Spiegazione dei Database Vettoriali in 3 Livelli di Difficoltà
Livelli di Difficoltà dei Database Vettoriali.
Da principiante a esperto: Demistificazione dei database vettoriali tra diversi contesti
Di recente, i database vettoriali hanno attirato molta attenzione, con molte start-up di database vettoriali che raccolgono milioni di finanziamenti.
Probabilmente ne hai già sentito parlare, ma finora non ti interessavano molto – almeno, è quello che suppongo sia il motivo per cui sei qui ora…
Se sei qui solo per una risposta breve, cominciamo subito:
Definizione: Cos’è un Database Vettoriale?
Un database vettoriale è un tipo di database che archivia e gestisce dati non strutturati, come testo, immagini o audio, in incorporamenti vettoriali (vettori ad alta dimensione) per facilitare la ricerca e il recupero rapido di oggetti simili.
- 10 Domande sulla lista Python più frequentemente poste su Stack Overflow
- Scaling dei dati con Python
- Incontra l’evangelista dell’IA presso Metaphy Labs
Se questa definizione ha causato solo confusione, allora procediamo passo dopo passo. Questo articolo è ispirato alla serie video “5 Levels” di WIRED e spiega cosa sono i database vettoriali nei seguenti tre livelli di difficoltà:
- Spiegato come se avessi 5 anni
- Spiegare i Database Vettoriali ai Nativi Digitali e agli Appassionati di Tecnologia
- Spiegare i Database Vettoriali agli Ingegneri e ai Professionisti dei Dati
Database Vettoriali: Spiegato come se avessi 5 anni (ELI5)
Questo è leggermente fuori tema, ma sai cosa non capisco?
Quando le persone organizzano le loro librerie per colore. — Accidenti!
Come fanno a trovare un libro quando non sanno di che colore è la copertina del libro?
L’intuizione dietro i database vettoriali
Se vuoi trovare un libro specifico velocemente, organizzare la tua libreria per genere e poi per autore ha molto più senso che per colore. Ecco perché la maggior parte delle biblioteche è organizzata in questo modo per aiutarti a trovare ciò che stai cercando rapidamente.
Ma come fai a trovare qualcosa da leggere in base a una query invece che per genere o autore? Cosa succede se vuoi leggere un libro che è, ad esempio:
- simile a “La Piccola Oruga Glotona” o
- riguarda un personaggio principale a cui piace mangiare tanto quanto a te?
Se non hai tempo per cercare tra gli scaffali dei libri, il modo più veloce per fare ciò sarebbe chiedere al bibliotecario un suo consiglio perché ha letto molti libri e saprà esattamente quale si adatta meglio alla tua query.
Nell’esempio dell’organizzazione dei libri, puoi pensare al bibliotecario come a un database vettoriale perché i database vettoriali sono progettati per archiviare informazioni complesse (ad esempio, la trama di un libro) su un oggetto (ad esempio, un libro). Pertanto, i database vettoriali possono aiutarti a trovare oggetti in base a una query specifica (ad esempio, un libro che tratta di…) anziché a pochi attributi predefiniti (ad esempio, l’autore) – proprio come un bibliotecario.
Spiegare i Database Vettoriali ai Nativi Digitali e agli Appassionati di Tecnologia
Ora, rimaniamo all’esempio della biblioteca e andiamo un po’ più nel dettaglio: Ovviamente, oggigiorno ci sono tecniche più avanzate per cercare un libro in una biblioteca che solo per genere o autore.
Se visiti una biblioteca, di solito c’è un computer nell’angolo che ti aiuta a trovare un libro con attributi più specifici, come il titolo, l’ISBN, l’anno di pubblicazione o alcune parole chiave. In base ai valori che inserisci, viene interrogato un database dei libri disponibili. Questo database di solito è un tradizionale database relazionale.

Qual è la differenza tra un database relazionale e un database vettoriale?
La principale differenza tra i database relazionali e i database vettoriali risiede nel tipo di dati che memorizzano. Mentre i database relazionali sono progettati per i dati strutturati che si adattano alle tabelle, i database vettoriali sono destinati ai dati non strutturati, come testo o immagini.
Il tipo di dati memorizzato influisce anche su come i dati vengono recuperati: nei database relazionali, i risultati delle query si basano su corrispondenze per parole chiave specifiche. Nei database vettoriali, i risultati delle query si basano su similitudini.
Puoi pensare ai database relazionali tradizionali come a dei fogli di calcolo. Sono ottimi per memorizzare dati strutturali, come informazioni di base su un libro (ad esempio, titolo, autore, ISBN, ecc.), perché questo tipo di informazioni può essere archiviato in colonne, che sono ottime per filtrare e ordinare.
Con i database relazionali, puoi ottenere rapidamente tutti i libri che sono, ad esempio, libri per bambini e che contengono “bruco” nel titolo.
Ma cosa succede se ti piaceva che “La piccola oruga che aveva fame” parlasse di cibo? Potresti provare a cercare la parola chiave “cibo”, ma a meno che la parola chiave “cibo” non venga menzionata nel riassunto del libro, non troverai nemmeno “La piccola oruga che aveva fame”. Invece, probabilmente finirai con una serie di libri di cucina e con la delusione.
E questa è una limitazione dei database relazionali: devi aggiungere tutte le informazioni che pensi che qualcuno potrebbe aver bisogno per trovare quel determinato elemento. Ma come sai quali informazioni e quante di esse aggiungere? Aggiungere tutte queste informazioni è tempo-consuming e non garantisce la completezza.
Ecco dove entrano in gioco i database vettoriali!
Ma prima, una piccola deviazione su un concetto chiamato incorporamenti vettoriali.
Gli algoritmi di Machine Learning (ML) di oggi possono convertire un dato oggetto (ad esempio, una parola o un testo) in una rappresentazione numerica che conserva le informazioni di quell’oggetto. Immagina di dare a un modello ML una parola (ad esempio, “cibo”), quindi quel modello ML fa la sua magia e ti restituisce un lungo elenco di numeri. Questo lungo elenco di numeri è la rappresentazione numerica della tua parola e viene chiamato incorporamento vettoriale.
Poiché questi incorporamenti sono un lungo elenco di numeri, li chiamiamo ad alta dimensione. Facciamo finta per un secondo che questi incorporamenti siano solo tridimensionali per visualizzarli come mostrato di seguito.
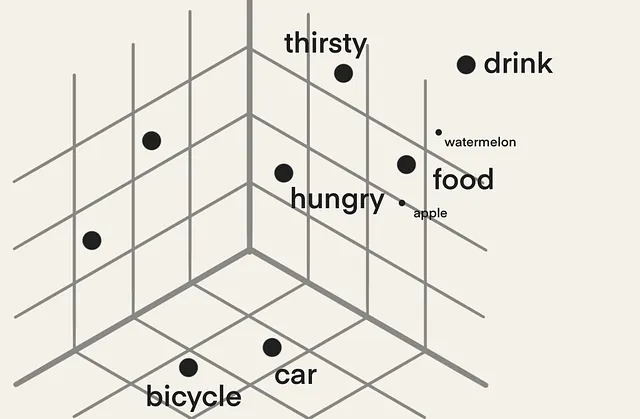
Puoi vedere che parole simili come “affamato”, “assetato”, “cibo” e “bevanda” sono tutte raggruppate in un angolo simile, mentre altre parole come “bicicletta” e “auto” sono vicine ma in un angolo diverso in questo spazio vettoriale.
Le rappresentazioni numeriche ci consentono di applicare calcoli matematici a oggetti, come parole, che di solito non sono adatti per i calcoli. Ad esempio, il seguente calcolo non funzionerà a meno che non sostituisci le parole con i loro incorporamenti:
bevanda - cibo + affamato = assetatoE poiché siamo in grado di utilizzare gli incorporamenti per i calcoli, possiamo anche calcolare le distanze tra una coppia di oggetti incorporati. Più due oggetti incorporati sono vicini tra loro, più sono simili.
Come puoi vedere, gli incorporamenti vettoriali sono piuttosto cool.
Torniamo al nostro esempio e diciamo che incorporiamo il contenuto di ogni libro nella biblioteca e memorizziamo questi incorporamenti in un database vettoriale. Ora, quando vuoi trovare un “libro per bambini con un personaggio principale che ama il cibo”, anche la tua query viene incorporata e vengono restituiti i libri più simili alla tua query, come “La piccola oruga che aveva fame” o forse “Riccioli d’oro e i tre orsi”.
Quali sono i casi d’uso dei database vettoriali?
I database vettoriali esistevano già prima dell’hype intorno ai Large Language Models (LLM). All’inizio, venivano utilizzati nei sistemi di raccomandazione perché possono trovare rapidamente oggetti simili per una query data. Ma perché possono fornire una memoria a lungo termine ai LLM, sono stati utilizzati di recente nelle applicazioni di domande e risposte.
Spiegazione dei database vettoriali a ingegneri e professionisti dei dati
Se hai già immaginato che i database di vettori siano probabilmente un modo per archiviare le incapsulazioni di vettori prima di aprire questo articolo e vuoi solo sapere cosa sono le incapsulazioni di vettori, allora entriamo nei dettagli e parliamo degli algoritmi.
Come funzionano i database di vettori?
I database di vettori sono in grado di recuperare rapidamente oggetti simili a una query perché li hanno già pre-calcolati. Il concetto sottostante si chiama ricerca di Nearest Neighbor Approssimato (ANN), che utilizza diversi algoritmi per l’indicizzazione e il calcolo delle similarità.
Come puoi immaginare, calcolare le similarità tra una query e ogni oggetto incorporato che hai con un semplice algoritmo dei k-nearest neighbors (kNN) può diventare lento quando hai milioni di incapsulazioni. Con ANN, puoi scambiare un po’ di precisione in cambio di velocità e recuperare gli oggetti più simili approssimativamente a una query.
Indicizzazione — Per fare ciò, un database di vettori indicizza le incapsulazioni di vettori. Questo passaggio mappa i vettori in una struttura dati che consentirà una ricerca più veloce.
Puoi pensare all’indicizzazione come alla suddivisione dei libri in una biblioteca in diverse categorie, come autore o genere. Ma poiché le incapsulazioni possono contenere informazioni più complesse, ulteriori categorie potrebbero essere “genere del personaggio principale” o “luogo principale della trama”. L’indicizzazione può quindi aiutarti a recuperare una porzione più piccola di tutti i vettori disponibili e quindi velocizzare il recupero.
Non entreremo nei dettagli tecnici degli algoritmi di indicizzazione, ma se sei interessato a ulteriori letture, potresti iniziare cercando Hierarchical Navigable Small World (HNSW).
Misure di similarità — Per trovare i vicini più prossimi alla query tra i vettori indicizzati, un database di vettori applica una misura di similarità. Le misure di similarità comuni includono la similarità coseno, il prodotto scalare, la distanza euclidea, la distanza di Manhattan e la distanza di Hamming.
Qual è il vantaggio dei database di vettori rispetto all’archiviazione delle incapsulazioni di vettori in un array NumPy?
Una domanda che mi è capitato di sentire spesso è: Non possiamo semplicemente usare array NumPy per archiviare le incapsulazioni? — Certo, puoi farlo se non hai molte incapsulazioni o se stai lavorando solo a un progetto divertente. Ma come puoi immaginare, i database di vettori sono notevolmente più veloci quando hai molte incapsulazioni e non devi tenere tutto in memoria.
La terrò breve perché Ethan Rosenthal ha fatto un lavoro molto migliore nel spiegare la differenza tra l’uso di un database di vettori e l’uso di un array NumPy di quanto potrei mai scrivere.
Hai davvero bisogno di un database di vettori? | Ethan Rosenthal
Attenzione: la risposta è forse! Anche se l’inclusione della parola “davvero” tradisce il mio pregiudizio. I database di vettori sono…
www.ethanrosenthal.com
Ti è piaciuta questa storia?
Iscriviti gratuitamente per essere avvisato quando pubblico una nuova storia.
Vuoi leggere più di 3 storie gratuite al mese? — Diventa un membro di Nisoo per 5$/mese. Puoi supportarmi utilizzando il mio link di referral quando ti registri. Riceverò una commissione senza costi aggiuntivi per te.
Unisciti a Nisoo con il mio link di referral — Leonie Monigatti
Leggi ogni storia di Leonie Monigatti (e migliaia di altri scrittori su Nisoo). La tua quota di iscrizione va direttamente…
Nisoo.com
Trovami su LinkedIn, Twitter e Kaggle!






