GPT vs BERT Quale è Migliore?
GPT vs BERT which one is better?)
Confrontare due grandi modelli di linguaggio: approccio ed esempio

L’aumento della popolarità dell’AI generativa ha portato anche ad un aumento del numero di grandi modelli di linguaggio. In questa storia, effettuerò un confronto tra due di essi: GPT e BERT. GPT (Generative Pre-trained Transformer) è sviluppato da OpenAI ed è basato sull’architettura a sola decodifica. D’altra parte, BERT (Bidirectional Encoder Representations from Transformers) è sviluppato da Google ed è un modello pre-addestrato a sola codifica.
Entrambi sono tecnicamente diversi, ma hanno un obiettivo simile: svolgere compiti di elaborazione del linguaggio naturale. Molti articoli li confrontano dal punto di vista tecnico. Tuttavia, in questa storia, li confronterei in base alla qualità del loro obiettivo, ovvero l’elaborazione del linguaggio naturale.
Approccio di confronto
Come confrontare due architetture tecniche completamente diverse? GPT è un’architettura a sola decodifica e BERT è un’architettura a sola codifica. Quindi un confronto tecnico di un’architettura solo-decodifica vs solo-codifica è come confrontare Ferrari vs Lamborgini – entrambi sono ottimi ma con tecnologie completamente diverse sotto il telaio.
Tuttavia, possiamo fare un confronto basato sulla qualità di un comune compito di linguaggio naturale che entrambi possono svolgere, ovvero la generazione di embedding. Gli embedding sono rappresentazioni vettoriali di un testo. Gli embedding costituiscono la base di qualsiasi compito di elaborazione del linguaggio naturale. Quindi, se possiamo confrontare la qualità degli embedding, allora ci può aiutare a giudicare la qualità dei compiti di linguaggio naturale, poiché gli embedding costituiscono la base per l’elaborazione del linguaggio naturale tramite l’architettura del trasformatore.
- Immersione teorica profonda nella regressione lineare
- DeepMind RoboCat Un modello di IA robotico auto-apprendente.
- Incontra BITE un nuovo metodo che ricostruisce la forma e le pose tridimensionali di un cane da un’immagine, anche con pose difficili come seduto e sdraiato.
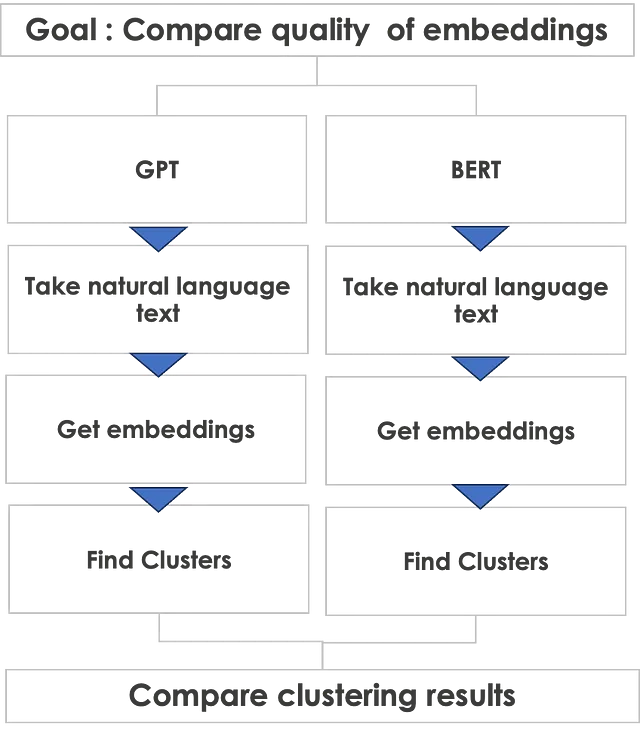
Di seguito viene mostrato l’approccio di confronto che adotterò.
Iniziamo con GPT
Ho fatto una moneta al volo e GPT ha vinto! Quindi cominciamo con GPT prima. Prenderò il testo dal dataset delle recensioni di Amazon sui cibi prelibati. Le recensioni sono un buon modo per testare entrambi i modelli, poiché le recensioni sono espresse in linguaggio naturale e sono molto spontanee. Racchiudono il sentimento dei clienti e possono contenere tutti i tipi di lingue – buone, cattive, brutte! Inoltre, possono avere molte parole sbagliate, emoji e gergo comunemente usato.
Ecco un esempio del testo della recensione.

Per ottenere gli embedding del testo usando GPT, dobbiamo effettuare una chiamata API a OpenAI. Il risultato è un embedding o un vettore di dimensioni di 1540 per ogni testo. Qui c’è un esempio di dati che include gli embedding.

Il passo successivo è il clustering e la visualizzazione. Si può utilizzare KMeans per clusterizzare il vettore di embedding e utilizzare TSNE per ridurre le 1540 dimensioni a 2 dimensioni. Qui di seguito sono mostrati i risultati dopo il clustering e la riduzione della dimensionalità per GPT.
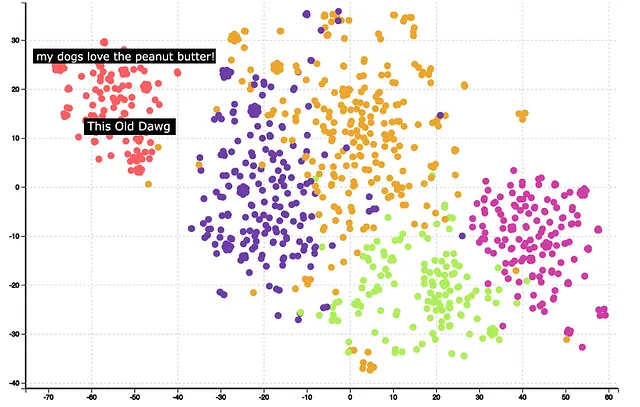
Si può notare che i cluster sono molto ben formati. Passando il mouse su alcuni dei cluster si può capire il significato dei cluster. Ad esempio, il cluster rosso è relativo al cibo per cani. Ulteriori analisi mostrano anche che le incastonature GPT hanno correttamente identificato che la parola ‘Dog’ e ‘Dawg’ sono simili e le ha collocate nello stesso cluster.
Nel complesso, le incastonature GPT forniscono buoni risultati come indicato dalla qualità del clustering.
È ora il turno di BERT
Può BERT fare meglio? Scopriamolo. Ci sono molteplici versioni del modello BERT come bert-base-case, bert-base-uncased, ecc. Essenzialmente hanno diverse dimensioni di vettori di incastonatura. Qui c’è il risultato basato su Bert base che ha una dimensione di incastonatura di 768.
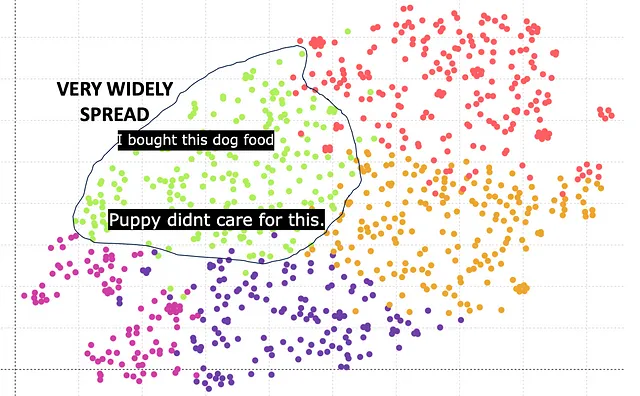
Il cluster verde corrisponde al cibo per cani. Tuttavia si può notare che i cluster sono ampiamente diffusi e non molto compatti rispetto a GPT. La ragione principale è che la lunghezza del vettore di incastonatura di 768 è inferiore rispetto alla lunghezza del vettore di incastonatura di 1540 di GPT.
Felizmente, BERT offre anche una dimensione di incastonatura più elevata di 1024. Ecco i risultati.
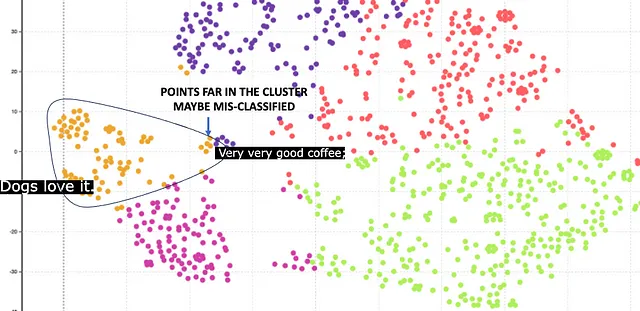
Qui il cluster arancione corrisponde al cibo per cani. Il cluster è relativamente compatto, il che è un risultato migliore rispetto all’incastonatura di 768. Tuttavia, ci sono alcuni punti che sono lontani dal centro. Questi punti sono classificati in modo errato. Ad esempio, c’è una recensione di caffè, ma è stata classificata in modo errato come cibo per cani perché ha la parola Dog in essa.
Conclusione
Chiaramente, GPT fa un lavoro migliore e fornisce incastonature di alta qualità rispetto a BERT. Tuttavia, non vorrei dare tutto il merito a GPT poiché ci sono altri aspetti del confronto. Ecco una tabella riepilogativa

GPT vince su BERT per la qualità dell’incastonatura fornita dalla maggiore dimensione dell’incastonatura. Tuttavia, GPT richiedeva un’API a pagamento, mentre BERT è gratuito. Inoltre, il modello BERT è open-source e non è nero scatola, quindi è possibile effettuare ulteriori analisi per capirlo meglio. I modelli GPT di OpenAI sono scatole nere.
In conclusione, consiglio di utilizzare BERT per il testo complesso di Nisoo come pagine web o libri che hanno un testo curato. GPT può essere usato per testo molto complesso come le recensioni dei clienti che sono completamente in linguaggio naturale e non sono curati.
Implementazione Tecnica
Ecco uno snippet di codice Python che implementa il processo descritto nella storia. Per illustrazione, ho dato l’esempio di GPT. Quello di BERT è simile.
##Importa pacchettiimport openaiimport pandas as pdimport reimport contextlibimport ioimport tiktokenfrom openai.embeddings_utils import get_embeddingfrom sklearn.cluster import KMeansfrom sklearn.manifold import TSNE##Legge i dati_nome_file = 'percorso_del_file'df = pd.read_csv(file_name)##Imposta i parametrimodello_di_incastonatura = "text-embedding-ada-002"incastonatura_di_codifica = "cl100k_base" # questa è la codifica per text-embedding-ada-002max_tokens = 8000 # il massimo per text-embedding-ada-002 è 8191top_n = 1000encoding = tiktoken.get_encoding(embedding_encoding)col_embedding = 'incastonatura'n_tsne=2n_iter = 1000##Ottiene l'incastonatura da OpenAIdef get_embedding(text, model): openai.api_key = "YOUR_OPENAPI_KEY" text = text.replace("\n", " ") return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']col_txt = 'Recensione'df["n_tokens"] = df[col_txt].apply(lambda x: len(encoding.encode(x)))df = df[df.n_tokens <= max_tokens].tail(top_n)df = df[df.n_tokens > 0].reset_index(drop=True) ##Rimuove se non ci sono token, ad esempio le righe vuotedf[col_embedding] = df[col_txt].apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))matrix = np.array(df[col_embedding].to_list())##Fa il clusteringkmeans_model = KMeans(n_clusters=n_clusters,random_state=0)kmeans = kmeans_model.fit(matrix)kmeans_clusters = kmeans.predict(matrix)#TSNEtsne_model = TSNE(n_components=n_tsne, verbose=0, random_state=42, n_iter=n_iter,init='random')tsne_out = tsne_model.fit_transform(matrix)Citazione del dataset
Il dataset è disponibile qui con licenza CC0 di pubblico dominio. Sia l’uso commerciale che non commerciale sono consentiti .
Recensioni di Amazon Fine Food
Analizza ~ 500.000 recensioni di cibo da Amazon
www.kaggle.com
Si prega di iscriversi per rimanere informati ogni volta che pubblico una nuova storia.
Ricevi un’email ogni volta che Pranay Dave pubblica.
Ricevi un’email ogni volta che Pranay Dave pubblica. Iscrivendoti, creerai un account Nisoo se non ne hai già uno…
pranay-dave9.medium.com
Puoi anche unirti a Nisoo con il mio link di riferimento
Unisciti a Nisoo con il mio link di riferimento – Pranay Dave
Come membro di Nisoo, una parte della tua quota di iscrizione va agli scrittori che leggi e ottieni l’accesso completo ad ogni storia…
pranay-dave9.medium.com
Risorse aggiuntive
Sito web
Puoi visitare il mio sito web per fare analisi senza alcuna codifica. https://experiencedatascience.com
Canale YouTube
Visita il mio canale YouTube per imparare casi d’uso di scienza dei dati e AI usando demo
La Scienza dei Dati Dimostrata
Impara la scienza dei dati attraverso demo. Qualunque sia la tua professione, siediti, rilassati e goditi i video. Il mio nome è…
www.youtube.com