Approcci di Apprendimento In-Context in Modelli di Lingua di Grandi Dimensioni
'In-Context Learning Approaches in Large-scale Language Models'
Tecniche semplici e potenti per far sì che le LLM apprendano nuovi compiti al momento dell’inferenza
Introduzione
La modellizzazione del linguaggio (LM) mira a modellare la probabilità generativa delle sequenze di parole, al fine di prevedere le probabilità dei token futuri (o mancanti). I modelli di linguaggio hanno rivoluzionato l’elaborazione del linguaggio naturale (NLP) negli ultimi anni. Ora è ben noto che aumentare la scala dei modelli di linguaggio (ad esempio, la potenza di calcolo di addestramento, i parametri del modello, ecc.) può portare a una migliore performance e a una maggiore efficienza di campionamento su una serie di compiti NLP successivi. L’articolo di revisione “A Survey of Large Language Models” [1] copre quasi ogni aspetto dei grandi modelli di linguaggio. L’articolo fornisce una rassegna aggiornata della letteratura sui LLM, dettagli sui meccanismi di addestramento come gli approcci di pre-training insieme alle tecniche di tuning delle istruzioni e ulteriori addestramenti di allineamento con l’approccio RLHF recente. Gli approcci di tuning delle istruzioni e di allineamento vengono utilizzati per adattare le LLM in base agli obiettivi specifici.
Dopo il pre-training o l’adattamento, un approccio principale per utilizzare le LLM è quello di progettare strategie di prompt adatte per risolvere vari compiti. Un tipico metodo di prompt, noto anche come apprendimento in contesto (ICL), formula la descrizione del compito e/o le dimostrazioni (esempi) sotto forma di testo in linguaggio naturale.
Apprendimento in Contesto
Le LLM dimostrano la capacità di apprendimento in contesto (ICL), ovvero l’apprendimento da alcuni esempi nel contesto. Molti studi hanno dimostrato che le LLM possono svolgere una serie di compiti complessi attraverso l’ICL, come risolvere problemi di ragionamento matematico.
La chiave dell’apprendimento in contesto è imparare per analogia. La figura di seguito mostra un esempio che descrive come i modelli di linguaggio prendono decisioni con l’ICL. Innanzitutto, l’ICL richiede alcuni esempi per formare un contesto di dimostrazione. Questi esempi sono generalmente scritti in modelli di linguaggio naturale. Quindi, l’ICL concatena una domanda di query e un pezzo di contesto di dimostrazione per formare un prompt, che viene quindi alimentato nel modello di linguaggio per la previsione [2].
- Contextual AI presenta LENS un framework di intelligenza artificiale per modelli di linguaggio potenziati dalla visione che supera Flamingo del 9% (56->65%) su VQAv2.
- Con cinque nuovi modelli multimodali attraverso le scale 3B, 4B e 9B, il team di OpenFlamingo rilascia OpenFlamingo v2 che supera il modello precedente.
- Unity annuncia il rilascio di Muse una piattaforma di giochi di testo-a-video che ti permette di creare texture, sprite e animazioni con il linguaggio naturale.
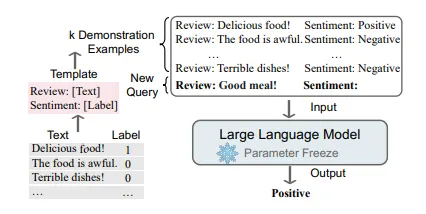
Diversamente dall’apprendimento supervisionato che richiede una fase di addestramento che utilizza gradienti inversi per aggiornare i parametri del modello, l’ICL non effettua aggiornamenti dei parametri e esegue direttamente previsioni sui modelli di linguaggio pre-addestrati. Si prevede che il modello impari il pattern nascosto nella dimostrazione e faccia la previsione corretta di conseguenza.
Cosa rende l’ICL interessante?
- Gli esempi scritti in linguaggio naturale forniscono un’interfaccia interpretabile per comunicare con le LLM. Questo paradigma rende molto più facile incorporare la conoscenza umana nelle LLM attraverso la modifica degli esempi e dei modelli.
- È simile al processo decisionale degli esseri umani attraverso l’apprendimento per analogia.
- Rispetto all’addestramento supervisionato, l’ICL è un framework di apprendimento senza addestramento. Questo non solo riduce notevolmente i costi di calcolo per adattare il modello a nuovi compiti, ma rende anche possibile il modello di linguaggio come servizio e può essere facilmente applicato a compiti reali su larga scala.
Ma come funziona questo?
Dopo il pre-training, le LLM possono mostrare interessanti capacità di ICL (capacità emergenti) senza essere aggiornate [3]. Sebbene intuitivamente ragionevole, il meccanismo di funzionamento dell’ICL rimane poco chiaro e pochi studi hanno fornito spiegazioni preliminari per le due domande.
Come il pre-training influenza la capacità di ICL?
Ricercatori hanno suggerito che un modello pre-addestrato acquisisce alcune capacità emergenti di ICL quando raggiunge una grande quantità di passi di pre-training o parametri del modello [3]. Alcuni studi hanno anche mostrato che la capacità di ICL cresce all’aumentare dei parametri delle LLM da 0,1 miliardi a 175 miliardi. Le ricerche suggeriscono che la progettazione dei compiti di addestramento è un importante fattore di influenza sulla capacità di ICL delle LLM. Oltre ai compiti di addestramento, studi recenti hanno anche indagato la relazione tra ICL e le corpora di pre-training. È stato dimostrato che le prestazioni dell’ICL dipendono pesantemente dalla fonte delle corpora di pre-training piuttosto che dalla scala.
Come le LLM eseguono l’ICL durante l’inferenza?
Nell’articolo “Why Can GPT Learn In-Context?” [4], i ricercatori hanno individuato una forma duale tra l’attenzione del Transformer e la discesa del gradiente e hanno proposto di comprendere l’ICL come un fine-tuning implicito. Hanno confrontato l’ICL basato su GPT e il fine-tuning esplicito su compiti reali e hanno scoperto che l’ICL si comporta in modo simile al fine-tuning da molteplici prospettive. In questo framework, il processo di ICL può essere spiegato nel seguente modo: mediante il calcolo in avanti, le LLM generano meta-gradienti rispetto alle dimostrazioni e eseguono implicitamente la discesa del gradiente tramite il meccanismo di attenzione.
Un’altra prospettiva dalla ricerca di Stanford [5] spiega ‘L’apprendimento in contesto come inferenza bayesiana implicita’. Gli autori forniscono un framework in cui l’LM effettua l’apprendimento in contesto utilizzando il prompt per “individuare” il concetto rilevante appreso durante la preformazione per svolgere il compito. Possiamo teoricamente considerare questo come inferenza bayesiana di un concetto latente condizionato al prompt, e questa capacità deriva dalla struttura (coerenza a lungo termine) dei dati di preformazione.
Anche se ci sono alcune risposte, questa ricerca è ancora in evoluzione per comprendere meglio il meccanismo e le ragioni sottostanti.
Approcci di apprendimento in contesto
Ora esploriamo alcuni metodi di ICL popolari.
- Chain of thought (COT)
- COT di auto-coerenza
- Albero dei pensieri
Chain of thought (COT)
Si è osservato che le tecniche di prompting standard (note anche come prompt di input-output generale) non si comportano bene in compiti di ragionamento complessi, come il ragionamento aritmetico, il ragionamento del buon senso e il ragionamento simbolico. CoT è una strategia di prompting migliorata per potenziare le prestazioni degli LLM in tali casi non banali che coinvolgono il ragionamento [6]. Invece di costruire semplicemente i prompt con coppie input-output come in ICL, CoT incorpora passaggi di ragionamento intermedi che possono portare all’output finale nei prompt. Come si può vedere dall’esempio qui sotto.
![Riferimento[6]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*D4AEQft-b2VmXb07dIVONg.png)
La figura sopra mostra un esempio di un modello che produce una catena di pensieri per risolvere un problema di matematica che altrimenti avrebbe sbagliato. Sul lato sinistro, in ICL, al modello vengono forniti esempi o dimostrazioni di domande di ragionamento matematico e una risposta diretta. Ma il modello non è in grado di prevedere la risposta corretta.
Sul lato destro, in COT, al modello viene presentato un passaggio intermedio per aiutare a ottenere una risposta all’esempio/dimostrazione fornita. Possiamo vedere che quando un modello viene ora posto una domanda di ragionamento simile, è in grado di prevedere correttamente la risposta, dimostrando così l’efficacia dell’approccio COT per tali casi d’uso.
Se si guarda, COT o ICL in generale forniscono alcuni esempi per dimostrare i casi d’uso, questo è chiamato Few-Shot (pochi esempi). C’è un altro articolo [7] che ha evidenziato un interessante prompting “Pensiamo passo dopo passo..” senza alcun esempio per dimostrare il caso d’uso, questo è chiamato Zero-shot (nessun esempio).
In Zero-shot CoT, LLM viene prima sollecitato da “Pensiamo passo dopo passo” per generare passaggi di ragionamento e quindi sollecitato da “Pertanto, la risposta è” per ottenere la risposta finale. Hanno scoperto che tale strategia potenzia notevolmente le prestazioni quando la dimensione del modello supera una certa dimensione, ma non è efficace con modelli di piccola scala, mostrando un significativo modello di abilità emergenti.
![Riferimento[7]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*l7oj25kVU6ALI5IbBb2BUA.png)
Figura sopra: Esempi di input e output di GPT-3 con (a) Few-shot standard (ICL), (b) Few-shot-CoT, (c) Zero-shot standard (ICL), e (d) il nostro (Zero-shot-CoT).
Similmente a Few-shot-CoT, Zero-shot-CoT facilita il ragionamento a più passaggi (testo in blu) e raggiunge la risposta corretta dove il prompting standard fallisce. A differenza di Few-shot-CoT che utilizza esempi di ragionamento passo dopo passo per compito, Zero-Shot non ha bisogno di alcun esempio e utilizza semplicemente lo stesso prompt “Pensiamo passo dopo passo” per tutti i compiti (aritmetica, simbolica, ragionamento del buon senso e altri compiti di ragionamento logico).
Questa ricerca mostra che gli LLM sono ragionatori zero-shot decenti aggiungendo un semplice prompt, Pensiamo passo dopo passo, per facilitare il pensiero passo dopo passo prima di rispondere ad ogni domanda.
Vediamo cosa succede sotto:
Anche se Zero-shot-CoT è concettualmente semplice, utilizza il prompting due volte per estrarre sia il ragionamento che la risposta, come spiegato nella figura qui sotto.
![Riferimento[7]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*VvezFJ4L5Ur1he-qT8scAg.png)
Il processo prevede due passaggi: prima l’estrazione del “prompt di ragionamento” per estrarre un percorso completo di ragionamento da un modello di linguaggio, e poi l’utilizzo del secondo “prompt di risposta” per estrarre la risposta nel formato corretto dal testo di ragionamento.
1° prompt – estrazione del ragionamento
In questo passaggio, si modifica prima la domanda di input x in un prompt x’ utilizzando un semplice template “Q: [X]. A: [T]”, dove [X] è uno slot di input per x e [T] è uno slot per una frase di innesco artigianale t che estrarrà la catena di pensiero per rispondere alla domanda x. Ad esempio, se si utilizza “Pensiamo passo dopo passo” come frase di innesco, il prompt x’ sarà “Q: [X]. A: Pensiamo passo dopo passo.”. Il testo del prompt x’ viene quindi inserito in un modello di linguaggio e genera la frase successiva z. È possibile utilizzare qualsiasi strategia di decodifica.
Alcuni altri esempi di tali prompt:
Pensiamo a questo logicamente.
Risolviamo questo problema suddividendolo in passaggi.
Pensiamo come un detective passo dopo passo.
Prima di immergerci nella risposta.
2° prompt – estrazione della risposta
Nel secondo passaggio, la frase generata z insieme alla frase di prompt x’ viene utilizzata per estrarre la risposta finale dal modello di linguaggio. Per essere concreti, si concatenano semplicemente tre elementi come ” [X’] [Z] [A]: [X’] ” per il 1° prompt x’, [Z] per la frase z generata nel primo passaggio, e [A] per una frase di innesco per estrarre la risposta. Il prompt per questo passaggio è auto-aumentato poiché il prompt contiene la frase z generata dallo stesso modello di linguaggio. Negli esperimenti, gli autori utilizzano un innesco di risposta leggermente diverso a seconda del formato della risposta.
Ad esempio, si utilizza “Pertanto, tra A ed E, la risposta è” per una domanda a scelta multipla, e “Pertanto, la risposta (numeri arabi) è” per problemi matematici che richiedono una risposta numerica.
L’articolo [11] propone idee interessanti, le performance di vari prompt, ecc., per ulteriori dettagli si prega di leggere.
Quando CoT funziona per LLM?
Ha un effetto positivo solo su modelli sufficientemente grandi (ad esempio, tipicamente contenenti 10 miliardi o più parametri), ma non su modelli piccoli. Questo fenomeno è chiamato “abilità emergenti” dei grandi modelli di linguaggio. Un’abilità è considerata emergente se non è presente nei modelli più piccoli, ma è presente nei modelli più grandi [3].
- È principalmente efficace per migliorare i compiti che richiedono un ragionamento passo-passo, come il ragionamento aritmetico, il ragionamento del buonsenso e il ragionamento simbolico.
- Per altri compiti che non si basano su un ragionamento complesso, potrebbe mostrare una performance peggiore rispetto allo standard. È interessante notare che sembra che il guadagno in performance ottenuto tramite CoT prompting possa essere significativo solo quando il prompting standard produce risultati scadenti.
Perché i LLM possono eseguire il ragionamento CoT?
- Si ipotizza ampiamente che ciò possa essere attribuito all’addestramento sul codice, poiché i modelli addestrati su di esso mostrano una forte capacità di ragionamento. Intuitivamente, i dati del codice sono ben organizzati con una logica algoritmica e un flusso di programmazione, che potrebbero essere utili per migliorare le prestazioni di ragionamento dei LLM. Tuttavia, questa ipotesi manca ancora di prove pubblicamente riportate di esperimenti di ablazione (con e senza addestramento sul codice).
- La principale distinzione tra il prompting CoT e il prompting standard è l’incorporazione dei percorsi di ragionamento prima della risposta finale. Pertanto, alcuni ricercatori investigano l’effetto dei diversi componenti nei percorsi di ragionamento. In particolare, uno studio recente identifica tre componenti chiave nel prompting CoT, ovvero simboli (ad esempio, quantità numeriche nel ragionamento aritmetico), pattern (ad esempio, equazioni nel ragionamento aritmetico) e testo (cioè il resto dei token che non sono simboli o pattern). Si è dimostrato che gli ultimi due componenti (cioè pattern e testo) sono essenziali per le prestazioni del modello, e la rimozione di uno dei due porterebbe a una significativa diminuzione delle prestazioni.
In sintesi, si tratta di un’area di ricerca attiva. Per una discussione approfondita su questo argomento, si prega di leggere [2]. C’è una ricerca interessante [8] che discute possibili ragioni per l’apprendimento in contesto nei modelli di trasformatori.
Self-consistency COT
Invece di utilizzare la strategia di decodifica greedy in COT, gli autori in [9] propongono un’altra strategia di decodifica chiamata self-consistency per sostituire la strategia di decodifica greedy utilizzata nella catena di pensiero, che migliora ulteriormente le prestazioni di ragionamento dei modelli linguistici in modo significativo. Self-consistency sfrutta l’intuizione che compiti di ragionamento complessi ammettono tipicamente percorsi di ragionamento multipli che conducono a una risposta corretta. Più è richiesto pensiero e analisi deliberata per un problema, maggiore è la diversità dei percorsi di ragionamento che possono recuperare la risposta.
Prima, fornisci al modello linguistico una catena di pensiero come prompt, quindi invece di decodificare in modo greedy il percorso di ragionamento ottimale, gli autori propongono una procedura di decodifica chiamata “sample-and-marginalize”.
La figura di seguito illustra il metodo self-consistency con un esempio.
![Reference[9]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*aHxtX5BCVcJ5rHaqB1aHaw.png)
Prima di tutto, campiona dal decoder del modello linguistico per generare un insieme diversificato di percorsi di ragionamento; ogni percorso di ragionamento potrebbe condurre a una risposta finale diversa, quindi determina la risposta ottimale marginalizzando i percorsi di ragionamento campionati per trovare la risposta più coerente nell’insieme finale di risposte. In altre parole, dal decoder del modello, prendendo una maggioranza di voti sulle risposte, arriviamo alla risposta più “coerente” tra l’insieme finale di risposte.
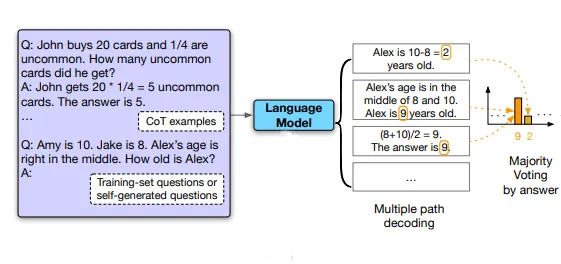
Tale approccio è analogo all’esperienza umana secondo cui se molteplici modi diversi di pensare portano alla stessa risposta, si ha maggiore fiducia che la risposta finale sia corretta. Rispetto ad altri metodi di decodifica, self-consistency evita la ripetitività e l’ottimalità locale che affliggono la decodifica greedy, mitigando allo stesso tempo la stocasticità di una singola generazione campionata.
Un’ampia valutazione empirica mostra che self-consistency migliora le prestazioni della catena di pensiero con un margine sorprendente su una serie di benchmark di ragionamento aritmetico e di buon senso, tra cui GSM8K (+17,9%), SVAMP (+11,0%), AQuA (+12,2%), StrategyQA (+6,4%) e ARC-challenge (+3,9%).
Un limite di self-consistency è che comporta un costo computazionale maggiore. Nella pratica, le persone possono provare un piccolo numero di percorsi (ad esempio, 5 o 10) come punto di partenza per ottenere la maggior parte dei vantaggi senza incorrere in troppi costi, poiché nella maggior parte dei casi le prestazioni saturano rapidamente.
Albero dei pensieri
Gli autori in [10] propongono “Albero dei pensieri” (ToT), che generalizza l’approccio “Catena dei pensieri” per promuovere i modelli linguistici e consente di esplorare unità coerenti di testo (“pensieri”) che fungono da passaggi intermedi verso la risoluzione dei problemi. ToT consente ai modelli linguistici di prendere decisioni deliberate considerando percorsi di ragionamento multipli e valutando autonomamente le scelte per decidere il prossimo passo da compiere, oltre a guardare avanti o tornare indietro quando necessario per prendere decisioni globali. I risultati/esperimenti mostrano che ToT potenzia significativamente le capacità di risoluzione dei problemi dei modelli linguistici su tre nuovi compiti che richiedono pianificazione o ricerca non banale: Gioco del 24, Scrittura creativa e Mini Cruciverba.
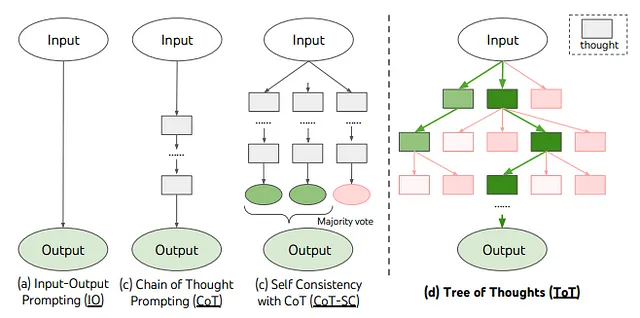
Albero dei pensieri (ToT) consente ai modelli linguistici di esplorare percorsi di ragionamento multipli sui pensieri (figura sopra). ToT riconduce qualsiasi problema a una ricerca su un albero, in cui ogni nodo è uno stato s = [x, z1···i] che rappresenta una soluzione parziale con l’input x e la sequenza di pensieri finora zi. ToT fa 4 cose: decomposizione dei pensieri, generatore di pensieri, valutatore di stato e algoritmo di ricerca.
1. Decomposizione dei pensieri: Decomporre il processo intermedio in passaggi di pensiero:
Mentre CoT campiona pensieri in modo coerente senza decomposizione esplicita, ToT sfrutta le proprietà del problema per progettare e decomporre i passaggi del pensiero intermedi. Come mostra la Tabella 1, a seconda dei diversi problemi, un pensiero potrebbe essere un paio di parole (Cruciverba), una linea di equazione (Gioco del 24), o un intero paragrafo di piano di scrittura (Scrittura creativa). È come dividere la domanda in diverse attività. Ogni attività è uno step Zn che discutiamo. Nota che questa parte riguarda solo la decomposizione delle domande in attività. È come fare un piano, non facciamo effettivamente alcun pensiero in questa parte.
![Riferimento [10]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*lQUGig2RwBH8OcabkocyoA.png)
2. Generazione del pensiero: Quindi, dopo aver definito l’attività per ogni step nella decomposizione del pensiero. Adesso generiamo effettivamente i pensieri. Cerchiamo di generare k pensieri come candidati per un dato step Zn. Ci sono due modi per generare i pensieri: campionare e proporre.
a. Campionare pensieri i.i.d. da un prompt di CoT. Ripetiamo il processo di generazione k volte in modo indipendente. Questo funziona meglio quando lo spazio dei pensieri è ampio (ad esempio, ogni pensiero è un paragrafo) e campioni i.i.d. portano a diversità.
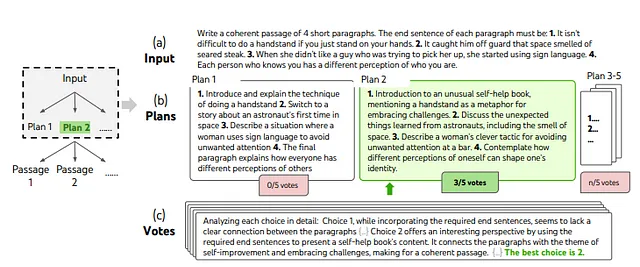
Nella figura sopra, uno step di ricerca deliberata in un’attività di Scrittura creativa scelta casualmente. Dato l’input, l’LM campiona 5 piani diversi, quindi vota 5 volte per decidere quale piano sia il migliore. La scelta maggioritaria viene utilizzata per scrivere consecutivamente il passaggio di output con la stessa procedura di campionamento-voto.
b. Proporre pensieri in modo sequenziale utilizzando un “prompt di proposta”. Questo funziona meglio quando lo spazio dei pensieri è più limitato (ad esempio, ogni pensiero è solo una parola o una linea), quindi proporre pensieri diversi nello stesso contesto evita la duplicazione. In questo caso, generiamo k pensieri in un’unica inferenza. Quindi, questi k pensieri potrebbero non essere indipendenti.
3. Valutare gli stati: In questa parte, definiamo una funzione di valutazione dello stato: v(s). Per espandere l’albero, utilizziamo questa funzione per trovare il percorso migliore, come nella programmazione degli scacchi. Valutiamo il percorso dato dall’albero s=[x, z1…i]. Ci sono due modi per definire la funzione di valutazione:
- Valutare ogni stato in modo indipendente: ogni stato ‘s’ (o percorso) viene valutato in modo indipendente. [ Esempio: Gioco del 24 ]
- Voto tra gli stati: ogni stato ‘s’ viene valutato dato l’insieme di tutti gli stati S. Proprio come si confrontano gli stati in S tra loro come nel CoT di autoconsistenza. [ Esempio: attività di scrittura creativa ]
Esempio Gioco del 24:
Il Gioco del 24 è una sfida di ragionamento matematico, dove l’obiettivo è utilizzare 4 numeri e le operazioni aritmetiche di base (+-*/) per ottenere 24. Ad esempio, dato l’input “4 9 10 13″, una soluzione potrebbe essere ” (10–4) * (13–9) = 24″.
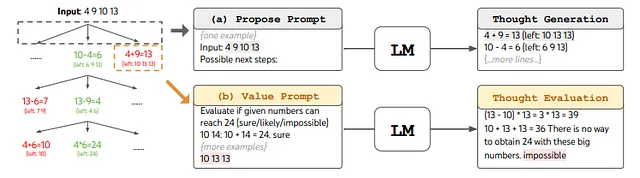
Per inquadrare il ‘Gioco del 24’ in ToT, decomponiamo i pensieri in 3 step, ognuno rappresenta un’equazione intermedia. Come mostrato nella Figura sopra (a), ad ogni nodo dell’albero, estraiamo i numeri “a sinistra” e chiediamo all’LM di proporre alcuni possibili passi successivi. Lo stesso “prompt di proposta” viene utilizzato per tutti e 3 i passi del pensiero, anche se ha solo un esempio con 4 numeri di input. Eseguiamo una ricerca in ampiezza (BFS) in ToT, in cui ad ogni step manteniamo i migliori b = 5 candidati. Per eseguire una BFS deliberata in ToT, come mostrato nella Figura (b), chiediamo all’LM di valutare ogni candidato pensiero come “sicuro/forse/impossibile” per quanto riguarda il raggiungimento di 24. L’obiettivo è promuovere soluzioni parziali corrette che possano essere verificate con poche prove di look-ahead, ed eliminare soluzioni parziali impossibili basate sul “troppo grande/piccolo” buonsenso, e mantenere il resto come “forse”. Campioniamo i valori 3 volte per ogni pensiero.
4. Algoritmo di ricerca: Cerchiamo di espandere l’albero. Per ogni nodo foglia, lo valutiamo con la funzione di valutazione dello stato. Per scegliere quale nodo foglia valutare, utilizziamo un algoritmo di ricerca. Può essere una ricerca in ampiezza o una ricerca in profondità. È possibile utilizzare diversi algoritmi di ricerca a seconda della struttura dell’albero.
Concettualmente, ToT ha diversi vantaggi come metodo per la risoluzione generale dei problemi con i modelli linguistici:
- Generalità: IO, CoT, CoT-SC e auto-raffinamento possono essere visti come casi particolari di ToT (cioè alberi di profondità e ampiezza limitata)
- Modularità: Il modello linguistico di base, così come le procedure di decomposizione, generazione, valutazione e ricerca del pensiero, possono essere variati indipendentemente.
- Adattabilità: È possibile adattare diverse proprietà del problema, capacità dei modelli linguistici e vincoli di risorse.
- Convenienza: Non è necessario eseguire un addestramento aggiuntivo, è sufficiente un modello linguistico preaddestrato.
Il framework ToT consente ai modelli linguistici di prendere decisioni e risolvere problemi in modo più autonomo e intelligente.
Limitazioni: ToT richiede più risorse (ad esempio, il costo dell’API del modello) rispetto ai metodi di campionamento al fine di migliorare le prestazioni delle attività, ma la flessibilità modulare di ToT consente agli utenti di personalizzare tali compromessi tra prestazioni e costo, e gli sforzi open-source in corso dovrebbero ridurre facilmente tali costi in futuro.
Tecniche di autopromozione
L’ingegneria delle promozioni è una scienza empirica e l’effetto dei metodi di ingegneria delle promozioni può variare molto tra i modelli, richiedendo quindi sperimentazione intensiva ed euristici. Possiamo automatizzare questo processo di ingegneria delle promozioni? Si tratta di un’area di ricerca attiva e la sezione seguente discute alcuni tentativi di approcci di progettazione automatica delle promozioni.
Aumento automatico delle promozioni e selezione COT
Nel paper intitolato “Aumento automatico delle promozioni e selezione con catena di pensiero dai dati etichettati” [11]. La maggior parte degli studi CoT si basa su catene razionali annotate dall’uomo appositamente progettate per sollecitare il modello linguistico, il che pone sfide per le applicazioni reali in cui sono disponibili dati di addestramento etichettati senza catene razionali annotate dall’uomo. Per costruire promozioni automatiche di catene di pensiero, gli autori hanno suggerito l’approccio di aumentare-ridurre-selezionare, un processo in tre fasi:
- Aumento: Generare diverse pseudo-catene di pensiero date le domande utilizzando promozioni CoT a few-shot o zero-shot;
- Riduzione: Ridurre le pseudo-catene in base alla corrispondenza tra le risposte generate e le verità di riferimento.
- Selezione: Applicare una strategia di gradiente di politica con varianza ridotta per apprendere la distribuzione di probabilità sugli esempi selezionati, considerando la distribuzione di probabilità sugli esempi come politica e l’accuratezza sul set di validazione come ricompensa.
Auto-CoT: Sollecitazione automatica di catena di pensiero
In “Sollecitazione automatica di catene di pensiero in grandi modelli linguistici” [12], gli autori propongono il paradigma Auto-CoT per costruire automaticamente dimostrazioni con domande e catene di ragionamento. In questa tecnica, gli autori hanno adottato tecniche di clustering per selezionare domande campione e generare catene. Hanno osservato che i modelli linguistici tendono a commettere determinati tipi di errori. Un tipo di errore può essere simile nello spazio di embedding e quindi vengono raggruppati insieme. Campionando solo uno o alcuni dai cluster di errori frequenti, è possibile evitare troppe dimostrazioni errate di un tipo di errore e raccogliere un insieme vario di esempi.
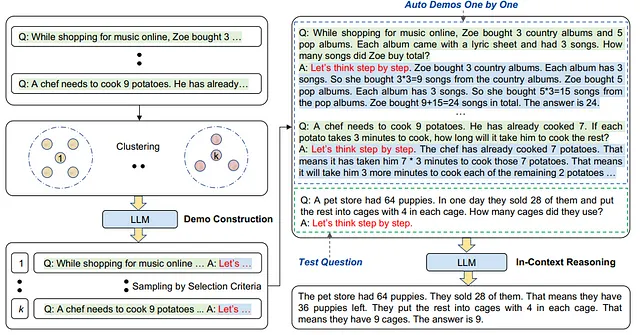
Auto-CoT è composto dalle seguenti fasi principali:
- Clustering delle domande: Effettua un’analisi dei cluster per un dato insieme di domande Q. Prima calcola una rappresentazione vettoriale per ogni domanda in Q utilizzando Sentence-BERT. I vettori contestualizzati vengono mediati per formare una rappresentazione della domanda di dimensione fissa. Successivamente, le rappresentazioni delle domande vengono elaborate dall’algoritmo di clustering k-means per produrre k cluster di domande.
- Selezione delle dimostrazioni: Seleziona un insieme di domande rappresentative da ciascun cluster; cioè una dimostrazione da un cluster. Gli esempi in ciascun cluster vengono ordinati in base alla distanza dal centroide del cluster e quelli più vicini al centroide vengono selezionati per primi.
- Generazione della giustificazione: Utilizza CoT zero-shot per generare catene di ragionamento per le domande selezionate e costruire una promozione a few-shot per eseguire l’inferenza.
LLM hanno dimostrato capacità di ragionamento con promemoria CoT. La performance superiore di Manual-CoT si basa sulla creazione manuale delle dimostrazioni. Per eliminare tali progettazioni manuali, l’Auto-CoT proposto costruisce automaticamente le dimostrazioni. Esegue il campionamento delle domande con diversità e genera catene di ragionamento per costruire le dimostrazioni. I risultati sperimentali sui set di dati di ragionamento hanno mostrato che con GPT-3, Auto-CoT corrisponde o supera costantemente le prestazioni del paradigma CoT che richiede progettazioni manuali delle dimostrazioni.
Conclusion
L’apprendimento in contesto o il prompting ci aiutano a comunicare con LLM per guidare il suo comportamento verso risultati desiderati. È un approccio interessante per estrarre informazioni perché non è necessario un grande set di addestramento offline, non è necessario l’accesso offline a un modello e risulta intuitivo anche per i non ingegneri. L’ingegneria del prompting mira a utilizzare il prompting come modo per creare funzionalità affidabili per applicazioni reali. Si tratta di una scienza empirica e l’effetto dei metodi di ingegneria del prompting può variare molto tra i modelli, richiedendo quindi una sperimentazione intensiva e l’utilizzo di euristici. Il prompting richiede sforzi umani significativi per creare e adattarsi a nuovi set di dati. Il processo di annotazione non è banale perché gli umani devono non solo selezionare le domande, ma anche progettare attentamente i passaggi di ragionamento per ciascuna domanda, quindi c’è bisogno di automazione delle tecniche di prompting.
References
[1] A Survey of Large Language Models, https://arxiv.org/pdf/2303.18223.pdf
[2] A Survey on In-Context Learning, https://arxiv.org/pdf/2301.00234.pdf
[3] Emergent Abilities of Large Language Models, https://arxiv.org/pdf/2206.07682.pdf
[4] Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers, https://arxiv.org/pdf/2212.10559.pdf
[5] An Explanation of In-context Learning as Implicit Bayesian Inference, http://ai.stanford.edu/blog/understanding-incontext/
[6] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, https://arxiv.org/pdf/2201.11903.pdf
[7] Large Language Models are Zero-shot Reasoners, https://arxiv.org/pdf/2205.11916.pdf
[8] In-context learning and induction heads. Transformer Circuits, 2022. https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html .
[9] Self-consistency improves chain-of-thought reasoning in LLM, https://arxiv.org/pdf/2203.11171.pdf
[10] Tree of Thoughts, https://arxiv.org/pdf/2305.10601.pdf
[11] Automatic Prompt Augmentation and Selection with Chain-of-Thought from Labeled Data https://arxiv.org/pdf/2302.12822.pdf
[12] Automatic Chain-of-Thought Prompting in Large Language Models, https://arxiv.org/pdf/2210.03493.pdf
[13] Large Language models can Self Improve, https://www.arxiv-vanity.com/papers/2210.11610/





