Incontra Video-ControlNet un nuovo modello di diffusione di testo in video destinato a cambiare il gioco e a plasmare il futuro della generazione di video controllabili.
Introducing Video-ControlNet, a new text dissemination model in videos that is set to change the game and shape the future of controllable video generation.


Negli ultimi anni c’è stato un rapido sviluppo nella generazione di contenuti visivi basati su testo. Allenati con coppie di immagini-testo su larga scala, i modelli diffusivi Text-to-Image (T2I) attuali hanno dimostrato un’abilità impressionante nella generazione di immagini di alta qualità basate su prompt di testo forniti dall’utente. Il successo nella generazione di immagini è stato esteso anche alla generazione di video. Alcuni metodi sfruttano i modelli T2I per generare video in modo one-shot o zero-shot, anche se i video generati da questi modelli sono ancora inconsistenti o privi di varietà. Scalando i dati video, i modelli di diffusione Text-to-Video (T2V) possono creare video coerenti con prompt di testo. Tuttavia, questi modelli generano video che mancano di controllo sul contenuto generato.
Uno studio recente propone un modello di diffusione T2V che consente mappe di profondità come controllo. Tuttavia, è richiesto un dataset su larga scala per ottenere coerenza e alta qualità, il che è poco amichevole alle risorse. Inoltre, è ancora difficile per i modelli di diffusione T2V generare video di coerenza, lunghezza arbitraria e diversità.
Video-ControlNet, un modello T2V controllabile, è stato introdotto per affrontare questi problemi. Video-ControlNet offre i seguenti vantaggi: migliorata coerenza attraverso l’uso di priorità di movimento e mappe di controllo, la capacità di generare video di lunghezza arbitraria mediante l’impiego di una strategia di condizionamento del primo fotogramma, generalizzazione di dominio mediante il trasferimento di conoscenza da immagini a video, ed efficienza delle risorse con una convergenza più rapida utilizzando una dimensione batch limitata.
- Un Confronto degli Algoritmi di Apprendimento Automatico in Python e R
- Vision Transformers (ViT) nell’elaborazione delle didascalie delle immagini utilizzando modelli ViT preaddestrati
- Come costruire un’intelligenza artificiale responsabile con TensorFlow?
L’architettura di Video-ControlNet è riportata di seguito.
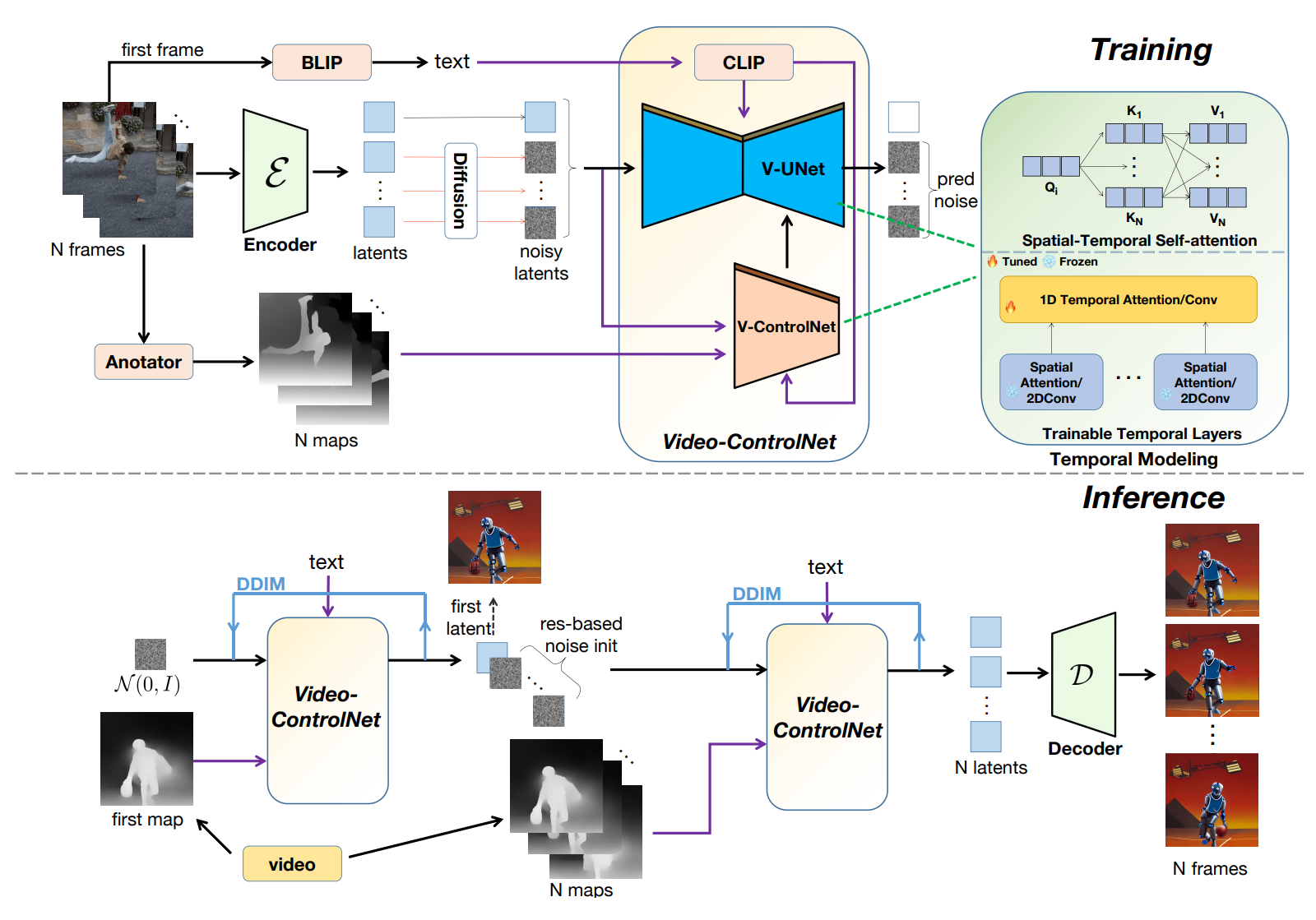

L’obiettivo è generare video basati su testo e mappe di controllo di riferimento. Pertanto, il modello generativo è sviluppato riorganizzando un modello T2I controllabile pre-allenato, incorporando ulteriori strati temporali addestrabili e presentando un meccanismo di auto-attenzione spaziale-temporale che facilita interazioni dettagliate tra i fotogrammi. Questo approccio consente la creazione di video coerenti nel contenuto, anche senza un addestramento esteso.
Per garantire la coerenza della struttura del video, gli autori propongono un approccio pionieristico che incorpora la priorità di movimento del video di origine nel processo di denoising nella fase di inizializzazione del rumore. Sfruttando la priorità del movimento e le mappe di controllo, Video-ControlNet è in grado di produrre video che presentano meno sfarfallio e assomigliano da vicino ai cambiamenti di movimento nel video di input, evitando anche la propagazione degli errori in altri metodi basati sul movimento a causa della natura del processo di denoising multistep.
Inoltre, anziché i metodi precedenti che addestrano i modelli per generare direttamente interi video, in questo lavoro è stato introdotto uno schema di addestramento innovativo, che produce video basati sul fotogramma iniziale. Con una strategia così semplice ma efficace, diventa più gestibile disentangling del contenuto e dell’apprendimento temporale, poiché il primo è presentato nel primo fotogramma e nel prompt di testo.
Il modello deve solo imparare a generare fotogrammi successivi, ereditando le capacità generative dal dominio delle immagini e semplificando la richiesta di dati video. Durante l’inferezza, il primo fotogramma viene generato condizionato alla mappa di controllo del primo fotogramma e a un prompt di testo. Quindi, i fotogrammi successivi vengono generati, condizionati al primo fotogramma, al testo e alle mappe di controllo successivo. Nel frattempo, un altro vantaggio di tale strategia è che il modello può generare in modo auto-regressivo un video di lunghezza infinita trattando l’ultimo fotogramma dell’iterazione precedente come il fotogramma iniziale.
Ecco come funziona. Diamo un’occhiata ai risultati riportati dagli autori. Una limitata batch di risultati campione e il confronto con approcci di ultima generazione sono mostrati nella figura seguente.

Questo è il riassunto di Video-ControlNet, un nuovo modello di diffusione per la generazione T2V con qualità all’avanguardia e consistenza temporale. Se sei interessato, puoi saperne di più su questa tecnica ai link sottostanti.






