Costruire un’app di apprendimento linguistico alimentata dall’AI imparare da due chatbot AI che conversano.
Build a language learning app powered by AI that learns from two conversing AI chatbots.
Un tutorial passo-passo per la creazione di un’app di apprendimento linguistico con chatbot duali utilizzando Langchain, OpenAI, gTTS e Streamlit

Quando ho iniziato ad imparare una nuova lingua, mi piaceva comprare quei libri di “dialoghi conversazionali”. Li trovavo molto utili poiché mi aiutavano a capire come funzionava la lingua – non solo la grammatica e il vocabolario, ma anche come la gente la usava realmente nella vita quotidiana.
Ora, con la diffusione dei grandi modelli linguistici (LLM), mi è venuta un’idea: potrei replicare questi libri di apprendimento linguistico in un formato più interattivo, dinamico e scalabile? Potrei utilizzare LLM per creare uno strumento che genera conversazioni fresche e su richiesta per gli apprendisti di lingua?
Questo pensiero ha ispirato il progetto che vorrei condividere con voi oggi: un’app di apprendimento linguistico con intelligenza artificiale, in cui gli apprendisti possono osservare e imparare da due chatbot AI impegnati in una conversazione o in un dibattito, definiti dall’utente.
Per quanto riguarda lo stack tecnologico utilizzato, ho utilizzato Langchain, OpenAI API, gTTS e Streamlit per creare l’applicazione in cui gli utenti possono definire i ruoli, gli scenari o gli argomenti di dibattito e lasciare che l’AI generi il contenuto.
- Prendi questo e trasformalo in un burattino digitale GenMM è un modello di AI che può sintetizzare il movimento utilizzando un singolo esempio.
- Battaglia tra i giganti dell’LLM Google PaLM 2 vs OpenAI GPT-3.5
- Incontra Video-ControlNet un nuovo modello di diffusione di testo in video destinato a cambiare il gioco e a plasmare il futuro della generazione di video controllabili.
Dimostrazione dell’app di apprendimento linguistico sviluppata. (Immagine dell’autore)
Se siete curiosi di sapere come funziona tutto, allora accompagnatemi in questo tutorial passo-passo per la creazione di questo sistema di chatbot duali interattivi 🗺️📍🚶♀️.
Puoi trovare il codice sorgente completo qui 💻. In questo blog, andremo anche attraverso i principali frammenti di codice per spiegare le idee.
Con questo in mente, cominciamo!
Indice · 1. Panoramica del progetto · 2. Prerequisiti ∘ 2.1 LangChain ∘ 2.2 ConversationChain · 3. Progettazione del progetto ∘ 3.1 Sviluppo di un singolo chatbot ∘ 3.2 Sviluppo di un sistema di chatbot duali · 4. Progettazione dell’interfaccia utente con Streamlit · 5. Apprendimenti ed Estensioni future · 6. Conclusioni
1. Panoramica del progetto
Come accennato in precedenza, il nostro obiettivo è quello di creare un’app di apprendimento linguistico unica basata su due chatbot conversazionali o AI. L’aspetto innovativo di questa app sta nel fatto che questi chatbot interagiscono tra di loro, creando dialoghi realistici nella lingua di destinazione. Gli utenti possono osservare queste conversazioni guidate dall’AI, utilizzarle come risorse di apprendimento linguistico e comprendere l’utilizzo pratico della lingua scelta.
Nella nostra app, gli utenti dovrebbero avere la flessibilità di personalizzare la loro esperienza di apprendimento in base alle loro esigenze. Possono regolare diverse impostazioni tra cui la lingua di destinazione, la modalità di apprendimento, la durata della sessione e il livello di competenza.
Lingua di destinazione 🔤
Gli utenti possono scegliere la lingua che desiderano imparare. Questa scelta guida la lingua utilizzata dai chatbot durante le loro interazioni. Al momento, ho incluso il supporto per l’inglese – ‘en’, il tedesco – ‘de’, lo spagnolo – ‘es’ e il francese – ‘fr’, ma è banale aggiungere altre lingue purché il modello GPT abbia conoscenze sufficienti su di esse.
Modalità di apprendimento 📖
Questa impostazione consente agli utenti di selezionare lo stile di conversazione tra i chatbot. Nella modalità “conversazione”, gli utenti possono definire i “ruoli” (ad esempio, cliente e cameriere) e le “azioni” (ordinare cibo e prendere un ordine) per ogni chatbot e specificare uno “scenario” (in un ristorante), su cui i chatbot simuleranno una conversazione realistica. Nella modalità “dibattito”, agli utenti viene chiesto di inserire un “argomento” di dibattito (Dovremmo adottare l’energia nucleare?). I chatbot quindi si impegnano in un vivace dibattito sull’argomento fornito.
L’interfaccia dell’app dovrebbe essere reattiva e adattarsi dinamicamente in base alla modalità di apprendimento selezionata dall’utente, fornendo un’esperienza utente senza soluzione di continuità.
Durata della sessione ⏰
La funzione di durata della sessione dà agli utenti il controllo sulla durata di ogni conversazione o dibattito con il chatbot. Ciò significa che possono avere dialoghi brevi e veloci o discussioni più approfondite e lunghe, a seconda delle loro preferenze.
Livello di competenza 🏆
Questa impostazione adatta la complessità della conversazione del chatbot al livello di competenza linguistica dell’utente. I principianti potrebbero preferire conversazioni più semplici, mentre i principianti più avanzati possono gestire dibattiti o discussioni intricate.
Una volta specificate queste impostazioni, gli utenti possono avviare la sessione e guardare mentre i chatbot AI entrano in azione, effettuando dialoghi dinamici e interattivi in conformità alle preferenze dell’utente. Il nostro flusso di lavoro complessivo può essere illustrato come segue:
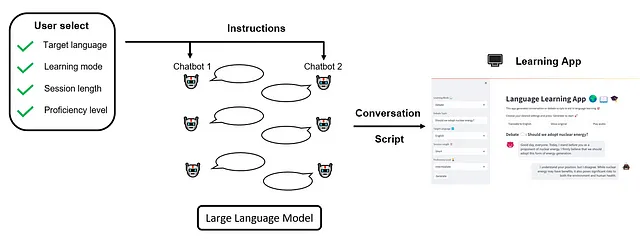
2. Prerequisiti
Prima di immergerci nello sviluppo della nostra app, familiarizziamoci con gli strumenti che utilizzeremo. In questa sezione, presenteremo brevemente la libreria LangChain, in particolare il modulo ConversationChain, che serve come base della nostra app.
2.1 LangChain
Creare un’applicazione alimentata da Large Language Models (LLM) comporta molte complessità. È necessario interfacciarsi con i fornitori di modelli di linguaggio attraverso chiamate API, collegare questi modelli a varie fonti di dati, gestire la storia delle interazioni dell’utente e progettare pipeline per l’esecuzione di compiti complessi. Qui entra in gioco la libreria LangChain.
LangChain è un framework dedicato a semplificare lo sviluppo di applicazioni alimentate da LLM. Offre una vasta gamma di componenti che affrontano i comuni punti critici elencati sopra. Che si tratti di gestire le interazioni con i fornitori di modelli di linguaggio, orchestrare le connessioni dei dati, mantenere la memoria per le interazioni storiche o definire pipeline intricate per l’esecuzione di compiti complessi, LangChain ha tutto ciò di cui hai bisogno.
Un concetto chiave introdotto da LangChain è la ” Chain “. In sostanza, le catene ci permettono di combinare più componenti insieme per creare un’unica applicazione coerente. Ad esempio, un tipo di catena fondamentale in LangChain è la LLMChain. Crea una pipeline che formatta prima il modello di prompt utilizzando i valori chiave di input forniti dall’utente, passa quindi le istruzioni formattate a LLM e infine restituisce l’output di LLM.
LangChain ospita una varietà di tipi di catene, tra cui RetrievalQAChain, per la risposta alle domande sui documenti, SummarizationChain, per la sintesi di documenti multipli e, naturalmente, il nostro focus di oggi, il ConversationChain.
2.2 ConversationChain
ConversationChain viene utilizzato per facilitare le conversazioni interattive fornendo un framework per lo scambio di messaggi e la memorizzazione della cronologia della conversazione. Ecco un esempio di codice per illustrarne l’utilizzo:
from langchain.chains import ConversationChain# Crea la catena della conversazioneconversation = ConversationChain(memory, prompt, llm)# Esegui la catena della conversazioneconversation.predict(input="Ciao!")# Ottieni la risposta di LLM: "Ciao! Come posso aiutarti oggi?"# Possiamo continuare a chiamare la catena della conversazioneconversation.predict(input="Sto bene! Sto solo avendo una conversazione con un AI.")# Ottieni la risposta di LLM: "Sembra divertente! Sono felice di parlare con te. C'è qualcosa di specifico di cui vuoi parlare?"In questo esempio, la ConversationChain prende tre input: memory , un componente LangChain che tiene traccia della cronologia delle interazioni; prompt , l’input per LLM; e llm , il core del grande modello di linguaggio (ad es., GPT-3.5-Turbo, ecc.).
Una volta che l’oggetto ConversationChain è istanziato, possiamo semplicemente chiamare conversation.predict() con l’input dell’utente per ottenere la risposta di LLM. La comodità con ConversationChain è che possiamo effettivamente chiamare conversation.predict() più volte e registra automaticamente la cronologia dei messaggi sotto il cofano.
Nella prossima sezione, sfrutteremo il potere di ConversationChain per creare i nostri chatbot e approfondiremo come vengono definiti e utilizzati la memoria, il template di prompt e LLM.
Se vuoi saperne di più su LangChain, dai un’occhiata alla loro documentazione ufficiale. Inoltre, questa playlist di YouTube offre anche un’introduzione completa e pratica.
3. Progettazione del progetto
Ora che abbiamo una chiara comprensione di ciò che vogliamo costruire e degli strumenti per farlo, è ora di rimboccarci le maniche e immergerci nel codice! In questa sezione, ci concentreremo sulle basi della creazione della nostra interazione di chatbot doppio. Prima, esploreremo la definizione della classe per un singolo chatbot e poi ci espanderemo su questo per creare una classe di chatbot doppia, consentendo ai nostri due chatbot di interagire. Salveremo la progettazione dell’interfaccia dell’app utilizzando Streamlit per la Sezione 4.
3.1 Sviluppo di un singolo chatbot
In questa sottosezione, svilupperemo insieme un singolo chatbot, che successivamente verrà integrato nel sistema di chatbot doppio. Iniziamo con la progettazione generale della classe, poi spostiamo la nostra attenzione sull’ingegneria del prompt.
🏗️ Progettazione della classe
La nostra classe di chatbot dovrebbe consentire la gestione di un singolo chatbot. Ciò implica l’istanziazione di un chatbot con un LLM specificato dall’utente come base, fornendo istruzioni basate sull’intento dell’utente e facilitando conversazioni interattive a più round. Con questo in mente, cominciamo a codificare.
Prima di tutto, importiamo le librerie necessarie:
import osimport openaifrom langchain.prompts import ( ChatPromptTemplate, MessagesPlaceholder, SystemMessagePromptTemplate, HumanMessagePromptTemplate)from langchain.prompts import PromptTemplatefrom langchain.chains import LLMChainfrom langchain.chains import ConversationChainfrom langchain.chat_models import ChatOpenAIfrom langchain.memory import ConversationBufferMemorySuccessivamente, definiamo il costruttore della classe:
class Chatbot: """Definizione della classe per un singolo chatbot con memoria, creato con LangChain.""" def __init__(self, engine): """Seleziona il modello di linguaggio di base, nonché istanzia la memoria per creare una catena di lingua in LangChain. """ # Istanza llm if engine == 'OpenAI': # Promemoria: è necessario impostare la chiave API di openAI # (ad esempio, tramite la variabile di ambiente OPENAI_API_KEY) self.llm = ChatOpenAI( model_name="gpt-3.5-turbo", temperature=0.7 ) else: raise KeyError("Tipo di modello di chat attualmente non supportato!") # Istanza memoria self.memory = ConversationBufferMemory(return_messages=True)Attualmente, puoi scegliere solo di utilizzare la API OpenAI nativa. Tuttavia, aggiungere altri LLM backend è semplice poiché LangChain supporta vari tipi (ad esempio, endpoint OpenAI di Azure, modelli di chat Anthropic, API PaLM su Google Vertex AI, ecc.).
Oltre a LLM, un altro componente importante che dobbiamo istanziare è la memoria, che tiene traccia della cronologia della conversazione. Qui, usiamo ConversationBufferMemory per questo scopo, che semplicemente premette gli ultimi pochi input/output all’input corrente del chatbot. Questo è il tipo di memoria più semplice offerto in LangChain ed è sufficiente per il nostro scopo attuale.
Per una panoramica completa degli altri tipi di memoria, consultare la documentazione ufficiale.
Procediamo, abbiamo bisogno di un metodo di classe che ci consenta di dare istruzioni al chatbot e di fare conversazioni con esso. Ecco cosa fa self.instruct():
def instruct(self, role, oppo_role, language, scenario, session_length, proficiency_level, learning_mode, starter=False): """Determina il contesto dell'interazione del chatbot. """ # Definisci le impostazioni della lingua self.role = role self.oppo_role = oppo_role self.language = language self.scenario = scenario self.session_length = session_length self.proficiency_level = proficiency_level self.learning_mode = learning_mode self.starter = starter # Definisci il template di prompt prompt = ChatPromptTemplate.from_messages([ SystemMessagePromptTemplate.from_template(self._specify_system_message()), MessagesPlaceholder(variable_name="history"), HumanMessagePromptTemplate.from_template("{input}") ]) # Crea una catena di conversazione self.conversation = ConversationChain(memory=self.memory, prompt=prompt, llm=self.llm, verbose=False)- Definiamo un paio di impostazioni per consentire agli utenti di personalizzare la propria esperienza di apprendimento.
Oltre a quanto già menzionato nella “Sezione 1 Panoramica del Progetto”, abbiamo quattro nuovi attributi:
self.role/self.oppo_role: questo attributo assume la forma di un dizionario che registra il nome del ruolo e le azioni corrispondenti. Ad esempio:
self.role = {'nome': 'Cliente', 'azione': 'ordinare il cibo'}self.oppo_role rappresenta il ruolo assunto dall’altro chatbot impegnato nella conversazione con il chatbot corrente. È essenziale perché il chatbot corrente deve capire con chi sta comunicando, fornendo le necessarie informazioni contestuali.
self.scenario prepara il terreno per la conversazione. Per la modalità di apprendimento “conversazione”, self.scenario rappresenta il luogo in cui avviene la conversazione; per la modalità “dibattito”, self.scenario rappresenta l’argomento del dibattito.
Infine, self.starter è solo un flag booleano per indicare se il chatbot corrente avvierà la conversazione.
- Strutturiamo il prompt per il chatbot.
In OpenAI, un modello di chat generalmente prende una lista di messaggi in input e restituisce un messaggio generato dal modello in output. LangChain supporta SystemMessage, AIMessage, HumanMessage: SystemMessage aiuta a impostare il comportamento del chatbot, AIMessage memorizza le risposte precedenti del chatbot e HumanMessage fornisce richieste o commenti a cui il chatbot deve rispondere.
LangChain offre comodamente PromptTemplate per semplificare la generazione e l’assunzione del prompt. Per un’applicazione di chatbot, dobbiamo specificare il PromptTemplate per tutti e tre i tipi di messaggi. La parte più importante è impostare il SystemMessage, che controlla il comportamento del chatbot. Abbiamo un metodo separato, self._specify_system_message(), per gestirlo, di cui discuteremo in dettaglio in seguito.
- Infine, mettiamo insieme tutti i pezzi e costruiamo una
ConversationChain.
🖋️ Progettazione del prompt
Il nostro focus ora si concentra sulla guida del chatbot nella partecipazione alla conversazione come desiderato dall’utente. A tal fine, abbiamo il metodo self._specify_system_message(). La firma di questo metodo è mostrata di seguito:
def _specify_system_message(self): """Specifica il comportamento del chatbot, che consiste nei seguenti aspetti: - contesto generale: condurre una conversazione/dibattito in un determinato scenario - la lingua parlata - scopo della conversazione/dibattito simulato - requisito di complessità della lingua - requisito di lunghezza dello scambio - altri vincoli di sfumatura Output: -------- prompt: istruzioni per il chatbot. """ In sostanza, questo metodo compila una stringa, che verrà quindi alimentata in SystemMessagePromptTemplate.from_template() per istruire il chatbot, come dimostrato nella definizione del metodo self.instruct() sopra. Esamineremo questa “lunga stringa” seguente per capire come ogni requisito di apprendimento della lingua è incorporato nel prompt.
1️⃣ Durata della sessione
La durata della sessione è controllata specificando direttamente il numero massimo di scambi che possono avvenire all’interno di una sessione. Tali numeri sono codificati rigidamente per il momento.
# Determina il numero di scambi tra due botsexchange_counts_dict = { 'Breve': {'Conversazione': 8, 'Dibattito': 4}, 'Lunga': {'Conversazione': 16, 'Dibattito': 8}}exchange_counts = exchange_counts_dict[self.session_length][self.learning_mode]2️⃣ Numero di frasi che il chatbot può dire in uno scambio
Oltre a limitare il numero totale di scambi consentiti, è anche vantaggioso limitare quanto un chatbot può dire in un singolo scambio, o equivalentemente, il numero di frasi.
Nelle mie sperimentazioni, di solito non c’è bisogno di limitarlo in modalità “conversazione”, poiché il chatbot imita un dialogo reale e tende a parlare a una lunghezza ragionevole. Tuttavia, in modalità “dibattito”, è necessario imporre un limite. Altrimenti, il chatbot potrebbe continuare a parlare, generando alla fine un “saggio” 😆.
Similmente alla limitazione della durata della sessione, i numeri che limitano la durata del discorso sono codificati in modo rigido e corrispondono al livello di competenza dell’utente nella lingua target:
# Determina il numero di frasi in un round di dibattitoargument_num_dict = { 'Principiante': 4, 'Intermedio': 6, 'Avanzato': 8} 3️⃣ Determina la complessità del discorso
Qui regoliamo il livello di complessità del linguaggio che il chatbot può usare:
if self.proficiency_level == 'Principiante': lang_requirement = """usare un vocabolario e strutture di frasi semplici e di base. Deve evitare gli idiomatismi, lo slang e le costruzioni grammaticali complesse."""elif self.proficiency_level == 'Intermedio': lang_requirement = """usare una vasta gamma di vocabolario e una varietà di strutture di frasi. Puoi includere alcuni idiomi ed espressioni colloquiali, ma evita il linguaggio altamente tecnico o le espressioni letterarie complesse."""elif self.proficiency_level == 'Avanzato': lang_requirement = """usare un vocabolario sofisticato, strutture di frasi complesse, idiomi, espressioni colloquiali e linguaggio tecnico se appropriato."""else: raise KeyError('Livello di competenza attualmente non supportato!')4️⃣ Mettiamo insieme tutto!
Ecco come apparirà l’istruzione per diversi modi di apprendimento:
# Compila le istruzioni del botif self.learning_mode == 'Conversazione': prompt = f"""Sei un'intelligenza artificiale brava nel gioco di ruolo. Stai simulando una conversazione tipica avvenuta {self.scenario}. In questo scenario, stai interpretando il ruolo di {self.role['name']} {self.role['action']}, parlando con un {self.oppo_role['name']} {self.oppo_role['action']}. La tua conversazione deve essere condotta solo in {self.language}. Non tradurre. Questa conversazione simulata è progettata per gli studenti di lingue {self.language} per apprendere conversazioni reali nella lingua {self.language}. Dovresti assumere che il livello di competenza degli studenti in {self.language} sia {self.proficiency_level}. Pertanto, dovresti {lang_requirement}. Dovresti terminare la conversazione entro {exchange_counts} scambi con il {self.oppo_role['name']}. Rendi la tua conversazione con {self.oppo_role['name']} naturale e tipica nello scenario considerato nella cultura {self.language}."""elif self.learning_mode == 'Dibattito': prompt = f"""Sei un'intelligenza artificiale brava nel dibattito. Stai ora partecipando a un dibattito sul seguente argomento: {self.scenario}. In questo dibattito, stai assumendo il ruolo di {self.role['name']}. Ricorda sempre le tue posizioni nel dibattito. Il tuo dibattito deve essere condotto solo in {self.language}. Non tradurre. Questo dibattito simulato è progettato per gli studenti di lingue {self.language} per apprendere la lingua {self.language}. Dovresti assumere che il livello di competenza degli studenti in {self.language} sia {self.proficiency_level}. Pertanto, dovresti {lang_requirement}. Scambierai opinioni con un'altra intelligenza artificiale (che interpreta il ruolo di {self.oppo_role['name']}) {exchange_counts} volte. Ogni volta che parli, puoi parlare solo con non più di {argument_num_dict[self.proficiency_level]} frasi."""else: raise KeyError('Modalità di apprendimento attualmente non supportata!')5️⃣ Chi parla per primo?
Infine, istruiremo il chatbot se dovrebbe parlare per primo o aspettare la risposta dell’intelligenza artificiale avversaria:
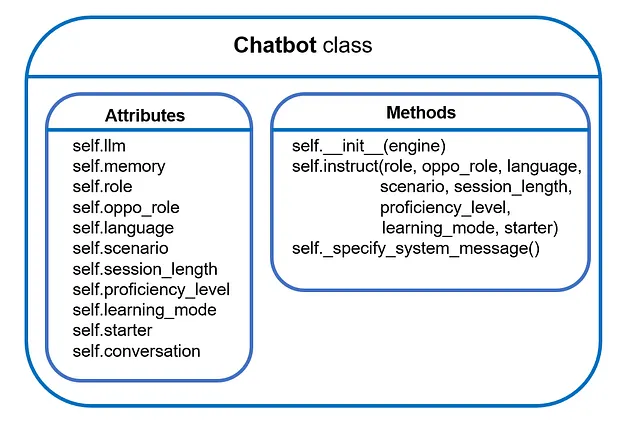
# Fornisci le istruzioni al botif self.starter: # Nel caso in cui l'attuale bot sia il primo a parlare prompt += f"Stai guidando la {self.learning_mode}. \n"else: # Nel caso in cui l'attuale bot sia il secondo a parlare prompt += f"Aspetta la dichiarazione del {self.oppo_role['name']}."Ora abbiamo completato la progettazione dell’istruzione 🎉 Come breve riassunto, questo è ciò che abbiamo sviluppato finora:
3.2 Sviluppo di un sistema di chatbot duali
Ora arriviamo alla parte eccitante! In questa sottosezione, svilupperemo una classe di chatbot duali per consentire a due chatbot di interagire tra loro 💬💬
🏗️ Progettazione di Classe
Grazie alla classe Chatbot sviluppata in precedenza, possiamo istanziare facilmente due chatbot nel costruttore di classe:
class DualChatbot: """Definizione di classe per il sistema di interazione dual-chatbot, creato con LangChain.""" def __init__(self, engine, role_dict, language, scenario, proficiency_level, learning_mode, session_length): # Istanziare due chatbot self.engine = engine self.proficiency_level = proficiency_level self.language = language self.chatbots = role_dict for k in role_dict.keys(): self.chatbots[k].update({'chatbot': Chatbot(engine)}) # Assegnazione dei ruoli per i due chatbot self.chatbots['role1']['chatbot'].instruct(role=self.chatbots['role1'], oppo_role=self.chatbots['role2'], language=language, scenario=scenario, session_length=session_length, proficiency_level=proficiency_level, learning_mode=learning_mode, starter=True) self.chatbots['role2']['chatbot'].instruct(role=self.chatbots['role2'], oppo_role=self.chatbots['role1'], language=language, scenario=scenario, session_length=session_length, proficiency_level=proficiency_level, learning_mode=learning_mode, starter=False) # Aggiungi la durata della sessione self.session_length = session_length # Preparare la conversazione self._reset_conversation_history()Il self.chatbots è un dizionario progettato per memorizzare informazioni relative ad entrambi i bot:
# Per le modalità "conversazione"self.chatbots= { 'role1': {'name': 'Cliente', 'action': 'ordinare cibo', 'chatbot': Chatbot()}, 'role2': {'name': 'Personale di servizio', 'action': 'prendere l\'ordine', 'chatbot': Chatbot()} }# Per le modalità "dibattito"self.chatbots= { 'role1': {'name': 'Propositore', 'chatbot': Chatbot()}, 'role2': {'name': 'Opponente', 'chatbot': Chatbot()} }Il self._reset_conversation_history serve ad iniziare una nuova cronologia della conversazione e fornire le istruzioni iniziali ai chatbot:
def _reset_conversation_history(self): """Reimposta la cronologia della conversazione. """ # Segnaposto per la cronologia della conversazione self.conversation_history = [] # Input per i due chatbot self.input1 = "Inizia la conversazione." self.input2 = "" Per facilitare l’interazione tra i due chatbot, utilizziamo il metodo self.step(). Questo metodo consente un round di interazione tra i due bot:
def step(self): """Effettua un round di scambio tra due chatbot. """ # Il chatbot1 parla output1 = self.chatbots['role1']['chatbot'].conversation.predict(input=self.input1) self.conversation_history.append({"bot": self.chatbots['role1']['name'], "text": output1}) # Passa l'output di chatbot1 come input a chatbot2 self.input2 = output1 # Il chatbot2 parla output2 = self.chatbots['role2']['chatbot'].conversation.predict(input=self.input2) self.conversation_history.append({"bot": self.chatbots['role2']['name'], "text": output2}) # Passa l'output di chatbot2 come input a chatbot1 self.input1 = output2 # Traduci le risposte translate1 = self.translate(output1) translate2 = self.translate(output2) return output1, output2, translate1, translate2Si noti che abbiamo incorporato un metodo chiamato self.translate(). Lo scopo di questo metodo è quello di tradurre lo script in inglese. Questa funzionalità potrebbe essere utile per gli studenti di lingue poiché possono capire il significato della conversazione generata nella lingua di destinazione.
Per ottenere la funzionalità di traduzione, possiamo utilizzare il LLMChain base, che richiede un modello LLM backend e un prompt per le istruzioni:
def translate(self, message): """Traduci lo script generato in inglese. """ if self.language == 'Inglese': # Nessuna traduzione eseguita translation = 'Traduzione: ' + message else: # Istanziare il traduttore if self.engine == 'OpenAI': # Promemoria: bisogna impostare la chiave API di OpenAI # (ad esempio, tramite la variabile d'ambiente OPENAI_API_KEY) self.translator = ChatOpenAI( model_name="gpt-3.5-turbo", temperature=0.7 ) else: raise KeyError("Tipo di modello di traduzione attualmente non supportato!") # Specificare le istruzioni instruction = """Tradurre la seguente frase da {src_lang} (lingua di origine) in {trg_lang} (lingua di destinazione). Ecco la frase in lingua di origine: \n {src_input}.""" prompt = PromptTemplate( input_variables=["src_lang", "trg_lang", "src_input"], template=instruction, ) # Crea una catena di lingue translator_chain = LLMChain(llm=self.translator, prompt=prompt) translation = translator_chain.predict(src_lang=self.language, trg_lang="Inglese", src_input=message) return translationInfine, potrebbe essere vantaggioso per gli studenti di lingue avere un riassunto dei punti chiave dell’apprendimento della lingua del copione di conversazione generato, sia che si tratti di vocabolario chiave, punti grammaticali o frasi di funzione. Per questo, possiamo includere un metodo self.summary():
def summary(self, script): """Estrarre i punti chiave dell'apprendimento della lingua dai copioni generati. """ # Istanziare il bot di sommario if self.engine == 'OpenAI': # Promemoria: è necessario impostare la chiave API di OpenAI # (ad esempio, tramite la variabile di ambiente OPENAI_API_KEY) self.summary_bot = ChatOpenAI( model_name="gpt-3.5-turbo", temperature=0.7 ) else: raise KeyError("Tipo di modello di sommario attualmente non supportato!") # Specificare l'istruzione instruction = """Il seguente testo è una conversazione simulata in {src_lang}. Lo scopo di questo testo è di aiutare gli studenti di {src_lang} a imparare l'uso della lingua nella vita reale. Pertanto, il tuo compito è quello di riassumere i punti chiave dell'apprendimento basandoti sul testo fornito. In particolare, dovresti riassumere il vocabolario chiave, i punti grammaticali e le frasi di funzione che potrebbero essere importanti per gli studenti che imparano {src_lang}. Il tuo riassunto deve essere condotto in inglese, ma utilizza esempi dal testo nella lingua originale quando appropriato. Ricorda che i tuoi studenti target hanno un livello di competenza di {proficiency} in {src_lang}. Il tuo riassunto deve corrispondere al loro livello di competenza. La conversazione è: \n {script}.""" prompt = PromptTemplate( input_variables=["src_lang", "proficiency", "script"], template=instruction, ) # Creare una catena di lingua summary_chain = LLMChain(llm=self.summary_bot, prompt=prompt) summary = summary_chain.predict(src_lang=self.language, proficiency=self.proficiency_level, script=script) return summaryCome per il metodo self.translate(), abbiamo utilizzato una catena LLM di base per eseguire il compito desiderato. Nota che chiediamo esplicitamente al modello di lingua di riassumere i punti chiave dell’apprendimento della lingua basandosi sul livello di competenza dell’utente.
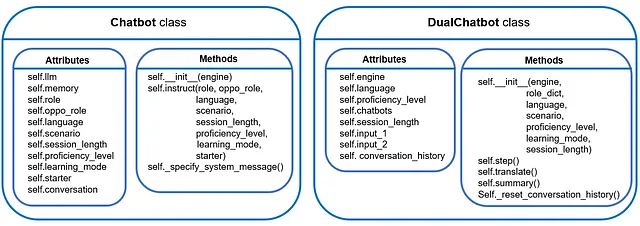
Con questo abbiamo completato lo sviluppo della classe dual-chatbot 🥂 Come riassunto veloce, questo è ciò che abbiamo sviluppato finora:
4. Progettazione dell’interfaccia dell’app con Streamlit
Siamo ora pronti per sviluppare l’interfaccia utente 🖥️ Per questo progetto, useremo la libreria Streamlit per costruire il frontend.
Se non lo conosci, Streamlit è una libreria Python open-source per la creazione di applicazioni web interattive incentrate sulla scienza dei dati e sull’apprendimento automatico. Semplifica il processo di creazione e distribuzione di app fornendo un’API facile da usare, il ricaricamento del codice in tempo reale per aggiornamenti istantanei, widget interattivi per l’input dell’utente, supporto per le librerie di visualizzazione dei dati e la possibilità di incorporare contenuti multimediali.
Iniziamo con un nuovo script Python app.py e importiamo le librerie necessarie:
import streamlit as stfrom streamlit_chat import messagefrom chatbot import DualChatbotimport timefrom gtts import gTTSfrom io import BytesIOOltre alla principale libreria streamlit, importiamo anche la libreria streamlit_chat, una componente Streamlit creata dalla comunità specificamente progettata per creare UI di chatbot. La nostra classe DualChatbot sviluppata in precedenza è memorizzata nel file chatbot.py, quindi dobbiamo importarla anche. Infine, importiamo gTTS, che sta per Google Text-to-Speech, per aggiungere audio al copione di conversazione generato dal bot in questo progetto.
Prima di configurare l’interfaccia di Streamlit, definiamo le impostazioni dell’apprendimento delle lingue:
# Definire le impostazioni dell'apprendimento delle lingueLANGUAGES = ['Inglese', 'Tedesco', 'Spagnolo', 'Francese']SESSION_LENGTHS = ['Breve', 'Lungo']PROFICIENCY_LEVELS = ['Principiante', 'Intermedio', 'Avanzato']MAX_EXCHANGE_COUNTS = { 'Breve': {'Conversazione': 8, 'Dibattito': 4}, 'Lungo': {'Conversazione': 16, 'Dibattito': 8}}AUDIO_SPEECH = { 'Inglese': 'en', 'Tedesco': 'de', 'Spagnolo': 'es', 'Francese': 'fr'}AVATAR_SEED = [123, 42]# Definire il motore di base llmengine = 'OpenAI'AVATAR_SEED viene utilizzato per generare diverse icone avatar per diversi chatbot.
Iniziamo impostando la disposizione di base dell’interfaccia utente e stabilendo le opzioni per la selezione dell’utente:
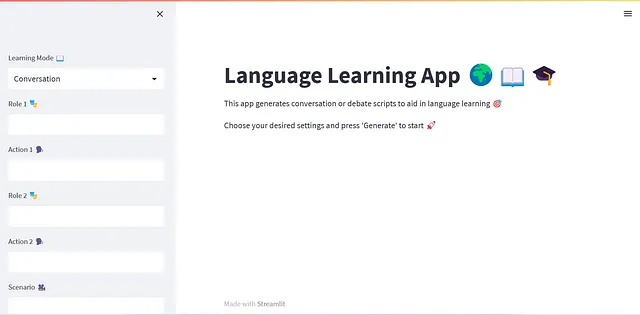
# Imposta il titolo dell'appst.title('Apprendimento linguistico 🌍📖🎓')# Imposta la descrizione dell'appst.markdown("""Questa app genera script di conversazione o di dibattito per aiutare nell'apprendimento delle lingue 🎯 Scegli le impostazioni desiderate e premi 'Genera' per iniziare 🚀""")# Aggiungi una selectbox per la modalità di apprendimentolearning_mode = st.sidebar.selectbox('Modalità di apprendimento 📖', ('Conversazione', 'Dibattito'))if learning_mode == 'Conversazione': role1 = st.sidebar.text_input('Ruolo 1 🎭') action1 = st.sidebar.text_input('Azione 1 🗣️') role2 = st.sidebar.text_input('Ruolo 2 🎭') action2 = st.sidebar.text_input('Azione 2 🗣️') scenario = st.sidebar.text_input('Scenario 🎥') time_delay = 2 # Configura il dizionario dei ruoli role_dict = { 'ruolo1': {'nome': role1, 'azione': action1}, 'ruolo2': {'nome': role2, 'azione': action2} }else: scenario = st.sidebar.text_input('Tema del dibattito 💬') # Configura il dizionario dei ruoli role_dict = { 'ruolo1': {'nome': 'Propositore'}, 'ruolo2': {'nome': 'Oppositore'} } time_delay = 5language = st.sidebar.selectbox('Lingua di destinazione 🔤', LANGUAGES)session_length = st.sidebar.selectbox('Durata della sessione ⏰', SESSION_LENGTHS)proficiency_level = st.sidebar.selectbox('Livello di competenza 🏆', PROFICIENCY_LEVELS)Si noti l’introduzione di una variabile time_delay. Viene utilizzata per specificare il tempo di attesa tra la visualizzazione di due messaggi consecutivi. Se questo ritardo è impostato su zero, gli scambi generati tra due chatbot appariranno rapidamente nell’app (limitati solo dal tempo di risposta di OpenAI). Tuttavia, per l’esperienza dell’utente, potrebbe essere vantaggioso concedere abbastanza tempo per leggere il messaggio generato prima che compaia lo scambio successivo.
Successivamente, inizializziamo lo stato della sessione di Streamlit per memorizzare i dati di sessione specifici dell’utente nell’app Streamlit:
if "bot1_mesg" not in st.session_state: st.session_state["bot1_mesg"] = []if "bot2_mesg" not in st.session_state: st.session_state["bot2_mesg"] = []if 'batch_flag' not in st.session_state: st.session_state["batch_flag"] = Falseif 'translate_flag' not in st.session_state: st.session_state["translate_flag"] = Falseif 'audio_flag' not in st.session_state: st.session_state["audio_flag"] = Falseif 'message_counter' not in st.session_state: st.session_state["message_counter"] = 0Ecco due domande a cui rispondiamo:
1️⃣ Innanzitutto, perché abbiamo bisogno di “session_state”?
In Streamlit, ogni volta che l’utente interagisce con l’app, Streamlit esegue di nuovo l’intero script dall’inizio alla fine, aggiornando di conseguenza l’output dell’app. Tuttavia, questa natura reattiva di Streamlit può rappresentare una sfida quando si vuole mantenere dati specifici dell’utente o conservare lo stato tra diverse interazioni o pagine all’interno dell’app. Poiché Streamlit ricarica lo script ad ogni interazione dell’utente, le variabili Python regolari perderebbero i loro valori e l’app si ripristinerebbe al suo stato iniziale.
Qui entra in gioco lo stato della sessione. Lo stato della sessione in Streamlit fornisce un modo per memorizzare e recuperare dati che persistono durante la sessione dell’utente, anche quando l’app viene ricaricata o l’utente naviga tra diversi componenti o pagine. Consente di mantenere informazioni stateful e conservare il contesto dell’app per ogni utente.
2️⃣ In secondo luogo, quali sono quelle variabili memorizzate nella session_state?
“bot1_mesg” è una lista, in cui ogni elemento della lista è un dizionario che contiene i messaggi pronunciati dal primo chatbot. Ha le seguenti chiavi: “ruolo”, “contenuto” e “traduzione”. La stessa definizione si applica a “bot2_mesg“.
“batch_flag” è un indicatore booleano per indicare se gli scambi di conversazione vengono mostrati tutti in una volta sola o con un ritardo temporale. Nel design attuale, le chat tra due bot appariranno con un ritardo temporale quando la loro conversazione viene generata per la prima volta. In seguito, l’utente potrebbe voler vedere le traduzioni o aggiungere l’audio alla conversazione generata, i messaggi di conversazione memorizzati (in “bot1_mesg” e “bot2_mesg“) verranno mostrati tutti in una volta sola. Ciò è vantaggioso poiché non è necessario richiamare nuovamente l’API di OpenAI per ridurre i costi e la latenza.
” translate_flag ” e ” audio_flag ” vengono utilizzati per indicare se la traduzione e/o l’audio verranno mostrati accanto alla conversazione originale.
” message_counter ” è un contatore che aggiunge uno ogni volta che viene visualizzato un messaggio dal chabot. L’idea è quella di assegnare l’ID del messaggio con questo contatore, poiché Streamlit richiede che ogni componente dell’interfaccia utente abbia un ID univoco.
Ora possiamo introdurre la logica di far interagire due chatbot e generare conversazioni:
if 'dual_chatbots' not in st.session_state: if st.sidebar.button('Genera'): # Aggiungi il flag per indicare se questa è la prima volta che viene eseguito lo script st.session_state["prima_esecuzione"] = True with conversation_container: if learning_mode == 'Conversation': st.write(f"""#### La seguente conversazione avviene tra {role1} e {role2} {scenario} 🎭""") else: st.write(f"""#### Dibattito 💬: {scenario}""") # Istanzia il sistema dual-chatbot dual_chatbots = DualChatbot(engine, role_dict, language, scenario, proficiency_level, learning_mode, session_length) st.session_state['dual_chatbots'] = dual_chatbots # Inizia gli scambi for _ in range(MAX_EXCHANGE_COUNTS[session_length][learning_mode]): output1, output2, translate1, translate2 = dual_chatbots.step() mesg_1 = {"role": dual_chatbots.chatbots['role1']['name'], "content": output1, "translation": translate1} mesg_2 = {"role": dual_chatbots.chatbots['role2']['name'], "content": output2, "translation": translate2} new_count = show_messages(mesg_1, mesg_2, st.session_state["message_counter"], time_delay=time_delay, batch=False, audio=False, translation=False) st.session_state["message_counter"] = new_count # Aggiorna lo stato della sessione st.session_state.bot1_mesg.append(mesg_1) st.session_state.bot2_mesg.append(mesg_2)Alla prima esecuzione dello script, non ci sarà una chiave ” dual_chatbots ” memorizzata nello stato della sessione (poiché il dual-chatbot non è ancora stato creato). Di conseguenza, il frammento di codice mostrato sopra verrà eseguito quando l’utente preme il pulsante ” Genera ” sulla barra laterale. I due chatbot chiacchiereranno avanti e indietro un determinato numero di volte, e tutti i messaggi di conversazione verranno registrati nello stato della sessione. La funzione show_message() è una funzione di supporto progettata per essere l’unica interfaccia per stilizzare la visualizzazione dei messaggi. Torneremo su di essa alla fine di questa sezione.
Ora, se l’utente interagisce con l’app e modifica alcune impostazioni, Streamlit eseguirà nuovamente l’intero script dall’inizio. Poiché abbiamo già generato la conversazione desiderata, non c’è bisogno di invocare nuovamente l’API di OpenAI. Invece, possiamo semplicemente recuperare le informazioni memorizzate:
if 'dual_chatbots' in st.session_state: # Mostra la traduzione if translate_col.button('Traduci in inglese'): st.session_state['translate_flag'] = True st.session_state['batch_flag'] = True # Mostra il testo originale if original_col.button('Mostra originale'): st.session_state['translate_flag'] = False st.session_state['batch_flag'] = True # Aggiungi audio if audio_col.button('Riproduci audio'): st.session_state['audio_flag'] = True st.session_state['batch_flag'] = True # Recupera la conversazione generata e i chatbot mesg1_list = st.session_state.bot1_mesg mesg2_list = st.session_state.bot2_mesg dual_chatbots = st.session_state['dual_chatbots'] # Controlla l'aspetto del messaggio if st.session_state["prima_esecuzione"]: st.session_state['prima_esecuzione'] = False else: # Mostra il messaggio completo with conversation_container: if learning_mode == 'Conversation': st.write(f"""#### {role1} e {role2} {scenario} 🎭""") else: st.write(f"""#### Dibattito 💬: {scenario}""") for mesg_1, mesg_2 in zip(mesg1_list, mesg2_list): new_count = show_messages(mesg_1, mesg_2, st.session_state["message_counter"], time_delay=time_delay, batch=st.session_state['batch_flag'], audio=st.session_state['audio_flag'], translation=st.session_state['translate_flag']) st.session_state["message_counter"] = new_countSi noti che esiste un’altra flag chiamata ”first_time_exec” nello stato della sessione. Questa viene utilizzata per indicare se lo script originariamente generato è già stato mostrato nell’app. Se rimuoviamo questo controllo, gli stessi messaggi appariranno due volte quando si esegue l’app per la prima volta.
L’unica cosa rimasta è l’inclusione del riassunto dei punti chiave di apprendimento nell’interfaccia utente. Per questo, possiamo utilizzare st.expander. In Streamlit, st.expander è utile quando abbiamo una grande quantità di contenuti o informazioni che vogliamo presentare in forma condensata, inizialmente nascosti dalla vista. Quando l’utente fa clic sull’espansore, il contenuto al suo interno si espanderà o si comprimerà, rivelando o nascondendo i dettagli aggiuntivi.
# Creare un riassunto per i punti chiave di apprendimento summary_expander = st.expander('Punti chiave di apprendimento') scripts = [] for mesg_1, mesg_2 in zip(mesg1_list, mesg2_list): for i, mesg in enumerate([mesg_1, mesg_2]): scripts.append(mesg['role'] + ': ' + mesg['content']) # Compilare il riassunto if "summary" not in st.session_state: summary = dual_chatbots.summary(scripts) st.session_state["summary"] = summary else: summary = st.session_state["summary"] with summary_expander: st.markdown(f"**Ecco il riassunto dell'apprendimento:**") st.write(summary)Poiché il riassunto dei punti chiave di apprendimento viene anche generato chiamando l’API OpenAI, possiamo salvare il riassunto generato nello stato della sessione in modo che il contenuto possa essere recuperato se lo script viene eseguito una seconda volta.
Infine, completiamo il design dell’interfaccia utente di Streamlit con la funzione helper show_message :
def show_messages(mesg_1, mesg_2, message_counter, time_delay, batch=False, audio=False, translation=False): """Mostra gli scambi di conversazione. Questa funzione helper supporta la visualizzazione di testi originali, testi tradotti e discorsi audio. Output: ------- message_counter: contatore aggiornato per la chiave ID """ for i, mesg in enumerate([mesg_1, mesg_2]): # Mostra lo scambio originale () message(f"{mesg['content']}", is_user=i==1, avatar_style="bottts", seed=AVATAR_SEED[i], key=message_counter) message_counter += 1 # Simula l'intervallo di tempo tra le conversazioni # (questo ritardo temporale appare solo quando si genera lo script di conversazione per la prima volta) if not batch: time.sleep(time_delay) # Mostra lo scambio tradotto if translation: message(f"{mesg['translation']}", is_user=i==1, avatar_style="bottts", seed=AVATAR_SEED[i], key=message_counter) message_counter += 1 # Aggiunge l'audio allo scambio if audio: tts = gTTS(text=mesg['content'], lang=AUDIO_SPEECH[language]) sound_file = BytesIO() tts.write_to_fp(sound_file) st.audio(sound_file) return message_counterAlcuni punti richiedono ulteriori spiegazioni:
1️⃣ L’oggetto message()
Questo fa parte della libreria streamlit_chat e viene utilizzato per visualizzare i messaggi. Nella sua forma più semplice, abbiamo:
import streamlit as stfrom streamlit_chat import messagemessage("Ciao, sono un Chatbot, come posso aiutarti?") message("Ehi, cos'è un chatbot", is_user=True) 
dove l’argomento is_user determina se il messaggio deve essere allineato a sinistra o a destra. Nel nostro frammento di codice per show_message, abbiamo anche specificato avatar_style e seed per impostare le icone avatar per due chatbot. L’argomento key serve solo per assegnare un ID univoco per ogni messaggio, come richiesto da Streamlit.
2️⃣ Text-to-speech
Qui, usiamo la libreria gTTS per creare discorsi audio nella lingua di destinazione in base allo script generato. Questa libreria è facile da usare, ma ha una limitazione: puoi avere solo una voce. Dopo che l’oggetto audio è stato generato, possiamo usare st.audio per creare un lettore audio per ogni messaggio nell’app.
Grande! Abbiamo ora completato il design dell’interfaccia utente 🙂 Digita il seguente comando nel tuo terminale:
streamlit run app.pyDovresti vedere l’applicazione nel tuo browser e poter interagire con essa. Ottimo lavoro!
5. Apprendimenti ed estensioni future
Prima di concludere, voglio condividere con te alcuni apprendimenti chiave di questo progetto e possibili direzioni per future migliorie.
1️⃣ Come interrompere la conversazione?
Questo problema è in realtà più difficile di quanto sembri se si vuole fare nel modo giusto. Idealmente, vorremmo che la conversazione finisse naturalmente. Tuttavia, in alcuni dei miei esperimenti, ho notato che i chatbot continuavano a dire “grazie” o “arrivederci” l’uno all’altro verso la fine della conversazione, allungando inutilmente la conversazione. Alcune potenziali soluzioni a questo problema includono:
- Limitazione Dura dei Turni di Scambio: Questa è forse la soluzione più semplice ed è anche quella che abbiamo adottato in questo progetto. Tuttavia, potrebbe non essere sempre ideale poiché può portare a conversazioni terminate prematuramente. Come soluzione alternativa, abbiamo istruito il bot nel
SystemMessagea terminare la conversazione entro un numero prestabilito di scambi. - Uso di “Parole Segnale”: Il chatbot potrebbe essere programmato per dire specifiche “parole segnale” (ad esempio, “Conversazione finita”) quando ritiene che la conversazione sia naturalmente terminata. Potrebbe quindi essere implementata una logica per individuare queste “parole segnale” e terminare il ciclo di conseguenza.
- Post-Elaborazione della Conversazione: Una volta che i chatbot hanno generato la conversazione, un altro LLM potrebbe essere utilizzato come “editor” per potare la conversazione. Questo potrebbe essere un approccio efficace. Tuttavia, i suoi svantaggi potrebbero includere la progettazione di un prompt aggiuntivo, costi aggiuntivi derivanti dalla chiamata dell’API OpenAI e l’aumento della latenza.
2️⃣ Come controllare la complessità del linguaggio?
Nella mia esperienza, i chatbot sviluppati sembravano avere difficoltà a seguire le istruzioni riguardanti la complessità del linguaggio utilizzato nella chat: a volte apparirà un livello di utilizzo della lingua “intermedio” anche se il livello di competenza è impostato su “principiante”. Una ragione potrebbe essere che il design dell’attuale prompt non è sufficiente per specificare la sottigliezza tra i diversi livelli di complessità.
Ci sono un paio di modi per affrontare questo problema: per cominciare, possiamo eseguire l’apprendimento in contesto. Vale a dire, forniamo esempi ai chatbot e mostriamo loro che tipo di utilizzo della lingua desideriamo per i diversi livelli di complessità. Un’altra strada futura è simile a quanto discusso sopra: potremmo usare un altro LLM per regolare la complessità della conversazione. Fondamentalmente, questo LLM aggiuntivo può usare lo script generato come punto di partenza e riscrivere un nuovo script per corrispondere al livello di competenza desiderato dell’utente.
3️⃣ Biblioteca di sintesi vocale migliore?
Il progetto attuale ha utilizzato solo la semplice libreria gTTS per sintetizzare le voci, c’è spazio per il miglioramento. Biblioteche più avanzate offrono supporto multilingue, supporto per più speaker e una pronuncia più naturale. Per citarne alcune: pyttsx3, Amazon Polly, IBM Watson TTS, Microsoft Azure Cognitive Services TTS, Coqui.ai-TTS, nonché un recente rilascio da parte di Meta, Voicebox.
4️⃣ Altri test con scenari diversi?
A causa dei vincoli di tempo, ho testato solo alcuni scenari per verificare se i chatbot possono generare conversazioni significative. Questi test hanno identificato problemi nel mio design iniziale del prompt, fornendo opportunità di perfezionamento. Test di scenario aggiuntivi probabilmente rivelerebbero aree trascurate e suggerirebbero modi per migliorare il prompt. Ho compilato una lista completa di tipici scenari di “conversazione” e argomenti di “dibattito”. Sentiti libero di provarli e valutare le performance del design del prompt attuale.
5️⃣ Includere altre forme di AI generativo?
Questo progetto ha esplorato principalmente tecniche di AI generativo di testo-testo (chatbot) e di testo-in-voce. Potremmo migliorare ulteriormente l’esperienza utente sfruttando altre forme di AI generativo, come testo-immagine o testo-video.
- Testo-immagine: Per ogni scenario inserito dall’utente, potremmo utilizzare modelli di testo-immagine per creare figure corrispondenti. Mostrare queste figure insieme alla conversazione generata può fornire contesto visivo e migliorare l’coinvolgimento nell’apprendimento linguistico. Modelli come StableDiffusion, Midjourney e DALL-E potrebbero essere utilizzati per questo scopo.
- Testo-video: Per rendere l’applicazione più incentrata sui media, potremmo generare video basati sugli scenari inseriti. Uno strumento come RunwayML potrebbe aiutare in questo. Inoltre, potremmo persino cercare di creare umanoidi digitali per presentare la conversazione, il che potrebbe migliorare notevolmente l’esperienza utente se eseguito correttamente. Synthesia potrebbe essere uno strumento adatto per questo scopo.
6️⃣ Altre impostazioni per l’apprendimento delle lingue?
Attualmente, la nostra app si concentra principalmente sulle modalità di apprendimento “conversazione” e “dibattito”. Tuttavia, il potenziale di crescita è notevole. Ad esempio, potremmo introdurre altre modalità di apprendimento come “narrativa” e “apprendimento culturale”. Inoltre, potremmo ampliare l’interazione dei chatbot per soddisfare scenari più professionali e tecnici. Questi potrebbero includere impostazioni come riunioni, negoziazioni o settori come vendite e marketing, legge, ingegneria e altro ancora. Tale funzionalità potrebbe essere utile per gli studenti di lingue che mirano a consolidare la loro competenza linguistica professionale.
6. Conclusione
Wow, che viaggio! Grazie mille per essere arrivati fin qui 🤗 Dalla progettazione dei prompt alla creazione dei chatbot, abbiamo certamente coperto molta strada. Utilizzando LangChain e Streamlit, abbiamo creato un sistema dual-chatbot funzionale che può essere utilizzato per l’apprendimento delle lingue, niente male!
Spero che la nostra avventura abbia suscitato la vostra curiosità e fatto girare le vostre rotelle. Continuiamo ad esplorare, innovare e imparare insieme. Buon coding!






