Analisi in-database sfruttare le funzioni analitiche di SQL
In-database analysis using SQL analytic functions.
Scopri le varie funzioni analitiche SQL come RANK(), NTILE(), CUME_DIST() e altre ancora per potenziare le tue competenze di analisi dei dati al livello successivo.

Tutti conosciamo l’importanza dell’analisi dei dati nel mondo odierno basato sui dati e come ci offra preziosi insight dai dati disponibili. Ma a volte, l’analisi dei dati diventa molto impegnativa e richiede molto tempo per l’analista dei dati. La ragione principale per cui è diventato così frenetico al giorno d’oggi è l’enorme volume di dati generati e la necessità di strumenti esterni per eseguire tecniche di analisi complesse su di esso.
Ma cosa succede se analizziamo i dati direttamente nel database e con query significativamente semplificate? Questo è possibile utilizzando le funzioni analitiche SQL. Questo articolo discuterà delle varie funzioni analitiche SQL che possono essere eseguite all’interno del SQL Server e ci permetteranno di ottenere risultati preziosi.
- Costruzione di Sistemi di Raccomandazione Potenti con Deep Learning
- Smetti di usare PowerPoint per le tue presentazioni di Machine Learning e prova invece questo
- Come creare test di dati preziosi
Queste funzioni calcolano il valore aggregato in base a un gruppo di righe e vanno oltre le operazioni di base sulle righe. Ci forniscono strumenti per il ranking, i calcoli delle serie temporali, la finestrazione e l’analisi delle tendenze. Quindi, senza perdere ulteriore tempo, iniziamo a discutere queste funzioni una per una con alcuni dettagli ed esempi pratici. Il prerequisito di questo tutorial è la conoscenza pratica di base delle query SQL.
Creazione di una tabella demo
Creaeremo una tabella demo e applicheremo tutte le funzioni analitiche su questa tabella in modo che tu possa seguirla facilmente con il tutorial.
Nota: Alcune funzioni discusse in questo tutorial non sono presenti in SQLite. È quindi preferibile utilizzare MySQL o PostgreSQL Server.
Questa tabella contiene i dati di diversi studenti universitari, con quattro colonne: ID studente, Nome studente, Soggetto e Voto finale su 100.
Creazione di una tabella Studenti contenente 4 colonne:
CREATE TABLE students
(
id INT NOT NULL PRIMARY KEY,
NAME VARCHAR(255),
subject VARCHAR(30),
final_marks INT
); Ora, inseriremo alcuni dati fittizi in quella tabella.
INSERT INTO Students (id, name, subject, final_marks)
VALUES (1, 'John', 'Matematica', 89),
(2, 'Kelvin', 'Fisica', 67),
(3, 'Peter', 'Chimica', 78),
(4, 'Saina', 'Matematica', 44),
(5, 'Pollard', 'Chimica', 91),
(6, 'Steve', 'Biologia', 88),
(7, 'Jos', 'Fisica', 89),
(8, 'Afridi', 'Matematica', 97),
(9, 'Ricky', 'Biologia', 78),
(10, 'David', 'Chimica', 93),
(11, 'Jofra', 'Chimica', 93),
(12, 'James', 'Biologia', 65),
(13, 'Adam', 'Matematica', 90),
(14, 'Warner', 'Biologia', 45),
(15, 'Virat', 'Fisica', 56);Ora visualizzeremo la nostra tabella.
SELECT *
FROM studentsOutput:
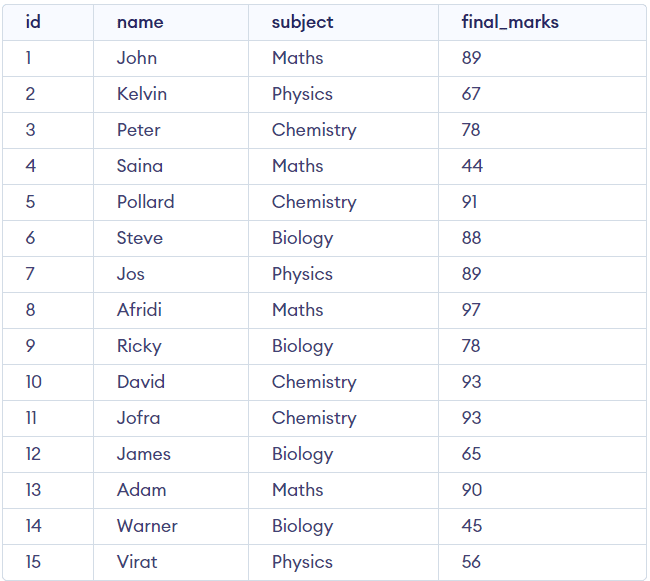
Siamo pronti per eseguire le funzioni analitiche.
RANK() & DENSE_RANK()
La funzione RANK() assegnerà a ciascuna riga all’interno di una partizione un rango specifico in base all’ordine specificato. Se le righe hanno valori identici nella stessa partizione, assegna loro lo stesso rango.
Capiremo meglio con l’esempio seguente.
SELECT *,
Rank()
OVER (
ORDER BY final_marks DESC) AS 'ranks'
FROM students;Output:
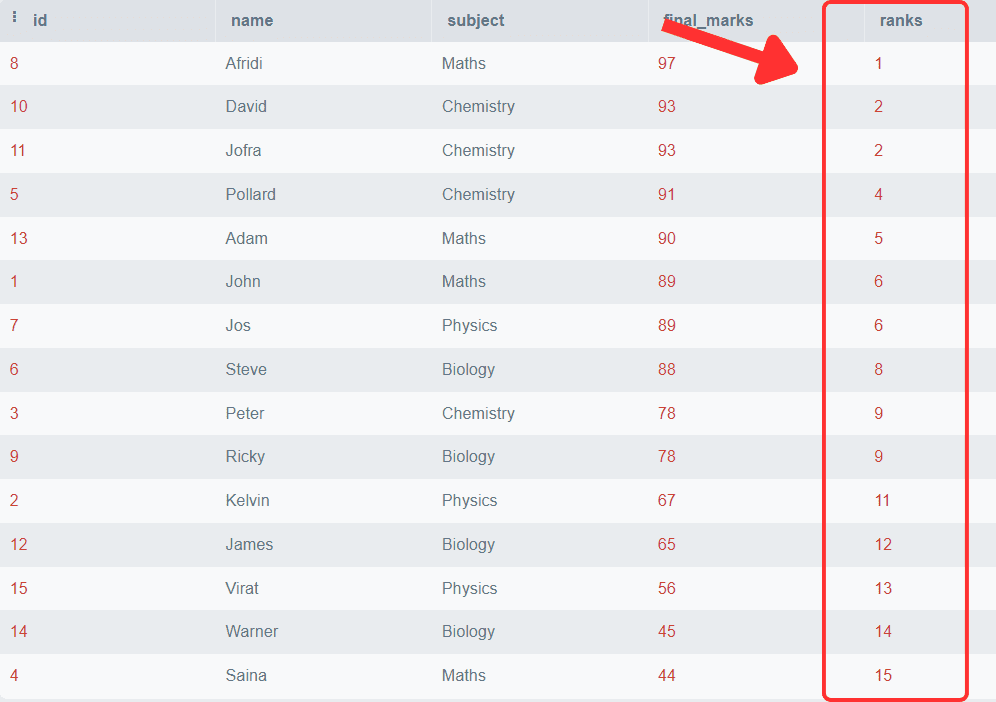
Puoi osservare che i voti finali sono disposti in ordine decrescente e a ogni riga è associato un rango specifico. Puoi anche osservare che gli studenti con gli stessi voti ottengono lo stesso rango e il rango successivo dopo la riga duplicata viene saltato.
Possiamo anche trovare i migliori studenti di ogni materia, ovvero possiamo partizionare il rango in base alle materie. Vediamo come farlo.
SELECT *,
Rank()
OVER (
PARTITION BY subject
ORDER BY final_marks DESC) AS 'ranks'
FROM students;Output:
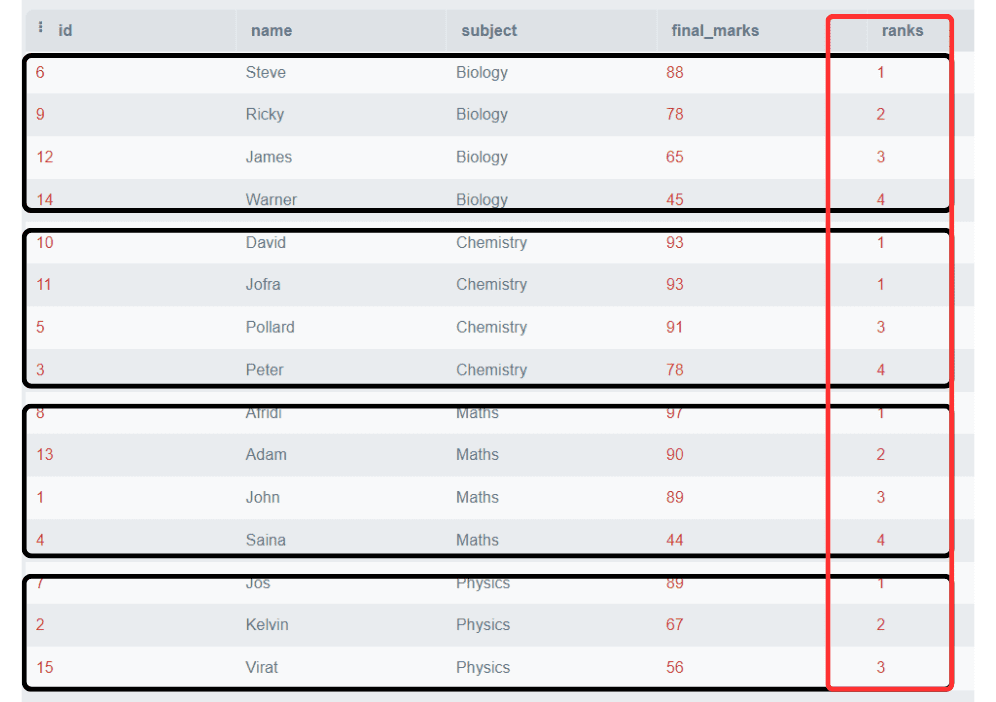
In questo esempio, abbiamo partizionato il ranking in base alle materie e i punteggi sono assegnati separatamente per ogni materia.
Nota: Si osservi che due studenti hanno ottenuto lo stesso punteggio nella materia di Chimica, classificati come 1, e il punteggio per la riga successiva inizia direttamente da 3. Si salta il punteggio di 2.
Questa è la caratteristica della funzione RANK() che non è sempre necessario produrre classifiche consecutivamente. La classifica successiva sarà la somma della classifica precedente e dei numeri duplicati.
Per superare questo problema, è stata introdotta la funzione DENSE_RANK() che funziona in modo simile alla funzione RANK(), ma assegna sempre classifiche consecutivamente. Seguire l’esempio seguente:
SELECT *,
DENSE_RANK()
OVER (
PARTITION BY materia
ORDER BY punteggio_finale DESC) AS 'classifica'
FROM studenti;Output:
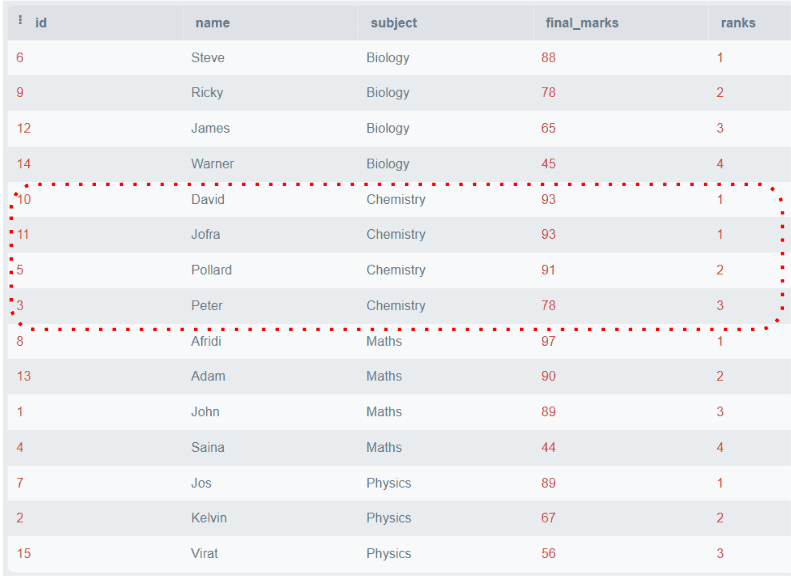 Nella figura sopra, tutte le classifiche sono consecutive, anche se i punteggi duplicati si trovano nella stessa partizione.
Nella figura sopra, tutte le classifiche sono consecutive, anche se i punteggi duplicati si trovano nella stessa partizione.
NTILE()
La funzione NTILE() viene utilizzata per dividere le righe in un numero specificato (N) di bucket di dimensioni approssimativamente uguali. Ogni riga viene assegnata un numero di bucket da 1 a N (numero totale di bucket).
Possiamo anche applicare la funzione NTILE() su una specifica partizione o ordinamento, che vengono specificati nelle clausole PARTITION BY e ORDER BY.
Supponiamo che N non sia perfettamente divisibile per il numero di righe. In tal caso, la funzione creerà bucket di dimensioni diverse con una differenza di uno.
Sintassi:
NTILE(n) OVER (PARTITION BY c1, c2 ORDER BY c3)La funzione NTILE() richiede un parametro obbligatorio N, ovvero il numero di bucket, e alcuni parametri opzionali come la clausola PARTITION BY e ORDER BY. NTILE() dividerà le righe in base all’ordine specificato da queste clausole.
Prendiamo ad esempio la nostra tabella “Studenti”. Supponiamo che vogliamo dividere gli studenti in gruppi in base ai loro punteggi finali. Creeremo tre gruppi. Il Gruppo 1 conterrà gli studenti con i punteggi più alti. Il Gruppo 2 avrà tutti gli studenti mediocri e il Gruppo 3 includerà gli studenti con punteggi bassi.
SELECT *,
NTILE(3)
OVER (
ORDER BY punteggio_finale DESC) AS bucket
FROM studenti; Output:
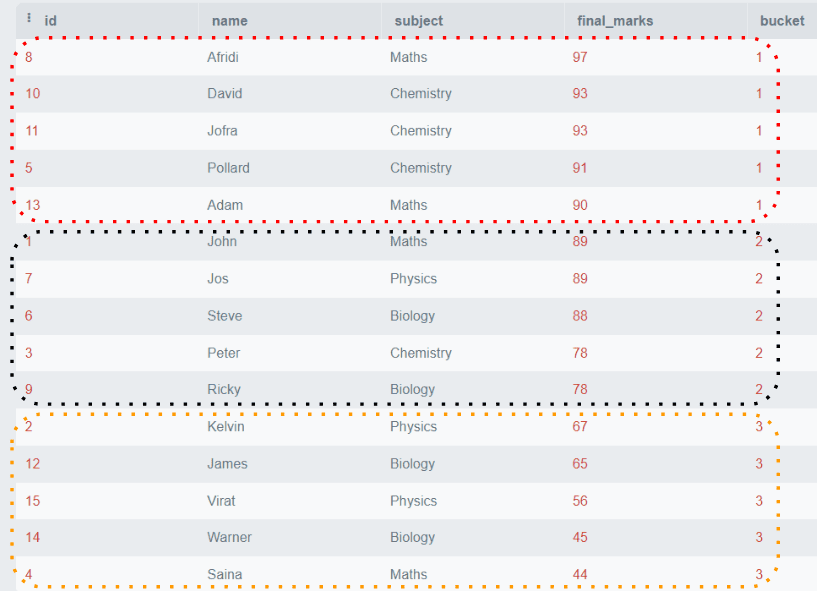
Nell’esempio precedente, tutte le righe sono ordinate per punteggio_finale e divise in tre gruppi contenenti cinque righe per gruppo.
NTILE() è utile quando vogliamo dividere dei dati in gruppi uguali in base a determinati criteri specificati. Può essere utilizzato nelle applicazioni come la segmentazione dei clienti in base agli articoli acquistati o la categorizzazione delle prestazioni dei dipendenti, ecc.
CUME_DIST()
La funzione CUME_DIST() trova la distribuzione cumulativa di un valore particolare in ogni riga all’interno di una partizione o di un ordine specificato. La Cumulative Distribution Function (CDF) indica la probabilità che la variabile casuale X sia minore o uguale a x. Viene indicata con F(x) e la sua formula matematica è rappresentata come,
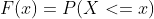
P(x) è la Probability Distribution Function (Funzione di Distribuzione di Probabilità).
In parole semplici, la funzione CUME_DIST() restituisce la percentuale di righe il cui valore è minore o uguale al valore corrente della riga. Ci aiuterà ad analizzare la distribuzione dei dati e anche la posizione relativa di un valore nell’insieme.
SELECT *,
CUME_DIST()
OVER (
ORDER BY punteggio_finale) AS distrib_cum
FROM studenti; Output:
Il codice sopra ordinerà tutte le righe in base a final_marks e troverà la distribuzione cumulativa, ma se si desidera suddividere i dati in base alle materie, è possibile utilizzare la clausola PARTITION BY. Di seguito è riportato un esempio di come farlo.
SELECT *,
CUME_DIST()
OVER (
PARTITION BY subject
ORDER BY final_marks) AS cum_dis
FROM students; Output:
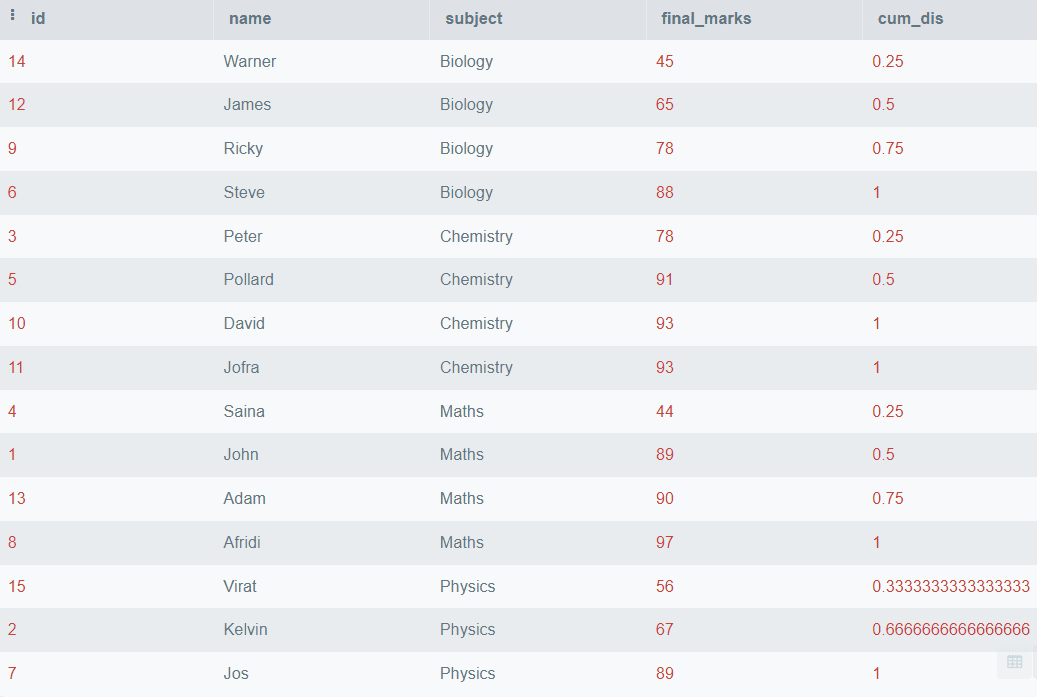
Nell’output precedente, abbiamo visto la distribuzione cumulativa di final_marks suddivisa per il nome del soggetto.
STDDEV() e VARIANCE()
La funzione VARIANCE() viene utilizzata per trovare la varianza di un determinato valore all’interno della partizione. Nelle statistiche, la varianza rappresenta quanto un numero si discosta dal suo valore medio, o rappresenta il grado di dispersione tra i numeri. È rappresentata da ?^2.
La funzione STDDEV() viene utilizzata per trovare la deviazione standard di un determinato valore all’interno della partizione. La deviazione standard misura anche la variazione dei dati ed è uguale alla radice quadrata della varianza. È rappresentata da ?.
Questi parametri possono aiutarci a trovare dispersione e variabilità nei dati. Vediamo come possiamo farlo praticamente.
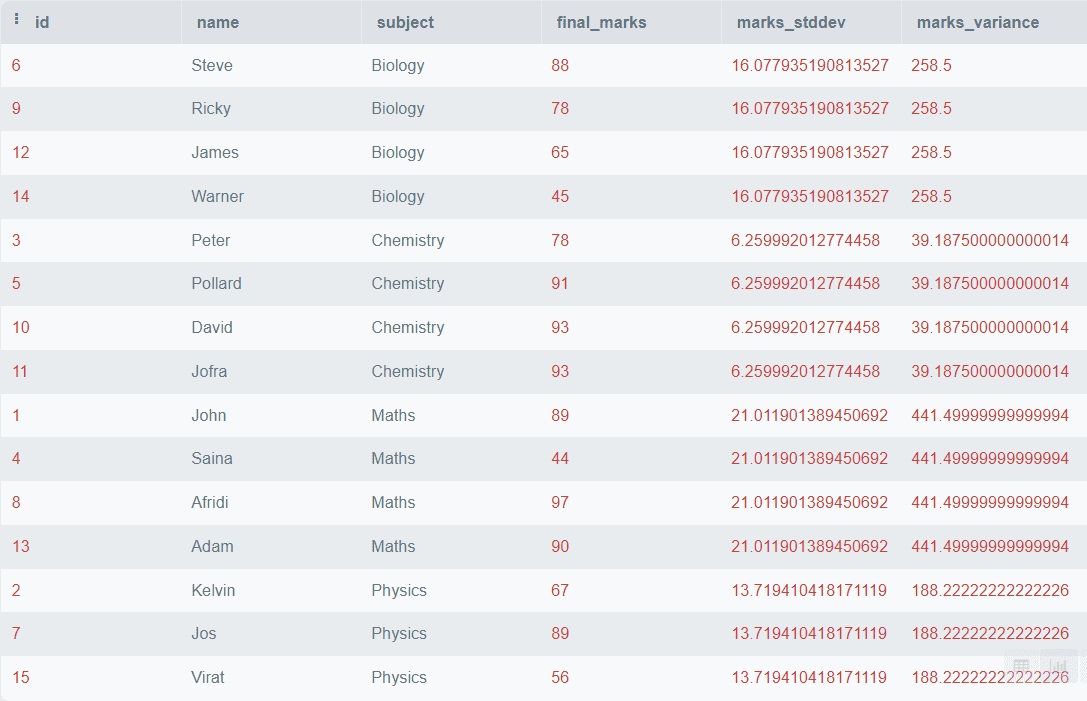
SELECT *,
STDDEV(final_marks)
OVER (
PARTITION BY subject) AS marks_stddev,
VARIANCE(final_marks)
OVER (
PARTITION BY subject) AS marks_variance
FROM students; Output: 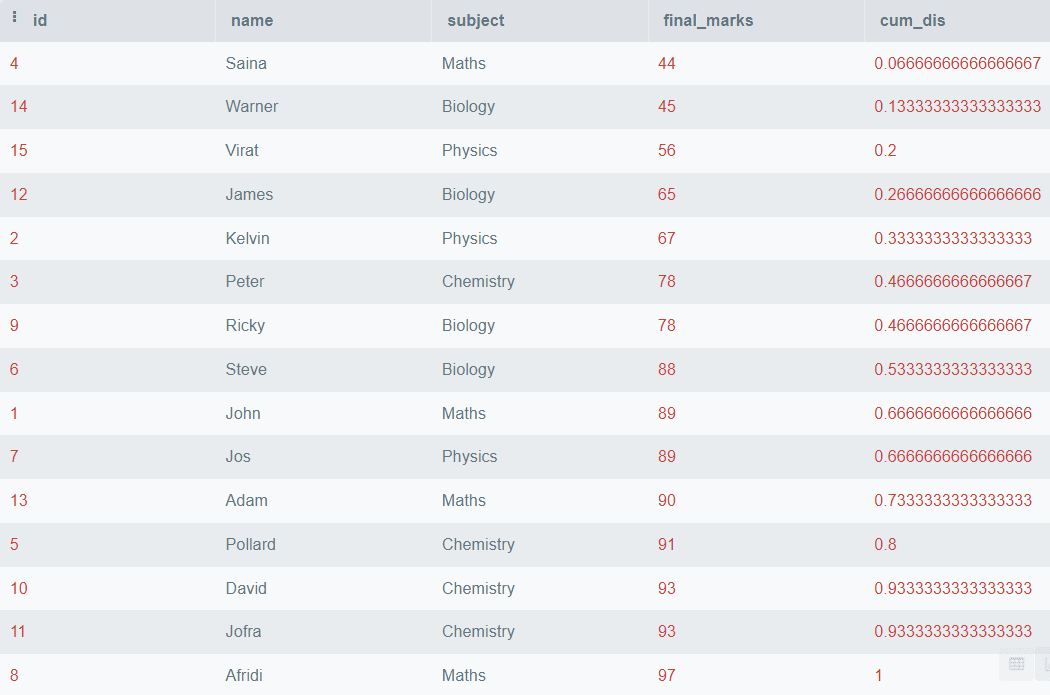 L’output precedente mostra la deviazione standard e la varianza dei voti finali per ogni materia.
L’output precedente mostra la deviazione standard e la varianza dei voti finali per ogni materia.
FIRST_VALUE() e LAST_VALUE()
La funzione FIRST_VALUE() restituirà il primo valore di una partizione in base a un ordinamento specifico. Allo stesso modo, la funzione LAST_VALUE() restituirà l’ultimo valore di quella partizione. Queste funzioni possono essere utilizzate quando si desidera identificare la prima e l’ultima occorrenza di una partizione specificata.
Sintassi:
SELECT *,
FIRST_VALUE(col1)
OVER (
PARTITION BY col2, col3
ORDER BY col4) AS first_value
FROM table_nameConclusion
Le funzioni analitiche SQL ci forniscono le funzioni per eseguire l’analisi dei dati all’interno del server SQL. Utilizzando queste funzioni, possiamo sbloccare il vero potenziale dei dati e ottenere informazioni preziose per aumentare la nostra attività. Oltre alle funzioni discusse in precedenza, ci sono molte altre funzioni eccellenti che possono risolvere i tuoi problemi complessi molto rapidamente. Puoi leggere di più su queste funzioni analitiche da questo articolo di Microsoft. Aryan Garg è uno studente di Ingegneria Elettrica, attualmente all’ultimo anno del suo corso di laurea. Il suo interesse si concentra nel campo dello sviluppo web e dell’apprendimento automatico. Ha coltivato questo interesse ed è desideroso di lavorare di più in queste direzioni.



