Unificazione di dataset di immagini e didascalie con condizionamento del prefisso
Unificazione di dataset di immagini e didascalie con condizionamento del prefisso.
Pubblicato da Kuniaki Saito, Ricercatore Studente, Cloud AI Team, e Kihyuk Sohn, Ricercatore Scientista, Perception Team
Il pre-training dei modelli di visual language (VL) su dataset di immagini e didascalie su scala web è recentemente emerso come un’alternativa potente al pre-training tradizionale sui dati di classificazione delle immagini. I dataset di immagini e didascalie sono considerati più “open-domain” perché contengono tipi di scene più ampi e parole di vocabolario più ampie, il che porta a modelli con prestazioni elevate nelle attività di riconoscimento few- e zero-shot. Tuttavia, le immagini con descrizioni di classe dettagliate possono essere rare e la distribuzione delle classi può essere sbilanciata poiché i dataset di immagini e didascalie non vengono sottoposti a cura manuale. Al contrario, i dataset di classificazione su larga scala, come ImageNet, spesso vengono curati e possono quindi fornire categorie più dettagliate con una distribuzione di etichette bilanciata. Anche se sembra promettente, la combinazione diretta dei dataset di didascalie e classificazione per il pre-training spesso fallisce poiché può portare a rappresentazioni sbilanciate che non generalizzano bene a varie attività successive.
In “Prefix Conditioning Unifies Language and Label Supervision”, presentato a CVPR 2023, dimostriamo una strategia di pre-training che utilizza sia dataset di classificazione che didascalie per fornire benefici complementari. Innanzitutto, mostriamo che unificare in modo ingenuo i dataset porta a una performance sub-ottimale nelle attività di riconoscimento zero-shot successive poiché il modello è influenzato dal bias del dataset: la copertura dei domini delle immagini e delle parole del vocabolario è diversa in ogni dataset. Affrontiamo questo problema durante il training attraverso la prefix conditioning, un nuovo metodo semplice ed efficace che utilizza token di prefisso per separare i bias del dataset dai concetti visivi. Questo approccio consente all’encoder del linguaggio di apprendere da entrambi i dataset e di adattare l’estrazione delle caratteristiche a ciascun dataset. La prefix conditioning è un metodo generico che può essere facilmente integrato negli obiettivi di pre-training VL esistenti, come Contrastive Language-Image Pre-training (CLIP) o Unified Contrastive Learning (UniCL).
Idea di alto livello
Noto che i dataset di classificazione tendono ad essere sbilanciati in almeno due modi: (1) le immagini contengono principalmente oggetti singoli provenienti da domini ristretti e (2) il vocabolario è limitato e manca della flessibilità linguistica richiesta per l’apprendimento zero-shot. Ad esempio, l’embedding di classe di “una foto di un cane” ottimizzato per ImageNet di solito porta a una foto di un cane al centro dell’immagine estratta dal dataset ImageNet, il che non generalizza bene ad altri dataset contenenti immagini di cani multipli in diverse posizioni spaziali o un cane con altri soggetti.
- Eseguire attività Python Wheel in contenitori Docker personalizzati in Databricks
- Sfruttare i dati a griglia sulla precipitazione e il clima in Sud America
- L’alba dei Denoisers modelli di apprendimento automatico multi-output per l’imputazione dei dati tabulari
Al contrario, i dataset di didascalie contengono una maggiore varietà di tipi di scene e vocabolari. Come mostrato di seguito, se un modello impara semplicemente da due dataset, l’embedding di linguaggio può ingarbugliare il bias della classificazione delle immagini e del dataset di didascalie, il che può ridurre la generalizzazione nella classificazione zero-shot. Se riusciamo a separare il bias dai due dataset, possiamo utilizzare gli embedding di linguaggio adattati al dataset di didascalie per migliorare la generalizzazione.
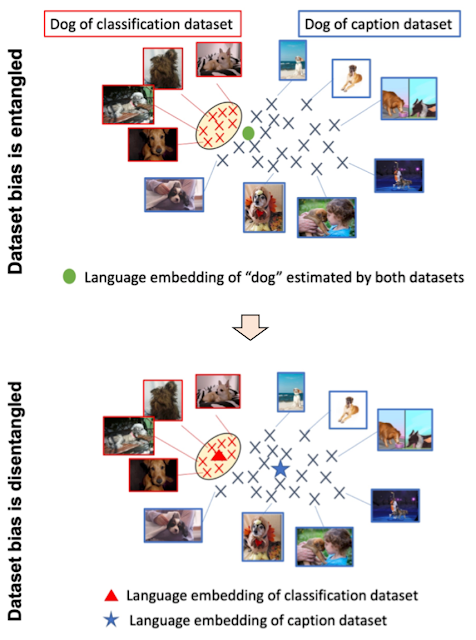 |
| In alto: L’embedding di linguaggio ingarbuglia il bias della classificazione delle immagini e del dataset di didascalie. In basso: Gli embedding di linguaggio separano il bias dai due dataset. |
Prefix conditioning
La prefix conditioning è parzialmente ispirata dal prompt tuning, che premette token apprendibili alle sequenze di token di input per istruire una struttura di modello pre-addestrato a imparare conoscenze specifiche del compito che possono essere utilizzate per risolvere compiti successivi. L’approccio della prefix conditioning si differenzia dal prompt tuning in due modi: (1) è progettato per unificare i dataset di immagini e didascalie separando il bias del dataset, e (2) viene applicato al pre-training VL mentre il prompt tuning standard viene utilizzato per il fine-tuning dei modelli. La prefix conditioning è un modo esplicito per guidare specificamente il comportamento delle strutture di modello in base al tipo di dataset forniti dagli utenti. Questo è particolarmente utile in produzione quando il numero di diversi tipi di dataset è noto in anticipo.
Durante l’addestramento, il conditioning del prefisso apprende un token di testo (token di prefisso) per ogni tipo di dataset, che assorbe il bias del dataset e consente agli altri token di testo di concentrarsi sull’apprendimento dei concetti visivi. In particolare, antepone i token di prefisso per ogni tipo di dataset ai token di input che informano il codificatore linguistico e visivo del tipo di dati di input (ad esempio, classificazione vs. didascalia). I token di prefisso vengono addestrati per apprendere il bias specifico del tipo di dataset, il che ci consente di svincolare quel bias nelle rappresentazioni linguistiche e utilizzare l’embedding appreso sul dataset immagine-didascalia durante il test, anche senza una didascalia di input.
Utilizziamo il conditioning del prefisso per CLIP utilizzando un codificatore linguistico e visivo. Durante il test, impieghiamo il prefisso utilizzato per il dataset immagine-didascalia poiché si suppone che il dataset copra tipi di scene più ampi e parole del vocabolario, portando a una migliore performance nel riconoscimento a zero-shot.
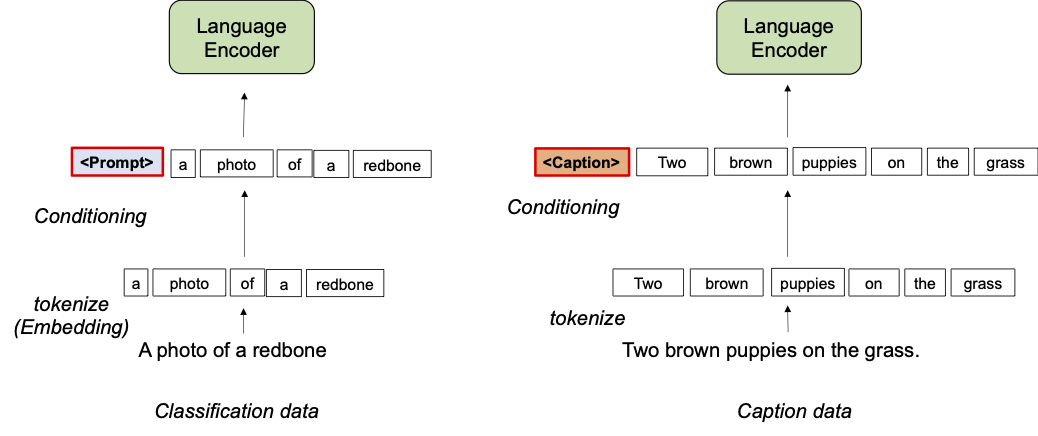 |
| Illustrazione del Conditioning del Prefisso. |
Risultati sperimentali
Applichiamo il conditioning del prefisso a due tipi di perdita contrastiva, CLIP e UniCL, e valutiamo le loro performance nei compiti di riconoscimento a zero-shot rispetto ai modelli addestrati con ImageNet21K (IN21K) e Conceptual 12M (CC12M). I modelli CLIP e UniCL addestrati con i due dataset utilizzando il conditioning del prefisso mostrano notevoli miglioramenti nell’accuratezza della classificazione a zero-shot.
 |
| Accuratezza della classificazione a zero-shot dei modelli addestrati solo con IN21K o CC12M rispetto ai modelli CLIP e UniCL addestrati con entrambi i dataset utilizzando il conditioning del prefisso (“Nostri”). |
Studio sul prefisso utilizzato durante il test
La tabella qui di seguito descrive la variazione delle prestazioni in base al prefisso utilizzato durante il test. Dimostriamo che utilizzando lo stesso prefisso utilizzato per il dataset di classificazione (“Prompt”), migliora la performance sul dataset di classificazione (IN-1K). Quando si utilizza lo stesso prefisso utilizzato per il dataset immagine-didascalia (“Didascalia”), migliora la performance su altri dataset (Media a zero-shot). Questa analisi illustra che se il prefisso è adattato per il dataset immagine-didascalia, si ottiene una migliore generalizzazione dei tipi di scene e delle parole del vocabolario.
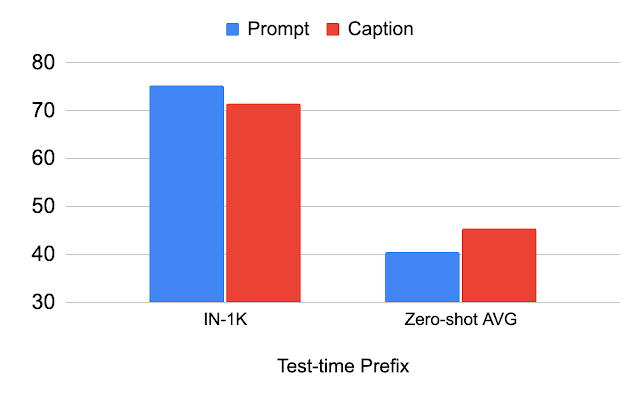 |
| Analisi del prefisso utilizzato per il test. |
Studio sulla robustezza al cambio di distribuzione delle immagini
Studiamo il cambiamento nella distribuzione delle immagini utilizzando varianti di ImageNet. Vediamo che il prefisso “Caption” funziona meglio di “Prompt” in ImageNet-R (IN-R) e ImageNet-Sketch (IN-S), ma ha prestazioni inferiori in ImageNet-V2 (IN-V2). Ciò indica che il prefisso “Caption” ottiene una generalizzazione su domini lontani dal dataset di classificazione. Pertanto, il prefisso ottimale probabilmente varia a seconda di quanto il dominio di test si discosta dal dataset di classificazione.
 |
| Analisi sulla robustezza al cambiamento della distribuzione a livello di immagine. IN: ImageNet, IN-V2: ImageNet-V2, IN-R: Art, Cartoon style ImageNet, IN-S: ImageNet Sketch. |
Conclusioni e lavoro futuro
Introduciamo la condizionamento del prefisso, una tecnica per unificare i dataset di didascalie e classificazione delle immagini per una migliore classificazione a zero-shot. Dimostriamo che questo approccio porta a una maggiore precisione nella classificazione a zero-shot e che il prefisso può controllare il bias nell’embedding del linguaggio. Una limitazione è che il prefisso appreso sul dataset delle didascalie non è necessariamente ottimale per la classificazione a zero-shot. Identificare il prefisso ottimale per ciascun dataset di test è una direzione interessante per il lavoro futuro.
Ringraziamenti
Questa ricerca è stata condotta da Kuniaki Saito, Kihyuk Sohn, Xiang Zhang, Chun-Liang Li, Chen-Yu Lee, Kate Saenko e Tomas Pfister. Grazie a Zizhao Zhang e Sergey Ioffe per il loro prezioso feedback.