Incontra MeLoDy Un Modello di Diffusione Testo-Audio Efficiente per la Sintesi Musicale.
MeLoDy un modello di diffusione testo-audio per la sintesi musicale.


La musica è un’arte composta da armonia, melodia e ritmo che permea ogni aspetto della vita umana. Con la fioritura dei modelli generativi profondi, la generazione di musica ha attirato molta attenzione negli ultimi anni. Come classe prominente di modelli generativi, i modelli di linguaggio (LM) hanno mostrato straordinarie capacità di modellizzazione nella modellizzazione di complesse relazioni attraverso contesti a lungo termine. Alla luce di questo, AudioLM e molti lavori successivi hanno applicato con successo gli LM alla sintesi audio. In contemporanea con gli approcci basati su LM, i modelli probabilistici di diffusione (DPM), come un’altra classe competitiva di modelli generativi, hanno dimostrato anche eccezionali capacità nella sintesi di discorsi, suoni e musica.
Tuttavia, la generazione di musica da testo libero rimane una sfida poiché le descrizioni musicali permesse possono essere diverse e riguardare generi, strumenti, tempo, scenari o persino alcuni sentimenti soggettivi. I modelli di generazione di testo-musica tradizionali si concentrano spesso su proprietà specifiche come la continuazione audio o il campionamento rapido, mentre alcuni modelli privilegiano i test robusti, che vengono occasionalmente condotti da esperti del settore, come i produttori musicali. Inoltre, la maggior parte di essi è addestrata su grandi dataset musicali e ha dimostrato prestazioni generative all’avanguardia con alta fedeltà e aderenza a vari aspetti di prompt di testo.
Tuttavia, il successo di questi metodi, come MusicLM o Noise2Music, comporta costi di calcolo elevati, che ne limiterebbero gravemente la fattibilità. In confronto, altri approcci basati su DPM hanno reso possibile il campionamento efficiente di musica di alta qualità. Tuttavia, i loro casi dimostrativi erano comparativamente piccoli e mostravano una dinamica limitata all’interno del campione. Mirando a uno strumento di creazione musicale fattibile, un’alta efficienza del modello generativo è essenziale poiché facilita la creazione interattiva con il feedback umano preso in considerazione, come in uno studio precedente.
- Come funziona la diagnosi medica dell’AI?
- Modellando il Futuro dell’Intelligenza Artificiale Un’Indagine Approfondita sui Modelli di Pre-Allenamento Visione-Linguaggio e il loro Ruolo nei Compiti Uni-Modalità e Multi-Modalità.
- Il Deep Learning va in profondità l’AI svela nuove immagini su larga scala nel deserto peruviano.
Mentre LM e DPM hanno entrambi mostrato risultati promettenti, la domanda pertinente non è se uno dovrebbe essere preferito rispetto all’altro, ma se è possibile sfruttare contemporaneamente i vantaggi di entrambi gli approcci.
In base alla motivazione menzionata, è stato sviluppato un approccio denominato MeLoDy. La panoramica della strategia è presentata nella figura qui sotto.
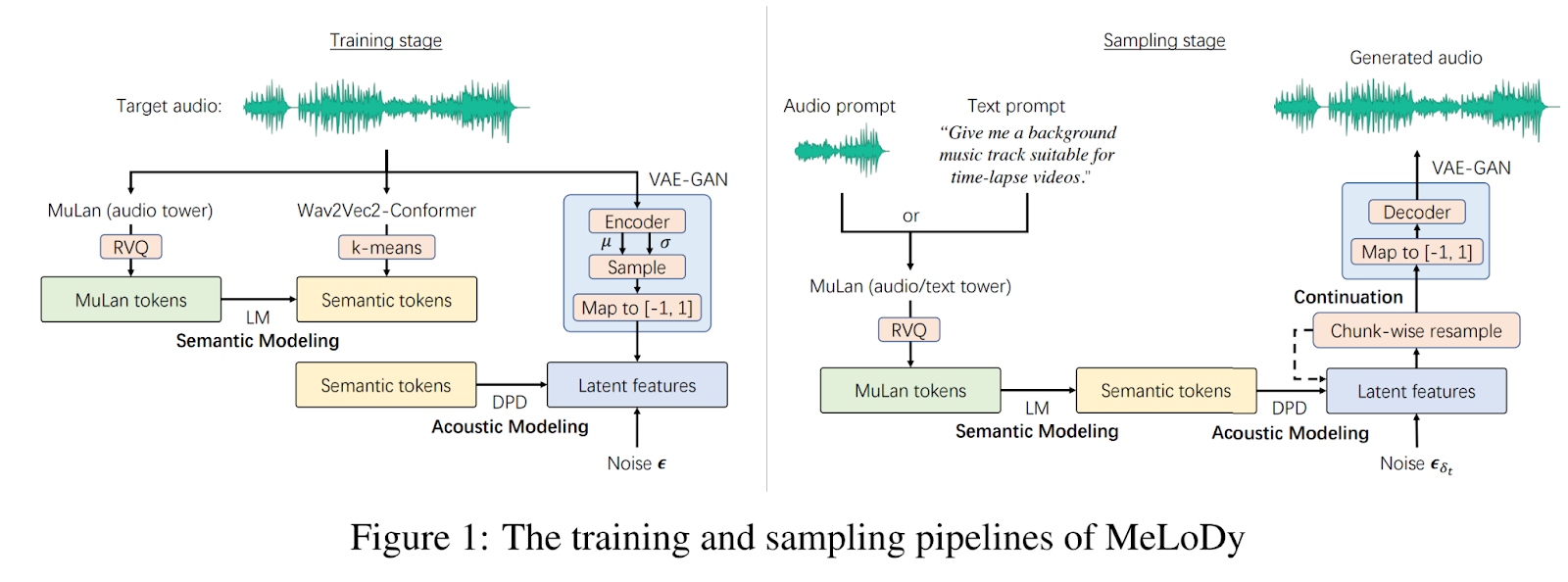
Dopo aver analizzato il successo di MusicLM, gli autori sfruttano l’LM di livello più elevato in MusicLM, denominato LM semantico, per modellare la struttura semantica della musica, determinando l’organizzazione generale di melodia, ritmo, dinamiche, timbro e tempo. Condizionale a questo LM semantico, sfruttano la natura non autoregressiva dei DPM per modellare l’acustica in modo efficiente ed efficace con l’aiuto di una tecnica di accelerazione del campionamento di successo.
Inoltre, gli autori propongono il cosiddetto modello di diffusione a doppio percorso (DPD) invece di adottare il processo di diffusione classico. Infatti, lavorare sui dati grezzi aumenterebbe esponenzialmente le spese di calcolo. La soluzione proposta consiste nel ridurre i dati grezzi a una rappresentazione latente a bassa dimensionalità. La riduzione della dimensionalità dei dati ostacola il suo impatto sulle operazioni e, quindi, riduce il tempo di esecuzione del modello. Successivamente, i dati grezzi possono essere ricostruiti dalla rappresentazione latente attraverso un autoencoder pre-addestrato.
Alcuni campioni di output prodotti dal modello sono disponibili al seguente link: https://efficient-melody.github.io/. Il codice non è ancora disponibile, il che significa che al momento non è possibile provarlo né online né localmente.
Questo è stato il riassunto di MeLoDy, un efficiente modello di diffusione guidato da LM che genera audio di musica di qualità all’avanguardia. Se sei interessato, puoi saperne di più su questa tecnica ai link sottostanti.





