Plugin di diffusione su dispositivo per la generazione di testo condizionato su immagini
'Plugin per generare testo condizionato su immagini su dispositivo'
Pubblicato da Yang Zhao e Tingbo Hou, Ingegneri del Software, Core ML
Negli ultimi anni, i modelli di diffusione hanno mostrato un grande successo nella generazione di testo-immagine, raggiungendo una qualità delle immagini elevata, una migliore performance dell’inferenza e ampliando la nostra ispirazione creativa. Tuttavia, è ancora difficile controllare efficientemente la generazione, specialmente con condizioni difficili da descrivere con il testo.
Oggi annunciamo i plugin di diffusione di MediaPipe, che consentono l’esecuzione della generazione controllata di testo-immagine sul dispositivo. Ampliando il nostro lavoro precedente sull’inferenza GPU per modelli generativi di grandi dimensioni sul dispositivo, introduciamo nuove soluzioni a basso costo per la generazione controllata di testo-immagine che possono essere collegati a modelli di diffusione esistenti e alle loro varianti di adattamento a basso rango ( LoRA ).
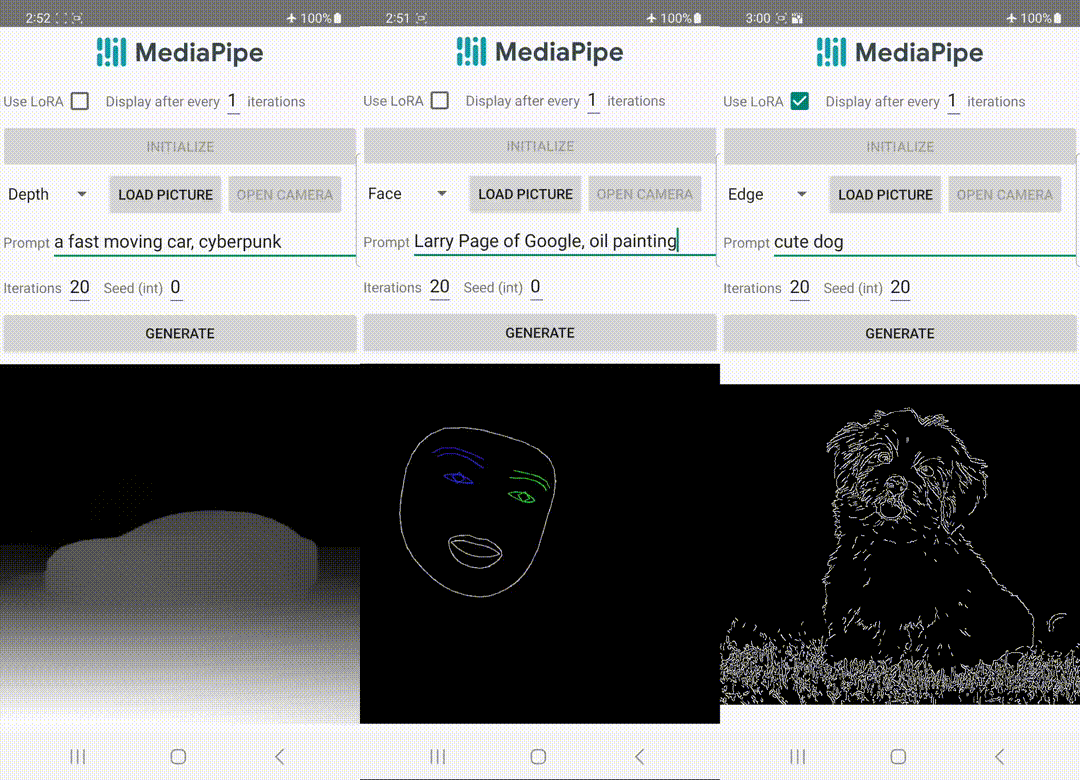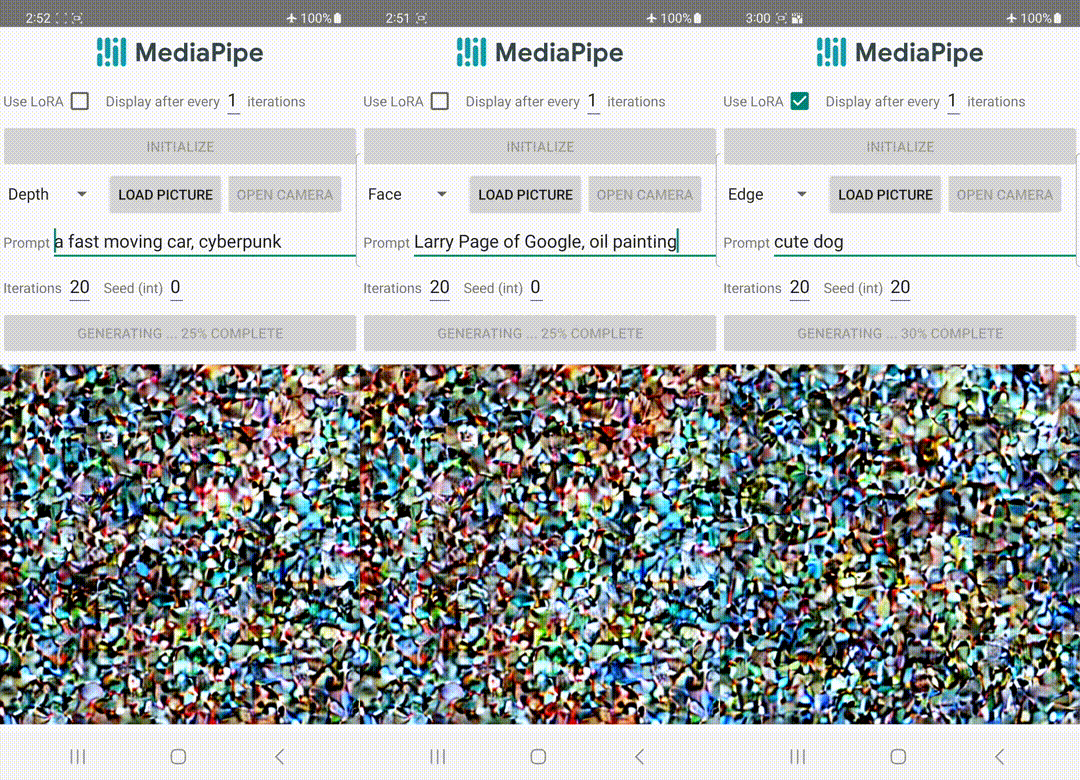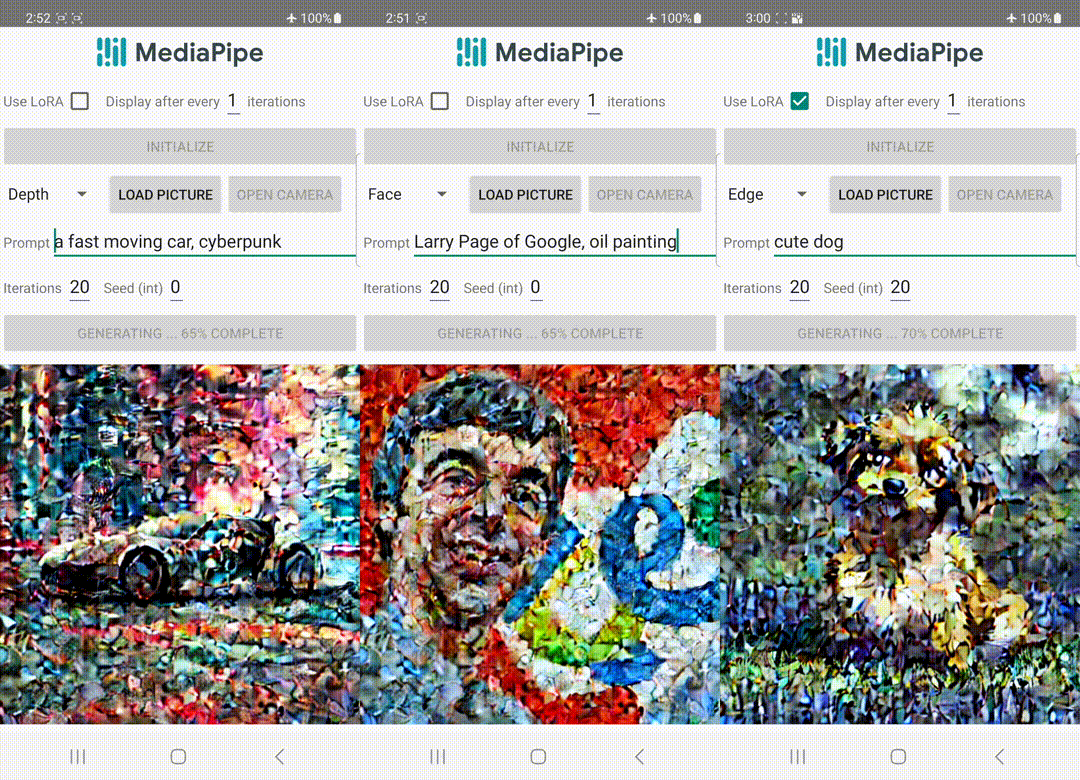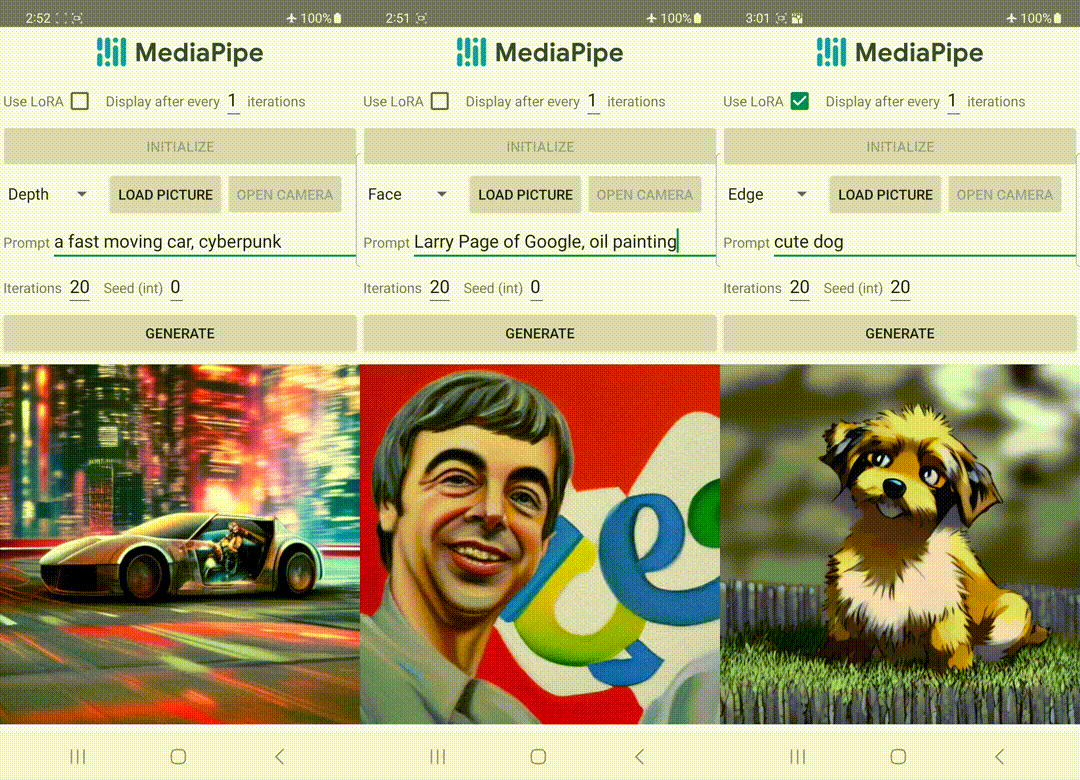 |
| Generazione di testo-immagine con plugin di controllo eseguita sul dispositivo. |
Background
Con i modelli di diffusione, la generazione di immagini è modellata come un processo di denoising iterativo. Partendo da un’immagine di rumore, ad ogni passo, il modello di diffusione denoisa gradualmente l’immagine per rivelare un’immagine del concetto target. La ricerca mostra che sfruttare la comprensione del linguaggio tramite prompt di testo può migliorare notevolmente la generazione di immagini. Per la generazione di testo-immagine, l’embedding del testo è collegato al modello tramite strati di cross-attention. Tuttavia, alcune informazioni sono difficili da descrivere con prompt di testo, ad esempio la posizione e la posa di un oggetto. Per risolvere questo problema, i ricercatori aggiungono modelli aggiuntivi alla diffusione per inserire informazioni di controllo da un’immagine di condizione.
- Potenziare i robot con la performance di compiti complessi Meta AI sviluppa un modello di affordance visuale utilizzando video su Internet del comportamento umano.
- Google DeepMind sta lavorando su un algoritmo per superare ChatGPT.
- Ottimizza in modo interattivo Falcon-40B e altri LLM su Amazon SageMaker Studio notebooks utilizzando QLoRA
Gli approcci comuni per la generazione controllata di testo-immagine includono Plug-and-Play , ControlNet e T2I Adapter . Plug-and-Play applica un approccio di inversione del modello di diffusione di denoising implicito ampiamente utilizzato ( DDIM ) che inverte il processo di generazione a partire da un’immagine di input per ottenere un input di rumore iniziale, e quindi utilizza una copia del modello di diffusione (860M parametri per Stable Diffusion 1.5) per codificare la condizione da un’immagine di input. Plug-and-Play estrae le caratteristiche spaziali con self-attention dalla diffusione copiata e le inietta nella diffusione di testo-immagine. ControlNet crea una copia addestrabile dell’encoder di un modello di diffusione, che si collega tramite uno strato di convoluzione con parametri inizializzati a zero per codificare le informazioni di condizionamento che vengono trasmesse ai livelli del decoder. Tuttavia, di conseguenza, la dimensione è grande, pari alla metà del modello di diffusione (430M parametri per Stable Diffusion 1.5). T2I Adapter è una rete più piccola (77M parametri) e ottiene effetti simili nella generazione controllata. T2I Adapter prende solo l’immagine di condizione come input e la sua uscita è condivisa tra tutte le iterazioni di diffusione. Tuttavia, il modello dell’adattatore non è progettato per dispositivi portatili.
I plugin di diffusione di MediaPipe
Per rendere efficiente, personalizzabile e scalabile la generazione condizionata, progettiamo il plugin di diffusione di MediaPipe come una rete separata che è:
- Inseribile : può essere facilmente collegato a un modello di base preaddestrato.
- Addestrato da zero : non utilizza pesi preaddestrati del modello di base.
- Portatile : viene eseguito al di fuori del modello di base su dispositivi mobili, con un costo trascurabile rispetto all’inferenza del modello di base.
| Metodo | Dimensione dei parametri | Inseribile | Da zero | Portatile | ||||
| Plug-and-Play | 860M* | ✔️ | ❌ | ❌ | ||||
| ControlNet | 430M* | ✔️ | ❌ | ❌ | ||||
| T2I Adapter | 77M | ✔️ | ✔️ | ❌ | ||||
| Plugin MediaPipe | 6M | ✔️ | ✔️ | ✔️ |
| Confronto tra Plug-and-Play, ControlNet, T2I Adapter e il plugin MediaPipe per la diffusione. * Il numero varia a seconda dei dettagli del modello di diffusione. |
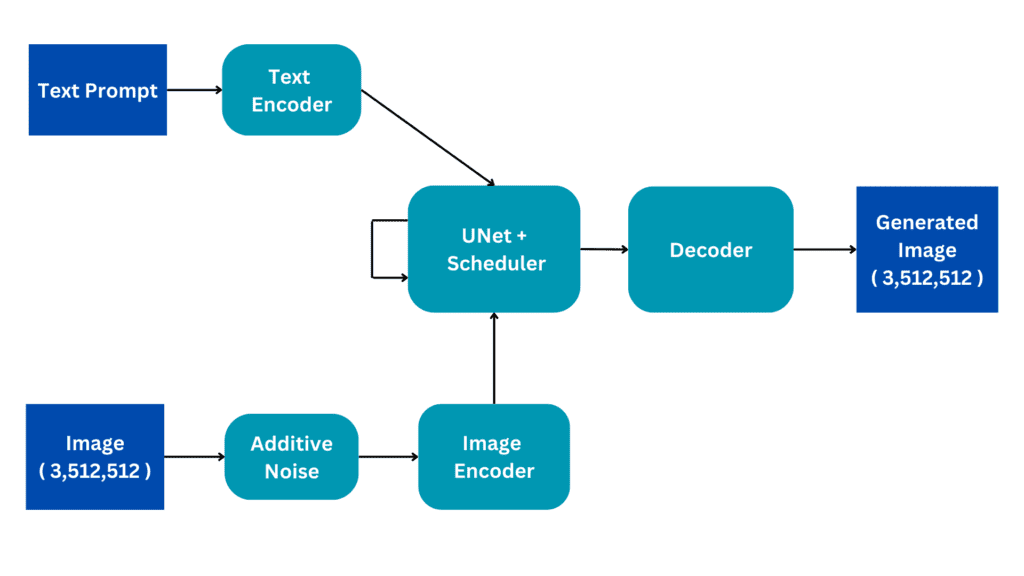
Il plugin MediaPipe per la diffusione è un modello portatile su dispositivo per la generazione di testo-immagine. Estrae caratteristiche multiscala da un’immagine di condizionamento, che vengono aggiunte all’encoder di un modello di diffusione ai livelli corrispondenti. Quando si connette a un modello di diffusione testo-immagine, il modello del plugin può fornire un segnale di condizionamento extra alla generazione dell’immagine. Abbiamo progettato la rete del plugin per essere un modello leggero con solo 6M di parametri. Utilizza convoluzioni di profondità e bottleneck invertiti di MobileNetv2 per un’elaborazione rapida su dispositivi mobili.
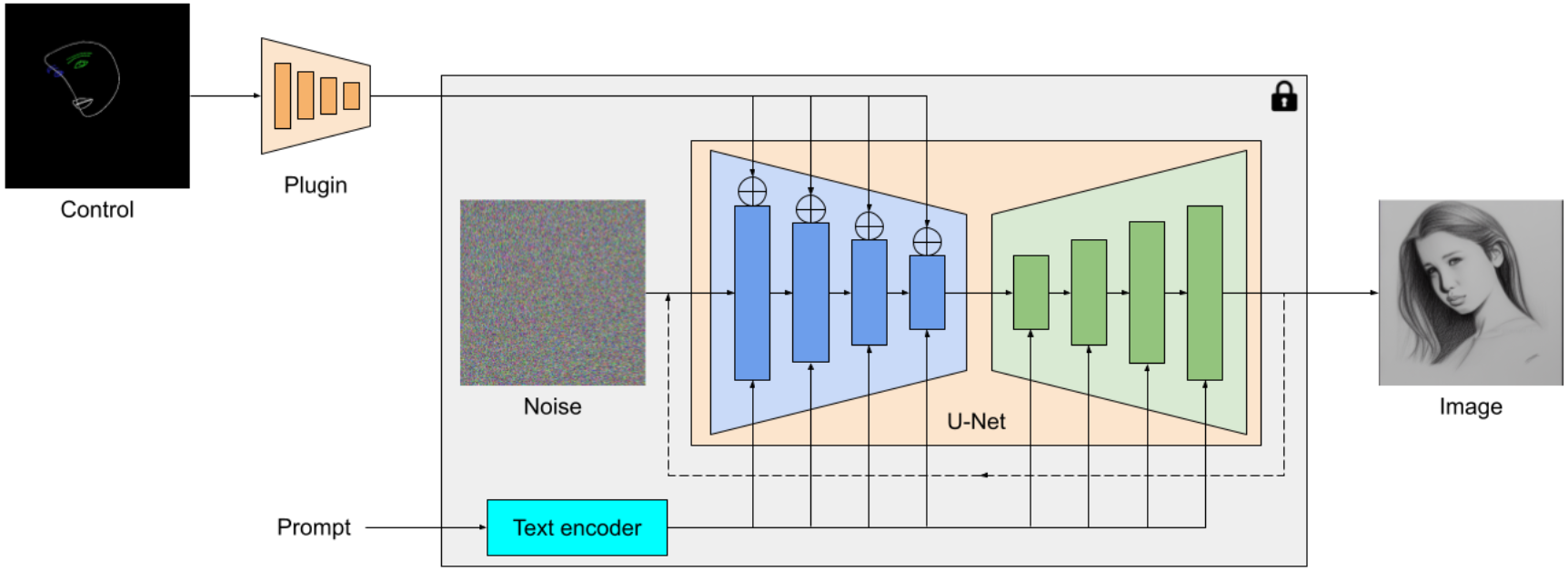 |
| Panoramica del modello plugin MediaPipe per la diffusione. Il plugin è una rete separata, il cui output può essere collegato a un modello pre-allenato di generazione testo-immagine. Le caratteristiche estratte dal plugin vengono applicate al livello di downsampling associato del modello di diffusione (blu). |
A differenza di ControlNet, iniettiamo le stesse caratteristiche di controllo in tutte le iterazioni di diffusione. Ciò significa che eseguiamo il plugin una sola volta per la generazione di un’immagine, il che consente di risparmiare computazione. Illustreremo di seguito alcuni risultati intermedi di un processo di diffusione. Il controllo è efficace ad ogni passo di diffusione e consente una generazione controllata anche ai primi passi. Un numero maggiore di iterazioni migliora l’allineamento dell’immagine con il prompt di testo e genera più dettagli.
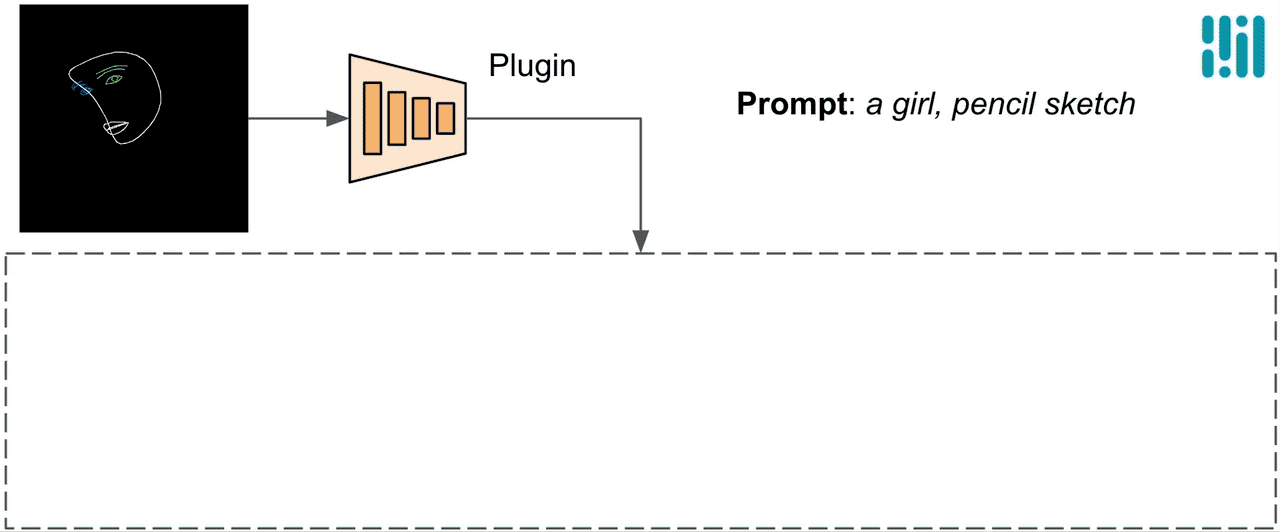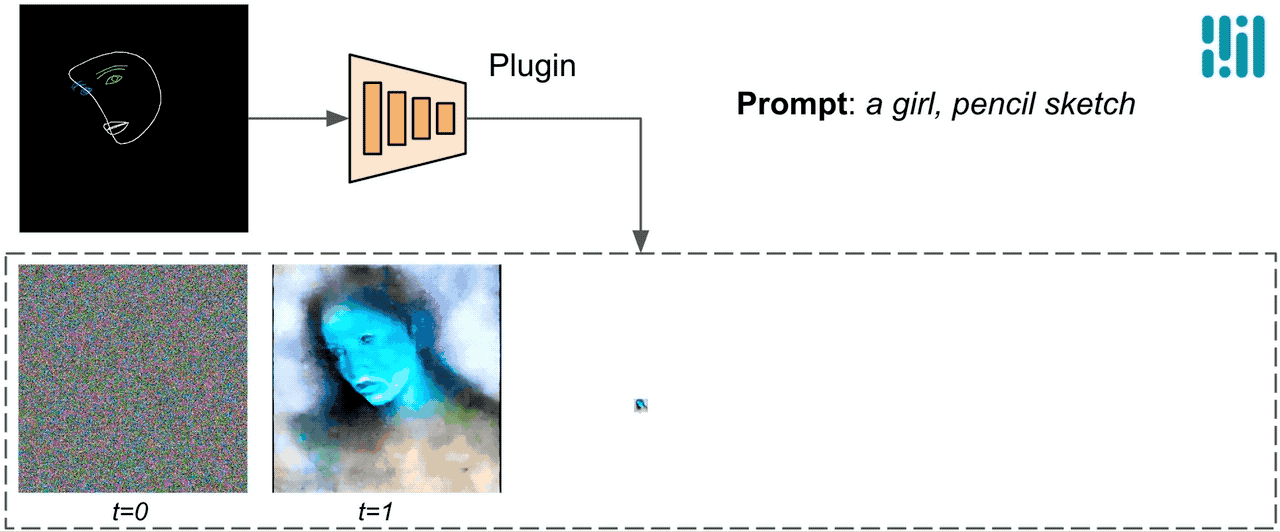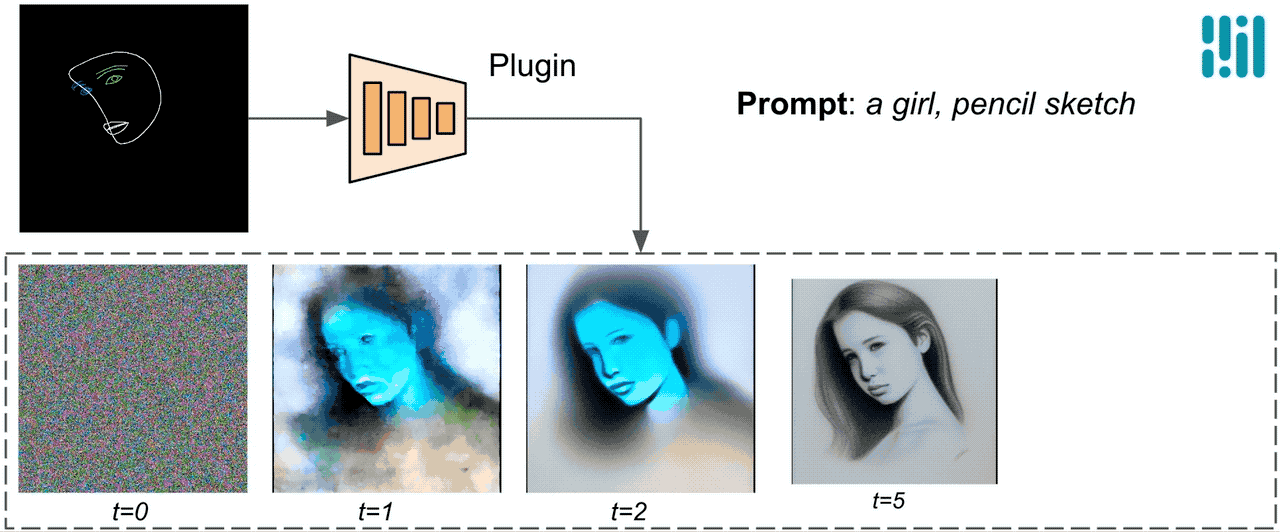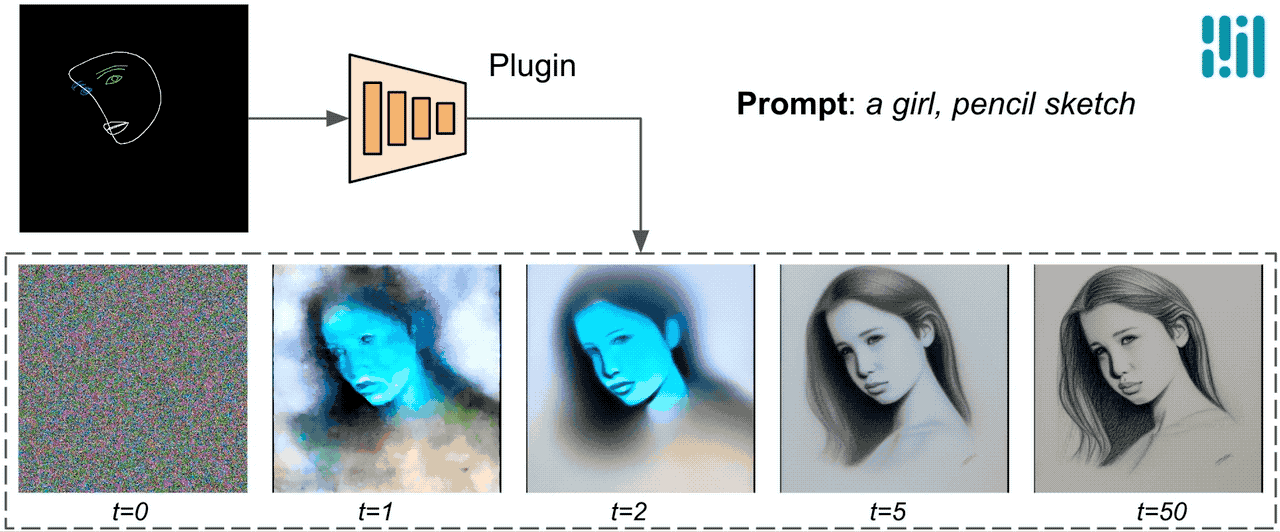 |
| Illustrazione del processo di generazione utilizzando il plugin MediaPipe per la diffusione. |
Esempi
In questo lavoro, abbiamo sviluppato plugin per un modello di generazione testo-immagine basato sulla diffusione con MediaPipe Face Landmark, MediaPipe Holistic Landmark, mappe di profondità e bordi di Canny. Per ogni attività, selezioniamo circa 100.000 immagini da un dataset di immagini-testo di scala web e calcoliamo segnali di controllo utilizzando le soluzioni MediaPipe corrispondenti. Utilizziamo didascalie raffinate da PaLI per addestrare i plugin.
Face Landmark
Il compito di MediaPipe Face Landmarker calcola 478 landmark (con attenzione) di un volto umano. Utilizziamo gli strumenti di disegno in MediaPipe per renderizzare un volto, compresi contorno del viso, bocca, occhi, sopracciglia e iridi, con colori diversi. La tabella seguente mostra campioni generati casualmente condizionando la generazione su mesh facciale e prompt. A titolo di confronto, sia ControlNet che il Plugin possono controllare la generazione testo-immagine con condizioni specifiche.
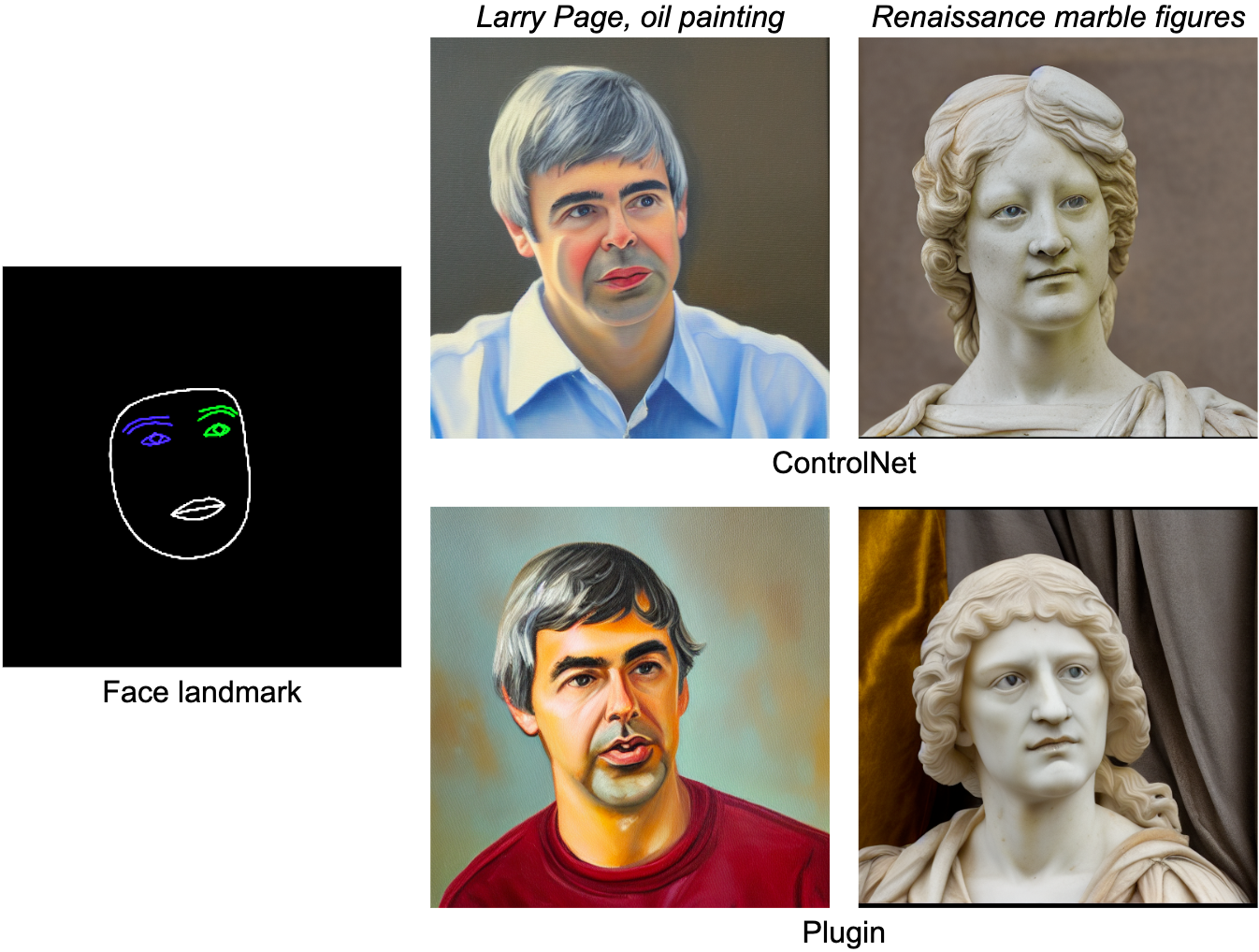 |
| Plugin Face-landmark per la generazione testo-immagine, confrontato con ControlNet. |
Landmark Olistico
Il compito di MediaPipe Holistic Landmarker include landmark di postura corporea, mani e mesh del viso. Di seguito, generiamo varie immagini stilizzate condizionando sulle caratteristiche olistiche.
 |
| Plugin Holistic-landmark per la generazione di testo-immagine. |
Profondità
 |
| Plugin Depth per la generazione di testo-immagine. |
Canny Edge
 |
| Plugin Canny-edge per la generazione di testo-immagine. |
Valutazione
Conduciamo uno studio quantitativo del plugin di landmark facciale per dimostrare le prestazioni del modello. Il dataset di valutazione contiene 5.000 immagini umane. Confrontiamo la qualità di generazione misurata dalle metriche ampiamente utilizzate, distanza di Fréchet Inception (FID) e punteggi CLIP. Il modello di base è un modello di diffusione testo-immagine pre-addestrato. Qui utilizziamo Stable Diffusion v1.5.
Come mostrato nella tabella seguente, sia ControlNet che il plugin di diffusione MediaPipe producono una qualità campionaria molto migliore rispetto al modello di base, in termini di FID e punteggi CLIP. A differenza di ControlNet, che deve essere eseguito ad ogni passaggio di diffusione, il plugin MediaPipe viene eseguito solo una volta per ogni immagine generata. Abbiamo misurato le prestazioni dei tre modelli su una macchina server (con GPU Nvidia V100) e su un telefono cellulare (Galaxy S23). Sul server, eseguiamo tutti e tre i modelli con 50 passaggi di diffusione, e su mobile, eseguiamo 20 passaggi di diffusione utilizzando l’app di generazione di immagini MediaPipe. Rispetto a ControlNet, il plugin MediaPipe mostra un chiaro vantaggio in termini di efficienza di inferenza pur preservando la qualità campionaria.
| Modello | FID↓ | CLIP↑ | Tempo di Inferenza (s) | |||||
| Nvidia V100 | Galaxy S23 | |||||||
| Base | 10.32 | 0.26 | 5.0 | 11.5 | ||||
| Base + ControlNet | 6.51 | 0.31 | 7.4 (+48%) | 18.2 (+58.3%) | ||||
| Base + Plugin MediaPipe | 6.50 | 0.30 | 5.0 (+0.2%) | 11.8 (+2.6%) |
| Confronto quantitativo su FID, CLIP e tempo di inferenza. |
Testiamo le prestazioni del plugin su una vasta gamma di dispositivi mobili, dai dispositivi di fascia media a quelli di fascia alta. Riportiamo i risultati su alcuni dispositivi rappresentativi nella tabella seguente, che copre sia Android che iOS.
| Dispositivo | Android | iOS | ||||||||||
| Pixel 4 | Pixel 6 | Pixel 7 | Galaxy S23 | iPhone 12 Pro | iPhone 13 Pro | |||||||
| Tempo (ms) | 128 | 68 | 50 | 48 | 73 | 63 |
| Tempo di inferenza (ms) del plugin su diversi dispositivi mobili. |
Conclusioni
In questo lavoro, presentiamo MediaPipe, un plugin portatile per la generazione di immagini condizionate da testo. Inietta le caratteristiche estratte da un’immagine di condizione in un modello di diffusione e controlla di conseguenza la generazione dell’immagine. I plugin portatili possono essere collegati a modelli di diffusione preaddestrati in esecuzione su server o dispositivi. Eseguendo la generazione di immagini da testo e i plugin completamente su dispositivo, consentiamo applicazioni più flessibili dell’IA generativa.
Ringraziamenti
Vorremmo ringraziare tutti i membri del team che hanno contribuito a questo lavoro: Raman Sarokin e Juhyun Lee per la soluzione di inferenza GPU; Khanh LeViet, Chuo-Ling Chang, Andrei Kulik e Matthias Grundmann per la leadership. Un ringraziamento speciale a Jiuqiang Tang, Joe Zou e Lu wang, che hanno reso possibile questa tecnologia e tutte le demo in esecuzione su dispositivo.