Come costruire una piattaforma di analisi semi-strutturata in streaming su Snowflake
'Building a semi-structured streaming analytics platform on Snowflake'
Costruire un datalake per dati semi-strutturati o json è sempre stato una sfida. Immagina se i documenti json sono in streaming o fluiscono continuamente dai fornitori di assistenza sanitaria, allora abbiamo bisogno di un’architettura moderna e robusta che possa gestire un volume così elevato. Allo stesso tempo, anche il livello di analisi deve essere…

Introduzione
Snowflake è un SaaS, ovvero un software come servizio, che si adatta perfettamente all’esecuzione di analisi su grandi volumi di dati. La piattaforma è estremamente facile da usare ed è adatta per utenti aziendali, team di analisi, ecc., per ottenere valore dai dataset in continuo aumento. Questo articolo illustrerà i componenti per la creazione di una piattaforma di analisi semistrutturata in streaming su Snowflake per i dati sanitari. Analizzeremo anche alcune considerazioni chiave durante questa fase.
Contesto
Esistono molti formati di dati diversi supportati dall’intero settore sanitario, ma considereremo uno dei formati semistrutturati più recenti, ovvero FHIR (Fast Healthcare Interoperability Resources), per la costruzione della nostra piattaforma di analisi. Questo formato di solito contiene tutte le informazioni centrate sul paziente incorporate in un unico documento JSON. Questo formato contiene una moltitudine di informazioni, come tutti gli incontri ospedalieri, i risultati dei test di laboratorio, ecc. Il team di analisi, quando fornito di un data lake interrogabile, può estrarre informazioni preziose come ad esempio quanti pazienti sono stati diagnosticati con il cancro, ecc. Facciamo l’assunzione che tutti questi file JSON vengano caricati su AWS S3 (o qualsiasi altro storage cloud pubblico) ogni 15 minuti attraverso diversi servizi AWS o endpoint API finali.
- Conquistare i tentativi in Python utilizzando Tenacity un tutorial completo
- La Data Science è una buona carriera?
- Come cambiare carriera da Data Analyst a Data Scientist?
Design architetturale
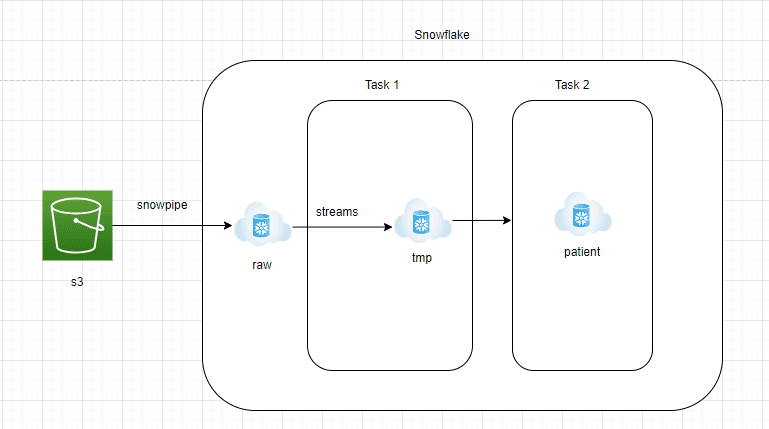
Componenti architetturali
AWS S3 a zona RAW di Snowflake:
- I dati devono essere continuamente trasmessi da AWS S3 nella zona RAW di Snowflake.
- Snowflake offre il servizio gestito Snowpipe, che può leggere file JSON da S3 in modo continuo e in streaming.
- Deve essere creata una tabella con una colonna di tipo “variant” nella zona RAW di Snowflake per contenere i dati JSON nel formato nativo.
Zona RAW di Snowflake a Streams:
- Streams è un servizio di change data capture gestito che sarà in grado di catturare tutti i nuovi documenti JSON in arrivo nella zona RAW di Snowflake
- Streams sarà puntato alla tabella della zona RAW di Snowflake e dovrebbe essere impostato su append=true
- Le Streams sono come qualsiasi altra tabella e facilmente interrogabili.
Snowflake Task 1:
- Task Snowflake è un oggetto simile a un pianificatore. Le query o le stored procedure possono essere programmate per essere eseguite utilizzando notazioni di cron job
- In questa architettura, creiamo il Task 1 per recuperare i dati dalle Streams e inserirli in una tabella di staging. Questo livello verrà troncato e ricaricato
- Ciò viene fatto per garantire che i nuovi documenti JSON vengano elaborati ogni 15 minuti
Snowflake Task 2:
- Questo livello convertirà il documento JSON grezzo in tabelle di report che il team di analisi può interrogare facilmente.
- Per convertire i documenti JSON in formato strutturato, è possibile utilizzare la funzionalità di flatten laterale di Snowflake.
- Il flatten laterale è una funzione facile da usare che espande gli elementi dell’array nidificato ed è possibile estrarli facilmente utilizzando la notazione ‘:’.
Considerazioni chiave
- Si consiglia di utilizzare Snowpipe con alcuni file di grandi dimensioni. I costi possono aumentare se i piccoli file su storage esterni non vengono raggruppati insieme
- In un ambiente di produzione, assicurarsi di creare processi automatizzati per monitorare le Streams in quanto, una volta diventate obsolete, non è possibile recuperare i dati da esse
- La dimensione massima consentita di un singolo documento JSON compresso che può essere caricato in Snowflake è di 16 MB. Se si dispone di documenti JSON molto grandi che superano questi limiti di dimensione, assicurarsi di avere un processo per suddividerli prima di caricarli in Snowflake
Conclusioni
Gestire dati semistrutturati è sempre una sfida a causa della struttura nidificata degli elementi incorporati nei documenti JSON. Prima di progettare il livello finale di reportistica, prendere in considerazione l’aumento graduale ed esponenziale del volume dei dati in ingresso. Questo articolo mira a dimostrare quanto sia facile costruire un flusso di dati in streaming con dati semistrutturati.
Milind Chaudhari è un data engineer/architetto dati esperto che ha un decennio di esperienza nel costruire data lake/lakehouse utilizzando una varietà di strumenti convenzionali e moderni. È estremamente appassionato dell’architettura di streaming dei dati ed è anche un revisore tecnico con Packt & O’Reilly.




