Scaling dei dati con Python
Data Scaling with Python
Come scalare i tuoi dati per renderli adatti alla costruzione del modello.

Nel processo di machine learning, la scalatura dei dati rientra nella pre-elaborazione dei dati o nell’ingegneria delle caratteristiche. La scalatura dei dati prima di utilizzarli per la costruzione del modello può ottenere i seguenti risultati:
- La scalatura garantisce che le caratteristiche abbiano valori nello stesso intervallo
- La scalatura garantisce che le caratteristiche utilizzate per la costruzione del modello siano adimensionali
- La scalatura può essere utilizzata per rilevare gli outlier
Esistono diversi metodi per la scalatura dei dati. Le due tecniche di scalatura più importanti sono la normalizzazione e la standardizzazione.
- Incontra l’evangelista dell’IA presso Metaphy Labs
- Il 70% degli sviluppatori abbraccia l’AI oggi Approfondimento sulla crescita dei grandi modelli linguistici, LangChain e dei database vettoriali nel panorama tecnologico attuale.
- Ricercatori di Microsoft propongono un nuovo framework per la calibrazione LLM utilizzando l’auto-supervisione di Pareto ottimale senza l’utilizzo di dati di addestramento etichettati.
Scalatura dei dati mediante normalizzazione
Quando i dati vengono scalati mediante normalizzazione, i dati trasformati possono essere calcolati utilizzando questa equazione
dove
Implementazione in Python della normalizzazione
La scalatura mediante normalizzazione può essere implementata in Python utilizzando il seguente codice:
from sklearn.preprocessing import Normalizer
norm = Normalizer()
X_norm = norm.fit_transform(data)Sia X un dato fornito con
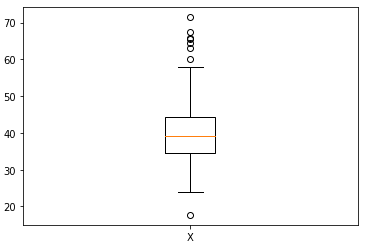
Il X normalizzato è mostrato nella figura sottostante:
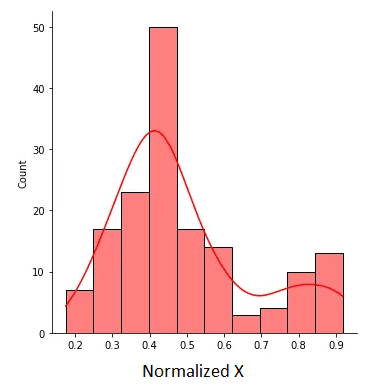 Figura 2. X normalizzato con valori compresi tra 0 e 1. Immagine dell’autore.
Figura 2. X normalizzato con valori compresi tra 0 e 1. Immagine dell’autore.
Scalatura dei dati mediante standardizzazione
Idealemente, la standardizzazione dovrebbe essere utilizzata quando i dati sono distribuiti secondo la distribuzione normale o gaussiana. I dati standardizzati possono essere calcolati come segue:
Qui, è la media dei dati e
è la deviazione standard. I valori standardizzati dovrebbero tipicamente trovarsi nell’intervallo [-2, 2], che rappresenta l’intervallo di confidenza del 95%. I valori standardizzati inferiori a -2 o superiori a 2 possono essere considerati outlier. Pertanto, la standardizzazione può essere utilizzata per la rilevazione degli outlier.
Implementazione in Python della standardizzazione
La scalatura mediante standardizzazione può essere implementata in Python utilizzando il seguente codice:
from sklearn.preprocessing import StandardScaler
stdsc = StandardScaler()
X_std = stdsc.fit_transform(data)Utilizzando i dati descritti in precedenza, i dati standardizzati sono mostrati di seguito:
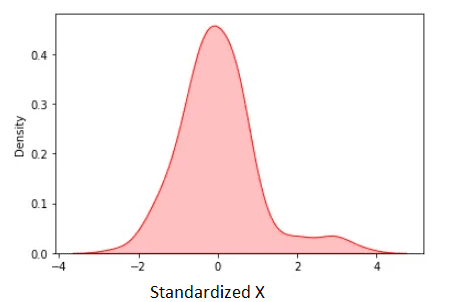 Figura 3. X standardizzato. Immagine dell’autore.
Figura 3. X standardizzato. Immagine dell’autore.
La media standardizzata è zero. Dalla figura sopra osserviamo che, ad eccezione di alcuni pochi outlier, la maggior parte dei dati standardizzati si trova nell’intervallo [-2, 2].
Conclusione
In sintesi, abbiamo discusso due dei metodi più popolari per la ridimensionamento delle caratteristiche, ovvero: standardizzazione e normalizzazione. I dati normalizzati si trovano nell’intervallo [0, 1], mentre i dati standardizzati si trovano tipicamente nell’intervallo [-2, 2]. Il vantaggio della standardizzazione è che può essere utilizzata per la rilevazione degli outlier. Benjamin O. Tayo è un fisico, educatore di data science e scrittore, nonché proprietario di DataScienceHub. In passato, Benjamin ha insegnato ingegneria e fisica presso l’Università di Central Oklahoma, l’Università del Grand Canyon e la Pittsburgh State University.




