Costruire pipeline di Machine Learning pronte per il rilascio
'Build ready-to-deploy Machine Learning pipelines'
Sfrutta Kedro per creare pipeline di machine learning pronte per la produzione

Background — I notebook non sono “deployabili”
I primi incontri dei data scientist con il coding avvengono spesso tramite interfacce utente di tipo notebook. I notebook sono indispensabili per l’esplorazione, un aspetto critico del nostro flusso di lavoro. Tuttavia, non sono progettati per essere pronti per la produzione. Questo è un problema chiave che ho riscontrato in numerosi clienti, alcuni dei quali chiedono come rendere pronti per la produzione i loro notebook. Invece di rendere pronti per la produzione i tuoi notebook, il percorso ottimale per la preparazione alla produzione è creare codice modulare, mantenibile e riproducibile.
In questo articolo, presento un esempio di una pipeline di ML modulare per l’addestramento di un modello per classificare le transazioni fraudolente con carte di credito. Alla fine di questo articolo, spero che tu:
- Acquisti una comprensione e un’apprezzamento delle pipeline di ML modulari.
- Ti senta ispirato a crearne una per te stesso.
Se desideri sfruttare i vantaggi del deployment dei tuoi modelli di machine learning per massimizzare l’effetto, scrivere codice modulare è un passo importante da compiere.
Prima una breve definizione di codice modulare. Il codice modulare è un paradigma di progettazione del software che enfatizza la separazione di un programma in moduli indipendenti e interscambiabili. Dovremmo cercare di raggiungere questo stato con le nostre pipeline di machine learning.
- Due Tecniche Avanzate di SQL Che Possono Migliorare Drasticamente le Tue Query
- Come diventare un data scientist senza una formazione tecnica consigli e strategie
- L’Assistente di Visualizzazione Definitivo
Breve deviazione — Il progetto, i dati e l’approccio
Il progetto di machine learning proviene da Kaggle. Il dataset consiste in 284.807 transazioni con carte di credito anonimizzate, di cui 492 sono fraudolente. Il compito è costruire un classificatore per rilevare le transazioni fraudolente.
I dati per questo progetto sono licenziati per qualsiasi scopo, inclusi l’uso commerciale, sotto Open Data Commons.
Ho utilizzato un approccio di deep learning sfruttando Ludwig, un framework open-source per il deep learning dichiarativo. Non entrerò nei dettagli di Ludwig qui, ma ho precedentemente scritto un articolo sul framework.
La rete neurale profonda di Ludwig è configurata con un file .yaml. Per coloro che sono curiosi, è possibile trovarlo nel repository di modelli su GitHub.
Costruire pipeline modulari con Kedro
La creazione di pipeline modulari di machine learning è stata resa più facile grazie a strumenti open-source, il mio preferito di questi è Kedro. Non solo perché ho visto che è stato utilizzato con successo nell’industria, ma anche perché mi ha aiutato a sviluppare le mie competenze di ingegneria del software.
Kedro è un framework open-source (licenziato con Apache 2.0) per la creazione di codice di data science riproducibile, mantenibile e modulare. L’ho scoperto mentre stavo sviluppando la strategia di intelligenza artificiale per una banca, considerando quali strumenti il mio team potesse utilizzare per creare codice pronto per la produzione.
Avviso: non ho alcuna affiliazione con Kedro o McKinsey’s QuantumBlack, i creatori di questo strumento open-source.
La pipeline di addestramento del modello
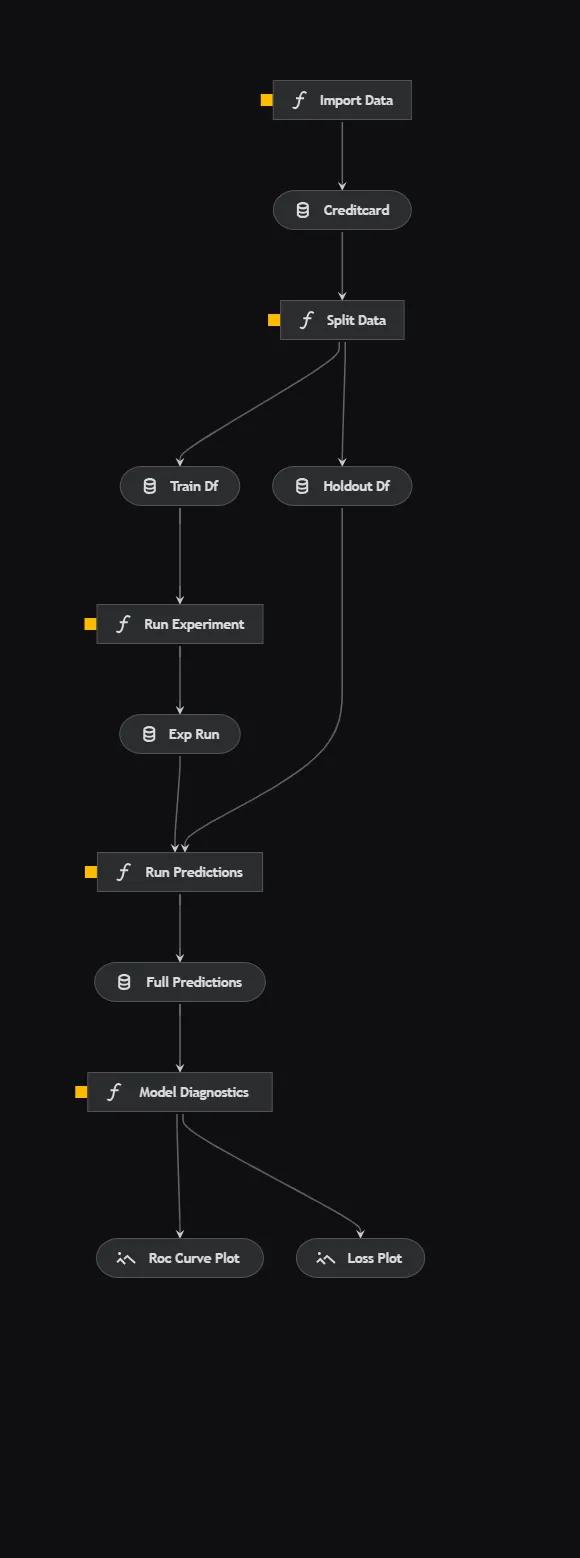
Kedro permette comodamente di visualizzare le pipeline, una caratteristica fantastica che può aiutare a rendere il codice più chiaro. La pipeline è standard per il machine learning, quindi affronterò brevemente ogni aspetto.
- Importa i dati: Importa i dati delle transazioni con carte di credito da una fonte esterna.
- Dividi i dati: Utilizza una divisione casuale per separare i dati in set di addestramento e di validazione.
- Esegui l’esperimento: Utilizza il framework Ludwig per addestrare una rete neurale profonda sul set di dati di addestramento. L’API di esperimento di Ludwig salva comodamente gli artefatti del modello per ogni esecuzione dell’esperimento.
- Esegui le previsioni: Utilizza il modello addestrato nel passaggio precedente per eseguire previsioni sul set di dati di validazione.
- Diagnostica del modello: Produce due grafici diagnostici. Primo, il tracciamento della perdita di entropia incrociata per ogni epoca. Secondo, la curva ROC che misura le prestazioni del modello sul set di dati di validazione.
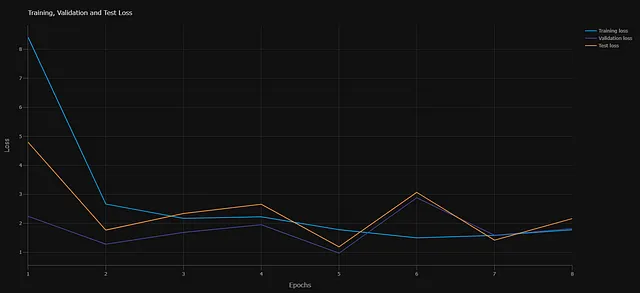
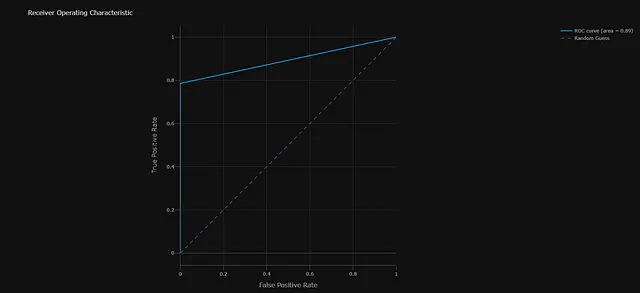
Componenti principali del pipeline
Ora che abbiamo stabilito una visione generale, entriamo nel dettaglio di alcune delle componenti principali di questo pipeline.
Struttura del progetto
C:.├───conf│ ├───base│ │ └───parameters│ └───local├───data│ ├───01_raw│ ├───02_intermediate│ ├───03_primary│ ├───04_feature│ ├───05_model_input│ ├───06_models│ │ ├───experiment_run│ │ │ └───model│ │ │ ├───logs│ │ │ │ ├───test│ │ │ │ ├───training│ │ │ │ └───validation│ │ │ └───training_checkpoints│ │ └───experiment_run_0│ │ └───model│ │ ├───logs│ │ │ ├───test│ │ │ ├───training│ │ │ └───validation│ │ └───training_checkpoints│ ├───07_model_output│ └───08_reporting├───docs│ └───source│ └───src ├───fraud_detection_model │ ├───pipelines │ ├───train_model └───tests └───pipelinesKedro fornisce una struttura di directory basata su template che viene stabilita quando si avvia un progetto. Da questa base, è possibile aggiungere in modo programmato ulteriori pipeline alla struttura delle directory. Questa struttura standardizzata garantisce che ogni progetto di machine learning sia identico ed è facile da documentare, facilitando così la manutenzione.
Gestione dei dati
I dati svolgono un ruolo cruciale nell’apprendimento automatico. La capacità di tracciare i dati diventa ancora più essenziale quando si utilizzano modelli di apprendimento automatico in un contesto commerciale. Spesso ci si trova di fronte ad audit o alla necessità di produrre o riprodurre il proprio pipeline su un’altra macchina.
Kedro offre due metodi per applicare le migliori pratiche nella gestione dei dati. Il primo è una struttura di directory progettata per carichi di lavoro di apprendimento automatico, che fornisce posizioni distinte per le tabelle intermedie prodotte durante la trasformazione dei dati e gli artefatti del modello. Il secondo metodo è il catalogo dei dati . Come parte del flusso di lavoro di Kedro, è necessario registrare i dataset all’interno di un file di configurazione .yaml, consentendo così di sfruttare questi dataset nelle pipeline. Questo approccio potrebbe sembrare inizialmente insolito, ma consente a te e agli altri che lavorano sul tuo pipeline di tracciare facilmente i dati.
Orchestrazione – Nodi e pipeline
Qui è dove accade la magia. Kedro ti fornisce direttamente la funzionalità delle pipeline.
Il blocco di costruzione iniziale della tua pipeline sono i nodi . Ogni pezzo eseguibile di codice può essere incapsulato in un nodo, che è semplicemente una funzione Python che accetta un input e restituisce un output. Puoi quindi strutturare una pipeline come una serie di nodi. Le pipeline sono facilmente costruite invocando il nodo e specificando gli input e gli output. Kedro determina l’ordine di esecuzione.
Una volta che le pipeline sono costruite, vengono registrate nel file pipeline_registry.py fornito. La bellezza di questo approccio è che puoi creare più pipeline. Questo è particolarmente vantaggioso nell’apprendimento automatico, dove potresti avere una pipeline di elaborazione dei dati, una pipeline di addestramento del modello, una pipeline di inferenza e così via.
Dopo la configurazione, è abbastanza semplice modificare gli aspetti della tua pipeline.
Snippet di codice che mostra un esempio di script nodes.py
Snippet di codice che mostra un esempio di script Pipeline
Configurazione
Le migliori pratiche di Kedro stabiliscono che tutte le configurazioni devono essere gestite tramite il file parameters.yml fornito. Da una prospettiva di apprendimento automatico, gli iperparametri rientrano in questa categoria. Questo approccio semplifica gli esperimenti, in quanto è possibile semplicemente sostituire un file parameters.yml con un set di iperparametri con un altro, il che è anche molto più facile da tracciare.
Ho incluso anche le posizioni del mio modello di rete neurale profonda Ludwig model.yaml e della fonte di dati all’interno della configurazione parameters.yml. Se il modello o la posizione dei dati cambiano – ad esempio, durante il passaggio tra le macchine degli sviluppatori – sarebbe estremamente semplice regolare queste impostazioni.
Snippet di codice che mostra il contenuto del file parameters.yml
Riproducibilità
Kedro include un file requirements.txt come parte della struttura predefinita. Questo rende molto semplice monitorare l’ambiente e le versioni esatte delle librerie. Tuttavia, se preferisci, puoi utilizzare altri metodi di gestione dell’ambiente, come un file environment.yml.
Creazione di un flusso di lavoro
Se stai sviluppando pipeline di apprendimento automatico e stai considerando l’utilizzo di Kedro, potrebbe inizialmente presentare una curva di apprendimento ripida, ma l’adozione di un flusso di lavoro standard semplificherà il processo. Ecco il mio flusso di lavoro suggerito:
- Stabilisci il tuo ambiente di lavoro: Preferisco utilizzare Anaconda per questa attività. Di solito utilizzo un file environment.yml, contenente tutte le dipendenze necessarie per il mio ambiente, e utilizzo la riga di comando di Anaconda Powershell per creare il mio ambiente da questo.
- Crea un progetto Kedro: Una volta installato Kedro, che dovrebbe essere dichiarato nel tuo environment.yml, puoi creare un progetto Kedro tramite l’interfaccia della riga di comando di Anaconda.
- Esplora in Jupyter Notebooks: Costruisco una pipeline iniziale in Jupyter notebooks, un processo familiare alla maggior parte degli scienziati dei dati. L’unica differenza è che, una volta costruita la tua pipeline, dovresti sistemarla in modo che ogni cella possa fungere da un nodo nella tua pipeline Kedro.
- Registra i tuoi dati: Registra gli input e gli output per ciascun passaggio di elaborazione dati o di ingestione dati nel catalogo dei dati.
- Aggiungi la tua pipeline: Dopo aver condotto l’esplorazione nei notebook, vorrai creare una pipeline. Questo viene fatto tramite l’interfaccia della riga di comando. Eseguendo questo comando verrà aggiunta una cartella aggiuntiva a ‘pipelines’, con il nome della pipeline appena creata. È all’interno di questa cartella che costruirai i tuoi nodi e le tue pipeline.
- Definisci la tua pipeline: Questa è la fase in cui inizi a trasferire il codice dai tuoi Jupyter notebooks nel file node.py nella cartella della tua pipeline, assicurandoti che i nodi che intendi far parte di una pipeline abbiano input e output. Una volta configurati i nodi, procedi a definire la tua pipeline nel file pipeline.py.
- Registra le tue pipeline: Il file pipeline_registry.py offre un modello per registrare la pipeline appena creata.
- Esegui il tuo progetto: Una volta stabilito, puoi eseguire qualsiasi pipeline tramite l’interfaccia della riga di comando e visualizzare anche il tuo progetto.
Le pipeline pronte per la produzione si integrano in un ecosistema più ampio di operazioni di apprendimento automatico. Leggi il mio articolo su MLOps per approfondimenti.
Creazione di operazioni di apprendimento automatico per le aziende
Una strategia MLOps efficace per supportare la tua strategia di intelligenza artificiale
towardsdatascience.com
Conclusioni
Kedro è un ottimo framework per fornire pipeline di apprendimento automatico pronte per la produzione. Oltre alle funzionalità discusse in questo articolo, ci sono numerose integrazioni con altre librerie open source, nonché pacchetti per la documentazione e il testing. Kedro non risolve tutti i problemi legati al rilascio del modello – ad esempio, la versione del modello è probabilmente gestita meglio da un altro strumento come DVC. Tuttavia, aiuterà gli scienziati dei dati in un contesto commerciale a produrre codice più manutenibile, modulare e riproducibile pronto per la produzione. C’è una curva di apprendimento relativamente ripida per i principianti assoluti, ma la documentazione è chiara e include tutorial guidati. Come con qualsiasi di questi pacchetti, il modo migliore per imparare è tuffarsi e sperimentare.
Link al repository completo su GitHub
Seguimi su LinkedIn
Iscriviti a Nisoo per ottenere ulteriori approfondimenti da parte mia:
Unisciti a Nisoo tramite il mio link di riferimento – John Adeojo
Condivido progetti, esperienze ed esperienze di data science per aiutarti nel tuo percorso. Puoi iscriverti a Nisoo tramite…
johnadeojo.medium.com
Se sei interessato a integrare l’IA o la data science nelle tue operazioni aziendali, ti invitiamo a pianificare una consulenza iniziale gratuita con noi:
Prenota online | Soluzioni centrate sui dati
Scopri la nostra esperienza nell’aiutare le aziende a raggiungere obiettivi ambiziosi con una consulenza gratuita. I nostri scienziati dei dati e…
www.data-centric-solutions.com