Modulo di auto-etichettatura per sistemi avanzati di assistenza alla guida basati su deep learning su AWS
Self-labeling module for advanced deep learning-based driving assistance systems on AWS.
Nella visione artificiale (CV), l’aggiunta di tag per identificare gli oggetti di interesse o di bounding box per individuare gli oggetti è chiamata etichettatura. È uno dei compiti preliminari per preparare i dati di addestramento per un modello di deep learning. Centinaia di migliaia di ore di lavoro vengono impiegate per generare etichette di alta qualità da immagini e video per vari casi d’uso di CV. Puoi utilizzare Amazon SageMaker Data Labeling in due modi per creare queste etichette:
- Amazon SageMaker Ground Truth Plus: questo servizio fornisce una forza lavoro esperta addestrata su compiti di apprendimento automatico e può aiutarti a soddisfare i requisiti di sicurezza dei dati, privacy e conformità. Carichi i tuoi dati e il team di Ground Truth Plus crea e gestisce i flussi di lavoro di etichettatura dei dati e la forza lavoro per tuo conto.
- Amazon SageMaker Ground Truth: in alternativa, puoi gestire i tuoi flussi di lavoro di etichettatura dei dati e la forza lavoro per etichettare i dati.
In particolare, per veicoli autonomi basati sull’apprendimento profondo (AV) e sistemi di assistenza avanzata alla guida (ADAS), è necessario etichettare dati complessi multimodali da zero, inclusi flussi sincronizzati di LiDAR, RADAR e telecamere multiple. Ad esempio, la figura seguente mostra una bounding box 3D intorno a un’auto nella visualizzazione Point Cloud per i dati LiDAR, viste ortogonali allineate di LiDAR sui lati e sette diversi flussi di telecamera con etichette proiettate della bounding box.
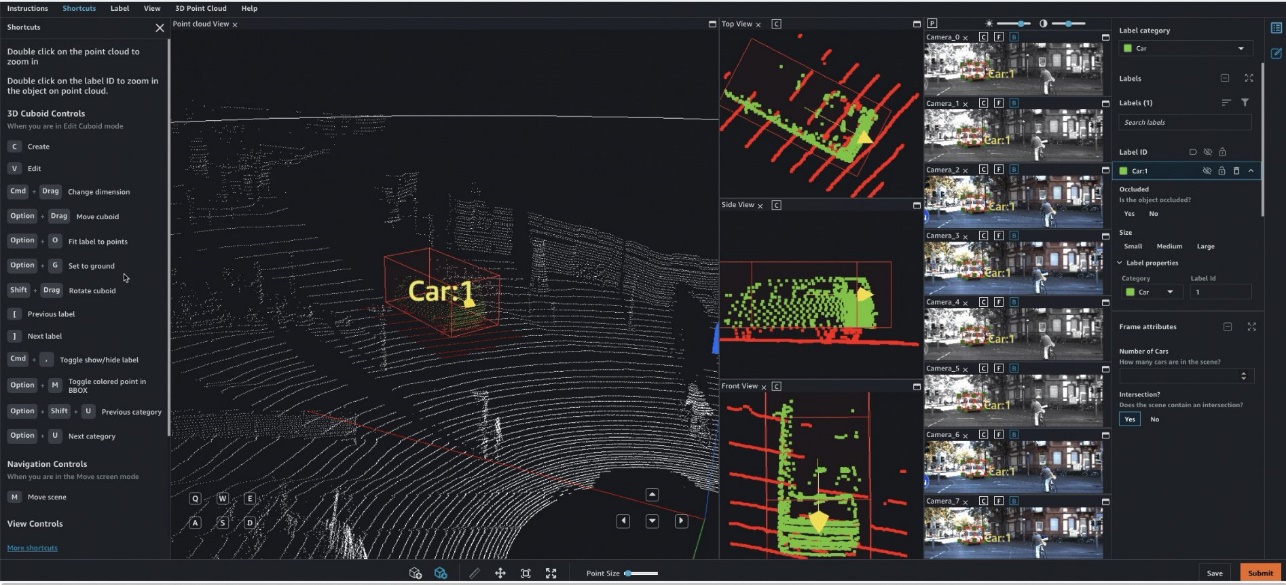
Le squadre AV/ADAS devono etichettare diverse migliaia di frame da zero e fare affidamento su tecniche come la consolidazione delle etichette, la calibrazione automatica, la selezione dei frame, l’interpolazione delle sequenze di frame e l’apprendimento attivo per ottenere un singolo dataset etichettato. Ground Truth supporta queste funzionalità. Per un elenco completo delle funzionalità, consulta le Caratteristiche di Amazon SageMaker Data Labeling. Tuttavia, può essere impegnativo, costoso e richiedere molto tempo etichettare decine di migliaia di miglia di video registrati e dati LiDAR per le aziende che si occupano di creare sistemi AV/ADAS. Una tecnica utilizzata per risolvere questo problema oggi è l’auto-etichettatura, che è evidenziata nel seguente diagramma per un design di funzioni modulari per ADAS su AWS.
- I Tre Metodi Essenziali per Valutare un Nuovo Modello di Linguaggio
- AI vs. Analisi Predittiva Un’Analisi Approfondita
- Cosa succede se si esegue un modello Transformer con una rete neurale ottica?

In questo post, illustreremo come utilizzare le funzionalità di SageMaker, come i modelli di Amazon SageMaker JumpStart e le capacità di inferenza asincrona insieme alla funzionalità di Ground Truth per eseguire l’auto-etichettatura.
Panoramica dell’auto-etichettatura
L’auto-etichettatura (talvolta indicata come pre-etichettatura) avviene prima o contemporaneamente ai compiti di etichettatura manuale. In questo modulo, il modello finora migliore addestrato per un determinato compito (ad esempio, rilevamento dei pedoni o segmentazione delle corsie) viene utilizzato per generare etichette di alta qualità. Gli etichettatori manuali semplicemente verificano o regolano le etichette create automaticamente dal dataset risultante. Questo è più semplice, veloce ed economico rispetto all’etichettatura di questi ampi dataset da zero. Moduli successivi, come i moduli di addestramento o di convalida, possono utilizzare queste etichette così come sono.
L’apprendimento attivo è un altro concetto strettamente correlato all’auto-etichettatura. È una tecnica di apprendimento automatico (ML) che identifica i dati che dovrebbero essere etichettati dai tuoi lavoratori. La funzionalità di etichettatura automatica dei dati di Ground Truth è un esempio di apprendimento attivo. Quando Ground Truth avvia un lavoro di etichettatura automatica dei dati, seleziona un campione casuale di oggetti di dati di input e li invia ai lavoratori umani. Quando i dati etichettati vengono restituiti, vengono utilizzati per creare un set di addestramento e un set di convalida. Ground Truth utilizza questi set di dati per addestrare e convalidare il modello utilizzato per l’auto-etichettatura. Ground Truth quindi esegue un lavoro di trasformazione batch per generare etichette per i dati non etichettati, insieme a punteggi di affidabilità per i nuovi dati. I dati etichettati con punteggi di affidabilità bassi vengono inviati agli etichettatori umani. Questo processo di addestramento, convalida e trasformazione batch viene ripetuto fino a quando l’intero dataset è etichettato.
In contrasto, l’auto-etichettatura presume l’esistenza di un modello pre-addestrato di alta qualità (sia all’interno dell’azienda, sia pubblicamente in un hub). Questo modello viene utilizzato per generare etichette affidabili utilizzabili per compiti successivi come verificare le etichette, l’addestramento o la simulazione. Questo modello pre-addestrato nel caso dei sistemi AV/ADAS viene implementato sul veicolo al bordo ed è utilizzato in lavori di inferenza batch su larga scala nel cloud per generare etichette di alta qualità.
JumpStart fornisce modelli preaddestrati open source per una vasta gamma di tipi di problemi per aiutarti a iniziare con l’apprendimento automatico. Puoi utilizzare JumpStart per condividere modelli all’interno della tua organizzazione. Cominciamo!
Panoramica della soluzione
In questo post, delineiamo i passaggi principali senza analizzare ogni cella nel nostro notebook di esempio. Per seguire o provarlo autonomamente, è possibile eseguire il notebook Jupyter in Amazon SageMaker Studio.
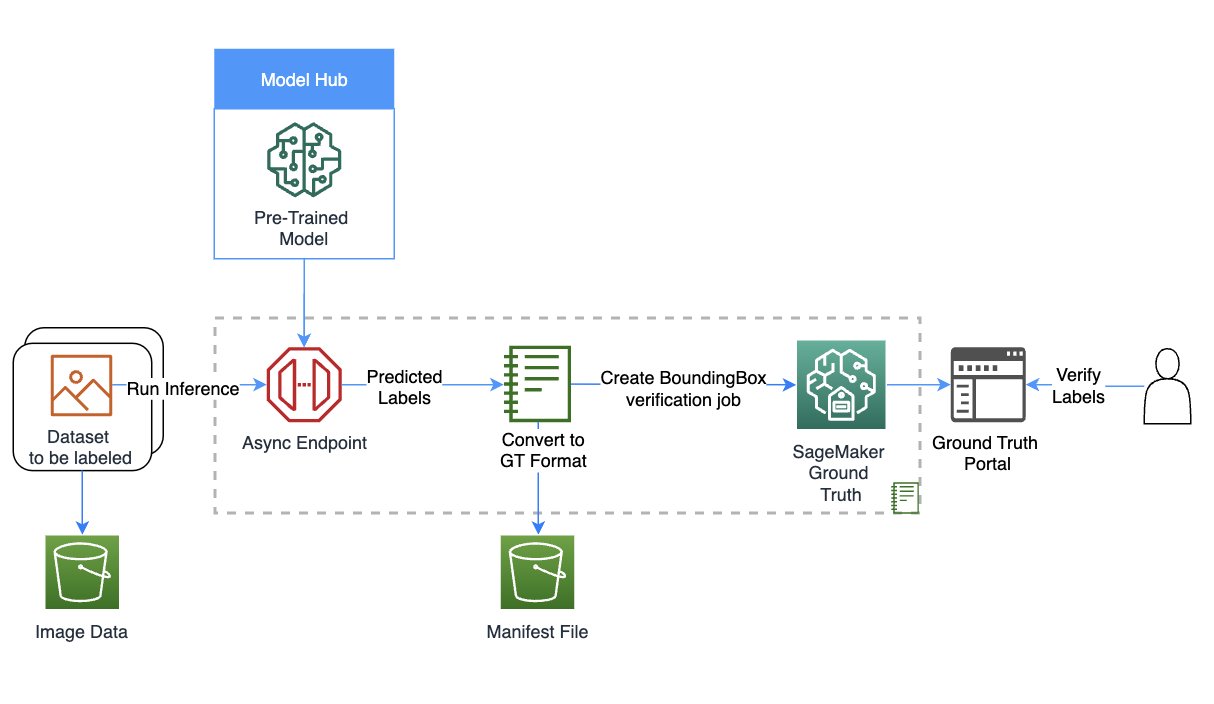
Il seguente diagramma fornisce una panoramica della soluzione.
Configurazione del ruolo e della sessione
In questo esempio, abbiamo utilizzato un kernel Data Science 3.0 in Studio su un’istanza di tipo ml.m5.large. Innanzitutto, effettuiamo alcuni import di base e configuriamo il ruolo e la sessione per l’utilizzo successivo nel notebook:
import sagemaker, boto3, json
from sagemaker import get_execution_role
from utils import *Crea il tuo modello utilizzando SageMaker
In questo passaggio, creiamo un modello per il task di auto-etichettatura. Puoi scegliere tra tre opzioni per creare un modello:
- Crea un modello da JumpStart – Con JumpStart, possiamo eseguire l’inferenza sul modello pre-addestrato, anche senza effettuare un fine-tuning su un nuovo dataset
- Utilizza un modello condiviso tramite JumpStart con il tuo team o organizzazione – Puoi utilizzare questa opzione se desideri utilizzare un modello sviluppato da uno dei team all’interno della tua organizzazione
- Utilizza un endpoint esistente – Puoi utilizzare questa opzione se hai già distribuito un modello esistente nel tuo account
Per utilizzare la prima opzione, selezioniamo un modello da JumpStart (qui, utilizziamo mxnet-is-mask-rcnn-fpn-resnet101-v1d-coco. Un elenco di modelli è disponibile nel file models_manifest.json fornito da JumpStart.
Utilizziamo questo modello JumpStart che è pubblicamente disponibile ed addestrato sul task di segmentazione dell’istanza, ma sei libero di utilizzare anche un modello privato. Nel codice seguente, utilizziamo image_uris, model_uris e script_uris per recuperare i valori dei parametri corretti da utilizzare in questo modello MXNet nell’API sagemaker.model.Model per creare il modello:
from sagemaker import image_uris, model_uris, script_uris, hyperparameters
from sagemaker.model import Model
from sagemaker.predictor import Predictor
from sagemaker.utils import name_from_base
endpoint_name = name_from_base(f"jumpstart-example-infer-{model_id}")
inference_instance_type = "ml.p3.2xlarge"
# Recupera l'URI del container Docker per l'inferenza
deploy_image_uri = image_uris.retrieve(
region=None,
framework=None, # determinato automaticamente da model_id
image_scope="inference",
model_id=model_id,
model_version=model_version,
instance_type=inference_instance_type,
)
# Recupera l'URI dello script di inferenza. Questo include gli script per il caricamento del modello, la gestione dell'inferenza, ecc.
deploy_source_uri = script_uris.retrieve(
model_id=model_id, model_version=model_version, script_scope="inference"
)
# Recupera l'URI del modello di base
base_model_uri = model_uris.retrieve(
model_id=model_id, model_version=model_version, model_scope="inference"
)
# Crea l'istanza del modello SageMaker
model = Model(
image_uri=deploy_image_uri,
source_dir=deploy_source_uri,
model_data=base_model_uri,
entry_point="inference.py", # file di ingresso nel source_dir e presente in deploy_source_uri
role=aws_role,
predictor_cls=Predictor,
name=endpoint_name,
)Configura l’inferenza asincrona e il ridimensionamento
Qui configuriamo una configurazione di inferenza asincrona prima di distribuire il modello. Abbiamo scelto l’inferenza asincrona perché può gestire dimensioni di payload elevate e può soddisfare i requisiti di latenza quasi in tempo reale. Inoltre, è possibile configurare l’endpoint per ridimensionare automaticamente e applicare una policy di ridimensionamento per impostare il conteggio delle istanze a zero quando non ci sono richieste da elaborare. Nel codice seguente, impostiamo max_concurrent_invocations_per_instance su 4. Configuriamo anche il ridimensionamento automatico in modo che l’endpoint si ridimensioni quando necessario e si riduca a zero dopo che il lavoro di auto-etichettatura è completo.
from sagemaker.async_inference.async_inference_config import AsyncInferenceConfig
async_config = AsyncInferenceConfig(
output_path=f"s3://{sess.default_bucket()}/asyncinference/output",
max_concurrent_invocations_per_instance=4)
.
.
.
response = client.put_scaling_policy(
PolicyName="Invocations-ScalingPolicy",
ServiceNamespace="sagemaker", # Il namespace del servizio AWS che fornisce la risorsa.
ResourceId=resource_id, # Nome dell'endpoint
ScalableDimension="sagemaker:variant:DesiredInstanceCount", # SageMaker supporta solo il conteggio delle istanze
PolicyType="TargetTrackingScaling", # 'StepScaling'|'TargetTrackingScaling'
TargetTrackingScalingPolicyConfiguration={
"TargetValue": 5.0, # Il valore target per la metrica. - qui la metrica è - SageMakerVariantInvocationsPerInstance
"CustomizedMetricSpecification": {
"MetricName": "ApproximateBacklogSizePerInstance",
"Namespace": "AWS/SageMaker",
"Dimensions": [{"Name": "EndpointName", "Value": endpoint_name}],
"Statistic": "Average",
},
"ScaleInCooldown": 300,
"ScaleOutCooldown": 300
},
)Scarica i dati ed esegui l’elaborazione
Utilizziamo il dataset stagionale Ford Multi-AV dal Catalogo dei dati aperti di AWS.
Prima di tutto, scarichiamo e prepariamo i dati per l’elaborazione. Abbiamo fornito i passaggi di preprocessing per elaborare il dataset nel notebook; puoi modificarlo per elaborare il tuo dataset. Quindi, utilizzando l’API di SageMaker, possiamo avviare il lavoro di elaborazione asincrona come segue:
import glob
import time
max_images = 10
input_locations,output_locations, = [], []
for i, file in enumerate(glob.glob("data/processedimages/*.png")):
input_1_s3_location = upload_image(sess,file,sess.default_bucket())
input_locations.append(input_1_s3_location)
async_response = base_model_predictor.predict_async(input_path=input_1_s3_location)
output_locations.append(async_response.output_path)
if i > max_images:
breakQuesto potrebbe richiedere fino a 30 minuti o più a seconda della quantità di dati che hai caricato per l’elaborazione asincrona. Puoi visualizzare una di queste elaborazioni come segue:
plot_response('data/single.out')
Converti l’output dell’elaborazione asincrona in un manifesto di input per Ground Truth
In questa fase, creiamo un manifesto di input per un lavoro di verifica delle bounding box in Ground Truth. Carichiamo il template dell’interfaccia utente di Ground Truth e il file delle categorie di etichette, e creiamo il lavoro di verifica. Il notebook collegato a questo post utilizza una forza lavoro privata per eseguire l’etichettatura; puoi modificarla se stai usando altri tipi di forza lavoro. Per ulteriori dettagli, fare riferimento al codice completo nel notebook.
Verifica le etichette dal processo di etichettatura automatica in Ground Truth
In questa fase, completiamo la verifica accedendo al portale di etichettatura. Per ulteriori dettagli, fare riferimento a qui .
Quando accedi al portale come membro della forza lavoro, potrai vedere le bounding box create dal modello JumpStart e apportare eventuali modifiche necessarie.

Puoi utilizzare questo modello per ripetere l’etichettatura automatica con molti modelli specifici per compiti, unire potenzialmente le etichette e utilizzare il dataset etichettato risultante in compiti successivi.
Pulizia
In questa fase, effettuiamo la pulizia eliminando l’endpoint e il modello creati nei passaggi precedenti:
# Elimina l'endpoint di SageMaker
base_model_predictor.delete_model()
base_model_predictor.delete_endpoint()Conclusione
In questo post, abbiamo illustrato un processo di etichettatura automatica che coinvolge JumpStart e l’elaborazione asincrona. Abbiamo utilizzato i risultati del processo di etichettatura automatica per convertire e visualizzare i dati etichettati su un dataset del mondo reale. Puoi utilizzare la soluzione per eseguire l’etichettatura automatica con molti modelli specifici per compiti, unire potenzialmente le etichette e utilizzare il dataset etichettato risultante in compiti successivi. Puoi anche esplorare l’uso di strumenti come il Modello Segment Anything per generare maschere di segmento come parte del processo di etichettatura automatica. Nei futuri post di questa serie, tratteremo il modulo di percezione e la segmentazione. Per ulteriori informazioni su JumpStart e l’elaborazione asincrona, fare riferimento a SageMaker JumpStart e Elaborazione asincrona , rispettivamente. Ti incoraggiamo a riutilizzare questo contenuto per casi d’uso al di là di AV/ADAS e a contattare AWS per qualsiasi aiuto.






