vLLM PagedAttention per un’Inferenza LLM 24 volte più veloce
'vLLM PagedAttention accelerates LLM inference by 24x'
Un modo più efficiente per calcolare l’attenzione del Transformer durante l’infusione
Quasi tutti i grandi modelli di linguaggio (LLM) si basano sull’architettura neurale del Transformer. Sebbene questa architettura sia apprezzata per la sua efficienza, presenta alcuni noti collo di bottiglia computazionali.
Durante la decodifica, uno di questi collo di bottiglia riguarda il calcolo dell’attenzione con coppie di tensori chiave-valore per ogni token di input. Tutti questi tensori devono essere memorizzati in memoria.
Nota: in questo articolo non spiegherò il ruolo di queste coppie chiave-valore. È uno degli aspetti più complicati e interessanti dell’architettura del Transformer. Se non ne sei a conoscenza, ti consiglio vivamente di leggere The Illustrated Transformer di Jay Alammar.
Poiché LLM accetta input sempre più lunghi, ad esempio LLM Claude accetta input di 100.000 token di lunghezza, la memoria consumata da questi tensori può diventare molto grande.
- 5 Modi per Ottenere Dataset Interessanti per il Tuo Prossimo Progetto di Dati (Non Kaggle)
- I 10 Migliori Strumenti di Modellizzazione dei Dati da Conoscere nel 2023.
- Troppe funzionalità? Analizziamo l’Analisi delle Componenti Principali
Memorizzare tutti questi tensori in memoria in modo ingenuo porta a sovra-prenotazione e frammentazione della memoria. Questa frammentazione può rendere l’accesso alla memoria molto inefficiente, soprattutto per sequenze lunghe di token. Per quanto riguarda la sovra-prenotazione, il sistema lo fa per assicurarsi di aver allocato abbastanza memoria per i tensori, anche se non ne consuma tutto.
Per alleviare questi problemi, UC Berkeley propone PagedAttention.
PagedAttention è implementato in vLLM (licenza Apache 2.0) che è distribuito da LMSYS, un’organizzazione per la ricerca aperta fondata da studenti e docenti di UC Berkeley con l’aiuto di UCSD e CMU.
In questo articolo, spiego cos’è PagedAttention e perché accelera significativamente la decodifica. Mostro alla fine dell’articolo come iniziare con vLLM per sfruttare PagedAttention per l’infusione e la distribuzione di LLM sul tuo computer.
PagedAttention per il Transformer
Kwon et al. (2023) propongono PagedAttention.
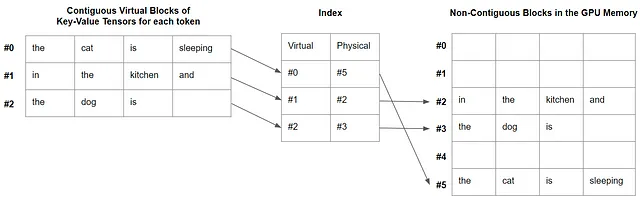
Lo scopo è quello di memorizzare i tensori chiave-valore in modo più efficiente negli spazi non contigui della VRAM della GPU.
In breve, l’idea alla base di PagedAttention è quella di creare blocchi virtuali contigui mappati in blocchi fisici nella memoria della GPU.
Ogni blocco è progettato per memorizzare i tensori di coppie chiave-valore per un numero predefinito di token. Tutti i blocchi sono virtualmente contigui e mappati in blocchi fisici non contigui, allocati su richiesta durante l’infusione, nella frammentata memoria della GPU. Viene anche creato un semplice indice in memoria per associare i blocchi virtuali a quelli fisici.
Il kernel di PagedAttention recupera come necessario questi blocchi. Questo è efficiente perché il sistema recupera un numero più piccolo di tensori chiave-valore a causa della dimensione limitata dei blocchi.
Prendiamo il seguente prompt per illustrazione:
il gatto sta dormendo in cucina e il cane è
Abbiamo i tensori di coppie chiave-valore per ogni token. Con PageAttention, possiamo (arbitrariamente) impostare la dimensione del blocco a 4. Ogni blocco contiene 4 tensori di coppie chiave-valore, tranne l’ultimo che contiene solo 3 tensori di coppie chiave-valore. I blocchi sono virtualmente contigui ma non necessariamente contigui nella memoria della GPU, come illustrato dalla figura nell’introduzione di questo articolo.
Per il calcolo dell’attenzione, per ogni token di query, il sistema recupera il blocco uno per uno, come illustrato di seguito.
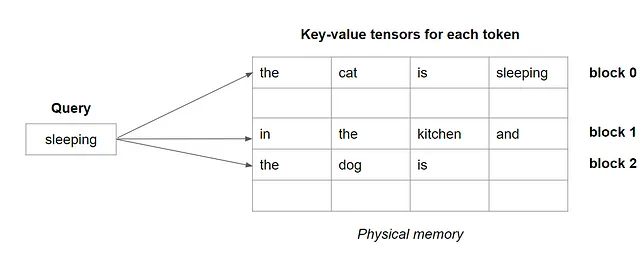
Recuperando i tensori di coppie chiave-valore per blocchi, invece dell’intera sequenza di tensori, il calcolo dell’attenzione è molto più veloce.
Campionamento parallelo per l’Inferenza
Un altro vantaggio di PagedAttention è che i blocchi virtuali possono essere condivisi durante il campionamento durante l’inferenza. Tutte le sequenze generate in parallelo tramite campionamento o ricerca con beam possono utilizzare gli stessi blocchi virtuali, evitando duplicati.
Nelle loro esperienze, LMSYS ha osservato una riduzione del 55% nell’utilizzo della memoria per la decodifica della ricerca con beam.
Prestazioni di PagedAttention riportate da LMSYS
Prima di provarlo da soli, diamo un’occhiata alle prestazioni riportate dagli autori (UC Berkely / LMSYS) quando si utilizza PagedAttention implementato in vLLM rispetto alla libreria di inferenza di generazione di testo sviluppata da Hugging Face.
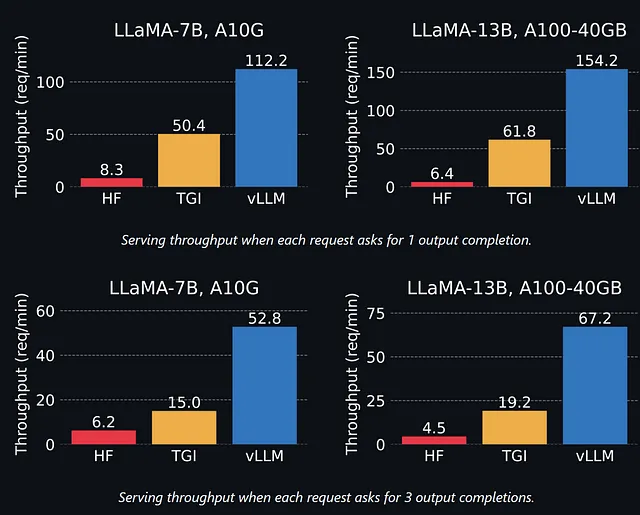
vLLM sembra molto più veloce secondo questi risultati, soprattutto nel caso di molteplici completamenti di output. La differenza tra TGI e vLLM aumenta con modelli più grandi. Questo è previsto poiché i modelli più grandi richiedono più memoria e sono quindi più influenzati dalla frammentazione della memoria.
In generale, vLLM è fino a 24 volte più veloce della libreria Hugging Face Transformers.
Nota: In realtà, sono anche impressionato dal miglioramento da HF a TGI. Non ho ancora coperto TGI sul mio blog, ma probabilmente scriverò una guida al riguardo. TGI è utilizzato in produzione da Hugging Face. Sebbene sembri molto più lento di vLLM, TGI ha altri vantaggi come il supporto per molti più modelli e funzionalità.
Come configurare vLLM sul tuo computer
Nota: vLLM non supporta ancora CUDA 12. Utilizzare una versione inferiore, come la 11.8.
In questa sezione, verranno trattati solo i concetti di base su come configurare e eseguire vLLM sul tuo computer. Per un utilizzo più avanzato, puoi dare un’occhiata alla documentazione vLLM.
Mentre scrivo questo articolo, vLLM supporta solo alcuni tipi di modelli :
- GPT-2
- GPT-NeoX e basati su Pythia
- LLaMa basati
- OPT basati
Puoi aggiungere il supporto di altri modelli seguendo queste istruzioni.
Nel codice qui sotto, utilizzo Dolly V2 (licenza MIT). È un modello di chat basato su Pythia e addestrato da DataBricks.
Ho scelto la versione più piccola con 3 miliardi di parametri. Può essere eseguito su una GPU di consumo con 24 GB di VRAM, ad esempio un nVidia RTX 3080/3090.
Il modo più semplice per installare vLLM è con pip:
pip install vllmNota: questo dovrebbe richiedere fino a 10 minuti.
Ma nel mio caso, sia sul mio computer che su Google Colab, pip non è riuscito ad installare la libreria vllm. Gli autori di vLLM confermano che c’è un problema con alcune versioni di nvcc e ambienti. Tuttavia, per la maggior parte delle configurazioni, pip dovrebbe installare vLLM senza alcun problema.
Se ti trovi nella stessa situazione in cui mi trovo io, la soluzione alternativa è semplicemente utilizzare un’immagine Docker. Questo ha funzionato per me:
docker run --gpus all -it --rm --shm-size=8g nvcr.io/nvidia/pytorch:22.12-py3Nota: una volta dentro il docker, gli autori raccomandano di rimuovere Pytorch prima di installare vLLM: pip uninstall torch. Quindi, “pip install vllm” dovrebbe funzionare.
Dopo di che, possiamo iniziare a scrivere Python.
Prima di tutto, abbiamo bisogno di importare vllm, e quindi caricare il modello con vllm. L’inferenza viene innescata da llm.generate().
from vllm import LLM
prompts = ["Parlami della gravità"] #Puoi inserire diverse richieste in questa listallm = LLM(model="databricks/dolly-v2-3b") # Carica il modellooutputs = llm.generate(prompts) # Avvia l'inferenzaPuoi anche utilizzare vLLM per fornire LLM. Funziona in modo simile a TGI. È anche molto più semplice rispetto all’esecuzione del server di inferenza NVIDIA Triton descritto in un precedente articolo.
Innanzitutto, devi avviare il server:
python -m vllm.entrypoints.openai.api_server --model databricks/dolly-v2-3bNota: il server sarà in ascolto sulla porta 8000. Assicurati che sia disponibile o cambialo nel file di configurazione vLLM.
Quindi, puoi interrogare il server con richieste come segue:
curl http://localhost:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "databricks/dolly-v2-3b", "prompt": "Parlami della gravità", "max_tokens": 200 }'E questo è tutto! Hai un server LLM molto efficiente in esecuzione sul tuo computer.
Conclusione
PagedAttention accelera significativamente l’inferenza. È un altro passo verso l’AI più accessibile con LLM.
In ulteriori esperimenti, ho confermato che vLLM è particolarmente efficiente con batch di richieste. Per sfruttare appieno vLLM, considera di ottimizzare la tua strategia di batching per l’inferenza.
Anche se la ricerca di beam con grandi beam potrebbe essere stata proibitiva con il calcolo dell’attenzione standard, la ricerca di beam con PagedAttention è più veloce e più efficiente in termini di memoria.
Uno dei miei prossimi esperimenti sarà quello di combinare PagedAttention con QLoRa per ridurre l’uso della memoria. Dovrebbe essere semplice. Ciò renderebbe ancora più efficiente l’esecuzione di LLM su hardware per consumatori.
Se ti piace questo articolo e sei interessato a leggere quelli successivi, il modo migliore per supportare il mio lavoro è diventare un membro di Nisoo usando questo link:
Unisciti a Nisoo con il mio link di referral – Benjamin Marie
Come membro di Nisoo, una parte della tua quota di iscrizione va ai writer che leggi, e hai accesso completo ad ogni storia…
Nisoo.com
Se sei già un membro e vuoi supportare questo lavoro, seguimi su Nisoo.