Dalla teoria alla pratica Costruire un classificatore k-Nearest Neighbors
Building a k-Nearest Neighbors classifier From theory to practice.
Il Classificatore dei k-Vicini piú Prossimi è un algoritmo di apprendimento automatico che assegna un nuovo punto dati alla classe piú comune tra i suoi k vicini piú prossimi. In questo tutorial, imparerai i passi base per costruire e applicare questo classificatore in Python.
Un altro giorno, un altro algoritmo classico: i vicini più vicini. Come il classificatore di Bayes ingenuo, è un metodo piuttosto semplice per risolvere i problemi di classificazione. L’algoritmo è intuitivo e ha un tempo di formazione imbattibile, il che lo rende un ottimo candidato da imparare quando si inizia la carriera di apprendimento automatico. Detto questo, fare previsioni è dolorosamente lento, specialmente per grandi set di dati. Le prestazioni per set di dati con molte funzionalità potrebbero anche non essere sorprendenti, a causa della maledizione della dimensionalità.
In questo articolo, imparerai
- come funziona il classificatore dei vicini più vicini
- perché è stato progettato in questo modo
- perché ha questi gravi svantaggi e, naturalmente,
- come implementarlo in Python utilizzando NumPy.
Poiché implementeremo il classificatore in modo conforme a scikit learn, vale la pena controllare anche il mio articolo Build your own custom scikit-learn Regression. Tuttavia, l’overhead di scikit-learn è piuttosto piccolo e dovresti essere in grado di seguire comunque.
- Perché c’è una sorta di pranzo gratis
- 8 Cose Potenzialmente Sorprendenti Da Sapere Sui Grandi Modelli Linguistici (LLM)
- Efficiente segmentazione delle immagini utilizzando PyTorch Parte 1.
Puoi trovare il codice sul mio Github.
Teoria
L’idea principale di questo classificatore è sorprendentemente semplice. Deriva direttamente dalla domanda fondamentale della classificazione:
Dato un punto dati x, qual è la probabilità che x appartenga a una certa classe c?
Nel linguaggio della matematica, cerchiamo la probabilità condizionata p ( c | x ). Mentre il classificatore di Bayes ingenuo cerca di modellare direttamente questa probabilità utilizzando alcune ipotesi, c’è un’altra intuizione per calcolare questa probabilità: il punto di vista frequentista della probabilità.
Il punto di vista ingenuo sulle probabilità
Ok, ma cosa significa questo adesso? Consideriamo il seguente esempio semplice: si lancia un dado a sei facce, possibilmente truccato, e si vuole calcolare la probabilità di ottenere un sei, ovvero p (lancio numero 6). Come si fa? Beh, si lancia il dado n volte e si annota quante volte è apparso un sei. Se hai visto il numero sei k volte, dici che la probabilità di vedere un sei è circa k / n. Nulla di nuovo o fantasia qui, giusto?
Ora, immaginate che vogliamo calcolare una probabilità condizionata, ad esempio
p(lancio del numero 6 | lancio di un numero pari)
Non hai bisogno del teorema di Bayes per risolvere questo problema. Basta lanciare di nuovo il dado e ignorare tutti i lanci con un numero dispari. Questo è ciò che fa la condizionatura: filtrare i risultati. Se hai lanciato il dado n volte, hai visto m numeri pari e k di essi erano sei, la probabilità sopra è circa k / m invece di k / n.
Motivare i vicini più vicini
Torniamo al nostro problema. Vogliamo calcolare p ( c | x ) dove x è un vettore contenente le caratteristiche e c è una certa classe. Come nell’esempio del dado, abbiamo bisogno di
- molti punti dati,
- filtrare quelli con le caratteristiche x e
- verificare quante volte questi punti dati appartengono alla classe c.
La frequenza relativa è il nostro tentativo per la probabilità p ( c | x ).
Vedi il problema qui?
In genere, non abbiamo molti punti dati con le stesse caratteristiche. Spesso solo uno, forse due. Ad esempio, immagina un set di dati con due caratteristiche: l’altezza (in cm) e il peso (in kg) delle persone. Le etichette sono maschio o femmina. Quindi, x= ( x ?, x ?) dove x ? è l’altezza e x ? è il peso, e c può assumere i valori maschio e femmina. Guardiamo alcuni dati finti:
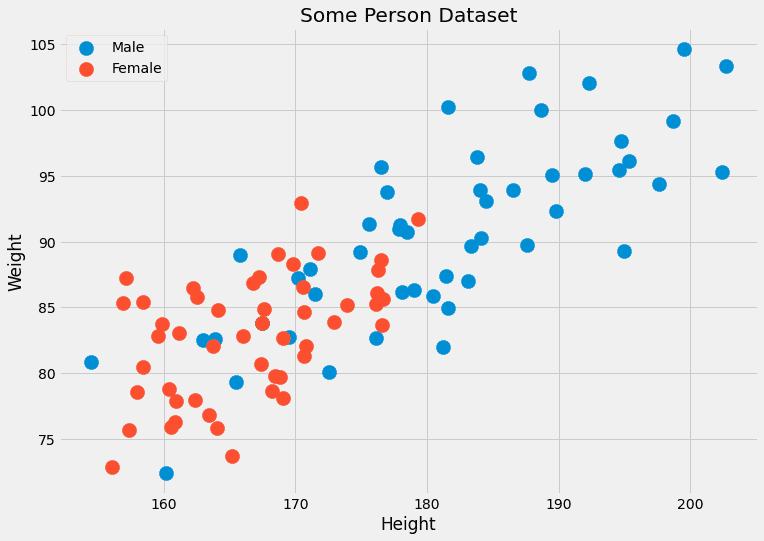
Dato che queste due caratteristiche sono continue, la probabilità di avere due, o anche diverse centinaia, di punti dati è trascurabile.
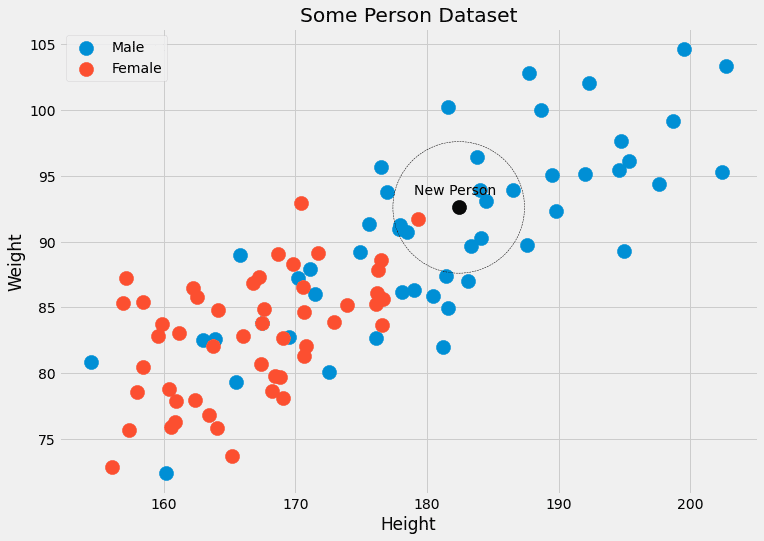
Un altro problema: cosa succede se vogliamo prevedere il genere per un punto dati con caratteristiche che non abbiamo mai visto prima, come (190,1, 85,2)? Questo è ciò che la previsione è effettivamente. Ecco perché questo approccio ingenuo non funziona. Ciò che fa invece l’algoritmo dei k-vicini più vicini è il seguente:
Cerca di approssimare la probabilità p ( c | x ) non con punti dati che hanno le caratteristiche x esatte, ma con punti dati con caratteristiche vicine a x.
È meno rigido, in un certo senso. Invece di aspettare molte persone con altezza=182,4 e peso=92,6, e verificare il loro genere, il metodo dei k -nearest neighbors permette di considerare persone che hanno caratteristiche simili. Il k nell’algoritmo è il numero di persone che consideriamo, è un iperparametro.
Questi sono parametri che noi o un algoritmo di ottimizzazione degli iperparametri come la grid search dobbiamo scegliere. Non sono direttamente ottimizzati dall’algoritmo di apprendimento.
L’algoritmo
Ora abbiamo tutto ciò di cui abbiamo bisogno per descrivere l’algoritmo.
Addestramento:
- Organizzare i dati di addestramento in qualche modo. Durante la predizione, questo ordine dovrebbe renderci possibile fornire i k punti più vicini per qualsiasi punto dati x.
- E questo è tutto! 😉
Predizione:
- Per un nuovo punto dati x , trovare i k vicini più vicini nei dati di addestramento organizzati.
- Aggregare le etichette di questi k vicini.
- Restituire l’etichetta/probabilità.
Finora non possiamo implementarlo, perché ci sono molte lacune che dobbiamo colmare.
- Cosa significa organizzare?
- Come misuriamo la vicinanza?
- Come aggregare?
Oltre al valore di k, questi sono tutti fattori che possiamo scegliere, e decisioni diverse ci danno algoritmi diversi. Facile, rispondiamo alle domande come segue:
- Organizzazione = salvare il dataset di addestramento così com’è
- Vicinanza = distanza euclidea
- Aggregazione = media
Questo richiede un esempio. Vediamo di nuovo l’immagine con i dati delle persone.
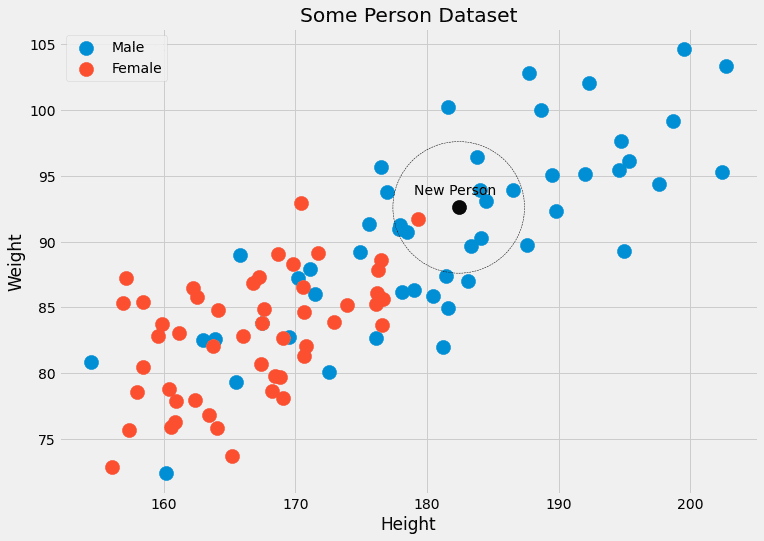
Possiamo vedere che i k = 5 punti dati più vicini al punto nero hanno 4 etichette maschili e un’etichetta femminile. Quindi potremmo restituire che la persona appartenente al punto nero è, in realtà, 4/5=80% maschio e 1/5=20% femmina. Se preferiamo una singola classe come output, restituireremo maschio. Nessun problema!
Ora, implementiamo il tutto.
Implementazione
La parte più difficile è trovare i vicini più vicini a un punto.
Una breve introduzione
Facciamo un piccolo esempio di come si può fare in Python. Partiamo da
import numpy as np
features = np.array([[1, 2], [3, 4], [1, 3], [0, 2]])
labels = np.array([0, 0, 1, 1])
new_point = np.array([1, 4])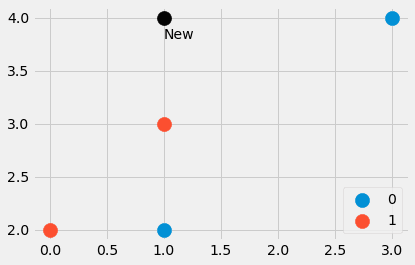
Abbiamo creato un piccolo dataset composto da quattro punti dati, così come un altro punto. Quali sono i punti più vicini? E il nuovo punto dovrebbe avere l’etichetta 0 o 1? Cerchiamo di scoprirlo. Digitando
distances = ((features - new_point)**2).sum(axis=1)otteniamo i quattro valori distances=[4, 4, 1, 5], che è la distanza euclidea quadrata dal punto new_point a tutti gli altri punti in features . Fantastico! Possiamo vedere che il punto numero tre è il più vicino, seguito dai punti numero uno e due. Il quarto punto è il più lontano.
Come possiamo estrarre i punti più vicini dall’array [4, 4, 1, 5]? Un distances.argsort() ci aiuta. Il risultato è [2, 0, 1, 3] che ci dice che il punto dati con indice 2 è il più piccolo (fuori dal punto numero tre), poi il punto con indice 0, poi con indice 1 e infine il punto con indice 3 è il più grande.
Si noti che argsort mette i primi 4 in distances prima dei secondi 4. A seconda dell’algoritmo di ordinamento, potrebbe essere il contrario, ma non entreremo in questi dettagli per questo articolo introduttivo.
Se vogliamo i tre vicini più vicini, ad esempio, possiamo ottenerli tramite
distances.argsort()[:3]e le etichette corrispondono a questi punti più vicini tramite
labels[distances.argsort()[:3]]Otteniamo [1, 0, 0], dove 1 è l’etichetta del punto più vicino a (1, 4), e gli zeri sono le etichette appartenenti ai prossimi due punti più vicini.
Questo è tutto ciò di cui abbiamo bisogno, passiamo al vero affare.
Il codice finale
Dovresti essere abbastanza familiare con il codice. L’unica nuova funzione è np.bincount che conta le occorrenze delle etichette. Notare che ho implementato prima un metodo predict_proba per calcolare le probabilità. Il metodo predict chiama solo questo metodo e restituisce l’indice (=classe) con la probabilità più alta usando una funzione argmax. La classe attende classi da 0 a C -1, dove C è il numero di classi.
Avviso legale: Questo codice non è ottimizzato, serve solo a scopo educativo.
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.utils.validation import check_X_y, check_array, check_is_fitted
class KNNClassifier(BaseEstimator, ClassifierMixin):
def __init__(self, k=3):
self.k = k
def fit(self, X, y):
X, y = check_X_y(X, y)
self.X_ = np.copy(X)
self.y_ = np.copy(y)
self.n_classes_ = self.y_.max() + 1
return self
def predict_proba(self, X):
check_is_fitted(self)
X = check_array(X)
res = []
for x in X:
distances = ((self.X_ - x)**2).sum(axis=1)
smallest_distances = distances.argsort()[:self.k]
closest_labels = self.y_[smallest_distances]
count_labels = np.bincount(
closest_labels,
minlength=self.n_classes_
)
res.append(count_labels / count_labels.sum())
return np.array(res)
def predict(self, X):
check_is_fitted(self)
X = check_array(X)
res = self.predict_proba(X)
return res.argmax(axis=1)E questo è tutto! Possiamo fare un piccolo test e vedere se concorda con il classificatore k -nearest neighbor di scikit-learn.
Testare il codice
Creiamo un altro piccolo dataset per il testing.
from sklearn.datasets import make_blobs
import numpy as np
X, y = make_blobs(n_samples=20, centers=[(0,0), (5,5), (-5, 5)], random_state=0)
X = np.vstack([X, np.array([[2, 4], [-1, 4], [1, 6]])])
y = np.append(y, [2, 1, 0])Sembra così:
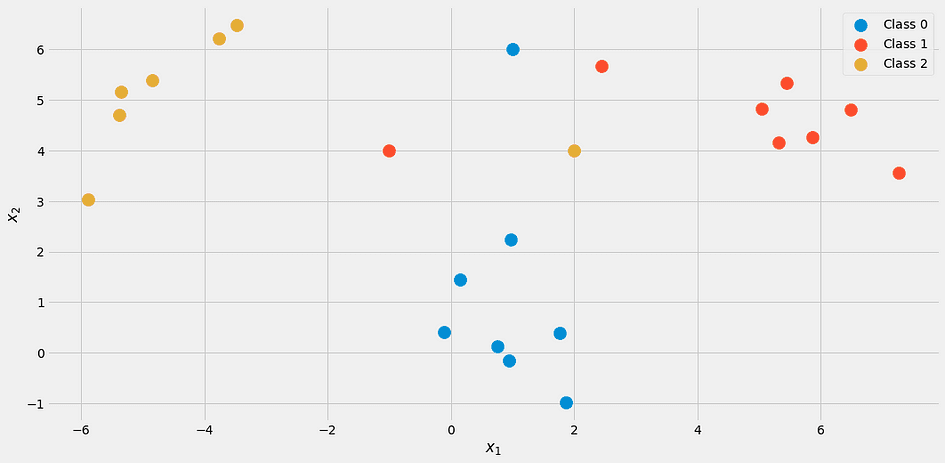
Usando il nostro classificatore con k = 3
my_knn = KNNClassifier(k=3)
my_knn.fit(X, y)
my_knn.predict_proba([[0, 1], [0, 5], [3, 4]])otteniamo
array([[1. , 0. , 0. ],
[0.33333333, 0.33333333, 0.33333333],
[0. , 0.66666667, 0.33333333]])Leggere l’output come segue: Il primo punto appartiene al 100% alla classe 1, il secondo punto si trova in ogni classe in modo uguale con il 33%, e il terzo punto è circa il 67% della classe 2 e il 33% della classe 3.
Se vuoi etichette concrete, prova
my_knn.predict([[0, 1], [0, 5], [3, 4]])che restituisce [0, 0, 1]. Si noti che in caso di parità, il modello come l’abbiamo implementato restituisce la classe inferiore, ecco perché il punto (0, 5) viene classificato come appartenente alla classe 0.
Se controlli l’immagine, ha senso. Ma rassicuriamoci con l’aiuto di scikit-learn.
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X, y)
my_knn.predict_proba([[0, 1], [0, 5], [3, 4]])Il risultato:
array([[1. , 0. , 0. ],
[0.33333333, 0.33333333, 0.33333333],
[0. , 0.66666667, 0.33333333]])Uff! Tutto sembra essere a posto. Controlliamo i confini di decisione dell’algoritmo, solo perché è bello.
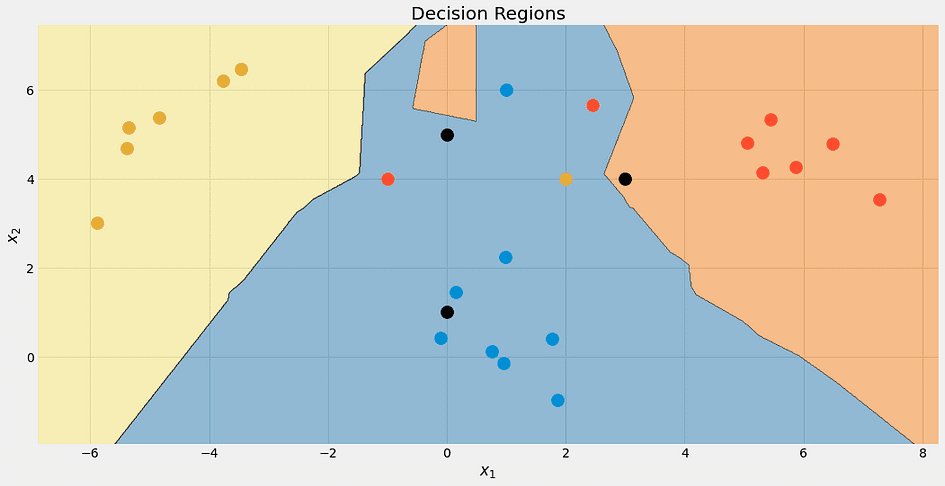
Di nuovo, il punto nero in alto non è completamente blu. È il 33% blu, rosso e giallo, ma l’algoritmo decide deterministicamente per la classe inferiore, che è blu.
Possiamo anche controllare i confini di decisione per diversi valori di k.
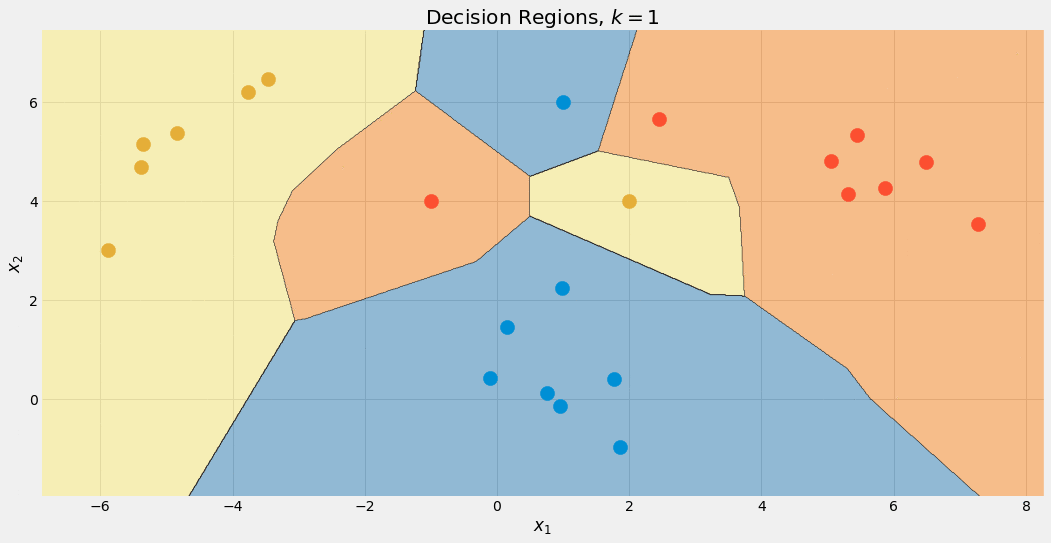
Si noti che la regione blu diventa più grande alla fine, a causa di questo trattamento preferenziale di questa classe. Possiamo anche vedere che per k = 1 i confini sono un disastro: il modello è sovradimensionato. Dall’altra parte dell’estremo, k è grande come la dimensione del dataset, e tutti i punti vengono utilizzati per la fase di aggregazione. Di conseguenza, ogni punto dati riceve la stessa previsione: la classe maggioritaria. Il modello è sottodimensionato in questo caso. La posizione ideale si trova da qualche parte in mezzo e può essere trovata utilizzando tecniche di ottimizzazione degli iperparametri.
Prima di arrivare alla fine, vediamo quali problemi ha questo algoritmo.
Svantaggi del k-Nearest Neighbors
I problemi sono i seguenti:
- Trovare i vicini più vicini richiede molto tempo, specialmente con la nostra implementazione ingenua. Se vogliamo prevedere la classe di un nuovo punto dati, dobbiamo controllarlo rispetto a ogni altro punto nel nostro dataset, il che è lento. Ci sono modi migliori per organizzare i dati utilizzando strutture dati avanzate, ma il problema persiste ancora.
- Seguendo il problema numero 1: di solito, si addestrano i modelli su computer più veloci e potenti e si può distribuire il modello su macchine più deboli successivamente. Pensiamo al deep learning, per esempio. Ma per i vicini più vicini di k, il tempo di addestramento è facile e il lavoro pesante è svolto durante il tempo di previsione, il che non vogliamo.
- Cosa succede se i vicini più vicini non sono affatto vicini? Allora non significano niente. Ciò può già accadere in dataset con un numero ridotto di funzionalità, ma con ancora più funzionalità la possibilità di incontrare questo problema aumenta drasticamente. Questo è anche ciò a cui le persone si riferiscono come la maledizione della dimensionalità. Una bella visualizzazione si trova in questo post di Cassie Kozyrkov .
In particolare, a causa del problema 2, non si vede il classificatore dei vicini più vicini di k in natura troppo spesso. È comunque un bel algoritmo che dovresti conoscere, e puoi anche usarlo per piccoli dataset, non c’è nulla di male in questo. Ma se hai milioni di punti dati con migliaia di funzionalità, le cose diventano difficili.
Conclusione
In questo articolo, abbiamo discusso come funziona il classificatore dei vicini più vicini di k e perché il suo design ha senso. Cerca di stimare la probabilità di un punto dati x che appartiene a una classe c, nonché possibile utilizzando i punti dati più vicini a x. È un approccio molto naturale, e quindi questo algoritmo viene solitamente insegnato all’inizio dei corsi di apprendimento automatico.
Si noti che è davvero semplice costruire anche un regressore dei k-vicini più vicini. Invece di contare le occorrenze delle classi, basta fare la media delle etichette dei vicini più vicini per ottenere una previsione. Puoi implementarlo da solo, è solo una piccola modifica!
Poi l’abbiamo implementato in modo diretto, imitando l’API di scikit-learn. Ciò significa che è possibile utilizzare questo stimatore anche nelle pipeline e nelle ricerche in griglia di scikit-learn. Questo è un grande vantaggio poiché abbiamo persino l’iperparametro k che è possibile ottimizzare utilizzando la ricerca in griglia, la ricerca casuale o l’ottimizzazione bayesiana.
Tuttavia, questo algoritmo ha alcuni seri problemi. Non è adatto per grandi dataset e non può essere utilizzato su macchine meno potenti per effettuare previsioni. Insieme alla suscettibilità alla maledizione della dimensionalità, è un algoritmo che è teoricamente bello ma può essere utilizzato solo per set di dati più piccoli.
Il Dr. Robert Kübler è un Data Scientist presso METRO.digital e Autore presso Towards Data Science.
Originale . Ripubblicato con il permesso.





