Ricerca di similarità, Parte 5 Hashing Sensibile alla Località (LSH)
'LSH Hashing Sensibile alla Località per la Similarità'
Esplora come le informazioni di similarità possono essere incorporate in una funzione di hash
La ricerca di similarità è un problema in cui, dato un query, l’obiettivo è quello di trovare i documenti più simili ad esso tra tutti i documenti del database.
Introduzione
Nella scienza dei dati, la ricerca di similarità appare spesso nel dominio dell’elaborazione del linguaggio naturale (NLP), nei motori di ricerca o nei sistemi di raccomandazione in cui è necessario recuperare i documenti o gli elementi più rilevanti per una determinata query. Esiste una vasta gamma di metodi per migliorare le prestazioni di ricerca in volumi massicci di dati.
Nelle parti precedenti di questa serie di articoli, abbiamo discusso dell’indice di file invertito, della quantizzazione del prodotto e di HNSW e di come possano essere utilizzati insieme per migliorare la qualità della ricerca. In questo capitolo, esamineremo un approccio sostanzialmente diverso che mantiene sia la velocità di ricerca elevata che la qualità.
- Incontra MeLoDy Un Modello di Diffusione Testo-Audio Efficiente per la Sintesi Musicale.
- Come funziona la diagnosi medica dell’AI?
- Modellando il Futuro dell’Intelligenza Artificiale Un’Indagine Approfondita sui Modelli di Pre-Allenamento Visione-Linguaggio e il loro Ruolo nei Compiti Uni-Modalità e Multi-Modalità.
Ricerca di similarità, Parte 3: Combinazione dell’indice di file invertito e della quantizzazione del prodotto
Nelle prime due parti di questa serie abbiamo discusso due algoritmi fondamentali nell’elaborazione delle informazioni: l’indice di file invertito e la quantizzazione del prodotto…
towardsdatascience.com
Ricerca di similarità, Parte 4: Hierarchical Navigable Small World (HNSW)
Hierarchical Navigable Small World (HNSW) è un algoritmo all’avanguardia utilizzato per una ricerca approssimata dei più vicini…
towardsdatascience.com
Local Sensitive Hashing (LSH) è un insieme di metodi utilizzati per ridurre l’ambito di ricerca tramite la trasformazione di vettori di dati in valori di hash preservando le informazioni sulla loro similarità.
Discuteremo l’approccio tradizionale che consiste in tre fasi:
- Shingling: codifica dei testi originali in vettori.
- MinHashing: trasformazione dei vettori in una rappresentazione speciale chiamata firma che può essere utilizzata per confrontare la similarità tra di essi.
- Funzione LSH: hash di blocchi di firma in bucket diversi. Se le firme di una coppia di vettori cadono nello stesso bucket almeno una volta, vengono considerati candidati.
Gradualmente approfondiremo i dettagli di ciascuna di queste fasi nell’articolo.
Shingling
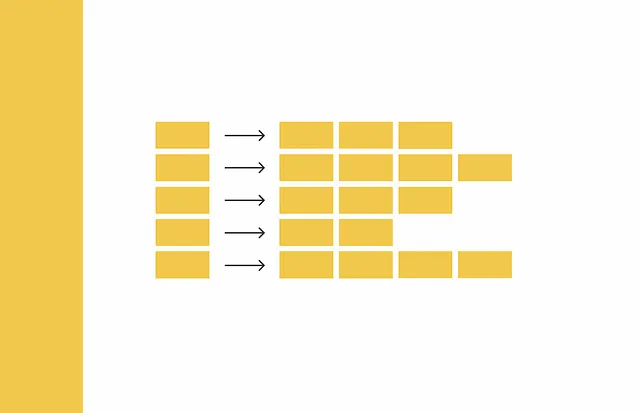
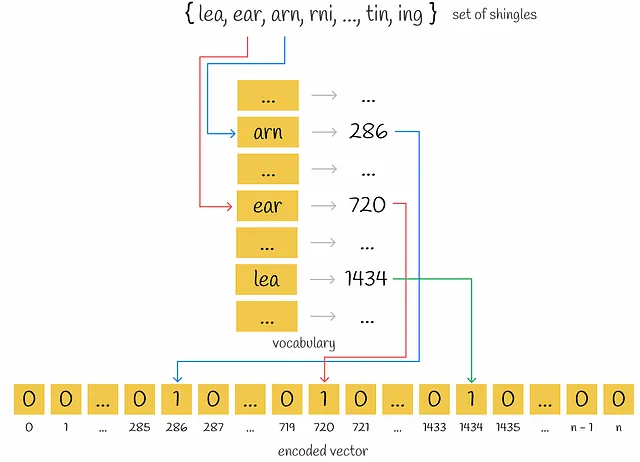
Shingling è il processo di raccolta di k-grammi su testi dati. Un k-grammo è un gruppo di k token sequenziali. A seconda del contesto, i token possono essere parole o simboli. L’obiettivo finale dello shingling è codificare ciascun documento utilizzando i k-grammi raccolti. Utilizzeremo la codifica one-hot per questo. Tuttavia, si possono applicare anche altri metodi di codifica.
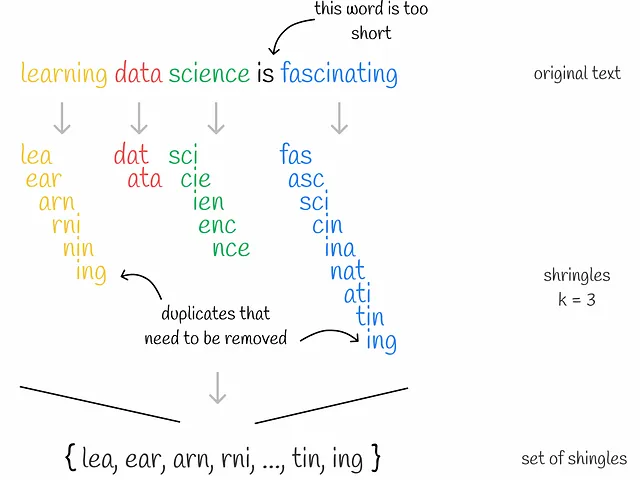
In primo luogo, vengono raccolti i k-grammi unici per ciascun documento. In secondo luogo, per codificare ogni documento, è necessario un vocabolario che rappresenti un insieme di k-grammi unici in tutti i documenti. Quindi, per ogni documento, viene creato un vettore di zeri con lunghezza pari alla dimensione del vocabolario. Per ogni k-gramma che appare nel documento, viene identificata la sua posizione nel vocabolario e viene inserito un “1” nella posizione corrispondente del vettore del documento. Anche se lo stesso k-gramma appare più volte in un documento, non importa: il valore nel vettore sarà sempre 1.
MinHashing
A questo punto, i testi iniziali sono stati vettorizzati. La similarità dei vettori può essere confrontata tramite l’Indice di Jaccard. Ricorda che l’Indice di Jaccard di due insiemi è definito come il numero di elementi comuni in entrambi gli insiemi diviso la lunghezza di tutti gli elementi.
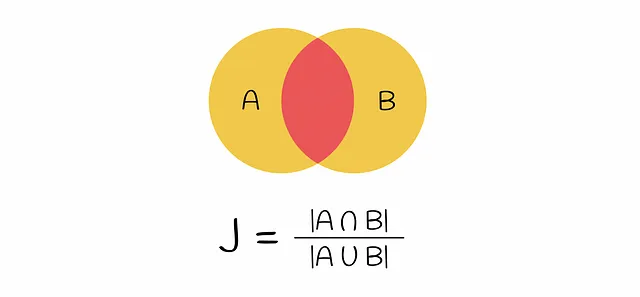
Se viene presa una coppia di vettori codificati, l’intersezione nella formula per l’Indice di Jaccard è il numero di righe che contengono entrambe il valore 1 (cioè l’k -gramma appare in entrambi i vettori) e l’unione è il numero di righe con almeno un 1 (l’k -gramma è presente almeno in uno dei vettori).
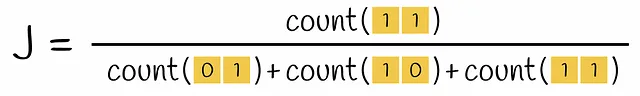
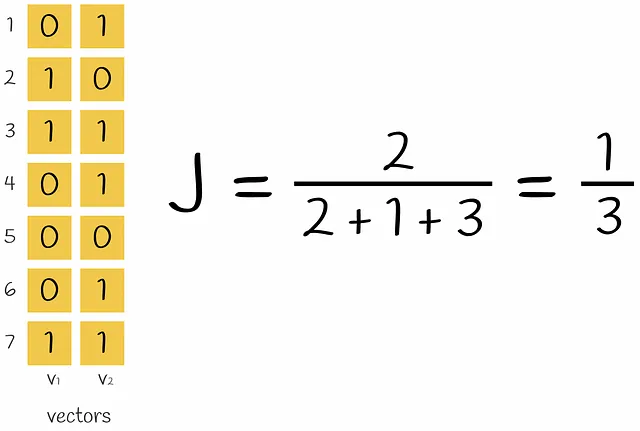
Il problema attuale è la sparsità dei vettori codificati. Calcolare un punteggio di similarità tra due vettori codificati one-hot richiederebbe molto tempo. Trasformarli in un formato denso li renderebbe più efficienti da operare in seguito. In definitiva, l’obiettivo è progettare una funzione che trasformi questi vettori in una dimensione più piccola preservando le informazioni sulla loro similarità. Il metodo che costruisce una tale funzione è chiamato MinHashing.
MinHashing è una funzione hash che permuta i componenti di un vettore di input e restituisce il primo indice in cui il componente del vettore permutato è uguale a 1.
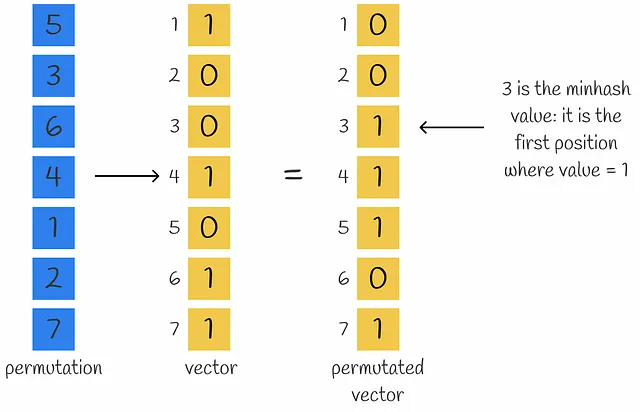
Per ottenere una rappresentazione densa di un vettore composto da n numeri, possono essere utilizzate n funzioni MinHash per ottenere n valori MinHash che formano una firma.
All’inizio potrebbe non sembrare ovvio, ma diversi valori MinHash possono essere utilizzati per approssimare la similarità di Jaccard tra vettori. In effetti, più valori MinHash vengono utilizzati, più accurata è l’approssimazione.
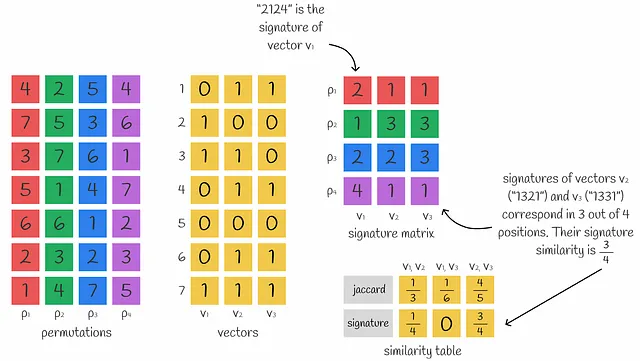
Questa è solo una utile osservazione. Si scopre che dietro le quinte c’è un intero teorema. Capiremo perché l’Indice di Jaccard può essere calcolato utilizzando le firme.
Dimostrazione della dichiarazione
Supponiamo che una data coppia di vettori contenga solo righe di tipo 01 , 10 e 11 . Viene quindi eseguita una permutazione casuale su questi vettori. Poiché esiste almeno un 1 in tutte le righe, durante il calcolo dei due valori hash, almeno uno di questi due processi di calcolo dei valori hash si fermerà alla prima riga di un vettore con il corrispondente valore hash uguale a 1.

Qual è la probabilità che il secondo valore hash sia uguale al primo? Ovviamente, questo accadrà solo se il secondo valore hash è anche uguale a 1. Ciò significa che la prima riga deve essere del tipo 11. Poiché la permutazione è stata presa casualmente, la probabilità di un tale evento è pari a P = count(11) / (count(01) + count(10) + count(11)). Questa espressione è assolutamente la stessa della formula dell’indice di Jaccard. Pertanto:
La probabilità di ottenere valori hash uguali per due vettori binari basati su una permutazione casuale delle righe equivale all’indice di Jaccard.
Tuttavia, dimostrando l’affermazione sopra, abbiamo supposto che i vettori iniziali non contenessero righe del tipo 00. È chiaro che le righe del tipo 00 non cambiano il valore dell’indice di Jaccard. Allo stesso modo, la probabilità di ottenere gli stessi valori hash con righe del tipo 00 incluse non lo influisce. Ad esempio, se la prima riga permutata è 00, l’algoritmo minhash la ignora e passa alla riga successiva finché non esiste almeno un 1 in una riga. Certo, le righe del tipo 00 possono produrre valori hash diversi rispetto a quelli senza di esse ma la probabilità di ottenere gli stessi valori hash rimane la stessa.

Abbiamo dimostrato un’affermazione importante. Ma come può essere stimata la probabilità di ottenere gli stessi valori minhash? Sicuramente, è possibile generare tutte le permutazioni possibili per i vettori e quindi calcolare tutti i valori minhash per trovare la probabilità desiderata. Per ovvie ragioni, questo non è efficiente perché il numero di permutazioni possibili per un vettore di dimensione n è uguale a n!. Tuttavia, la probabilità può essere valutata approssimativamente: usiamo molte funzioni di hash per generare tanti valori hash.
L’indice di Jaccard di due vettori binari approssimativamente equivale al numero di valori corrispondenti nelle loro firme.
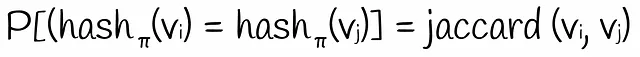
È facile notare che l’utilizzo di firme più lunghe produce calcoli più accurati.
Funzione LSH
Al momento attuale, possiamo trasformare testi grezzi in firme dense di uguale lunghezza che conservano le informazioni sulla similarità. Tuttavia, in pratica, tali firme dense hanno ancora di solito dimensioni elevate e sarebbe inefficiente confrontarle direttamente.
Consideriamo n = 10⁶ documenti con le loro firme di lunghezza 100. Supponendo che un singolo numero di una firma richieda 4 byte per essere memorizzato, l’intera firma richiederebbe 400 byte. Per memorizzare n = 10⁶ documenti, sono necessari 400 MB di spazio, il che è fattibile nella realtà. Ma confrontare ogni documento con tutti gli altri in modo forzato richiederebbe circa 5 * 10¹¹ confronti, il che è troppo, soprattutto quando n è ancora più grande.

Per evitare il problema, è possibile costruire una tabella hash per accelerare le prestazioni di ricerca, ma anche se due firme sono molto simili e differiscono solo in una posizione, è probabile che abbiano un hash diverso (perché i resti del vettore sono probabilmente diversi). Tuttavia, in genere vogliamo che cadano nello stesso bucket. Ecco dove LSH viene in soccorso.
LSH è un meccanismo che costruisce una tabella hash composta da diverse parti che inserisce una coppia di firme nello stesso bucket se hanno almeno una parte corrispondente.
LSH prende una matrice di firme e la divide in modo orizzontale in parti uguali chiamate bande, ognuna contenente r righe. Invece di inserire l’intera firma in una singola funzione hash, la firma viene divisa in b parti e ogni sottosegno viene elaborato indipendentemente da una funzione hash. Di conseguenza, ciascuna delle sottofirme cade in bucket separati.
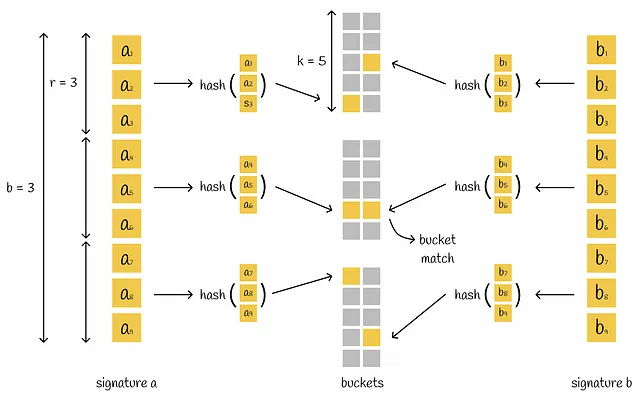
Se c’è almeno una collisione tra i sottovettori corrispondenti di due firme diverse, le firme sono considerate candidate. Come possiamo vedere, questa condizione è più flessibile poiché per considerare i vettori come candidati non è necessario che siano assolutamente uguali. Tuttavia, questo aumenta il numero di falsi positivi: una coppia di firme diverse può avere una singola parte corrispondente ma essere completamente diversa nel complesso. A seconda del problema, è sempre meglio ottimizzare i parametri b , r e k .
Tasso di errore
Con LSH, è possibile stimare la probabilità che due firme con similarità s saranno considerate candidati dati un numero di bande b e un numero di righe r in ogni banda. Troviamo la formula in diversi passaggi.
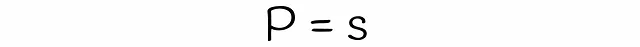
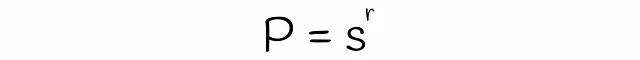
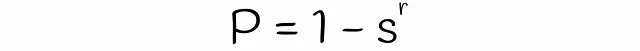
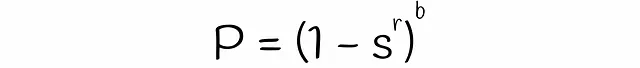
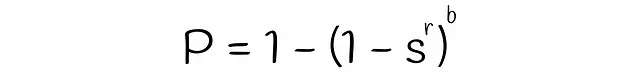
Si noti che la formula non tiene conto delle collisioni quando diversi sottovettori vengono accidentalmente hashati nello stesso bucket. A causa di ciò, la vera probabilità che le firme siano i candidati potrebbe differire insignificativamente.
Esempio
Per avere una migliore comprensione della formula appena ottenuta, consideriamo un semplice esempio. Consideriamo due firme con la lunghezza di 35 simboli divisi equamente in 5 bande con 7 righe ciascuna. Ecco la tabella che rappresenta la probabilità di avere almeno una banda uguale in base alla loro similarità di Jaccard:

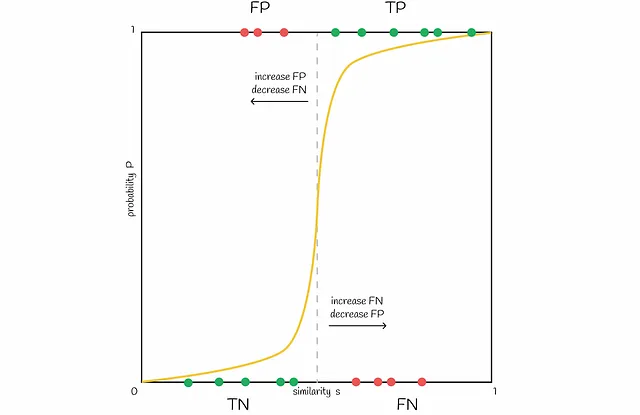
Noto che se due firme simili hanno una similarità di Jaccard dell’80%, allora hanno una banda corrispondente nel 93,8% dei casi (veri positivi). Nel restante 6,2% degli scenari, tale coppia di firme è un falso negativo.
Ora prendiamo due firme diverse. Ad esempio, sono simili solo del 20%. Pertanto, sono candidati falsi positivi nel 0,224% dei casi. In altri 99,776% dei casi, non hanno una banda simile, quindi sono veri negativi.
Visualizzazione
Visualizziamo ora la connessione tra la similarità s e la probabilità P di due firme che diventano candidati. Normalmente, con una maggiore similarità di firma s, le firme dovrebbero avere una probabilità maggiore di essere candidati. Idealmente, dovrebbe apparire come segue:
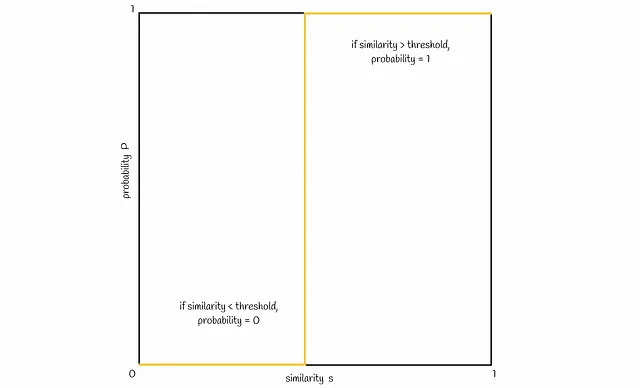
In base alla formula di probabilità ottenuta in precedenza, una linea tipica sarebbe come quella mostrata nella figura seguente:
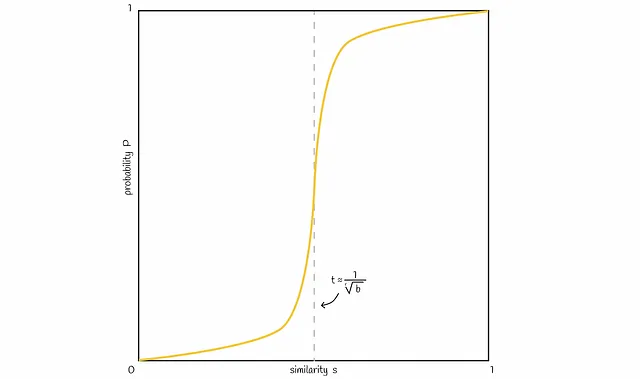
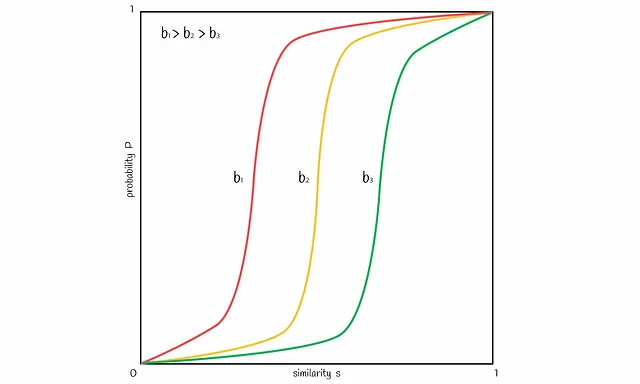
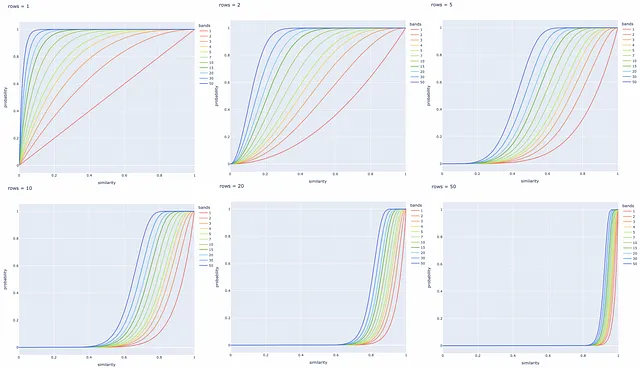
È possibile variare il numero di bande b per spostare la linea nella figura a sinistra o a destra. Aumentando b si sposta la linea a sinistra e si ottengono più FP, diminuendo — la si sposta a destra e si hanno più FN. È importante trovare un buon equilibrio, a seconda del problema.
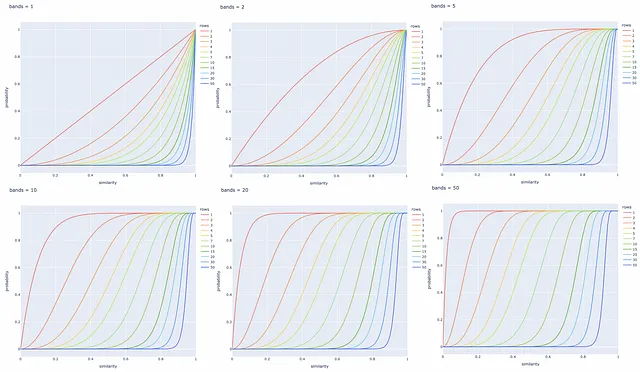
Sperimentazioni con diversi numeri di bande e righe
Sono stati creati diversi grafici a linea di seguito per diversi valori di b e r. È sempre meglio regolare questi parametri in base al compito specifico per recuperare con successo tutte le coppie di documenti simili ed ignorare quelli con firme diverse.
Conclusione
Abbiamo esplorato un’implementazione classica del metodo LSH. LSH ottimizza significativamente la velocità di ricerca utilizzando rappresentazioni di firma a dimensionalità inferiore e un meccanismo di hashing veloce per ridurre lo scopo di ricerca dei candidati. Allo stesso tempo, ciò comporta una riduzione dell’accuratezza di ricerca, ma nella pratica, la differenza è di solito insignificante.
Tuttavia, LSH è vulnerabile ai dati ad alta dimensionalità: più dimensioni richiedono lunghezze di firma più lunghe e più calcoli per mantenere una buona qualità di ricerca. In tali casi, è consigliabile utilizzare un altro indice.
In realtà, esistono diverse implementazioni di LSH, ma tutte si basano sullo stesso paradigma di trasformare i vettori di input in valori di hash mantenendo le informazioni sulla loro similarità. Fondamentalmente, altri algoritmi definiscono semplicemente altri modi per ottenere questi valori di hash.
Le proiezioni casuali sono un altro metodo LSH che verrà trattato nel prossimo capitolo e che è implementato come indice LSH nella libreria Faiss per la ricerca di similarità.
Risorse
- Locality Sensitive Hashing | Andrew Wylie | 2 dicembre 2013
- Data Mining | Locality Sensitive Hashing | Università di Szeged
- Repository Faiss
Tutte le immagini, salvo diversa indicazione, sono dell’autore.





