Modellando il Futuro dell’Intelligenza Artificiale Un’Indagine Approfondita sui Modelli di Pre-Allenamento Visione-Linguaggio e il loro Ruolo nei Compiti Uni-Modalità e Multi-Modalità.
Modellando il Futuro dell'Intelligenza Artificiale Un'Indagine sui Modelli di Pre-Allenamento Visione-Linguaggio e il loro Ruolo nei Compiti Uni-Modalità e Multi-Modalità.


Nell’ultima pubblicazione di documenti di ricerca sull’intelligenza artificiale, un team di ricercatori approfondisce l’area del pretraining visione-linguaggio (VLP) e le sue applicazioni in compiti multi-modali. Il documento esplora l’idea di addestramento uni-modale e come differisce dalle adattazioni multi-modalità. Successivamente, il rapporto illustra le cinque importanti aree di VLP: estrazione di caratteristiche, architettura del modello, obiettivi di pretraining, set di dati di pretraining e compiti downstream. I ricercatori esaminano quindi i modelli VLP esistenti e come si adattano ed emergono nel campo su diversi fronti.
Il campo dell’AI ha sempre cercato di addestrare i modelli in modo che percepiamo, pensiamo e comprendiamo i modelli e le sfumature come fanno gli esseri umani. Sono stati fatti vari tentativi per incorporare il maggior numero possibile di campi di input di dati, come dati visivi, audio o testuali. Ma la maggior parte di questi approcci ha cercato di risolvere il problema della “comprensione” in un senso uni-modale.
Un approccio uni-modale è un approccio in cui si valuta una situazione analizzando solo un suo aspetto, ad esempio in un video, ci si concentra solo sull’audio o sulla trascrizione, mentre in un approccio multi-modale, si cerca di mirare a quante più funzioni disponibili possibile e incorporarle nel modello. Ad esempio, durante l’analisi di un video, vengono presi in considerazione l’audio, la trascrizione e l’espressione facciale del parlante per comprendere veramente il contesto.
- Il Deep Learning va in profondità l’AI svela nuove immagini su larga scala nel deserto peruviano.
- Implementare un endpoint di inferenza ML serverless per grandi modelli di linguaggio utilizzando FastAPI, AWS Lambda e AWS CDK.
- GPT vs BERT Quale è Migliore?
L’approccio multi-modale si rende impegnativo perché è intensivo di risorse e anche perché la necessità di grandi quantità di dati etichettati per addestrare modelli capaci è stata difficile. I modelli di pretraining basati su strutture transformer hanno affrontato questo problema sfruttando l’apprendimento auto-supervisionato e compiti aggiuntivi per apprendere rappresentazioni universali da dati non etichettati su larga scala.
I modelli di pretraining in modo uni-modale, a cominciare da BERT in NLP, hanno dimostrato una notevole efficacia mediante il fine-tuning con dati etichettati limitati per compiti downstream. I ricercatori hanno esplorato la fattibilità del pretraining della visione-linguaggio (VLP) estendendo la stessa filosofia di progettazione al campo multi-modale. VLP utilizza modelli di pretraining su set di dati su larga scala per apprendere corrispondenze semantiche tra modalità.
I ricercatori esaminano i progressi compiuti nell’approccio VLP in cinque aree principali. In primo luogo, discutono di come i modelli VLP preprocessano e rappresentano immagini, video e testo per ottenere funzionalità corrispondenti, evidenziando vari modelli impiegati. In secondo luogo, esplorano ed esaminano la prospettiva del flusso singolo e la sua usabilità rispetto alla fusione a doppio flusso e al design solo encoder rispetto al design encoder-decoder.
Il documento esplora ulteriormente il pretraining dei modelli VLP, suddividendoli in completamento, corrispondenza e tipi particolari. Questi obiettivi sono importanti poiché aiutano a definire rappresentazioni universali visione-linguaggio. I ricercatori forniscono quindi una panoramica delle due principali categorie di pretraining dei set di dati, modelli di immagini-linguaggio e modelli di video-linguaggio. Il documento sottolinea come l’approccio multi-modale aiuti a ottenere una migliore comprensione e accuratezza in termini di comprensione del contesto e produzione di contenuti meglio mappati. Infine, l’articolo presenta gli obiettivi e i dettagli dei compiti downstream in VLP, enfatizzando la loro importanza nell’valutazione dell’efficacia dei modelli pre-addestrati.
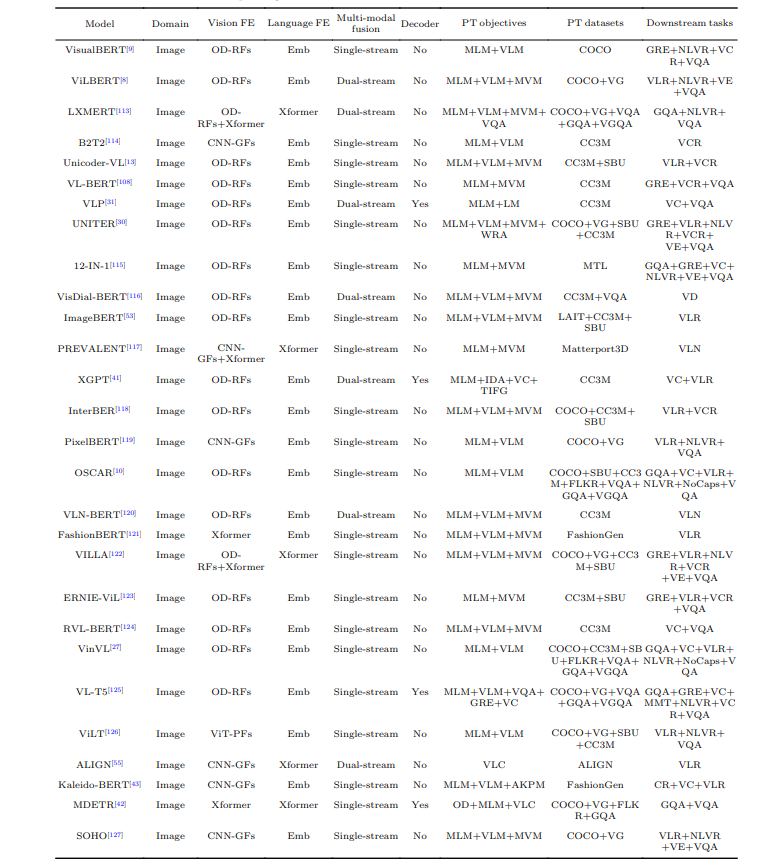
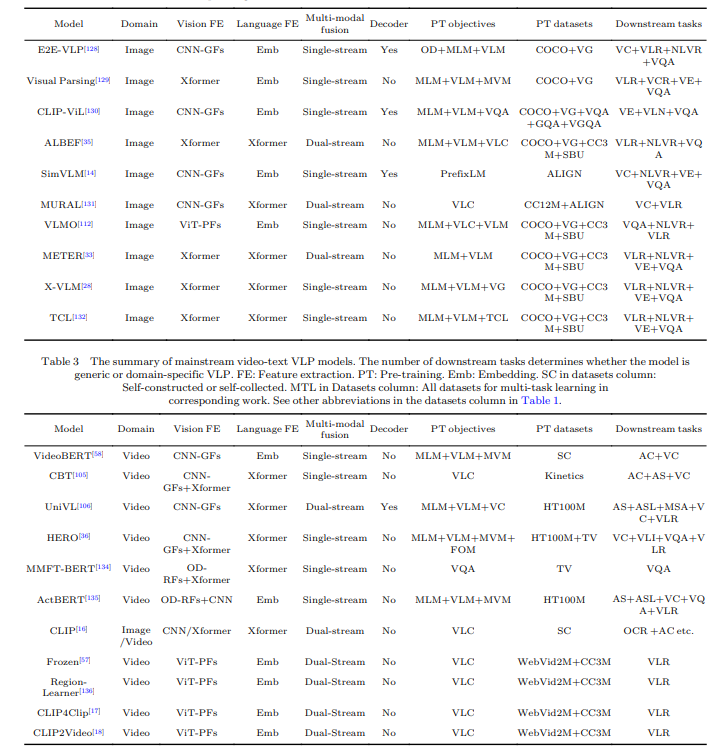
Il paper fornisce una panoramica dettagliata dei modelli VLP SOTA. Elenca tali modelli e ne evidenzia le caratteristiche chiave e le prestazioni. I modelli menzionati e coperti sono una solida base per l’avanzamento tecnologico all’avanguardia e possono servire come riferimento per lo sviluppo futuro.
In base al paper di ricerca, il futuro dell’architettura VLP sembra promettente e affidabile. Sono state proposte varie aree di miglioramento, come l’incorporazione di informazioni acustiche, l’apprendimento conoscitivo e cognitivo, la messa a punto rapida, la compressione e l’accelerazione del modello e la preformazione fuori dal dominio. Queste aree di miglioramento sono destinate a ispirare la nuova era di ricercatori a progredire nel campo del VLP e a trovare approcci innovativi.





