CI/CD per Endpoint Multi-Modello in AWS
CI/CD for Multi-Model Endpoint in AWS.
Una soluzione semplice e flessibile per soluzioni di ML sostenibili

L’automazione della riformazione e dell’implementazione delle soluzioni di machine learning di produzione è un passo cruciale per garantire che i modelli tengano conto dello spostamento dei covarianti limitando gli errori e lo sforzo umano superfluo.
Per i modelli implementati tramite lo stack AWS e in particolare SageMaker, AWS offre una soluzione standard CI/CD utilizzando SageMaker Pipelines per l’automazione della riformazione/ implementazione, e SageMaker Model Registry per tracciare la genealogia di un modello.
Anche se la soluzione standard funziona bene per i casi standard, ci sono diverse limitazioni per i casi più intricati:
- I dati di input devono provenire da AWS s3.
- Difficoltà nell’impostazione della messa a punto degli iperparametri di avvio dinamico.
- Sono necessari ulteriori passaggi di formazione del modello per formare più modelli.
- Lunga durata di avvio per eseguire una pipeline.
- Strumenti di debug limitati.
Fortunatamente, AWS ha lanciato nuove funzionalità che possono essere utilizzate per costruire una pipeline CI/CD che supera queste limitazioni. Le seguenti funzionalità possono essere accedute all’interno di SageMaker Studio, l’ambiente di sviluppo integrato di AWS per il machine learning:
- Nisoo Top Post per Maggio 2023 Mojo Lang Il Nuovo Linguaggio di Programmazione
- Abilità Emergente Svelata Solo l’AI Matura come GPT-4 può Migliorarsi da sola? Esplorare le Implicazioni della Crescita Autonoma nei Modelli di Linguaggio.
- Rosso Gatto & Athena AI creano droni militari intelligenti con visione notturna.
- Utilizzo di un’immagine SageMaker personalizzata
- Integrazione Git/SageMaker Studio
- Messa a punto degli iperparametri di avvio dinamico
- Notebook di lavoro di SageMaker Studio
- Registro modelli multi-account
Lo scopo di questo articolo…
è di esaminare i dettagli chiave di una soluzione alternativa CI/CD tramite il cloud AWS che fornisce maggiore flessibilità e velocità di commercializzazione più veloce.
Panoramica dei componenti della soluzione:
1. Immagine SageMaker Studio personalizzata per l’interrogazione di PostgreSQL
2. Messa a punto degli iperparametri di avvio dinamico
3. Registra più modelli nel Registro modelli in un singolo notebook interattivo di Python
4. Aggiorna un endpoint multi-modello con nuovi modelli
5. Programma i notebook di riformazione/ implementazione per l’esecuzione su un set di tempi prestabilito
Cominciamo.
1. Immagine SageMaker Studio personalizzata per l’interrogazione di PostgreSQL
Anche se SageMaker Pipelines consente l’input di dati da s3, cosa succede se i nuovi dati di input risiedono in un data warehouse come AWS Redshift o Google BigQuery? Naturalmente, può essere utilizzato un processo ETL o comparabile per spostare i dati in s3 a lotti, ma questo aggiunge semplicemente complessità/rigidità superflue rispetto all’interrogazione diretta dei dati del data warehouse nella pipeline.
SageMaker Studio fornisce diverse immagini predefinite per inizializzare un ambiente, un esempio è “Data Science” che include pacchetti comuni come numpy e pandas. Tuttavia, per connettersi a un database PostgreSQL in Python, è richiesto un driver o un adattatore. Psycopg2 è l’adattatore più popolare del database PostgreSQL per il linguaggio di programmazione Python. Fortunatamente, le immagini personalizzate possono essere utilizzate per inizializzare un ambiente Studio anche se ci sono requisiti specifici. Ho preconfezionato un’immagine Docker che soddisfa questi requisiti e che si basa sull’immagine Python Julia-1.5.2 aggiungendo il driver psycopg2. L’immagine può essere trovata in questo repository git. I passaggi qui descritti possono quindi essere utilizzati per rendere l’immagine accessibile in un dominio Studio.
2. Messa a punto degli iperparametri di avvio dinamico
La riformazione del modello è diversa per natura rispetto alla formazione iniziale del modello. Non è pratico investire le stesse risorse per cercare i migliori iperparametri del modello e su uno spazio di ricerca così ampio quando si riforma un modello. Questo è particolarmente vero quando si prevedono solo piccoli aggiustamenti ai migliori iperparametri rispetto all’ultimo modello di produzione.
Per questo motivo, la soluzione di messa a punto degli iperparametri consigliata per CI/CD in questo articolo non cerca di effettuare una messa a punto intensiva con K fold cross-validation, pool caldi, ecc. Tutto ciò può funzionare bene per la formazione iniziale del modello. Per la riformazione, tuttavia, vogliamo partire da ciò che ha funzionato bene in produzione già e apportare piccoli aggiustamenti per tener conto dei dati disponibili. Come tale, l’utilizzo della messa a punto degli iperparametri di avvio dinamico è la soluzione perfetta. Inoltre, può essere creata un sistema di messa a punto degli iperparametri di avvio dinamico che utilizza l’ultimo lavoro di messa a punto di produzione come genitore. La soluzione può apparire come segue per un esempio di lavoro di messa a punto baysiana XGBoost:
# Imposta i parametri di esecuzione
testing=False
hyperparam_jobs=10
# Imposta il numero massimo di job
if testing==False:
max_jobs=hyperparam_jobs
else:
max_jobs=1
# Carica i pacchetti
from sagemaker.xgboost.estimator import XGBoost
from sagemaker.tuner import IntegerParameter
from sagemaker.tuner import ContinuousParameter
from sagemaker.tuner import HyperparameterTuner
from sagemaker.tuner import WarmStartConfig, WarmStartTypes
# Configura l'avvio rapido
number_of_parent_jobs=1 # Può essere fino a 5, ma attualmente solo il valore 1 è supportato nel codice
# Nota che base_dir deve essere impostato, può anche essere impostato a vuoto
try:
eligible_parent_tuning_jobs=pd.read_csv(f"""{base_dir}logs/tuningjobhistory.csv""")
except:
eligible_parent_tuning_jobs=pd.DataFrame({'datetime':[],'tuningjob':[],'metric':[],'layer':[],'objective':[],'eval_metric':[],'eval_metric_value':[],'trainingjobcount':[]})
eligible_parent_tuning_jobs.to_csv(f"""{base_dir}logs/tuningjobhistory.csv""",index=False)
eligible_parent_tuning_jobs=eligible_parent_tuning_jobs[(eligible_parent_tuning_jobs['layer']==prefix)&(eligible_parent_tuning_jobs['metric']==metric)&(eligible_parent_tuning_jobs['objective']==trainingobjective)&(eligible_parent_tuning_jobs['eval_metric']==objective_metric_name)&(eligible_parent_tuning_jobs['trainingjobcount']>1)].sort_values(by='datetime',ascending=True)
eligible_parent_tuning_jobs_count=len(eligible_parent_tuning_jobs)
if eligible_parent_tuning_jobs_count>0:
parent_tuning_jobs=eligible_parent_tuning_jobs.iloc[(eligible_parent_tuning_jobs_count-(number_of_parent_jobs)):eligible_parent_tuning_jobs_count,1].iloc[0]
warm_start_config = WarmStartConfig(WarmStartTypes.TRANSFER_LEARNING, parents={parent_tuning_jobs})
# Nota che WarmStartTypes.IDENTICAL_DATA_AND_ALGORITHM può essere usato quando applicabile
print(f"""Warm start utilizzando il job di tuning: {parent_tuning_jobs[0]}""")
else:
warm_start_config = None
# Definisci i limiti di esplorazione (valori suggeriti predefiniti dalla documentazione di Amazon SageMaker)
hyperparameter_ranges = {
'eta': ContinuousParameter(0.1, 0.5, scaling_type='Logarithmic'),
'max_depth': IntegerParameter(0,10,scaling_type='Auto'),
'num_round': IntegerParameter(1,4000,scaling_type='Auto'),
'subsample': ContinuousParameter(0.5,1,scaling_type='Logarithmic'),
'colsample_bylevel': ContinuousParameter(0.1, 1,scaling_type="Logarithmic"),
'colsample_bytree': ContinuousParameter(0.5, 1, scaling_type='Logarithmic'),
'alpha': ContinuousParameter(0, 1000, scaling_type="Auto"),
'lambda': ContinuousParameter(0,100,scaling_type='Auto'),
'max_delta_step': IntegerParameter(0,10,scaling_type='Auto'),
'min_child_weight': ContinuousParameter(0,10,scaling_type='Auto'),
'gamma':ContinuousParameter(0, 5, scaling_type='Auto'),
}
tuner_log = HyperparameterTuner(
estimator,
objective_metric_name,
hyperparameter_ranges,
objective_type='Minimize',
max_jobs=max_jobs,
max_parallel_jobs=10,
strategy='Bayesian',
base_tuning_job_name="transferlearning",
warm_start_config=warm_start_config
)
# Nota che è necessario istanziare un estimatore SageMaker XGBoost in advancetraining_input_config
training_input_config = sagemaker.TrainingInput("s3://{}/{}/{}".format(bucket,prefix,filename), content_type='csv')
validation_input_config = sagemaker.TrainingInput("s3://{}/{}/{}".format(bucket,prefix,filename), content_type='csv')
# Nota che gli oggetti/alias bucket, prefix e filename devono essere impostati
# Avvia il job di hyperparameter tuning
tuner_log.fit({'train': training_input_config, 'validation': validation_input_config})
# Stampa lo stato dell'ultimo job di hyperparameter tuning
boto3.client('sagemaker').describe_hyper_parameter_tuning_job(
HyperParameterTuningJobName=tuner_log.latest_tuning_job.job_name)['HyperParameterTuningJobStatus']
La cronologia del job di tuning verrà salvata in un file di log nella directory base, con un esempio di output come segue:
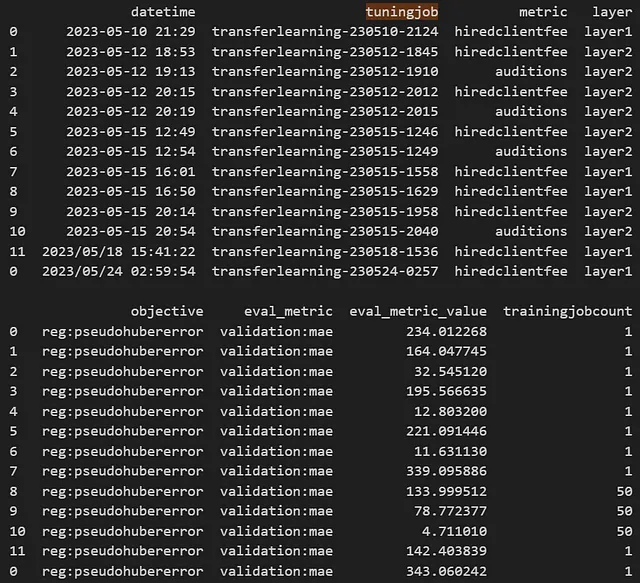
Il timestamp della data/ora, il nome del job di tuning e i metadati sono salvati in formato .csv, con i nuovi lavori di tuning che vengono aggiunti al file.
Il sistema effettuerà un warm start dinamico utilizzando l’ultimo lavoro di tuning che soddisfa le condizioni richieste. In questo esempio le condizioni sono indicate nella seguente riga di codice:
eligible_parent_tuning_jobs=eligible_parent_tuning_jobs[(eligible_parent_tuning_jobs['layer']==prefix)&(eligible_parent_tuning_jobs['metric']==metric)&(eligible_parent_tuning_jobs['objective']==trainingobjective)&(eligible_parent_tuning_jobs['eval_metric']==objective_metric_name)&(eligible_parent_tuning_jobs['trainingjobcount']>1)].sort_values(by='datetime',ascending=True)Per testare che il funzionamento della pipeline sia corretto, è disponibile l’opzione di esecuzione testing=True che forza soltanto un lavoro di tuning degli iperparametri. Viene aggiunta una condizione per considerare soltanto i lavori con un solo modello tarato come genitori, dato che questi lavori erano per il testing. Inoltre, il file di registro dei lavori di tuning può essere utilizzato su modelli differenti, in quanto teoricamente è possibile utilizzare un lavoro genitore su modelli differenti. In questo caso, il modello è tracciato con il campo ‘metric’, e i lavori di tuning idonei sono filtrati per corrispondere alla metrica nell’istanza di addestramento corrente.
Dopo che il riaddestramento è stato completato, verrà quindi aggiunto il file di registro con il nuovo lavoro di tuning degli iperparametri e scritto in locale, oltre che su s3 con la versioning attivata.
# Append Last Parent Job for Next Warm Starteligible_parent_tuning_jobs=pd.read_csv(f"""{base_dir}logs/tuningjobhistory.csv""")latest_tuning_job=boto3.client('sagemaker').describe_hyper_parameter_tuning_job( HyperParameterTuningJobName=tuner_log.latest_tuning_job.job_name)updatetuningjobhistory=pd.concat([eligible_parent_tuning_jobs,pd.DataFrame({'datetime':[datetime.now().strftime("%Y/%m/%d %H:%M:%S")],'tuningjob':[latest_tuning_job['HyperParameterTuningJobName']],'metric':[metric],'layer':prefix,'objective':[trainingobjective],'eval_metric':[latest_tuning_job['BestTrainingJob']['FinalHyperParameterTuningJobObjectiveMetric']['MetricName']],'eval_metric_value':latest_tuning_job['BestTrainingJob']['FinalHyperParameterTuningJobObjectiveMetric']['Value'],'trainingjobcount':[latest_tuning_job['HyperParameterTuningJobConfig']['ResourceLimits']['MaxNumberOfTrainingJobs']]})],axis=0)print(updatetuningjobhistory)# Write locallyupdatetuningjobhistory.to_csv(f"""{base_dir}logs/tuningjobhistory.csv""",index=False)# Upload to s3s3.upload_file(f"""{base_dir}logs/tuningjobhistory.csv""",bucket,'logs/tuningjobhistory.csv')3. Registrare più modelli nel Model Registry in un singolo notebook python interattivo
Spesso, le organizzazioni avranno più account AWS per diversi casi d’uso (ad esempio sandbox, QA e produzione). Sarà necessario determinare quale account utilizzare per ogni passaggio della soluzione CI/CD e aggiungere le autorizzazioni inter-account indicate in questa guida.
La raccomandazione è di effettuare l’addestramento del modello e la registrazione del modello nello stesso account, specificamente in un account sandbox o di testing. Quindi, nella tabella sottostante, l’account ‘Data Science’ e l’account ‘Shared Services’ saranno gli stessi. In questo account sarà necessario un bucket s3 per ospitare gli artefatti del modello e tracciare la linea di discendenza su altri file relativi alla pipeline. I modelli/endpoint saranno implementati separatamente all’interno di ogni account ‘deployment’ (ad esempio sandbox, QA, produzione) facendo riferimento agli artefatti del modello e al registro nel training/registration account.
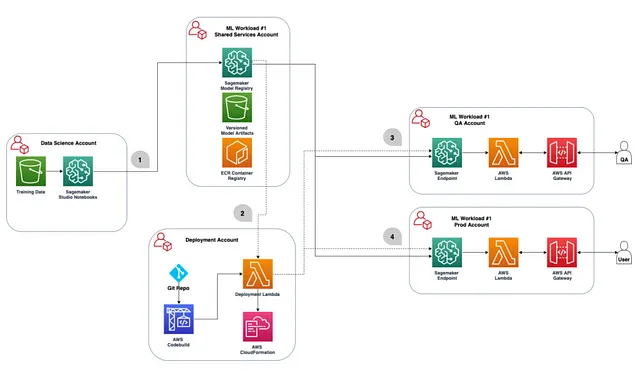
Ora che abbiamo deciso quale account AWS verrà utilizzato per l’addestramento e per ospitare il registro del modello, possiamo ora costruire un modello iniziale e sviluppare la soluzione CI/CD.
Quando si utilizzano le SageMaker Pipelines, vengono creati passaggi di pipeline separati per la pre-elaborazione dei dati, l’addestramento/tuning, la valutazione, la registrazione e qualsiasi post-elaborazione. Sebbene questo sia accettabile per una singola pipeline di modelli, crea molta duplicazione di codice di pipeline quando sono necessari più modelli per una soluzione di machine learning.
Di conseguenza, la soluzione consigliata è invece quella di costruire e pianificare tre notebook python interattivi in SageMaker Studio. Vengono eseguiti in sequenza e insieme completano la pipeline CI/CD una volta automatizzati con un lavoro di notebook:
A. Preparazione dei dati
B. Formazione, valutazione e registrazione del modello
C. Aggiornamento del punto finale con i modelli approvati più recenti
A. Preparazione dei dati
In questa fase interrogheremo e caricheremo i dati dal data warehouse e li scriveremo sia in locale che su s3. Possiamo impostare condizioni dinamiche di data/ora utilizzando la data corrente e passare il risultante pavimento e soffitto della data nella query SQL.
# Collegamento al Data Warehousedbname='<inserisci qui>'host='<inserisci qui>'password='<inserisci qui>'port='<inserisci qui>'search_path='<inserisci qui>'user='<inserisci qui>'import psycopg2data_warehouse= psycopg2.connect(f"""host={host} port={port} dbname={dbname} user={user} password={password} options = '-c search_path={search_path}'""")# Imposta il pavimento e il soffitto della data del dataset da applicare e passare alla querydatestart=date(2000, 1, 1)pushbackdays=30dateend=date.today() - timedelta(days=pushbackdays)print(datestart)print(dateend)# Interroga il data warehousedataset=pd.read_sql_query(f"""<inserisci query>""",data_warehouse)# Scrivi .csvdataset.to_csv(f"{base_dir}datasets/{filename}", index=False)dataset# Carica su s3 per il tracciamento della lineage s3 = boto3.client('s3')s3.upload_file(f"{base_dir}datasets/{filename}",bucket,f"datasets/{filename}")Questa fase si conclude con il salvataggio dei dati preparati per la formazione in locale e su s3 per il tracciamento della lineage.
B. Formazione, valutazione e registrazione del modello
Utilizzando un notebook interattivo di Python in Studio, possiamo ora completare la formazione, la valutazione e la registrazione del modello in un unico notebook. Tutti questi passaggi possono essere incorporati in una funzione e che viene applicata per i modelli aggiuntivi che devono essere nuovamente addestrati. A scopo illustrativo, il codice è stato fornito senza l’utilizzo di una funzione.
Prima di procedere, è necessario creare gruppi di pacchetti di modelli nel Registro (sia nella console che tramite Python) per ciascun modello che fa parte della soluzione.
# Ottieni il Miglior Job di Formazionebest_overall_training_job_name = latest_tuning_job['BestTrainingJob']['TrainingJobName']# latest_tuning_job è stato ottenuto dalla sezione di hyperparameter tuninglatest_tuning_job['BestTrainingJob']# Installa XGBoost! pip install xgboost# Scarica il Miglior Modello S3 = boto3.client('s3')s3.download_file('<bucket s3>', f"""output/{best_overall_training_job_name}/output/model.tar.gz""", f"""{base_dir}models/{metric}/model.tar.gz""")# Apri e Carica l'Artifact del Modello Scaricato in Memoriatar = tarfile.open(f"""{base_dir}models/{metric}/model.tar.gz""")tar.extractall(f"""{base_dir}models/{metric}""")tar.close()model = pkl.load(open(f"""{base_dir}models/{layer}/{metric}/xgboost-model""", 'rb'))# Esegui la Valutazione del Modelloimport jsonimport pathlibimport joblibfrom sklearn.metrics import mean_squared_errorfrom sklearn.metrics import mean_absolute_errorimport mathevaluationset=pd.read_csv(f"""{base_dir}datasets/{layer}/{metric}/{metric}modelbuilding_test.csv""")evaluationset['prediction']=model.predict(xgboost.DMatrix(evaluationset.drop(evaluationset.columns.values[0], axis=1), label=evaluationset[[evaluationset.columns.values[0]]]))# Nell'esempio è stato utilizzato un problema di regressione con MAE & RMSE come metriche di valutazionemae = mean_absolute_error(evaluationset[evaluationset.columns.values[0]], evaluationset['prediction'])rmse = math.sqrt(mean_squared_error(evaluationset[evaluationset.columns.values[0]], evaluationset['prediction']))stdev_error = np.std(evaluationset[evaluationset.columns.values[0]] - evaluationset['prediction'])evaluation_report=pd.DataFrame({'datetime':[datetime.now().strftime("%Y/%m/%d %H:%M:%S")], 'testing':[testing], 'trainingjob': [best_overall_training_job_name], 'objective':[trainingobjective], 'hyperparameter_tuning_metric':[objective_metric_name], 'mae':[mae], 'rmse':[rmse], 'stdev_error':[stdev_error]})# Carica i Report di Valutazione Passatitry: past_evaluation_reports=pd.read_csv(f"""{base_dir}models/{metric}/evaluationhistory.csv""")except: past_evaluation_reports=pd.DataFrame({'datetime':[],'testing':[], 'trainingjob': [], 'objective':[], 'hyperparameter_tuning_metric':[], 'mae':[], 'rmse':[], 'stdev_error':[]})evaluation_report=pd.concat([past_evaluation_reports,evaluation_report],axis=0)print(evaluation_report)# Scrivi .csvevaluation_report.to_csv(f"""{base_dir}models/{metric}/evaluationhistory.csv""",index=False)# Scrivi su s3s3.upload_file(f"""{base_dir}models/{metric}/evaluationhistory.csv""",'<bucket s3>',f"""{layer}/{metric}/evaluationhistory.csv""")# Nota: è anche possibile associare un modello registrato con le metriche di valutazione, ma qui verrà saltatoreport_dict = {}# Registra il Modellomodel_package_group_name='<>'modelpackage_inference_specification = { "InferenceSpecification": { "Containers": [ { "Image": xgboost_container, "ModelDataUrl": f"""s3://{s3 bucket}/output/{best_overall_training_job_name}/output/model.tar.gz""" } ], "SupportedContentTypes": [ "text/csv" ], "SupportedResponseMIMETypes": [ "text/csv" ], } }create_model_package_input_dict = { "ModelPackageGroupName" : model_package_group_name, "ModelPackageDescription" : "<inserisci qui la descrizione>", "ModelApprovalStatus" : "PendingManualApproval", "ModelMetrics" :report_dict}create_model_package_input_dict.update(modelpackage_inference_specification)sm_client = boto3.client('sagemaker')create_model_package_response = sm_client.create_model_package(**create_model_package_input_dict)model_package_arn = create_model_package_response["ModelPackageArn"]print('ModelPackage Version ARN : {}'.format(model_package_arn))Apri il gruppo del pacchetto modello nel registro per visualizzare tutte le versioni del modello che sono state registrate, la data in cui sono state registrate e il loro stato di approvazione.
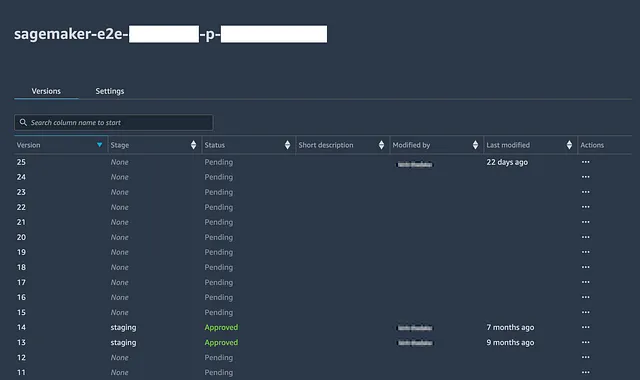
Il supervisore della pipeline può quindi esaminare il rapporto di valutazione salvato localmente nel passaggio precedente, che contiene la cronologia di tutte le valutazioni dei modelli passati, e determinare se desidera approvare o negare il modello in base alle metriche di valutazione del set di test. In seguito, possono essere definiti criteri per aggiornare solo i punti finali di produzione (o QA) con l’ultimo modello se è stato approvato.
4. Aggiornamento di un endpoint multi-modello con nuovi modelli
SageMaker ha una classe MultiDataModel che consente di distribuire i punti finali di SageMaker che possono ospitare più di un modello. Il ragionamento è che più modelli possono essere caricati nella stessa istanza di calcolo, condividendo le risorse e risparmiando costi. Inoltre, semplifica la riqualificazione / amministrazione del modello poiché è necessario riflettere solo un endpoint con i nuovi modelli e gestirlo, rispetto a dover duplicare i passaggi su ogni endpoint dedicato (che può essere fatto come alternativa). La classe MultiDataModel può essere utilizzata anche per distribuire un singolo modello, il che potrebbe avere senso se ci sono piani per aggiungere modelli aggiuntivi alla soluzione in futuro.
Dovremo creare il modello e l’endpoint alla prima esecuzione nell’account di formazione. La classe MultiDataModel richiede una posizione in cui archiviare gli artefatti del modello che possono essere caricati nell’endpoint quando vengono richiamati; di seguito useremo la directory ‘model’ nel bucket s3 utilizzato.
# Carica il contenitorefrom sagemaker.xgboost.estimator import XGBoostxgboost_container = sagemaker.image_uris.retrieve("xgboost", region, "1.2-2")# Una volta sola: Costruisci la classe Multi Modelestimator = sagemaker.estimator.Estimator.attach('sagemaker-xgboost-220611-1453-011-699894eb')xgboost_container = sagemaker.image_uris.retrieve("xgboost", region, "1.2-2")model = estimator.create_model(role=role, image_uri=xgboost_container)from sagemaker.multidatamodel import MultiDataModelsagemaker_session=sagemaker.Session()# Qui è dove il nostro MME leggerà i modelli su S3.model_data_prefix = f"s3://{bucket}/models/"mme = MultiDataModel( name=model_name, model_data_prefix=model_data_prefix, model=model, # passando il nostro modello - passa l'immagine del contenitore necessaria per l'endpoint sagemaker_session=sagemaker_session,)# Una volta sola: Distribuisci il MMEENDPOINT_INSTANCE_TYPE = "ml.m4.xlarge"ENDPOINT_NAME = "<inserisci qui>"predictor = mme.deploy( initial_instance_count=1, instance_type=ENDPOINT_INSTANCE_TYPE, endpoint_name=ENDPOINT_NAME,kms_key='<inserisci qui se desiderato>')Dopo di che, il MultiDataModel può essere referenziato come segue:
model=sagemaker.model.Model(model_name)from sagemaker.multidatamodel import MultiDataModelsagemaker_session=sagemaker.Session()# Qui è dove il nostro MME leggerà i modelli su S3.model_data_prefix = f"s3://{bucket}/models/"mme = MultiDataModel( name=model_name, model_data_prefix=model_data_prefix, model=model, # passando il nostro modello - passa l'immagine del contenitore necessaria per l'endpoint sagemaker_session=sagemaker_session,)I modelli possono essere aggiunti al MultiDataModel copiando l’artefatto nella directory {s3 bucket}/models che l’endpoint utilizzerà per caricare i modelli. Tutto ciò di cui abbiamo bisogno è il nome del gruppo del pacchetto modello e il Registro dei modelli fornirà la relativa posizione dell’artefatto sorgente e lo stato di approvazione.
Possiamo aggiungere una condizione per aggiungere solo l’ultimo modello se è approvato, illustrato di seguito. Questa condizione può essere omessa nell’account sandbox nel caso in cui sia necessaria una distribuzione immediata per la QA della scienza dei dati e per approvare infine il modello.
# Ottieni la versione del modello più recente e la relativa posizione dell'artefatto per un determinato gruppo del pacchetto modelloModelPackageGroup = 'model_package_group'list_model_packages_response = client.list_model_packages(ModelPackageGroupName=f"arn:aws:sagemaker:{region}:{aws_account_id}:model-package-group/{ModelPackageGroup}")list_model_packages_responselatest_model_version_arn = list_model_packages_response["ModelPackageSummaryList"][0][ "ModelPackageArn"]print(latest_model_version_arn)modelpackage=client.describe_model_package(ModelPackageName=latest_model_version_arn)modelpackageartifact_path=modelpackage['InferenceSpecification']['Containers'][0]['ModelDataUrl']artifact_path# Aggiungi il modello se è approvatoif list_model_packages_response["ModelPackageSummaryList"][0]['ModelApprovalStatus']=="Approved": model_artifact_name='<model_name>.tar.gz' mme.add_model(model_data_source=artifact_path, model_data_path=model_artifact_name)Puoi quindi elencare i modelli che sono stati aggiunti con la seguente funzione:
list(mme.list_models())# Output che vedremmo se aggiungessimo i seguenti due modelli['modela.tar.gz','modelb.tar.gz']Per rimuovere un modello, è possibile navigare nella directory s3 associata nella console ed eliminarne uno qualsiasi; saranno scomparsi quando si rielencheranno i modelli disponibili.
Un modello può essere invocato nell’endpoint distribuito una volta che è stato aggiunto utilizzando il seguente codice:
response = runtime_sagemaker_client.invoke_endpoint( EndpointName = "<nome_endpoint>", ContentType = "text/csv", TargetModel = "<nome_modello>.tar.gz", Body = body)Alla prima invocazione di un modello, l’endpoint caricherà il modello di destinazione, risultando in un’ulteriore latenza. Per le future invocazioni in cui il modello è già caricato, le inferenze saranno ottenute immediatamente. Nella guida per lo sviluppatore dell’endpoint multi-modello, AWS nota che i modelli che non sono stati invocati di recente saranno “scaricati” quando l’endpoint raggiunge una soglia di utilizzo della memoria. I modelli saranno quindi ricaricati alla loro prossima invocazione.
4. Aggiornare un endpoint multi-modello con nuovi modelli
Quando un’artefatto di modello esistente viene sovrascritto tramite mme.add_model() o nella console s3, l’endpoint distribuito non verrà riflettuto immediatamente. Per forzare l’endpoint a ricaricare gli ultimi artefatti del modello alla loro prossima invocazione, possiamo utilizzare un trucco per aggiornare l’endpoint con una nuova configurazione di endpoint arbitraria. Questo crea un nuovo endpoint in cui i modelli devono essere caricati e gestisce in modo sicuro la transizione tra il vecchio e il nuovo endpoint. Poiché ogni configurazione di endpoint richiede un nome univoco, possiamo aggiungere un suffisso con il timestamp della data.
# Ottieni la data e l'ora per la configurazione dell'endpointtime=str(datetime.now())[0:10]+'--'+str(datetime.now())[11:13]+'-'+'00'time# Crea una nuova configurazione di endpoint per 'aggiornare' i modelli caricati per tenere conto delle nuove distribuzioni.create_endpoint_config_api_response = client.create_endpoint_config( EndpointConfigName=f"""<nome_endpoint>-{time}""", ProductionVariants=[ { 'VariantName': model_name, 'ModelName': model_name, 'InitialInstanceCount': 1, 'InstanceType': instance_type }, ] )# Aggiorna l'endpoint con la nuova configurazioneresponse = client.update_endpoint( EndpointName=endpoint_name, EndpointConfigName=f"""{model_name}-{time}""")responseUna volta eseguito questo codice, vedrai che l’endpoint associato avrà uno stato di “aggiornamento” quando lo visualizzi nella console. Durante questo periodo di aggiornamento, il precedente endpoint sarà disponibile per l’uso e verrà sostituito con il nuovo endpoint non appena sarà pronto, dopodiché lo stato si adeguerà a “in servizio”. I nuovi modelli aggiunti saranno quindi caricati alla loro prossima invocazione.
Abbiamo ora creato i tre notebook richiesti per la soluzione CI/CD: la preparazione dei dati, la formazione/valutazione e l’aggiornamento dell’endpoint. Tuttavia, questi file sono attualmente solo nell’account AWS di formazione. Dobbiamo adattare il terzo notebook per lavorare in qualsiasi account AWS di distribuzione in cui verrà creato/aggiornato un endpoint rispettivo.
Per fare ciò, possiamo aggiungere una logica condizionale basata sull’ID dell’account AWS. Saranno inoltre necessari secchi s3 nei nuovi account AWS per ospitare gli artefatti del modello. Poiché i nomi dei secchi s3 devono essere univoci in tutta AWS, tale logica condizionale può essere utilizzata per questo. Può anche essere applicata per adattare il tipo di istanza dell’endpoint e le condizioni per l’aggiunta di nuovi modelli (ad esempio, lo stato di approvazione).
# Ottieni l'ID dell'account AWSaws_account_id = boto3.client("sts").get_caller_identity()["Account"]aws_account_id# Imposta il bucket e il tipo di istanza in tutti gli accountif aws_account_id=='<inserisci ID account AWS 1>': bucket='<inserisci nome secchio s3 1>' instance_type='ml.t2.medium'elif aws_account_id=='<inserisci ID account AWS 2>': bucket='<inserisci nome secchio s3 2>' instance_type='ml.t2.medium'elif aws_account_id=='<inserisci ID account AWS 3>': bucket='<inserisci nome secchio s3 3>' instance_type='ml.m5.large'training_account_bucket='<inserisci il nome del secchio s3 dell'account di formazione>'bucket_path = 'https://s3-{}.amazonaws.com/{}'.format(region,bucket)I passaggi per creare e distribuire inizialmente il MultiDataModel dovranno essere ripetuti in ogni nuovo account di distribuzione.
Ora che abbiamo un notebook funzionante che fa riferimento all’ID account AWS e può essere eseguito su diversi account AWS, vorremmo configurare un repository git che contiene questo notebook (e probabilmente gli altri due per il tracciamento della lineage), quindi clonare il repository nei domini SageMaker Studio di questi account. Fortunatamente, con l’integrazione Studio/Git, questi passaggi sono semplici/continui e sono descritti nel seguente documento. In base alla mia esperienza, è consigliabile creare il repository al di fuori di SageMaker Studio e clonarlo all’interno di ciascun dominio dell’account AWS.
Tutte le modifiche future ai notebook possono essere fatte nell’account di formazione e pushate nel repository. Possono quindi essere riflesse negli altri account di distribuzione tirando le modifiche. Assicurarsi di creare un file .gitignore in modo che solo i 3 notebook siano considerati rispetto a qualsiasi file di log o altro; la lineage verrà tracciata in s3. Inoltre, si dovrebbe riconoscere che ogni volta che viene eseguito un notebook, l’output della console cambierà. Per evitare conflitti quando si tirano le modifiche dei file negli altri account di distribuzione, qualsiasi modifica ai file dal momento dell’ultima pull in questi account dovrebbe essere ripristinata prima di tirare gli ultimi aggiornamenti.
5. Pianificare la ri-formazione/ri-deploy dei notebook per eseguirli su un’intervallo di tempo prestabilito
Infine, possiamo programmare tutti e tre i notebook per essere eseguiti contemporaneamente nell’account di formazione. Possiamo usare la nuova funzionalità di lavoro dei notebook SageMaker Studio per farlo. Gli orari dovrebbero essere considerati come dipendenti dall’ambiente/account – ad esempio negli account di distribuzione possiamo creare lavori di notebook separati, ma solo per aggiornare i punti finali con i modelli più recenti e fornire un po’ di tempo di ritardo tra quando i modelli recentemente approvati vengono automaticamente distribuiti negli account sandbox, QA e di produzione. La bellezza è che l’unica parte manuale del processo una volta rilasciata la soluzione diventa l’approvazione/denegazione del modello nel registro. E se qualcosa va storto con un modello appena distribuito, il modello può essere negato nel registro dopo di che il notebook di aggiornamento del punto finale può essere eseguito manualmente per tornare alla versione precedente del modello di produzione, guadagnando tempo per ulteriori indagini. In questo caso, abbiamo impostato il pipeline per essere eseguita su intervalli di tempo prestabiliti (ad esempio mensili/trimestrali), anche se questa soluzione può essere adattata per funzionare in base a condizioni (ad esempio deriva dei dati o riduzione dell’accuratezza del modello di produzione).
Considerazioni finali
CI/CD è attualmente un argomento caldo nello spazio delle operazioni di apprendimento automatico. Questo è giustificato poiché molte volte si pensa meno alla continuità di una soluzione di apprendimento automatico dopo la sua distribuzione iniziale. Per garantire che le soluzioni di apprendimento automatico di produzione siano robuste alla deriva delle covariate e siano sostenibili nel tempo, è necessaria una soluzione CI/CD semplice e flessibile. Fortunatamente, AWS ha rilasciato una serie di nuove funzionalità all’interno del suo ecosistema SageMaker che rende possibile una tale soluzione. Questo articolo mostra un percorso per realizzare con successo questo per una vasta gamma di soluzioni ML personalizzate, richiedendo solo una singola verifica manuale del modello.
Grazie per aver letto! Se ti è piaciuto questo articolo, seguimi per essere informato sui miei nuovi post. Inoltre, sentiti libero di condividere eventuali commenti/suggerimenti.