte proposte dopo BERT in un singolo e efficace pipeline per la creazione di modelli di comprensione del linguaggio efficaci.
Takeaways
Questo post ha coperto tutte le informazioni preliminari relative al modello T5, inclusi importanti informazioni di background e il framework sperimentale di base utilizzato. Nel prossimo post, copriremo i dettagli dell’estesa analisi eseguita in [1], che scopre le migliori pratiche per il transfer learning in NLP. Per ora, le principali conclusioni relative a T5 sono riassunte di seguito.
Il transfer learning è potente. Il transfer learning si riferisce al processo di pre-addestramento di un modello di deep learning su un dataset separato, quindi fine-tuning (o ulteriore addestramento) di questo modello su un dataset di destinazione a valle (cioè il task che stiamo cercando di risolvere). Se effettuato su un dataset sufficientemente grande e allineato (cioè simile al task a valle) il pre-addestramento è incredibilmente efficace. Il modello può imparare molto più velocemente durante il fine-tuning e raggiungere anche una maggiore accuratezza. Questa tecnica è efficace in molti domini (ad esempio, computer vision e NLP), ma l’approccio esatto utilizzato per il pre-addestramento o il fine-tuning potrebbe differire.
“Anche se non misuriamo esplicitamente i miglioramenti nell’efficienza dei dati in questo articolo, sottolineiamo che questo è uno dei principali vantaggi del paradigma di transfer learning.” — da [1]
Cosa viene dopo BERT? La proposta di BERT [2] è stata una grande svolta che ha reso popolare l’uso del transfer learning per i task di NLP. Infatti, BERT ha stabilito una nuova performance di stato dell’arte su quasi ogni task considerato. Grazie al suo successo, la comunità di ricerca ha adottato e iterato sull’approccio di BERT. T5 cerca di unificare tutto questo lavoro di follow-up e analisi che è venuto dopo la proposta di BERT, fornendo una visione più chiara degli approcci di transfer learning più efficaci.
Formulazione generica del task. Al fine di creare un framework unificato secondo il quale molteplici approcci di transfer learning possono essere studiati, T5 ha proposto un framework generico di testo-testo. Similmente alle tecniche di prompting e few-shot learning utilizzate per LLMs, questo framework testo-testo può ristrutturare qualsiasi task linguistico in input e output testuali. In particolare, ciò viene fatto aggiungendo un prefisso specifico del task all’input testuale (cioè in modo che T5 sappia quale task sta cercando di risolvere) e utilizzando il modulo decoder di T5 per generare testo corrispondente al target desiderato (ad esempio, un’etichetta, un valore di regressione o una sequenza di testo).
Considerazioni finali
Grazie per aver letto questo articolo. Sono Cameron R. Wolfe, Direttore di AI presso Rebuy. Studio le fondamenta empiriche e teoriche del deep learning. Potete anche consultare i miei altri scritti su Nisoo! Se vi è piaciuto, seguitemi su Twitter o iscrivetevi alla mia newsletter Deep (Learning) Focus, dove aiuto i lettori a costruire una comprensione più approfondita degli argomenti della ricerca sull’AI tramite una panoramica comprensibile di documenti popolari.
Bibliografia
[1] Raffel, Colin, et al. “Esplorare i limiti del trasferimento di apprendimento con un trasformatore di testo-unificato.” The Journal of Machine Learning Research 21.1 (2020): 5485–5551.
[2] Devlin, Jacob, et al. “Bert: Pre-training di trasformatori bidirezionali profondi per la comprensione del linguaggio.” arXiv preprint arXiv:1810.04805 (2018).
[3] McCann, Bryan, et al. “Il decathlon del linguaggio naturale: l’apprendimento multitask come risposta alle domande.” arXiv preprint arXiv:1806.08730 (2018).
[4] Rae, Jack W., et al. “Scalare i modelli del linguaggio: metodi, analisi e intuizioni dalla formazione di gopher.” arXiv preprint arXiv:2112.11446 (2021).
[5] Hoffmann, Jordan, et al. “Formazione di modelli di linguaggio grandi ottimizzati per il calcolo.” arXiv preprint arXiv:2203.15556 (2022).
[6] Vaswani, Ashish, et al. “L’attenzione è tutto ciò di cui hai bisogno.” Advances in neural information processing systems 30 (2017).





