Come Light & Wonder ha costruito una soluzione di manutenzione predittiva per le macchine da gioco su AWS
Light & Wonder built a predictive maintenance solution for gaming machines on AWS.
Questo post è stato scritto in collaborazione con Aruna Abeyakoon e Denisse Colin di Light and Wonder (L&W).
Con sede a Las Vegas, Light & Wonder, Inc. è la principale azienda globale di giochi cross-platform che fornisce prodotti e servizi di gioco d’azzardo. In collaborazione con AWS, Light & Wonder ha sviluppato di recente una soluzione sicura, Light & Wonder Connect (LnW Connect), che rappresenta un’industria-first per lo streaming di telemetria e dati di salute delle macchine da gioco elettroniche distribuite in tutto il mondo, quando LnW Connect raggiungerà il suo pieno potenziale. Oltre 500 eventi delle macchine vengono monitorati quasi in tempo reale per fornire una visione completa delle condizioni delle macchine e dei loro ambienti operativi. Utilizzando i dati trasmessi tramite LnW Connect, L&W mira a creare una migliore esperienza di gioco per i propri utenti finali e a portare più valore ai propri clienti di casinò.
Light & Wonder ha collaborato con il team di Amazon ML Solutions Lab per utilizzare i dati degli eventi trasmessi da LnW Connect per abilitare la manutenzione predittiva basata su machine learning (ML) per le slot machine. La manutenzione predittiva è un caso d’uso ML comune per le aziende che possiedono attrezzature fisiche o asset di macchinari. Con la manutenzione predittiva, L&W può ricevere un avviso avanzato sui guasti delle macchine e inviare proattivamente un team di servizio per ispezionare il problema. Ciò ridurrà il downtime delle macchine e eviterà significative perdite di ricavi per i casinò. Senza un sistema di diagnostica remota, la risoluzione dei problemi da parte del team di servizio di Light & Wonder sul pavimento del casinò può essere costosa ed inefficiente, degradando gravemente l’esperienza di gioco del cliente.
La natura del progetto è altamente esplorativa: questo è il primo tentativo di manutenzione predittiva nell’industria del gioco. Il team di Amazon ML Solutions Lab e L&W hanno intrapreso un percorso end-to-end, dalla formulazione del problema ML e la definizione delle metriche di valutazione, alla consegna di una soluzione di alta qualità. Il modello ML finale combina CNN e Transformer, che sono le architetture di rete neurale all’avanguardia per la modellizzazione dei dati sequenziali di log delle macchine. Il post presenta una descrizione dettagliata di questo percorso, e speriamo che lo apprezzerete tanto quanto noi!
- Rivoluzionare la scoperta dei farmaci il modello di apprendimento automatico identifica potenziali composti anti-invecchiamento e apre la strada per il futuro trattamento delle malattie complesse.
- Da Suono a Vista Conosci AudioToken per la Sintesi Audio-Immagine
- CI/CD per Endpoint Multi-Modello in AWS
In questo post, discutiamo i seguenti argomenti:
- Come abbiamo formulato il problema di manutenzione predittiva come un problema ML con un insieme di metriche appropriate per la valutazione
- Come abbiamo preparato i dati per l’addestramento e il testing
- Tecniche di preprocessing dei dati e di feature engineering che abbiamo impiegato per ottenere modelli performanti
- Esecuzione di una fase di accordatura degli iperparametri con Amazon SageMaker Automatic Model Tuning
- Confronti tra il modello baseline e il modello finale CNN+Transformer
- Tecniche aggiuntive che abbiamo utilizzato per migliorare le prestazioni del modello, come l’ensembling
Background
In questa sezione, discutiamo le problematiche che hanno reso necessaria questa soluzione.
Dataset
Gli ambienti delle slot machine sono altamente regolamentati e vengono distribuiti in un ambiente air-gapped. In LnW Connect, è stato progettato un processo di crittografia per fornire un meccanismo sicuro e affidabile per portare i dati in un data lake AWS per la modellizzazione predittiva. I file aggregati sono cifrati e la chiave di decodifica è disponibile solo in AWS Key Management Service (AWS KMS). È stata creata una rete privata basata su cellulari verso AWS attraverso la quale i file sono stati caricati in Amazon Simple Storage Service (Amazon S3).
LnW Connect trasmette una vasta gamma di eventi delle macchine, come l’avvio del gioco, la fine del gioco e altro ancora. Il sistema raccoglie oltre 500 diversi tipi di eventi. Come mostrato nella tabella seguente, ogni evento viene registrato insieme ad un timestamp di quando è avvenuto e all’ID della macchina che ha registrato l’evento. LnW Connect registra anche quando una macchina entra in uno stato non giocabile e viene contrassegnata come guasto o breakdown della macchina se non si riprende in uno stato giocabile entro un intervallo di tempo sufficientemente breve.
| ID Macchina | ID Tipo Evento | Timestamp |
| 0 | E1 | 2022-01-01 00:17:24 |
| 0 | E3 | 2022-01-01 00:17:29 |
| 1000 | E4 | 2022-01-01 00:17:33 |
| 114 | E234 | 2022-01-01 00:17:34 |
| 222 | E100 | 2022-01-01 00:17:37 |
Oltre agli eventi dinamici delle macchine, sono disponibili anche metadati statici su ciascuna macchina. Questi includono informazioni come l’identificatore univoco della macchina, il tipo di cabinet, la posizione, il sistema operativo, la versione del software, il tema del gioco e altro ancora, come mostrato nella seguente tabella. (Tutti i nomi nella tabella sono anonimizzati per proteggere le informazioni del cliente.)
| ID Macchina | Tipo di Cabinet | OS | Posizione | Tema del gioco |
| 276 | A | OS_Ver0 | AA Resort & Casino | StormMaiden |
| 167 | B | OS_Ver1 | BB Casino, Resort & Spa | UHMLIndia |
| 13 | C | OS_Ver0 | CC Casino & Hotel | TerrificTiger |
| 307 | D | OS_Ver0 | DD Casino Resort | NeptunesRealm |
| 70 | E | OS_Ver0 | EE Resort & Casino | RLPMealTicket |
Definizione del problema
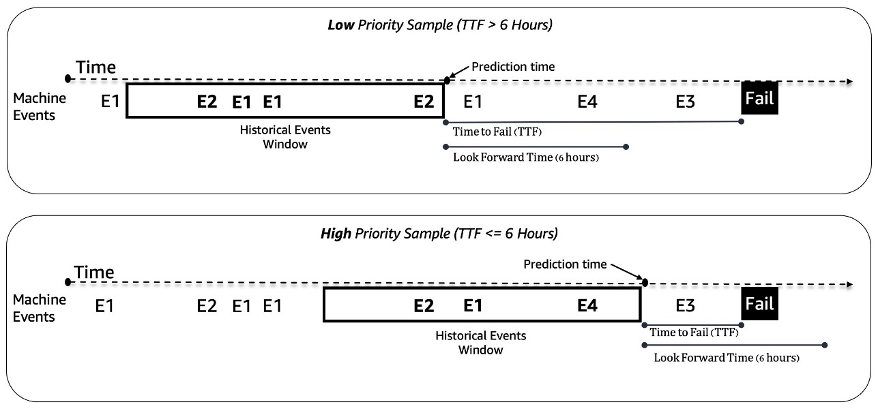
Trattiamo il problema della manutenzione predittiva delle slot machine come un problema di classificazione binaria. Il modello ML riceve la sequenza storica di eventi della macchina e altri metadati e predice se una macchina si troverà di fronte a un guasto in una finestra temporale futura di 6 ore. Se una macchina si romperà entro 6 ore, è considerata una macchina ad alta priorità per la manutenzione. In caso contrario, è a bassa priorità. La seguente figura fornisce esempi di campioni a bassa priorità (in alto) e ad alta priorità (in basso). Utilizziamo una finestra temporale di lunghezza fissa per raccogliere i dati storici degli eventi della macchina per la predizione. Gli esperimenti mostrano che finestre temporali più lunghe migliorano significativamente le prestazioni del modello (ulteriori dettagli in seguito in questo post).
Sfide di modellizzazione
Affrontiamo un paio di sfide per risolvere questo problema:
- Abbiamo una quantità enorme di registri di eventi che contengono circa 50 milioni di eventi al mese (da circa 1000 campioni di gioco). È necessaria un’ottimizzazione attenta nella fase di estrazione e preprocessamento dei dati.
- La modellizzazione della sequenza di eventi è stata difficile a causa della distribuzione estremamente disomogenea degli eventi nel tempo. Una finestra temporale di 3 ore può contenere da decine a migliaia di eventi.
- Le macchine sono in buone condizioni per la maggior parte del tempo e la manutenzione ad alta priorità è una classe rara, il che ha introdotto un problema di sbilanciamento di classe.
- Vengono continuamente aggiunte nuove macchine al sistema, quindi dovevamo assicurarci che il nostro modello potesse gestire la previsione su nuove macchine che non erano mai state viste in fase di addestramento.
Preprocessamento dei dati ed ingegneria delle caratteristiche
In questa sezione, discutiamo dei nostri metodi per la preparazione dei dati e l’ingegneria delle caratteristiche.
Ingegneria delle caratteristiche
Le alimentazioni delle slot machine sono flussi di eventi delle serie temporali non equamente spaziati; ad esempio, il numero di eventi in una finestra temporale di 3 ore può variare da decine a migliaia. Per gestire questo squilibrio, abbiamo utilizzato le frequenze degli eventi invece dei dati di sequenza grezzi. Un approccio semplice consiste nell’aggregare la frequenza degli eventi per l’intera finestra temporale e alimentarla nel modello. Tuttavia, quando si utilizza questa rappresentazione, le informazioni temporali vengono perse e l’ordine degli eventi non viene preservato. Invece, abbiamo utilizzato la suddivisione temporale dividendo la finestra temporale in N sottofinestre uguali e calcolando le frequenze degli eventi in ognuna di esse. Le caratteristiche finali di una finestra temporale sono la concatenazione di tutte le sue caratteristiche di sottofinestra. Aumentare il numero di sottofinestre preserva più informazioni temporali. La seguente figura illustra la suddivisione temporale su una finestra di esempio.

Prima di tutto, la finestra temporale di campionamento viene divisa in due sottofinestre (bin); qui abbiamo usato solo due bin per semplicità di illustrazione. Quindi, vengono calcolati i conteggi degli eventi E1, E2, E3 e E4 in ogni bin. Infine, vengono concatenati e utilizzati come caratteristiche.
Oltre alle caratteristiche basate sulla frequenza degli eventi, abbiamo utilizzato caratteristiche specifiche della macchina come versione del software, tipo di cabinet, tema del gioco e versione del gioco. Inoltre, abbiamo aggiunto caratteristiche relative ai timestamp per catturare la stagionalità, come l’ora del giorno e il giorno della settimana.
Preparazione dei dati
Per estrarre i dati in modo efficiente per l’addestramento e il testing, utilizziamo Amazon Athena e il Catalogo dati AWS Glue. I dati sugli eventi sono archiviati in Amazon S3 in formato Parquet e suddivisi in base al giorno/mese/ora. Ciò facilita l’estrazione efficiente di campioni di dati entro un determinato intervallo di tempo. Utilizziamo i dati di tutte le macchine dell’ultimo mese per il testing e il resto dei dati per l’addestramento, il che aiuta a evitare possibili perdite di dati.
Metodologia ML e addestramento del modello
In questa sezione, discutiamo del nostro modello di base con AutoGluon e di come abbiamo costruito una rete neurale personalizzata con SageMaker automatic model tuning.
Costruzione di un modello di base con AutoGluon
Con qualsiasi caso d’uso di ML, è importante stabilire un modello di base da utilizzare per il confronto e l’iterazione. Abbiamo utilizzato AutoGluon per esplorare diversi algoritmi di ML classici. AutoGluon è uno strumento AutoML facile da usare che utilizza l’elaborazione automatica dei dati, l’ottimizzazione degli iperparametri e l’ensemble del modello. Il miglior modello di base è stato ottenuto con un ensemble pesato di modelli di albero decisionale a gradiente potenziato. La facilità d’uso di AutoGluon ci ha aiutato nella fase di scoperta a navigare rapidamente ed efficientemente attraverso una vasta gamma di possibili direzioni di modellazione di dati e ML.
Costruzione e messa a punto di un modello di rete neurale personalizzato con SageMaker automatic model tuning
Dopo aver sperimentato diverse architetture di reti neurali, abbiamo costruito un modello di deep learning personalizzato per la manutenzione predittiva. Il nostro modello ha superato il modello di base AutoGluon del 121% in recall a precisione dell’80%. Il modello finale riceve dati di sequenza degli eventi della macchina storica, caratteristiche temporali come l’ora del giorno e metadati statici della macchina. Utilizziamo i lavori di messa a punto automatica del modello SageMaker per cercare i migliori iperparametri e le migliori architetture di modello.
La figura seguente mostra l’architettura del modello. In primo luogo normalizziamo i dati della sequenza di eventi binati per le frequenze medie di ogni evento nel set di addestramento per rimuovere l’effetto schiacciante degli eventi ad alta frequenza (inizio del gioco, fine del gioco, ecc.). Le embedding per gli eventi singoli sono apprendibili, mentre le embedding delle caratteristiche temporali (giorno della settimana, ora del giorno) vengono estratte utilizzando il pacchetto GluonTS. Quindi concateniamo i dati della sequenza di eventi con le embedding delle caratteristiche temporali come input al modello. Il modello è composto dai seguenti livelli:
- Livelli convoluzionali (CNN) – Ogni livello CNN consiste di due operazioni di convoluzione unidimensionale con connessioni residue. L’output di ogni livello CNN ha la stessa lunghezza di sequenza dell’input per consentire l’impilamento facile con altri moduli. Il numero totale di livelli CNN è un iperparametro regolabile.
- Livelli di codificatore del trasformatore (TRANS) – L’output dei livelli CNN viene alimentato insieme alla codifica posizionale a una struttura di autoattenzione multi-testa. Utilizziamo TRANS per catturare direttamente le dipendenze temporali invece di utilizzare le reti neurali ricorrenti. Qui, l’impilamento dei dati di sequenza grezzi (riducendo la lunghezza da migliaia a centinaia) aiuta a alleviare i colli di bottiglia della memoria GPU, mantenendo al contempo le informazioni cronologiche in modo regolabile (il numero dei bin è un iperparametro regolabile).
- Livelli di aggregazione (AGG) – Il livello finale combina le informazioni sui metadati (tipo di tema del gioco, tipo di cabinet, posizioni) per produrre la previsione della probabilità del livello di priorità. È composto da diversi livelli di pooling e di connessione completamente connessa per la riduzione incrementale della dimensione. Le embedding multi-hot dei metadati sono anch’esse apprendibili e non passano attraverso i livelli CNN e TRANS perché non contengono informazioni sequenziali.

Utilizziamo la perdita di entropia incrociata con pesi di classe come iperparametri regolabili per gestire il problema dell’equilibrio delle classi. Inoltre, il numero di strati CNN e TRANS sono iperparametri cruciali con valori possibili di 0, il che significa che specifici strati potrebbero non esistere sempre nell’architettura del modello. In questo modo, abbiamo un framework unificato in cui le architetture del modello sono cercate insieme ad altri iperparametri usuali.
Utilizziamo l’ottimizzazione automatica degli iperparametri (HPO), anche nota come sintonizzazione automatica del modello, di SageMaker per esplorare in modo efficiente variazioni del modello e il grande spazio di ricerca di tutti gli iperparametri. La sintonizzazione automatica del modello riceve l’algoritmo personalizzato, i dati di allenamento e le configurazioni dello spazio di ricerca degli iperparametri e cerca i migliori iperparametri utilizzando diverse strategie come Bayesian, Hyperband e altro con più istanze GPU in parallelo. Dopo la valutazione su un set di validazione, abbiamo ottenuto la migliore architettura del modello con due strati di CNN, uno strato di TRANS con quattro testate e uno strato AGG.
Abbiamo utilizzato i seguenti intervalli di iperparametri per cercare la migliore architettura del modello:
hyperparameter_ranges = {
# Learning Rate
"learning_rate": ContinuousParameter(5e-4, 1e-3, scaling_type="Logarithmic"),
# Class weights
"loss_weight": ContinuousParameter(0.1, 0.9),
# Number of input bins
"num_bins": CategoricalParameter([10, 40, 60, 120, 240]),
# Dropout rate
"dropout_rate": CategoricalParameter([0.1, 0.2, 0.3, 0.4, 0.5]),
# Model embedding dimension
"dim_model": CategoricalParameter([160,320,480,640]),
# Number of CNN layers
"num_cnn_layers": IntegerParameter(0,10),
# CNN kernel size
"cnn_kernel": CategoricalParameter([3,5,7,9]),
# Number of tranformer layers
"num_transformer_layers": IntegerParameter(0,4),
# Number of transformer attention heads
"num_heads": CategoricalParameter([4,8]),
#Number of RNN layers
"num_rnn_layers": IntegerParameter(0,10), # optional
# RNN input dimension size
"dim_rnn":CategoricalParameter([128,256])
}Per migliorare ulteriormente l’accuratezza del modello e ridurre la varianza del modello, abbiamo allenato il modello con molteplici inizializzazioni di pesi casuali indipendenti e abbiamo aggregato il risultato con i valori medi come previsione di probabilità finale. C’è un compromesso tra le risorse di calcolo e le prestazioni del modello, e abbiamo osservato che 5-10 dovrebbe essere un numero ragionevole nel caso d’uso attuale (i risultati saranno mostrati in seguito in questo post).
Risultati di performance del modello
In questa sezione, presentiamo le metriche e i risultati di valutazione delle prestazioni del modello.
Metriche di valutazione
La precisione è molto importante per questo caso d’uso di manutenzione predittiva. Una bassa precisione significa segnalare più chiamate di manutenzione false, il che aumenta i costi attraverso una manutenzione non necessaria. Poiché la precisione media (AP) non si allinea completamente con l’obiettivo di alta precisione, abbiamo introdotto una nuova metrica chiamata richiamo medio a precisioni elevate (ARHP). ARHP è uguale alla media dei richiami ai punti di precisione del 60%, 70% e 80%. Abbiamo anche utilizzato la precisione al top K% (K=1, 10), AUPR e AUROC come metriche aggiuntive.
Risultati
La seguente tabella riassume i risultati utilizzando i modelli di rete neurale di base e personalizzati, con il 7/1/2022 come punto di divisione tra allenamento e test. Gli esperimenti mostrano che l’aumento della lunghezza della finestra e delle dimensioni dei dati campione migliorano entrambi le prestazioni del modello, poiché contengono più informazioni storiche per aiutare nella previsione. Indipendentemente dalle impostazioni dei dati, il modello di rete neurale supera AutoGluon in tutte le metriche. Ad esempio, il richiamo al 80% di precisione fissa aumenta del 121%, il che consente di identificare rapidamente più macchine malfunzionanti se si utilizza il modello di rete neurale.
| Modello | Lunghezza finestra/Dimensione dati | AUROC | AUPR | ARHP | [email protected] | [email protected] | [email protected] | Prec@top1% | Prec@top10% |
| AutoGluon di base | 12H/500k | 66.5 | 36.1 | 9.5 | 12.7 | 9.3 | 6.5 | 85 | 42 |
| Rete neurale | 12H/500k | 74.7 | 46.5 | 18.5 | 25 | 18.1 | 12.3 | 89 | 55 |
| AutoGluon di base | 48H/1mm | 70.2 | 44.9 | 18.8 | 26.5 | 18.4 | 11.5 | 92 | 55 |
| Rete neurale | 48H/1mm | 75.2 | 53.1 | 32.4 | 39.3 | 32.6 | 25.4 | 94 | 65 |
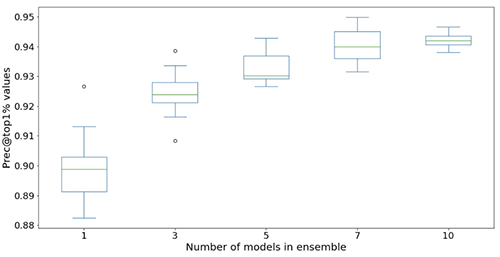
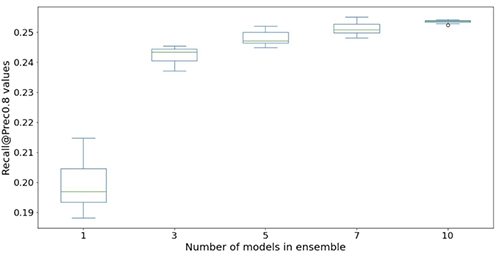
Le seguenti figure illustrano l’effetto dell’utilizzo di insiemi per migliorare le prestazioni del modello di rete neurale. Tutte le metriche di valutazione mostrate sull’asse x sono migliorate, con una media più alta (più precisa) e una varianza più bassa (più stabile). Ogni box-plot proviene da 12 esperimenti ripetuti, da nessun insieme a 10 modelli in insiemi (asse x). Tendenze simili persistono in tutte le metriche oltre a Prec@top1% e Recall@Prec80% mostrati.
Dopo aver considerato il costo computazionale, osserviamo che l’utilizzo di 5-10 modelli in insiemi è adatto per i dataset di Light & Wonder.
Conclusioni
La nostra collaborazione ha portato alla creazione di una soluzione innovativa per la manutenzione predittiva per l’industria dei giochi, nonché di un framework riutilizzabile che potrebbe essere utilizzato in una varietà di scenari di manutenzione predittiva. L’adozione delle tecnologie AWS come SageMaker automatic model tuning facilita Light & Wonder a navigare nuove opportunità utilizzando flussi di dati quasi in tempo reale. Light & Wonder sta avviando la distribuzione su AWS.
Se desideri aiuto per accelerare l’utilizzo di ML nei tuoi prodotti e servizi, contatta il programma Amazon ML Solutions Lab.