Due Tecniche Avanzate di SQL Che Possono Migliorare Drasticamente le Tue Query
Two Advanced SQL Techniques That Can Drastically Improve Your Queries.
Scopri le Common Table Expression (CTE) e le Window Functions
SQL è il pane quotidiano di ogni professionista dei dati. Non importa se sei un analista dei dati, un data scientist o un data engineer, devi avere una solida comprensione di come scrivere query SQL pulite ed efficienti.
Questo perché dietro ad ogni analisi rigorosa dei dati o ad ogni modello di machine learning sofisticato si trova il dato sottostante stesso, e questo dato deve provenire da qualche parte.
Spero che dopo aver letto il mio post introduttivo su SQL, tu abbia già imparato che SQL sta per Structured Query Language ed è un linguaggio utilizzato per recuperare dati da un database relazionale.
In quel post, abbiamo esaminato alcuni comandi SQL fondamentali come SELECT, FROM e WHERE, che dovrebbero coprire la maggior parte delle query di base che incontrerai quando utilizzi SQL.
- Come diventare un data scientist senza una formazione tecnica consigli e strategie
- L’Assistente di Visualizzazione Definitivo
- Allenamento dei modelli di linguaggio con dati sintetici di qualità da libro di testo
Ma cosa succede se quei comandi semplici non sono sufficienti? Cosa succede se i dati che desideri richiedono un approccio più robusto alla query?
Beh, non cercare oltre perché oggi, esamineremo due nuove tecniche SQL che puoi aggiungere al tuo toolkit e che porteranno le tue query al livello successivo. Queste tecniche si chiamano Common Table Expression (CTE) e Window Functions.
Per aiutarci a imparare queste tecniche, utilizzeremo un editor SQL online chiamato DB Fiddle (impostato su SQLite v3.39) e il dataset sulla durata dei viaggi in taxi proveniente da Google Cloud (licenza NYC Open Data).
Preparazione dei dati
Se non sei interessato a conoscere come ho preparato il dataset, puoi saltare questa sezione e incollare il seguente codice su DB Fiddle per generare lo schema.
CREATE TABLE taxi ( id varchar, vendor_id integer, pickup_datetime datetime, dropoff_datetime datetime, trip_seconds integer, distance float);INSERT INTO taxi VALUES('id2875421', 2, '2016-03-14 17:24:55', '2016-03-14 17:32:30', 455, 0.93), ('id2377394', 1, '2016-06-12 00:43:35', '2016-06-12 00:54:38', 663, 1.12), ('id3858529', 2, '2016-01-19 11:35:24', '2016-01-19 12:10:48', 2124, 3.97), ('id3504673', 2, '2016-04-06 19:32:31', '2016-04-06 19:39:40', 429, 0.92), ('id2181028', 2, '2016-03-26 13:30:55', '2016-03-26 13:38:10', 435, 0.74), ('id0801584', 2, '2016-01-30 22:01:40', '2016-01-30 22:09:03', 443, 0.68), ('id1813257', 1, '2016-06-17 22:34:59', '2016-06-17 22:40:40', 341, 0.82), ('id1324603', 2, '2016-05-21 07:54:58', '2016-05-21 08:20:49', 1551, 3.55), ('id1301050', 1, '2016-05-27 23:12:23', '2016-05-27 23:16:38', 255, 0.82), ('id0012891', 2, '2016-03-10 21:45:01', '2016-03-10 22:05:26', 1225, 3.19), ('id1436371', 2, '2016-05-10 22:08:41', '2016-05-10 22:29:55', 1274, 2.37), ('id1299289', 2, '2016-05-15 11:16:11', '2016-05-15 11:34:59', 1128, 2.35), ('id1187965', 2, '2016-02-19 09:52:46', '2016-02-19 10:11:20', 1114, 1.16), ('id0799785', 2, '2016-06-01 20:58:29', '2016-06-01 21:02:49', 260, 0.62), ('id2900608', 2, '2016-05-27 00:43:36', '2016-05-27 01:07:10', 1414, 3.97), ('id3319787', 1, '2016-05-16 15:29:02', '2016-05-16 15:32:33', 211, 0.41), ('id3379579', 2, '2016-04-11 17:29:50', '2016-04-11 18:08:26', 2316, 2.13), ('id1154431', 1, '2016-04-14 08:48:26', '2016-04-14 09:00:37', 731, 1.58), ('id3552682', 1, '2016-06-27 09:55:13', '2016-06-27 10:17:10', 1317, 2.86), ('id3390316', 2, '2016-06-05 13:47:23', '2016-06-05 13:51:34', 251, 0.81), ('id2070428', 1, '2016-02-28 02:23:02', '2016-02-28 02:31:08', 486, 1.56), ('id0809232', 2, '2016-04-01 12:12:25', '2016-04-01 12:23:17', 652, 1.07), ('id2352683', 1, '2016-04-09 03:34:27', '2016-04-09 03:41:30', 423, 1.29), ('id1603037', 1, '2016-06-25 10:36:26', '2016-06-25 10:55:49', 1163, 3.03), ('id3321406', 2, '2016-06-03 08:15:05', '2016-06-03 08:56:30', 2485, 12.82), ('id0129640', 2, '2016-02-14 13:27:56', '2016-02-14 13:49:19', 1283, 2.84), ('id3587298', 1, '2016-02-27 21:56:01', '2016-02-27 22:14:51', 1130, 3.77), ('id2104175', 1, '2016-06-20 23:07:16', '2016-06-20 23:18:50', 694, 2.33), ('id3973319', 2, '2016-06-13 21:57:27', '2016-06-13 22:12:19', 892, 1.57), ('id1410897', 1, '2016-03-23 14:10:39', '2016-03-23 14:49:30', 2331, 6.18);Dopo aver eseguito SELECT * from taxi, dovresti ottenere una tabella risultante che appare come questa.
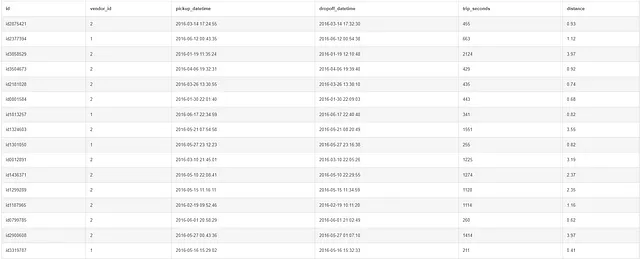
Per chi è curioso di sapere come è stata creata questa tabella, ho filtrato i dati di addestramento alle prime 30 righe e ho mantenuto solo le colonne che vedete sopra. Per quanto riguarda il campo della distanza, ho calcolato la distanza ortodromica tra le coordinate di prelievo e rilascio (latitudine e longitudine).
La distanza ortodromica è la distanza più breve tra due punti su una sfera, quindi in realtà si tratta di una sottostima della distanza reale percorsa dal taxi. Tuttavia, per lo scopo di ciò che stiamo facendo oggi, possiamo ignorarlo per ora.
La formula per calcolare la distanza ortodromica può essere trovata qui. Ora, torniamo a SQL.
Espressione di tabella comune (CTE)
Un’espressione di tabella comune (CTE) è una tabella temporanea restituita all’interno di una query. Puoi pensarla come una query all’interno di una query. Aiuta non solo a suddividere le tue query in blocchi più leggibili, ma puoi scrivere nuove query basate su una CTE che è stata definita.
Per dimostrarlo, supponiamo che vogliamo analizzare i viaggi in taxi suddivisi per ora del giorno e filtrare i viaggi che hanno avuto luogo tra i mesi di gennaio e marzo 2016.
SELECT CAST(STRFTIME('%H', pickup_datetime) AS INT) AS hour_of_day, trip_seconds, distanceFROM taxiWHERE pickup_datetime > '2016-01-01' AND pickup_datetime < '2016-04-01'ORDER BY hour_of_day;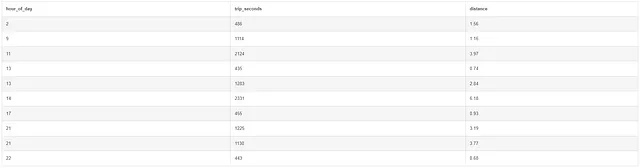
Abbastanza semplice; portiamo questo un passo avanti.
Supponiamo ora vogliamo calcolare il numero di viaggi e la velocità media per ciascuna di queste ore. Qui possiamo utilizzare una CTE per ottenere prima una tabella temporanea come quella osservata sopra, seguita da una query successiva per contare il numero di viaggi e calcolare la velocità media raggruppata per ora del giorno.
La CTE viene definita utilizzando le istruzioni WITH e AS.
WITH relevantrides AS(SELECT CAST(STRFTIME('%H', pickup_datetime) AS INT) AS hour_of_day, trip_seconds, distanceFROM taxiWHERE pickup_datetime > '2016-01-01' AND pickup_datetime < '2016-04-01'ORDER BY hour_of_day)SELECT hour_of_day, COUNT(1) as num_trips, ROUND(3600 * SUM(distance) / SUM(trip_seconds), 2) as avg_speedFROM relevantridesGROUP BY hour_of_dayORDER BY hour_of_day;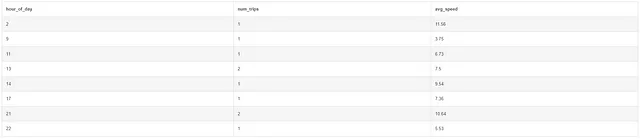
Un’alternativa all’utilizzo di una CTE è semplicemente racchiudere la tabella temporanea all’interno di una dichiarazione FROM (vedi codice di seguito), che ti darebbe lo stesso risultato. Tuttavia, ciò non è consigliabile dal punto di vista della leggibilità del codice. Inoltre, immagina se volessimo creare più di una sola tabella temporanea.
SELECT hour_of_day, COUNT(1) as num_trips, ROUND(3600 * SUM(distance) / SUM(trip_seconds), 2) as avg_speedFROM ( SELECT CAST(STRFTIME('%H', pickup_datetime) AS INT) AS hour_of_day, trip_seconds, distance FROM taxi WHERE pickup_datetime > '2016-01-01' AND pickup_datetime < '2016-04-01' ORDER BY hour_of_day)GROUP BY hour_of_dayORDER BY hour_of_day;Bonus: un’interessante intuizione che possiamo ottenere da questo esercizio è che i taxi tendono a muoversi più lentamente (velocità media più bassa) durante le ore di punta, molto probabilmente a causa del traffico più intenso mentre le persone si spostano da e verso il lavoro.
Funzioni di finestra
Le funzioni di finestra eseguono operazioni di aggregazione su gruppi di righe, ma producono un risultato per ogni riga nella tabella originale.
Per comprendere appieno come funzionano le funzioni di finestra, è utile fare un breve ripasso dell’aggregazione tramite GROUP BY.
Supponiamo di voler calcolare una lista di statistiche riassuntive per mese utilizzando il dataset dei taxi.
SELECT CAST(STRFTIME('%m', pickup_datetime) AS INT) AS mese, COUNT(1) AS conteggio_viaggi, ROUND(SUM(distanza), 3) AS distanza_totale, ROUND(AVG(distanza), 3) AS distanza_media, MIN(distanza) AS distanza_minima, MAX(distanza) AS distanza_massimaFROM taxiGROUP BY mese;
Nell’esempio sopra, abbiamo calcolato il conteggio, la somma, la media, la distanza minima e la distanza massima per ogni singolo mese nel dataset. Nota come la nostra tabella taxi originale con 30 righe sia stata ridotta a sei righe, una per ogni mese individuale.
Quindi, cosa succede effettivamente dietro le quinte? In primo luogo, SQL ha raggruppato tutte le 30 righe nella tabella originale in base ai loro mesi. Ha quindi applicato i calcoli pertinenti in base ai valori di questi singoli gruppi.
Prendiamo ad esempio il mese di gennaio. Ci sono due viaggi nel dataset che si sono svolti nel mese di gennaio, con una distanza percorsa rispettivamente di 3,97 e 0,68. SQL ha quindi calcolato il conteggio, la somma, la media, la distanza minima e la distanza massima basandosi su questi due valori. Il processo si ripete quindi per gli altri mesi fino a quando alla fine otteniamo un output simile a quello sopra.
Ora, tieni presente questo concetto mentre iniziamo a esplorare come funzionano le funzioni di finestra. Ci sono tre ampie categorie di funzioni di finestra: funzioni di aggregazione, funzioni di classifica e funzioni di navigazione. Vedremo degli esempi di ognuna di esse.
Funzioni di aggregazione
Abbiamo già visto le funzioni di aggregazione in azione nel nostro esempio precedente. Le funzioni di aggregazione includono funzioni come count, sum, average, minimum e maximum.
Ma dove le funzioni di finestra differiscono da GROUP BY è il numero di righe nell’output finale. In particolare, abbiamo visto che dopo l’aggregazione per mesi, la nostra tabella di output è rimasta con solo sei righe (una riga per ogni mese distinto).
Le funzioni di finestra, d’altra parte, non riassumeranno la tabella per il campo di aggregazione, ma semplicemente restituiranno il risultato in una nuova colonna per ogni riga. Il numero di righe nella tabella di output non cambierà. In altre parole, la tabella di output avrà sempre lo stesso numero di righe della tabella originale.
La sintassi per eseguire una funzione di finestra è OVER(PARTITION BY ...). Puoi pensare a questo come alla dichiarazione GROUP BY nel nostro esempio precedente.
Vediamo come funziona nella pratica.
WITH aggregate AS(SELECT id, pickup_datetime, CAST(STRFTIME('%m', pickup_datetime) AS INT) AS mese, distanzaFROM taxi)SELECT *, COUNT(1) OVER(PARTITION BY mese) AS conteggio_viaggi, ROUND(SUM(distanza) OVER(PARTITION BY mese), 3) AS distanza_mese_totale, ROUND(AVG(distanza) OVER(PARTITION BY mese), 3) AS distanza_mese_media, MIN(distanza) OVER(PARTITION BY mese) AS distanza_mese_minima, MAX(distanza) OVER(PARTITION BY mese) AS distanza_mese_massimaFROM aggregate;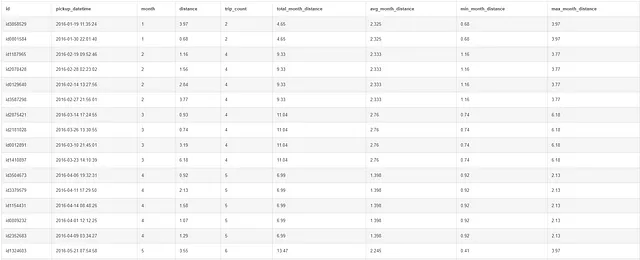
Qui, vogliamo lo stesso output dell’ultima volta, ma anziché ridurre la tabella, vogliamo che l’output venga visualizzato come righe individuali in una nuova colonna.
Noterai che i valori dopo l’aggregazione non sono cambiati, ma sono semplicemente visualizzati come righe ripetute nella tabella. Ad esempio, le prime due righe (gennaio) hanno gli stessi valori per il conteggio dei viaggi, la distanza totale del mese, la distanza media del mese, la distanza minima del mese e la distanza massima del mese come prima. Lo stesso vale per gli altri mesi.
Nel caso in cui ti stessi chiedendo come le funzioni di finestra siano utili, ci aiutano a confrontare il valore di ogni riga con il valore aggregato. In questo caso, possiamo facilmente confrontare la distanza percorsa in ogni riga con la media mensile, il minimo, il massimo, e così via.
Funzioni di classifica
Un altro tipo di funzione di finestra è la funzione di classifica. Come suggerisce il nome, questa classifica un gruppo di righe in base a un campo aggregato.
CON classifica AS(SELECT id, pickup_datetime, CAST(STRFTIME('%m', pickup_datetime) AS INT) AS mese, distanzaFROM taxi)SELECT *, RANK() OVER(ORDER BY distanza DESC) AS classifica_complessiva, RANK() OVER(PARTITION BY mese ORDER BY distanza DESC) AS classifica_meseFROM classificaORDER BY pickup_datetime;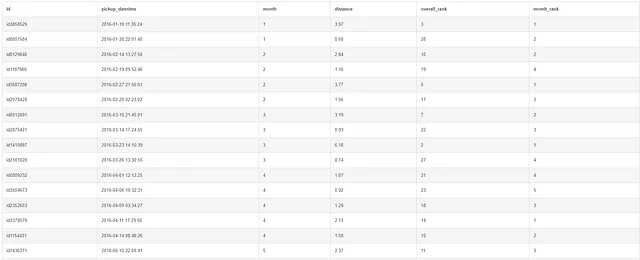
Nell’esempio precedente, abbiamo due colonne di classifica: una per la classifica complessiva (da 1 a 30) e una per la classifica mensile, entrambe in ordine decrescente.
Per specificare l’ordine durante la classifica, dovrai utilizzare ORDER BY all’interno della dichiarazione OVER.
Il modo in cui interpreti i risultati per la prima riga è che ha la terza distanza più lunga percorsa nell’intero set di dati e la distanza più lunga percorsa per il mese di gennaio.
Funzioni di navigazione
Ultimo ma non meno importante, abbiamo le funzioni di navigazione.
Una funzione di navigazione assegna un valore basato sul valore di una riga diversa rispetto alla riga corrente. Alcune comuni funzioni di navigazione includono FIRST_VALUE, LAST_VALUE, LEAD e LAG.
SELECT id, pickup_datetime, distanza, LAG(distanza) OVER(ORDER BY pickup_datetime) AS distanza_precedente, LEAD(distanza) OVER(ORDER BY pickup_datetime) AS distanza_successivaFROM taxiORDER BY pickup_datetime;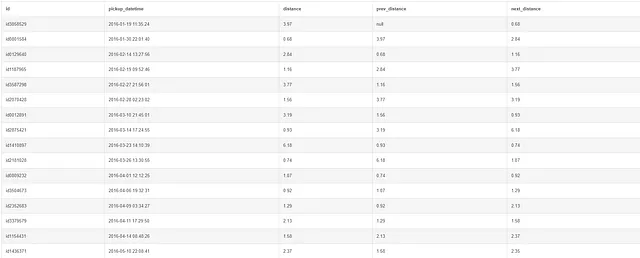

Nell’esempio precedente, abbiamo utilizzato la funzione LAG per restituire il valore della riga precedente e la funzione LEAD per restituire il valore della riga successiva. Nota come la prima riga della colonna di lag sia nulla, mentre l’ultima riga della colonna di lead sia nulla.
SELECT id, pickup_datetime, distanza, LAG(distanza, 2) OVER(ORDER BY pickup_datetime) AS distanza_precedente, LEAD(distanza, 2) OVER(ORDER BY pickup_datetime) AS distanza_successivaFROM taxiORDER BY pickup_datetime;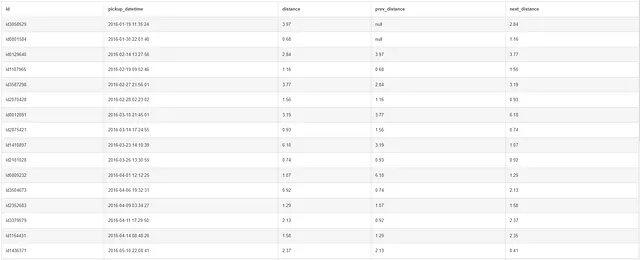
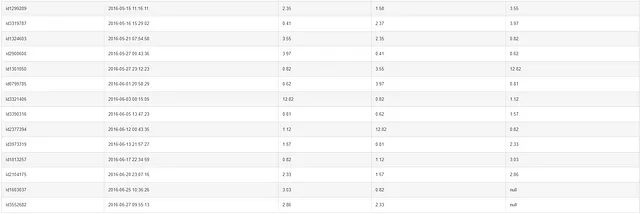
Su una nota simile, possiamo anche impostare l’offset delle funzioni LEAD e LAG, ovvero per iniziare da un particolare indice o posizione. Quando l’offset è impostato su due, puoi vedere che le prime due righe della colonna di lag sono nulle e le ultime due righe della colonna di lead sono nulle.
Spero che questo post del blog ti abbia aiutato a comprendere i concetti di Common Table Expression (CTE) e Window Functions.
Per riassumere, una CTE è una tabella temporanea o una query all’interno di una query. Sono utilizzate per dividere le query in blocchi più leggibili e puoi scrivere nuove query contro una CTE che è stata definita. Le window functions, d’altra parte, eseguono l’aggregazione su gruppi di righe e restituiscono i risultati per ogni riga nella tabella originale.
Se desideri migliorare queste tecniche, ti incoraggio vivamente a iniziarle nell’esecuzione delle tue query SQL, sia sul lavoro, risolvendo problemi di intervista o semplicemente giocando con dataset casuali. La pratica rende perfetti, giusto?
Sostenimi e gli altri scrittori straordinari iscrivendoti a una membership Nisoo utilizzando il link di seguito. Buono studio!
Iscriviti a Nisoo con il mio link di referenza – Jason Chong
Come membro di Nisoo, una parte della tua quota di iscrizione va agli scrittori che leggi, e ottieni pieno accesso a ogni storia…
chongjason.medium.com
Non sai cosa leggere dopo? Ecco alcune suggerimenti.
10 Comandi SQL più importanti che ogni analista dei dati deve conoscere
Estrarre dati da un database non deve essere complicato
towardsdatascience.com
Espressioni regolari chiaramente spiegate con esempi
Una delle competenze più sottovalutate che ogni analista dei dati dovrebbe avere quando lavora con le stringhe
towardsdatascience.com
Problemi comuni che possono fare o rompere il tuo progetto di Data Science
Una guida utile per individuare i problemi dei dati, perché possono essere dannosi e come affrontarli correttamente
towardsdatascience.com