L’artista Pal nel tuo taschino SnapFusion è un approccio di intelligenza artificiale che porta la potenza dei modelli di diffusione sui dispositivi mobili.
Pal artist on SnapFusion is an AI approach that brings the power of diffusion models to mobile devices.


Modelli di diffusione. Questo è un termine che hai sentito molto se hai prestato attenzione ai progressi nel dominio dell’AI. Sono stati la chiave che ha permesso la rivoluzione nei metodi di AI generativa. Ora abbiamo modelli che possono generare immagini fotorealistiche utilizzando prompt di testo in pochi secondi. Hanno rivoluzionato la generazione di contenuti, la modifica di immagini, la super risoluzione, la sintesi video e la generazione di asset 3D.
Anche se questa impressionante performance non è economica. I modelli di diffusione richiedono requisiti di calcolo estremamente elevati. Ciò significa che hai bisogno di GPU di alta gamma per sfruttarli appieno. Sì, ci sono anche tentativi di farli funzionare sui computer locali; ma anche in questo caso, hai bisogno di uno di alta gamma. D’altra parte, l’utilizzo di un provider cloud può essere una soluzione alternativa, ma in tal caso potresti rischiare la tua privacy.
Poi, c’è anche l’aspetto on-the-go che dobbiamo pensare. Per la maggior parte delle persone, trascorrono più tempo sui loro telefoni che sui loro computer. Se si desidera utilizzare modelli di diffusione sul proprio dispositivo mobile, beh, buona fortuna, poiché sarà troppo esigente per la limitata potenza hardware del dispositivo stesso.
- Comprensione della modellizzazione della miscela di marketing bayesiano un’analisi approfondita delle specifiche precedenti.
- Ricerca di similarità, Parte 5 Hashing Sensibile alla Località (LSH)
- Incontra MeLoDy Un Modello di Diffusione Testo-Audio Efficiente per la Sintesi Musicale.
I modelli di diffusione sono la prossima grande cosa, ma dobbiamo affrontare la loro complessità prima di applicarli in applicazioni pratiche. Ci sono stati molti tentativi che si sono concentrati sulla velocizzazione dell’infelicità sui dispositivi mobili, ma non hanno raggiunto un’esperienza utente senza soluzione di continuità o una valutazione quantitativa della qualità di generazione. Beh, era la storia fino ad ora perché abbiamo un nuovo giocatore sul campo, e si chiama SnapFusion.
SnapFusion è il primo modello di diffusione di testo-a-immagine che genera immagini su dispositivi mobili in meno di 2 secondi. Ottimizza l’architettura UNet e riduce il numero di passaggi di denoising per migliorare la velocità di inferenza. Inoltre, utilizza un framework di formazione in evoluzione, introduce pipeline di distillazione dei dati e migliora l’obiettivo di apprendimento durante la distillazione dei passaggi.
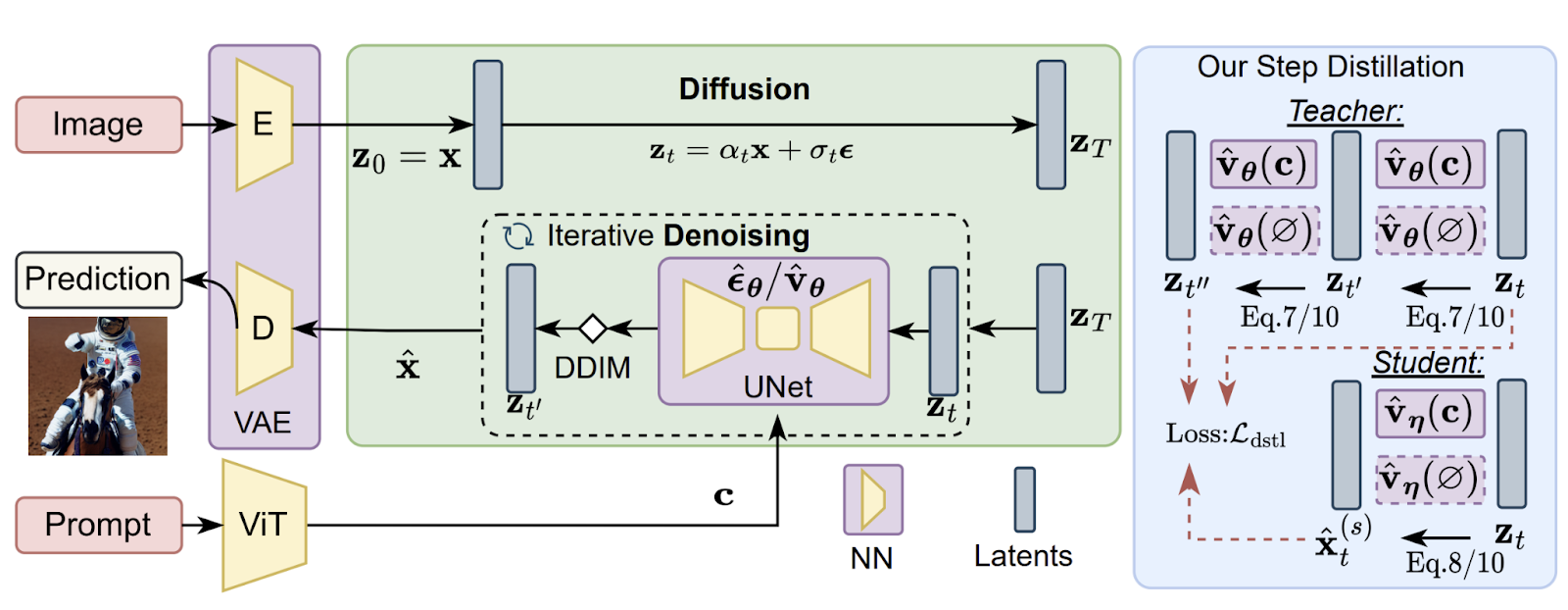
Prima di apportare modifiche alla struttura, gli autori di SnapFusion hanno prima indagato sulla ridondanza dell’architettura di SD-v1.5 per ottenere reti neurali efficienti. Tuttavia, applicare la potatura convenzionale o le tecniche di ricerca dell’architettura a SD era difficile a causa dell’alto costo di formazione. Qualsiasi cambiamento nell’architettura può comportare una performance degradata, richiedendo un’estesa messa a punto con risorse computazionali significative. Quindi, quella strada era bloccata, e hanno dovuto sviluppare soluzioni alternative che possano preservare le performance del modello UNet pre-addestrato, migliorandone gradualmente l’efficacia.
Per aumentare la velocità di inferenza, SnapFusion si concentra sull’ottimizzazione dell’architettura UNet, che è un collo di bottiglia nel modello di diffusione condizionata. I lavori esistenti si concentrano principalmente su ottimizzazioni post-formazione, ma SnapFusion identifica le ridondanze dell’architettura e propone un framework di formazione in evoluzione che supera il modello di diffusione stabile originale migliorando significativamente la velocità. Introduce anche una pipeline di distillazione dei dati per comprimere e accelerare il decodificatore delle immagini.
SnapFusion include una robusta fase di formazione, in cui viene applicata la propagazione anteriore stocastica per eseguire ogni attenzione incrociata e blocco ResNet con una certa probabilità. Questo robusto aumento della formazione garantisce che la rete sia tollerante alle permutazioni dell’architettura, consentendo una valutazione accurata di ogni blocco e l’evoluzione architettonica stabile.
Il decodificatore di immagini efficiente è ottenuto attraverso una pipeline di distillazione che utilizza dati sintetici per addestrare il decodificatore ottenuto tramite la riduzione dei canali. Questo decodificatore compresso ha parametri significativamente inferiori ed è più veloce di quello di SD-v1.5. Il processo di distillazione prevede la generazione di due immagini, una dal decodificatore efficiente e l’altra da SD-v1.5, utilizzando prompt di testo per ottenere la rappresentazione latente dall’UNet di SD-v1.5.
L’approccio di distillazione a step proposto include un obiettivo di perdita di distillazione vanilla, che mira a minimizzare la discrepanza tra la previsione della UNet dell’alunno e la rappresentazione latente rumorosa della UNet dell’insegnante. Inoltre, viene introdotto un obiettivo di perdita di distillazione CFG-aware per migliorare il punteggio CLIP. Le previsioni guidate da CFG sono utilizzate sia nei modelli dell’insegnante che dell’alunno, dove la scala CFG viene campionata casualmente per fornire un compromesso tra i punteggi FID e CLIP durante l’addestramento.

Grazie all’improved step distillation e allo sviluppo dell’architettura di rete, SnapFusion è in grado di generare immagini di 512 × 512 pixel da prompt di testo su dispositivi mobili in meno di 2 secondi. Le immagini generate presentano una qualità simile al modello di diffusione stabile all’avanguardia.





