Prendi questo e trasformalo in un burattino digitale GenMM è un modello di AI che può sintetizzare il movimento utilizzando un singolo esempio.
Trasforma questo in un burattino digitale con GenMM, un modello di intelligenza artificiale che usa un solo esempio per sintetizzare il movimento.


Le animazioni generate al computer diventano sempre più realistiche ogni giorno. Questo progresso può essere meglio visto nei videogiochi. Pensate alla prima Lara Croft nella serie Tomb Raider e alla più recente Lara Croft. Siamo passati da un burattino con 230 poligoni che fa movimenti strani a un personaggio realistico che si muove fluidamente sullo schermo.
Generare movimenti naturali e diversi nell’animazione al computer è da tempo un problema difficile. I metodi tradizionali, come i sistemi di acquisizione del movimento e la creazione manuale di animazioni, sono noti per essere costosi e richiedere molto tempo, risultando in dataset di movimenti limitati che mancano di diversità nello stile, nelle strutture scheletriche e nei tipi di modelli. Questa natura manuale e che richiede molto tempo nella generazione di animazioni porta alla necessità di una soluzione automatizzata nell’industria.
I metodi di sintesi del movimento basati sui dati esistenti sono limitati nella loro efficacia. Tuttavia, negli ultimi anni, l’apprendimento profondo è emerso come una tecnica potente nell’animazione al computer, in grado di sintetizzare movimenti diversi e realistici quando addestrato su dataset ampi e completi.
- Battaglia tra i giganti dell’LLM Google PaLM 2 vs OpenAI GPT-3.5
- Incontra Video-ControlNet un nuovo modello di diffusione di testo in video destinato a cambiare il gioco e a plasmare il futuro della generazione di video controllabili.
- Un Confronto degli Algoritmi di Apprendimento Automatico in Python e R
I metodi di apprendimento profondo hanno dimostrato risultati impressionanti nella sintesi del movimento, ma soffrono di inconvenienti che limitano la loro applicabilità pratica. In primo luogo, richiedono tempi di addestramento lunghi, che possono rappresentare un grosso ostacolo nella pipeline di produzione di animazioni. In secondo luogo, sono soggetti a artefatti visivi come tremolii o eccessivo liscio, che influiscono sulla qualità dei movimenti sintetizzati. Infine, hanno difficoltà a scalare bene a strutture scheletriche grandi e complesse, limitando il loro utilizzo in scenari in cui sono necessari movimenti intricati.
Sappiamo che c’è una domanda per un metodo affidabile di sintesi del movimento che può essere applicato in scenari pratici. Tuttavia, questi problemi non sono facili da superare. Quindi, quale può essere la soluzione? È il momento di incontrare GenMM.
GenMM è un approccio alternativo basato sull’idea classica di vicini di movimento più vicini e corrispondenza di movimento. Utilizza la corrispondenza di movimento, una tecnica ampiamente utilizzata nell’industria per l’animazione dei personaggi, e produce animazioni di alta qualità che appaiono naturali e si adattano a contesti locali variabili.
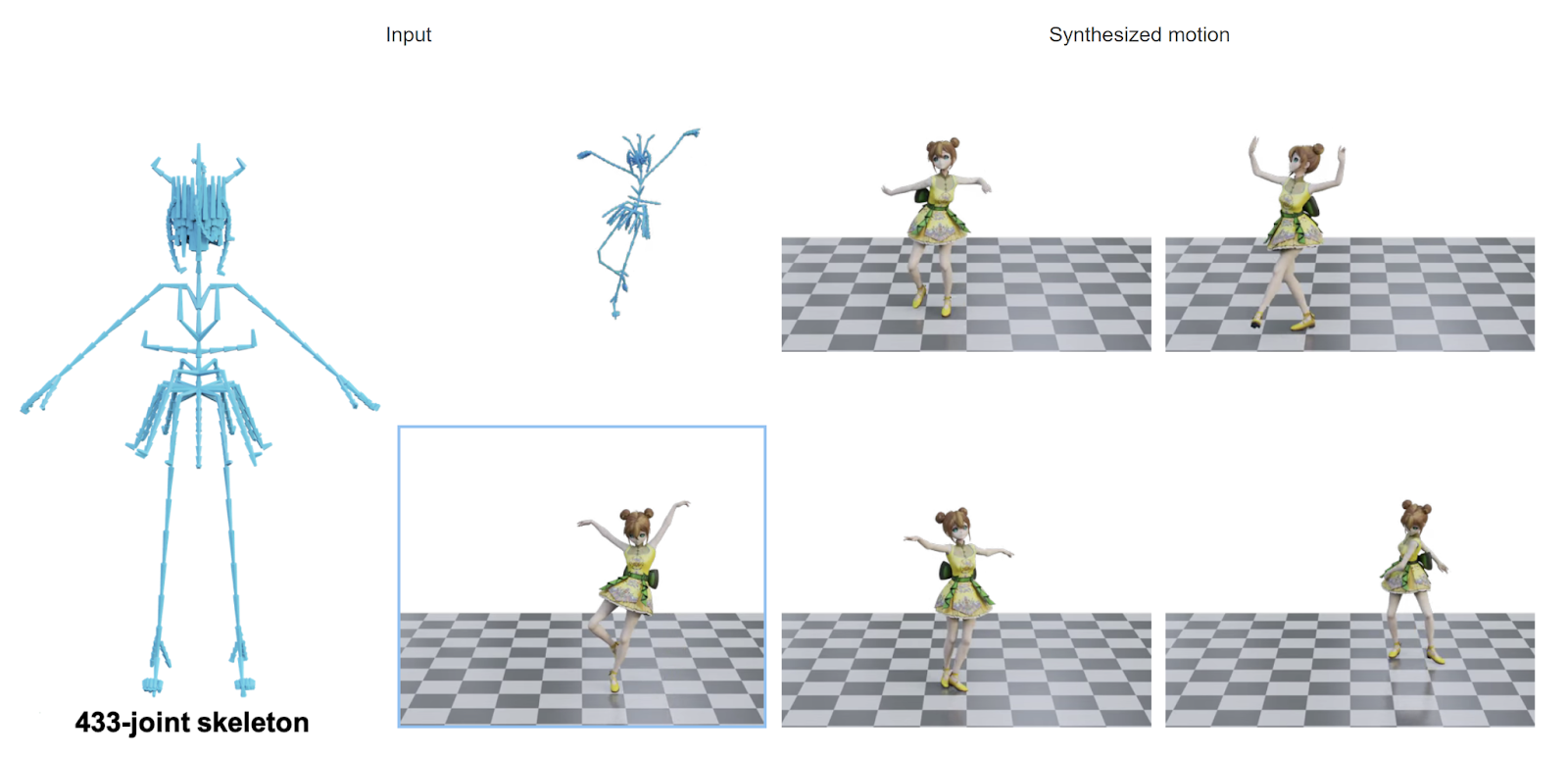
GenMM è un modello generativo che può estrarre movimenti diversi da una o poche sequenze di esempio. Lo fa sfruttando un ampio database di acquisizione del movimento come approssimazione di tutto lo spazio di movimento naturale.
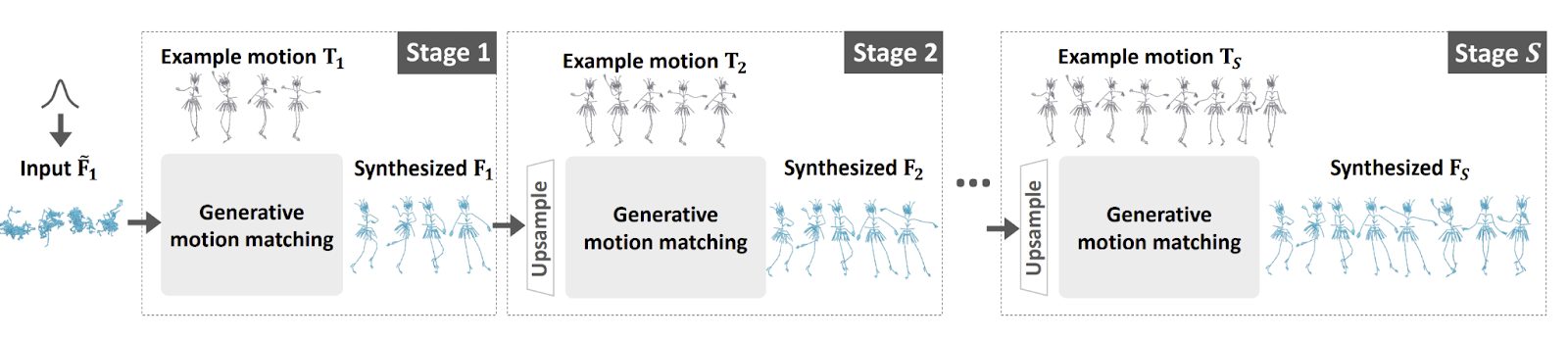
GenMM incorpora la similitudine bidirezionale come nuova funzione di costo generativa. Questa misura di similitudine garantisce che la sequenza di movimento sintetizzata contenga solo patch di movimento dagli esempi forniti e viceversa. Questo approccio mantiene la qualità della corrispondenza di movimento consentendo al tempo stesso le capacità generative. Per migliorare ulteriormente la diversità, utilizza un framework a più fasi che sintetizza progressivamente sequenze di movimento con minime discrepanze di distribuzione rispetto agli esempi. Inoltre, viene introdotto un input di rumore incondizionato nella pipeline, ispirato dal successo dei metodi basati su GAN nella sintesi di immagini, per ottenere risultati di sintesi altamente diversi.
Oltre alla sua capacità di generare movimenti diversi, GenMM dimostra anche di essere un framework versatile che può essere esteso a vari scenari al di là delle capacità della sola corrispondenza di movimento. Questi includono completamento del movimento, generazione guidata da frame chiave, looping infinito e riassemblaggio del movimento, dimostrando l’ampia gamma di applicazioni abilitate dall’approccio di corrispondenza di movimento generativo.






