Apprendimento delle preferenze con feedback automatizzato per l’espulsione della cache
Automated feedback-based preference learning for cache eviction.
Pubblicato da Ramki Gummadi, Ingegnere Software, Google e Kevin Chen, Ingegnere Software, YouTube
La memorizzazione nella cache è un’idea ubiqua nell’informatica che migliora significativamente le prestazioni dei sistemi di archiviazione e recupero memorizzando un sottoinsieme di elementi popolari più vicino al client in base ai modelli di richiesta. Un importante elemento algoritmico nella gestione della cache è la politica decisionale utilizzata per l’aggiornamento dinamico dell’insieme di elementi memorizzati, che è stata ampiamente ottimizzata nel corso di diversi decenni, portando a diverse euristiche efficienti e robuste . Sebbene l’applicazione dell’apprendimento automatico alle politiche di cache abbia mostrato risultati promettenti negli ultimi anni (ad esempio, LRB , LHD , applicazioni di archiviazione ), rimane una sfida superare le euristiche robuste in modo da poter generalizzare in modo affidabile oltre i benchmark e i contesti di produzione, mantenendo al contempo costi computazionali e di memoria competitivi.
In “HALP: Heuristic Aided Learned Preference Eviction Policy for YouTube Content Delivery Network”, presentato a NSDI 2023 , introduciamo un framework di evacuazione della cache all’avanguardia e scalabile basato su ricompense apprese e utilizzando l’apprendimento delle preferenze con feedback automatizzati. Il framework Heuristic Aided Learned Preference (HALP) è un meta-algoritmo che utilizza la randomizzazione per unire una regola di evacuazione di base euristica con un modello di ricompensa appreso. Il modello di ricompensa è una rete neurale leggera che viene continuamente addestrata con un feedback automatizzato continuo su confronti di preferenze progettati per imitare l’oracolo offline . Discutiamo come HALP abbia migliorato l’efficienza dell’infrastruttura e la latenza di riproduzione video dell’utente per la rete di distribuzione dei contenuti di YouTube .
Preferenze apprese per le decisioni di evacuazione della cache
Il framework HALP calcola le decisioni di evacuazione della cache basandosi su due componenti: (1) un modello di ricompensa neurale addestrato con feedback automatizzati tramite apprendimento delle preferenze e (2) un meta-algoritmo che combina un modello di ricompensa appreso con una euristica veloce. Mentre la cache osserva le richieste in arrivo, HALP addestra continuamente una piccola rete neurale che predice una ricompensa scalare per ciascun elemento formulando questo come un metodo di apprendimento delle preferenze tramite feedback di preferenza a coppie. Questo aspetto di HALP è simile ai sistemi di apprendimento per rinforzo da feedback umano (RLHF), ma con due distinzioni importanti:
- Tipi di funzioni di attivazione nelle reti neurali
- Cosa è il Machine Learning come Servizio? Vantaggi e le migliori piattaforme MLaaS.
- Cure più veloci come Insilico Medicine utilizza l’AI generativa per accelerare la scoperta di nuovi farmaci
- Il feedback è automatizzato e sfrutta risultati ben noti sulla struttura delle politiche di evacuazione della cache ottimali offline.
- Il modello viene appreso continuamente utilizzando un buffer transitorio di esempi di addestramento costruiti dal processo di feedback automatizzato.
Le decisioni di evacuazione si basano su un meccanismo di filtraggio con due fasi. Inizialmente, viene selezionato un piccolo sottoinsieme di candidati utilizzando una euristica efficiente, ma subottimale in termini di prestazioni. Successivamente, una fase di riordinamento ottimizza i candidati di base tramite l’uso parsimonioso di una funzione di punteggio di rete neurale per “migliorare” la qualità della decisione finale.
Come implementazione di una politica di cache pronta per la produzione, HALP non solo prende decisioni di evacuazione, ma comprende anche l’intero processo di campionamento di query di preferenza a coppie utilizzate per costruire in modo efficiente un feedback rilevante e aggiornare il modello per supportare le decisioni di evacuazione.
Un modello di ricompensa neurale
HALP utilizza un percettrone multistrato (MLP) leggero a due livelli come modello di ricompensa per valutare selettivamente gli elementi individuali nella cache. Le caratteristiche sono costruite e gestite come una “cache fantasma” solo metadati (simile a politiche classiche come ARC ). Dopo ogni richiesta di ricerca, oltre alle normali operazioni di cache, HALP svolge le attività di gestione (ad esempio, tracciamento e aggiornamento dei metadati delle caratteristiche in un sistema di archiviazione chiave-valore con capacità limitata) necessarie per aggiornare la rappresentazione interna dinamica. Ciò include: (1) caratteristiche contrassegnate esternamente fornite dall’utente come input, insieme a una richiesta di ricerca nella cache, e (2) caratteristiche dinamiche interne costruite (ad esempio, tempo trascorso dall’ultimo accesso, tempo medio tra gli accessi) costruite dai tempi di ricerca osservati su ciascun elemento.
HALP apprende il suo modello di ricompensa completamente online a partire da una inizializzazione casuale dei pesi. Questo potrebbe sembrare una cattiva idea, specialmente se le decisioni vengono prese esclusivamente per ottimizzare il modello di ricompensa. Tuttavia, le decisioni di evacuazione si basano sia sul modello di ricompensa appreso che su una euristica semplice e robusta ma subottimale come LRU . Ciò consente prestazioni ottimali quando il modello di ricompensa si è completamente generalizzato, pur rimanendo robusto rispetto a un modello di ricompensa temporaneamente non informativo che deve ancora generalizzarsi o che è in fase di adeguamento a un ambiente che cambia.
Un altro vantaggio dell’addestramento online è la specializzazione. Ogni server di cache funziona in un ambiente potenzialmente diverso (ad esempio, posizione geografica), che influenza le condizioni di rete locali e quali contenuti sono popolari a livello locale, tra le altre cose. L’addestramento online cattura automaticamente queste informazioni riducendo il carico di generalizzazione, a differenza di una singola soluzione di addestramento offline.
Calcolo dei punteggi da una coda prioritaria randomizzata
Può essere impraticabile ottimizzare la qualità delle decisioni di evacuazione con un obiettivo esclusivamente appreso per due motivi.
- Calcola i vincoli di efficienza: L’inferenza con una rete appresa può essere significativamente più costosa rispetto ai calcoli eseguiti nelle politiche di cache pratiche operative su larga scala. Ciò limita non solo l’espressività della rete e delle caratteristiche, ma anche la frequenza con cui queste vengono invocate durante ogni decisione di espulsione.
- Robustezza per la generalizzazione fuori distribuzione: HALP è implementato in un ambiente che prevede l’apprendimento continuo, in cui un carico di lavoro in rapido cambiamento potrebbe generare modelli di richiesta temporaneamente fuori distribuzione rispetto ai dati precedentemente visti.
Per affrontare questi problemi, HALP applica inizialmente una regola di punteggio euristica poco costosa che corrisponde a una priorità di espulsione per identificare un piccolo campione di candidati. Questo processo si basa su un campionamento casuale efficiente che approssima le code di priorità esatte. La funzione di priorità per la generazione dei campioni candidati è progettata per essere veloce da calcolare utilizzando algoritmi pre-regolati esistenti, ad esempio LRU. Tuttavia, questa funzione può essere configurata per approssimare altre euristiche di rimpiazzo della cache modificando una semplice funzione di costo. A differenza dei lavori precedenti, in cui la casualizzazione era utilizzata per bilanciare l’approssimazione con l’efficienza, HALP si basa anche sulla casualizzazione intrinseca nei candidati campionati nel tempo per fornire la necessaria diversità esplorativa nei candidati campionati sia per l’addestramento che per l’inferenza.
L’elemento espulso finale viene scelto tra i candidati forniti, equivalente al campione riordinato migliore tra i primi N, corrispondente alla massimizzazione del punteggio di preferenza previsto secondo il modello di ricompensa neurale. Lo stesso pool di candidati utilizzato per le decisioni di espulsione viene anche utilizzato per costruire le interrogazioni di preferenza a coppie per il feedback automatizzato, che aiuta a minimizzare la discrepanza tra l’addestramento e l’inferenza tra i campioni.
 |
| Una panoramica del processo a due fasi invocato per ogni decisione di espulsione. |
Apprendimento delle preferenze online con feedback automatizzato
Il modello di ricompensa viene appreso utilizzando un feedback online, che si basa su etichette di preferenza assegnate automaticamente che indicano, se possibile, l’ordine di preferenza classificato per il tempo richiesto per ricevere futuri ri-accessi, a partire da uno snapshot dato iniziale tra ogni campione di elementi interrogati. Questo è simile alla politica ottimale dell’oracolo, che, in qualsiasi momento, espelle un elemento con l’accesso futuro più lontano rispetto a tutti gli elementi nella cache.
 |
| Generazione del feedback automatizzato per l’apprendimento del modello di ricompensa. |
Per rendere informativo questo processo di feedback, HALP costruisce interrogazioni di preferenze a coppie che sono più probabili di essere rilevanti per le decisioni di espulsione. In sincronia con le normali operazioni di cache, HALP emette un piccolo numero di interrogazioni di preferenza a coppie durante ogni decisione di espulsione e le aggiunge a un insieme di confronti in sospeso. Le etichette per questi confronti in sospeso possono essere risolte solo in un momento futuro casuale. Per operare online, HALP esegue anche alcune operazioni aggiuntive di gestione dopo ogni richiesta di ricerca per elaborare eventuali confronti in sospeso che possono essere etichettati incrementalmente dopo la richiesta corrente. HALP indicizza il buffer di confronti in sospeso con ogni elemento coinvolto nel confronto e ricicla la memoria utilizzata dai confronti obsoleti (che potrebbero non ricevere mai un ri-accesso) per garantire che l’overhead di memoria associato alla generazione del feedback rimanga limitato nel tempo.
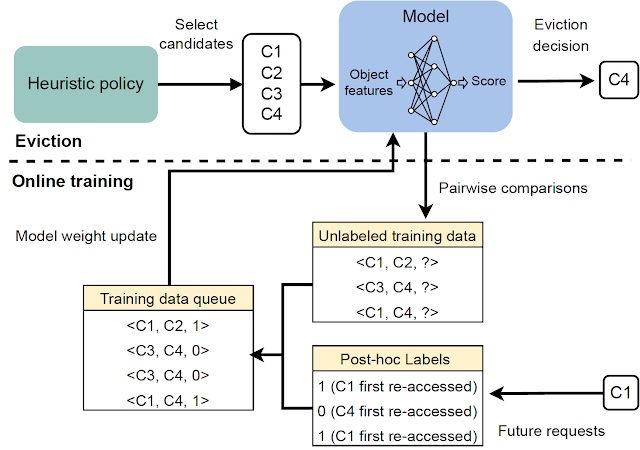 |
| Panoramica di tutti i componenti principali in HALP. |
Risultati: Impatto sulla CDN di YouTube
Attraverso l’analisi empirica, mostriamo che HALP si confronta favorevolmente con le politiche di cache all’avanguardia sui benchmark pubblici in termini di tassi di miss di cache. Tuttavia, mentre i benchmark pubblici sono uno strumento utile, raramente sono sufficienti per catturare tutti i modelli di utilizzo in tutto il mondo nel tempo, senza parlare delle diverse configurazioni hardware che abbiamo già implementato.
Fino a poco tempo fa, i server di YouTube utilizzavano un’evoluzione della politica LRU ottimizzata per l’evacuazione della cache di memoria. HALP aumenta l’ingresso/uscita di memoria di YouTube – il rapporto tra la larghezza di banda totale egress servita dalla CDN e quella consumata per il recupero (ingress) a causa dei miss di cache – di circa il 12% e l’hit rate di memoria del 6%. Ciò riduce la latenza per gli utenti, poiché la lettura dalla memoria è più veloce della lettura dal disco, e migliora anche la capacità di uscita per le macchine vincolate dal disco, proteggendo i dischi dal traffico.
La figura seguente mostra una riduzione visivamente convincente del rapporto di byte mancanti nei giorni successivi al rilascio finale di HALP sulla CDN di YouTube, che ora serve contenuti significativamente di più dalla cache con una latenza inferiore per l’utente finale, senza dover ricorrere a un recupero più costoso che aumenta i costi operativi.
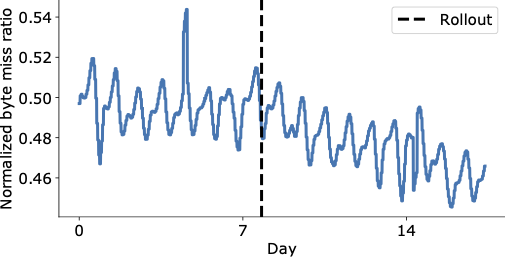 |
| Rapporto di byte mancanti aggregato a livello mondiale su YouTube prima e dopo il rilascio (linea tratteggiata verticale). |
Un miglioramento delle prestazioni aggregato potrebbe comunque nascondere importanti regressioni. Oltre a misurare l’impatto complessivo, conduciamo anche un’analisi nel documento per capirne l’impatto su diversi rack utilizzando un’analisi a livello di macchina e lo troviamo decisamente positivo.
Conclusioni
Abbiamo introdotto un framework di evacuazione della cache scalabile all’avanguardia basato su ricompense apprese e che utilizza l’apprendimento delle preferenze con feedback automatico. Grazie alle sue scelte di progettazione, HALP può essere implementato in modo simile a qualsiasi altra politica di cache senza l’onere operativo di dover gestire separatamente gli esempi etichettati, la procedura di formazione e le versioni del modello come pipeline offline aggiuntive comuni alla maggior parte dei sistemi di apprendimento automatico. Pertanto, comporta solo un piccolo overhead aggiuntivo rispetto ad altri algoritmi classici, ma ha il vantaggio aggiuntivo di poter sfruttare ulteriori funzionalità per prendere decisioni di evacuazione e adattarsi continuamente ai modelli di accesso in evoluzione.
Questa è la prima implementazione su larga scala di una politica di cache appresa su una CDN ampiamente utilizzata e ad alta densità di traffico, e ha migliorato significativamente l’efficienza dell’infrastruttura CDN, offrendo al contempo una migliore qualità dell’esperienza agli utenti.
Riconoscimenti
Ramki Gummadi fa ora parte di Google DeepMind. Desideriamo ringraziare John Guilyard per l’aiuto con le illustrazioni e Richard Schooler per il feedback su questo post.