NODO Alberi Neurali Orientati alla Tabella
NODONET
Esplorazione di NODE: Un’architettura di albero decisionale neurale per i dati tabulari
Negli ultimi anni, l’Apprendimento Automatico ha avuto un’esplosione di popolarità e i modelli di Apprendimento Profondo Neurale hanno superato modelli superficiali come XGBoost [4] per compiti complessi come l’elaborazione di immagini e testi. Tuttavia, i modelli profondi sono spesso meno efficaci di questi modelli superficiali per quanto riguarda i dati tabulari e nessun approccio di apprendimento profondo universale supera costantemente gli alberi di boosting del gradiente.
Per colmare questa lacuna, i ricercatori della società di servizi internet russa Yandex hanno proposto una nuova architettura: Neural Oblivious Decision Ensembles (NODE) [1]. Questa rete sfrutta alberi decisionali neurali leggeri e interpretabili e li integra all’interno di un framework di rete neurale. Ciò consente al modello di catturare interazioni complesse e dipendenze nei dati tabulari mantenendo l’interpretabilità.
In questo articolo, mi propongo di spiegare come funziona NODE e le varie caratteristiche che lo rendono un modello di previsione robusto ma interpretabile. Come al solito, incoraggio tutti a leggere l’articolo originale. Se desideri utilizzare NODE, consulta il GitHub per il modello.
Questo articolo fa parte di una serie su Alberi Decisionali Neurali, architetture altamente spiegabili che forniscono un potere predittivo equivalente alle reti neurali profonde tradizionali.
- Possono i modelli di linguaggio piccoli offrire alte prestazioni? Scopri StableLM un modello di linguaggio open source che può generare testo e codice fornendo alte prestazioni con un adeguato addestramento.
- Cosa sono i Large Language Models (LLM)? Applicazioni e Tipi di LLM.
- Modellare il futuro dell’Intelligenza Artificiale AI L’importanza dell’Ingegneria Tempestiva per il Progresso e l’Innovazione

Nakul Upadhya
Alberi Decisionali Soffici/Neurali
Visualizza elenco 2 storie

Struttura dell’Albero di Decisione NODE
Alberi Decisionali Neurali
Questo articolo presume che tu abbia una certa familiarità con gli Alberi Decisionali Neurali. Se non lo hai, ti incoraggio vivamente a leggere il mio articolo precedente su di essi per una spiegazione approfondita. Tuttavia, in sintesi: gli Alberi Decisionali Neurali sono alberi decisionali che sono sia soffici che obliqui.
Un albero obliquo è uno in cui più variabili vengono utilizzate per prendere decisioni in ogni nodo (di solito disposte in una combinazione lineare). Ad esempio, per prevedere un incidente automobilistico, un albero ortogonale può produrre una decisione di diramazione utilizzando la regola “velocità_auto – limite_velocità <10”. Questo è diverso dagli alberi “ortogonali” come CART (l’albero decisionale di base), che utilizza solo una variabile in ogni nodo e avrà bisogno di più nodi per approssimare la stessa frontiera decisionale.
Un albero soffice è uno in cui tutte le decisioni di diramazione sono probabilistiche e i calcoli in ogni nodo definiscono la probabilità di entrare in un ramo particolare. Questo è diverso dai tradizionali alberi decisionali “rigidi” come CART, in cui ogni decisione di diramazione è deterministica.
Dato che l’albero non limita il numero di variabili utilizzate in ogni nodo e le decisioni di diramazione sono continue, l’intero albero è differenziabile. Poiché l’intero albero è differenziabile, può essere integrato in qualsiasi framework di rete neurale come Pytorch o Tensorflow e addestrato utilizzando ottimizzatori neurali tradizionali (es. Stochastic Gradient Descent e Adam).
Alberi NODE
Gli alberi decisionali utilizzati da NODE sono leggermente diversi dai tradizionali Alberi Neurali. Vediamo tutte le differenze.
Natura Obliqua
Il primo cambiamento significativo è il fatto che gli alberi sono Obliqui. Questo significa che l’albero utilizza gli stessi pesi di divisione e le stesse soglie per tutti i nodi interni alla stessa profondità. Di conseguenza, gli Alberi Decisionali Obliqui (ODTs) possono essere rappresentati come una tabella decisionale con 2^ d voci ( d è la profondità). Un vantaggio è che gli ODT sono più interpretabili rispetto agli alberi decisionali tradizionali in quanto ci sono meno decisioni da analizzare, rendendo il percorso decisionale più facile da visualizzare e capire. Tuttavia, gli ODT sono apprenditori significativamente più deboli rispetto agli alberi decisionali tradizionali (ancora una volta a causa della natura vincolata delle funzioni di divisione).
Quindi, se il nostro obiettivo è la performance, perché dovremmo usare gli ODT? Come hanno dimostrato gli sviluppatori di CATBoost [2], gli ODT funzionano incredibilmente bene quando vengono insieme e sono meno inclini all’overfitting dei dati. Inoltre, l’inferenza degli ODT è estremamente efficiente poiché le divisioni possono essere calcolate tutte in parallelo per trovare rapidamente l’ingresso appropriato nella tabella.
Entmax per la selezione delle caratteristiche e il branching
Il secondo miglioramento di NODE rispetto all’albero decisionale neurale tradizionale è l’uso di alpha-entmax [3] al posto del sigmoid nella sua architettura. Alpha-entmax è una versione generalizzata di softmax in grado di produrre distribuzioni sparse in cui la maggior parte del risultato è uguale a zero. Questa sparsità è controllata da un parametro (alpha, da cui il nome) in cui più alto è l’alpha, più sparsa è la distribuzione.
![Figura da Peters et al. 2019 [3]](https://miro.medium.com/v2/resize:fit:640/format:webp/0*F_Ar1Nyc6BxnVXsP.png)
Questa trasformazione viene utilizzata in due punti chiave. Il primo utilizzo è nella selezione delle caratteristiche sparse. NODE include una matrice di pesi di selezione delle caratteristiche addestrabili F (di dimensione d x n dove n è il numero di caratteristiche e d è la profondità dell’albero) passata attraverso la trasformazione entmax. Poiché la maggior parte delle voci della trasformazione entmax è uguale a zero, ciò porta naturalmente a un numero ridotto di caratteristiche utilizzate in ogni nodo decisionale.
![Funzione di branching (Figura da Popov et al. 2019 [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/1*hCu6EpU9LVxeHL2cLN6UVQ.png)
Oltre alla selezione delle caratteristiche, entmax viene utilizzato anche per le probabilità di branching. Ciò viene fatto passando il risultato della funzione di branching, sottraendo una soglia appresa e scalando opportunamente. Questo valore viene quindi concatenato con 0 e passato alla funzione entmax per creare una distribuzione di probabilità a 2 classi, che è esattamente ciò di cui abbiamo bisogno per il branching.
![Equazione di branching da [1]. b_i è la soglia di branching tau_i è un valore appreso per scalare i dati (Figura dell'autore)](https://miro.medium.com/v2/resize:fit:640/format:webp/0*bWVGEq4eXFEVWwa3.png)
Utilizzando questo, possiamo definire un tensore “choice” C calcolando il prodotto esterno di tutte le distribuzioni di branching c. Questo può quindi essere moltiplicato per i valori nella foglia per creare il risultato della rete.
Ensemble
Come suggerisce il nome, questi alberi decisionali insensibili alle caratteristiche neurali sono insieme. Uno strato NODE è definito come una concatenazione di m alberi individuali, ognuno con le proprie decisioni di branching e valori di foglia. Come accennato in precedenza, questo insieme sinergizza con la natura insensibile delle singole alberature e aiuta ad aumentare l’accuratezza con una ridotta possibilità di overfitting.
NODE Multistrato
NODE è un’architettura flessibile che può essere addestrata da sola (risultando in un unico insieme di alberi decisionali) o con una struttura multi-layer complessa in cui ogni insieme di insiemi prende in input il layer precedente.
![Architettura NODE Multistrato (Figura da Popov et al. 2019 [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/1*WyQVp9Dg6JygVcKTPtYtAg.png)
L’architettura multistrato di NODE segue da vicino la popolare architettura DenseNet. Ogni layer NODE contiene diversi alberi i cui output vengono concatenati e sono input per i layer successivi. L’output finale viene quindi ottenuto facendo la media dell’output di tutti gli alberi di tutti i layer. Poiché ogni layer si basa su catene di tutte le previsioni precedenti, la rete può catturare dipendenze complesse.
Performance Sperimentale
Per testare la loro architettura, Popov et al. (2019) hanno confrontato NODE con CatBoost [2], XGBoost [4], una rete neurale completamente connessa, mGBDT [5] e DeepForest [6]. La loro metodologia ha coinvolto il test dei modelli su sei diversi dataset. In particolare, hanno effettuato un confronto utilizzando i parametri predefiniti di ciascun modello e un altro confronto in cui ciascun modello aveva iperparametri ottimizzati.
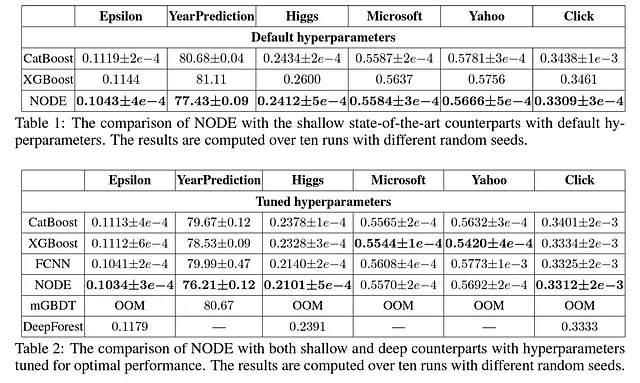
I risultati sperimentali per NODE sono estremamente incoraggianti. Innanzitutto, l’architettura NODE supera tutti gli altri modelli con i parametri predefiniti. Anche con parametri ottimizzati, NODE supera la maggior parte degli altri modelli su 4 dei 6 dataset selezionati.
Conclusioni
Incorporando i vantaggi degli alberi decisionali nell’architettura delle reti neurali, NODE apre nuove possibilità per le applicazioni di apprendimento profondo nei domini in cui prevale il dato tabellare strutturato, come finanza, assistenza sanitaria e analisi dei clienti.
Questo non significa che NODE sia perfetto, però. Innanzitutto, l’ensemble dell’architettura significa che molti dei guadagni di interpretabilità locale derivanti dall’utilizzo degli alberi decisionali neurali vengono persi e si può ottenere solo l’importanza globale delle caratteristiche dal modello. Tuttavia, questa architettura fornisce i mattoni per migliorare l’interpretabilità neurale e un modello di follow-up (NODE-GAM [7]) è stato proposto per colmare il divario di interpretabilità.
Inoltre, sebbene NODE superi molti modelli superficiali, la mia esperienza nell’usarlo ha indicato che richiede più tempo per l’addestramento, anche utilizzando le GPU (una conclusione supportata dai risultati sperimentali forniti dagli autori del paper).
Nel complesso, si tratta di un approccio estremamente promettente e che ho intenzione di utilizzare attivamente come componente dei modelli di apprendimento profondo che sviluppo in futuro.
Risorse e Riferimenti
- Documento NODE: https://arxiv.org/abs/1909.06312
- Codice NODE: https://github.com/Qwicen/node
- NODE può essere trovato anche nel pacchetto Pytorch Tabular: https://github.com/manujosephv/pytorch_tabular
- Se sei interessato a Machine Learning Interpretabile o Forecasting delle Serie Temporali, considera di seguirmi: https://medium.com/@upadhyan .
- Vedi i miei altri articoli sugli alberi decisionali neurali: https://medium.com/@upadhyan/list/3b4a9cb97b84
Riferimenti
[1] Popov, S., Morozov, S., & Babenko, A. (2019). Neural oblivious decision ensembles for deep learning on tabular data. Eight International Conference on Learning Representations.
[2] Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V., & Gulin, A. (2018). CatBoost: boosting imparziale con caratteristiche categoriche. Advances in neural information processing systems , 31 .
[3] Peters, B., Niculae, V., & Martins, A. (2019). Sparse Sequence-to-Sequence Models. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 1504–1519). Association for Computational Linguistics.
[4] Chen, T., & Guestrin, C. (2016, August). Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining (pp. 785–794).
[5] Feng, J., Yu, Y., & Zhou, Z. H. (2018). Multi-layered gradient boosting decision trees. Advances in neural information processing systems , 31 .
[6] Zhou, Z. H., & Feng, J. (2019). Deep forest. National science review , 6 (1), 74–86.
[7] Chang, C.H., Caruana, R., & Goldenberg, A. (2022). NODE-GAM: Neural Generalized Additive Model for Interpretable Deep Learning. In International Conference on Learning Representations .






