Utilizzo di GAN in TensorFlow per generare immagini
Generazione di immagini con GAN in TensorFlow.
Introduzione
In questo articolo, esploreremo l’applicazione delle GAN in TensorFlow per generare interpretazioni uniche di cifre scritte a mano. Il framework GAN comprende due componenti chiave: il generatore e il discriminatore. Il generatore genera nuove immagini in modo casuale, mentre il discriminatore è progettato per differenziare tra immagini autentiche e contraffatte. Attraverso l’addestramento delle GAN, otteniamo una collezione di immagini che assomigliano molto a cifre scritte a mano. L’obiettivo principale di questo articolo è delineare la procedura per costruire e valutare le GAN utilizzando il dataset MNIST.
Obiettivi di apprendimento
- Questo articolo fornisce un’introduzione completa alle Generative Adversarial Networks (GAN) ed esplora le loro applicazioni nella generazione di immagini.
- Lo scopo principale di questo tutorial è guidare i lettori attraverso il processo passo-passo di costruzione di una GAN utilizzando la libreria TensorFlow. Copre l’addestramento della GAN sul dataset MNIST per generare nuove immagini di cifre scritte a mano.
- L’articolo discute l’architettura e i componenti delle GAN, inclusi generatori e discriminatori, per migliorare la comprensione dei lettori del loro funzionamento fondamentale.
- Per facilitare l’apprendimento, l’articolo include esempi di codice che mostrano varie attività, come la lettura e la pre-elaborazione del dataset MNIST, la costruzione dell’architettura GAN, il calcolo delle funzioni di perdita, l’addestramento della rete e la valutazione dei risultati.
- Inoltre, l’articolo esplora l’obiettivo atteso delle GAN, ovvero una collezione di immagini che assomigliano molto a cifre scritte a mano.
Questo articolo è stato pubblicato come parte del Data Science Blogathon.
Cosa stiamo costruendo?
La generazione di immagini innovative utilizzando database di immagini preesistenti è una caratteristica prominente dei modelli specializzati chiamati Generative Adversarial Networks (GAN). Le GAN eccellono nella produzione di immagini non supervisionate o semi-supervisionate sfruttando diversi dataset di immagini.
Questo articolo sfrutta il potenziale di generazione di immagini delle GAN per creare cifre scritte a mano. La metodologia prevede l’addestramento della rete su un database di cifre scritte a mano. In questo articolo di istruzioni, costruiremo una GAN rudimentale utilizzando la libreria Tensorflow, condurremo l’addestramento sul dataset MNIST e genereremo nuove immagini di cifre scritte a mano.
- Cos’è la simulazione robotica?
- Una guida per migliorare la trasformazione digitale attraverso la pulizia dei dati
- Unificazione di dataset di immagini e didascalie con condizionamento del prefisso
Come impostiamo tutto questo?
L’accento principale di questo articolo ruota attorno al sfruttamento del potenziale di generazione di immagini delle GAN. La procedura inizia con il caricamento e la preelaborazione del database di immagini per facilitare il processo di addestramento della GAN. Una volta che i dati sono stati caricati con successo, procediamo a costruire il modello GAN e a sviluppare il codice necessario per l’addestramento e il testing. Nella sezione successiva vengono fornite istruzioni dettagliate su come implementare questa funzionalità e generare un’immagine nuova utilizzando il database MNIST.
Costruzione del modello
Il modello GAN che vogliamo costruire è composto da due componenti importanti:
- Generatore: Questa componente è responsabile della generazione di nuove immagini.
- Discriminatore: Questa componente valuta la qualità dell’immagine generata.
L’architettura generale che svilupperemo per generare immagini utilizzando la GAN è mostrata nel diagramma sottostante. La sezione successiva fornisce una breve descrizione di come leggere il database, creare l’architettura richiesta, calcolare la funzione di perdita e addestrare la rete. Inoltre, viene fornito del codice per ispezionare la rete e generare nuove immagini.
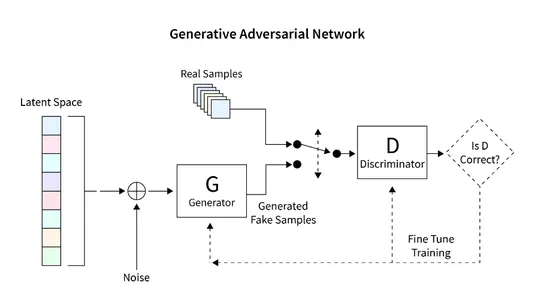
Lettura del dataset
Il dataset MNIST ha grande importanza nel campo della computer vision e comprende una vasta collezione di cifre scritte a mano con dimensioni di 28×28 pixel. Questo dataset si rivela ideale per la nostra implementazione di GAN grazie al suo formato di immagine in scala di grigi a singolo canale.
Lo snippet di codice successivo dimostra l’utilizzo di una funzione incorporata in Tensorflow per caricare il dataset MNIST. Una volta caricati con successo, procediamo a normalizzare e ridimensionare le immagini in un formato tridimensionale. Questa trasformazione consente un’elaborazione efficiente dei dati di immagine 2D all’interno dell’architettura GAN. Inoltre, viene allocata memoria per i dati di addestramento e di validazione.
La forma di ogni immagine è definita come una matrice 28x28x1, dove l’ultima dimensione rappresenta il numero di canali nell’immagine. Poiché il dataset MNIST comprende immagini in scala di grigi, abbiamo solo un singolo canale.
In questo caso particolare, impostiamo la dimensione dello spazio latente, indicata come “zsize”, a 100. Questo valore può essere regolato in base a requisiti o preferenze specifiche.
from __future__ import print_function, division
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam, SGD
import matplotlib.pyplot as plt
import sys
import numpy as np
num_rows = 28
num_cols = 28
num_channels = 1
input_shape = (num_rows, num_cols, num_channels)
z_size = 100
(train_ims, _), (_, _) = mnist.load_data()
train_ims = train_ims / 127.5 - 1.
train_ims = np.expand_dims(train_ims, axis=3)
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))Definizione del Generatore
Il Generatore (D) assume un ruolo cruciale nelle GAN in quanto è responsabile della generazione di immagini realistiche che possono ingannare il discriminatore. Serve come componente principale per la formazione delle immagini nelle GAN. In questo studio, utilizziamo un’architettura specifica per il Generatore, che incorpora uno strato fully connected (FC) e utilizza l’attivazione Leaky ReLU. Tuttavia, è importante notare che l’ultimo strato del Generatore utilizza l’attivazione TanH anziché LeakyReLU. Questo aggiustamento è stato fatto per garantire che l’immagine generata risieda nell’intervallo (-1, 1) come il database originale MNIST.
def build_generator():
gen_model = Sequential()
gen_model.add(Dense(256, input_dim=z_size))
gen_model.add(LeakyReLU(alpha=0.2))
gen_model.add(BatchNormalization(momentum=0.8))
gen_model.add(Dense(512))
gen_model.add(LeakyReLU(alpha=0.2))
gen_model.add(BatchNormalization(momentum=0.8))
gen_model.add(Dense(1024))
gen_model.add(LeakyReLU(alpha=0.2))
gen_model.add(BatchNormalization(momentum=0.8))
gen_model.add(Dense(np.prod(input_shape), activation='tanh'))
gen_model.add(Reshape(input_shape))
gen_noise = Input(shape=(z_size,))
gen_img = gen_model(gen_noise)
return Model(gen_noise, gen_img)Definizione del Discriminatore
In una Generative Adversarial Network (GAN), il Discriminatore (D) svolge il compito critico di differenziare tra immagini reali e immagini generate valutandone l’autenticità e la probabilità. Questo componente può essere visto come un problema di classificazione binaria. Per affrontare questo compito, possiamo utilizzare un’architettura di rete semplificata composta da strati Fully Connected (FC), attivazione Leaky ReLU e Dropout Layers. È importante menzionare che l’ultimo strato del Discriminatore include uno strato FC seguito da un’attivazione Sigmoid. La funzione di attivazione Sigmoid produce la probabilità di classificazione desiderata.
def build_discriminator():
disc_model = Sequential()
disc_model.add(Flatten(input_shape=input_shape))
disc_model.add(Dense(512))
disc_model.add(LeakyReLU(alpha=0.2))
disc_model.add(Dense(256))
disc_model.add(LeakyReLU(alpha=0.2))
disc_model.add(Dense(1, activation='sigmoid'))
disc_img = Input(shape=input_shape)
validity = disc_model(disc_img)
return Model(disc_img, validity)Calcolo della Funzione di Loss
Al fine di garantire un buon processo di generazione di immagini nelle GAN, è importante determinare le metriche appropriate per valutare le loro prestazioni. Definire questo parametro tramite la funzione di loss.
Il discriminatore è responsabile di dividere l’immagine generata in reale o finta e di fornire la probabilità di essere reale. Per ottenere questa differenza, il discriminatore mira a massimizzare la funzione D(x) quando gli viene presentata un’immagine reale e a minimizzare D(G(z)) quando gli viene presentata un’immagine falsa.
D’altra parte, lo scopo del generatore è ingannare il discriminatore creando un’immagine realistica che può essere interpretata erroneamente. Matematicamente, ciò comporta l’applicazione di una scala a D(G(z)). Tuttavia, fare affidamento solo su questo componente come funzione di loss può causare una rete troppo fiduciosa con risultati errati. Per risolvere questo problema, utilizziamo il logaritmo della funzione di loss (D(G(z)).
La funzione di costo complessiva della GAN per generare un’immagine può essere espressa come un gioco minimale:
min_G max_D V(D,G) = E(xp_data(x))(log(D(x))] + E(zp(z))(log(1 – D(G(z)))])
La formazione di questa GAN richiede un equilibrio delicato e può essere vista come una partita tra due avversari. Ciascuna parte cerca di influenzare e superare l’altra giocando un gioco MinMax.
Possiamo utilizzare la Binary Cross Entropy Loss per implementare il Generatore e il Discriminatore.
Per l’implementazione del Generatore e del Discriminatore, possiamo utilizzare la Binary Cross Entropy Loss.
# discriminatore
disc = build_discriminator()
disc.compile(loss='binary_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
z = Input(shape=(z_size,))
# generatore
img = generator(z)
disc.trainable = False
validity = disc(img)
# modello combinato
combined = Model(z, validity)
combined.compile(loss='binary_crossentropy', optimizer='sgd')Ottimizzazione della Loss
Per facilitare l’addestramento della rete, il nostro obiettivo è coinvolgere la GAN in un gioco MinMax. Questo processo di apprendimento ruota attorno all’ottimizzazione dei pesi della rete attraverso l’utilizzo del Gradient Descent. Per accelerare il processo di apprendimento e impedire la convergenza verso paesaggi di loss subottimali, viene utilizzato lo Stochastic Gradient Descent (SGD).
Dato che il Discriminatore e il Generatore hanno loss diverse, una singola funzione di loss non può ottimizzare contemporaneamente entrambi i sistemi. Di conseguenza, utilizziamo le funzioni di loss separate per ciascun sistema.
def inizializza_modello():
disc = build_discriminator()
disc.compile(loss='binary_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
generator = build_generator()
z = Input(shape=(z_size,))
img = generator(z)
disc.trainable = False
validity = disc(img)
combined = Model(z, validity)
combined.compile(loss='binary_crossentropy', optimizer='sgd')
return disc, Generator, e combinedDopo aver specificato tutte le caratteristiche necessarie, possiamo addestrare il sistema e ottimizzare la loss. I passaggi per addestrare una GAN per generare un’immagine sono i seguenti:
- Caricare l’immagine e generare un suono casuale della stessa dimensione dell’immagine caricata.
- Differenziare tra l’immagine caricata e il suono prodotto e considerare la possibilità che sia reale o falso.
- Produrre un altro rumore casuale della stessa ampiezza e fornirlo come input al generatore.
- Addestrare il generatore per un periodo specifico.
- Ripetere questi passaggi fino a quando l’immagine è soddisfacente.
def train(epochs, batch_size=128, sample_interval=50):
# carica le immagini
(train_ims, _), (_, _) = mnist.load_data()
# preprocessa
train_ims = train_ims / 127.5 - 1.
train_ims = np.expand_dims(train_ims, axis=3)
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
# ciclo di addestramento
for epoch in range(epochs):
batch_index = np.random.randint(0, train_ims.shape[0], batch_size)
imgs = train_ims[batch_index]
# crea il rumore
noise = np.random.normal(0, 1, (batch_size, z_size))
# predici utilizzando un Generatore
gen_imgs = gen.predict(noise)
# calcola le funzioni di loss
real_disc_loss = disc.train_on_batch(imgs, valid)
fake_disc_loss = disc.train_on_batch(gen_imgs, fake)
disc_loss_total = 0.5 * np.add(real_disc_loss, fake_disc_loss)
noise = np.random.normal(0, 1, (batch_size, z_size))
g_loss = full_model.train_on_batch(noise, valid)
# salva gli output ogni poche epoche
if epoch % sample_interval == 0:
one_batch(epoch)Generazione di Cifre Scritte a Mano
Utilizzando il dataset MNIST, possiamo creare una funzione di utilità per generare previsioni per un insieme di immagini utilizzando il Generatore. Questa funzione genera un suono casuale, lo fornisce al generatore, lo esegue per visualizzare l’immagine generata e la salva in una cartella speciale. Si consiglia di eseguire questa funzione di utilità periodicamente, ad esempio ogni 200 cicli, per monitorare il progresso della rete. L’implementazione è la seguente:
def one_batch(epoch):
r, c = 5, 5
noise_model = np.random.normal(0, 1, (r * c, z_size))
gen_images = gen.predict(noise_model)
# Ridimensiona le immagini tra 0 e 1
gen_images = gen_images*(0.5) + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_images[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("images/%d.png" % epoch)
plt.close()Nel nostro esperimento, abbiamo allenato la GAN per circa 10.000 epoche utilizzando una dimensione del batch di 32. Per monitorare il progresso dell’allenamento, abbiamo salvato le immagini generate ogni 200 epoche e le abbiamo archiviate in una cartella apposita chiamata “images”.
disc, gen, full_model = intialize_model()
train(epochs=10000, batch_size=32, sample_interval=200)Ora, esaminiamo i risultati della simulazione GAN in diverse fasi: inizializzazione, 400 epoche, 5000 epoche e il risultato finale a 10000 epoche.
Inizialmente, partiamo con rumore casuale come input per il Generatore.

Dopo 400 epoche di allenamento, possiamo osservare qualche progresso, anche se le immagini generate sono ancora significativamente diverse dai numeri reali.

Dopo l’allenamento per 5000 epoche, possiamo osservare che le figure generate iniziano a somigliare al dataset MNIST.

Completando le 10.000 epoche complete di allenamento, otteniamo i seguenti output.

Queste immagini generate assomigliano molto ai dati dei numeri scritti a mano utilizzati per allenare la rete. È importante notare che queste immagini non fanno parte del set di allenamento e sono completamente generate dalla rete.
Prossimi Passi
Ora che abbiamo ottenuto buoni risultati nella generazione di immagini della GAN, ci sono molti modi per migliorarli ulteriormente. Nell’ambito di questa discussione, possiamo considerare di sperimentare con diversi parametri. Ecco alcune suggerimenti:
- Esplora diversi valori per la variabile spazio latente z_size per vedere se aumenta l’efficienza.
- Aumenta il numero di epoche di allenamento oltre le 10.000. Raddoppiare o triplicare la durata dell’allenamento potrebbe rivelare risultati migliorati o peggiorati.
- Prova a utilizzare diversi dataset come fashion MNIST o moving MNIST. Poiché questi dataset hanno la stessa struttura di MNIST, adatta il nostro codice esistente.
- Considera di sperimentare con architetture alternative come CycleGun, DCGAN e altre. Modificare le funzioni del generatore e del discriminatore potrebbe essere sufficiente per esplorare questi modelli.
Implementando questi cambiamenti, possiamo migliorare ulteriormente le capacità delle GAN e esplorare nuove possibilità nella generazione di immagini.
Queste immagini generate assomigliano molto ai dati dei numeri scritti a mano utilizzati per allenare la rete. Queste immagini non fanno parte del set di allenamento e sono generate interamente dalla rete.
Conclusioni
In sintesi, la GAN è un potente modello di apprendimento automatico in grado di generare nuove immagini basate su database esistenti. In questo tutorial, abbiamo mostrato come progettare e allenare una semplice GAN utilizzando la libreria Tensorflow come esempio e il database MNIST.
Punti Chiave
- La GAN è composta da due componenti importanti: un generatore, responsabile della generazione di nuove immagini da un input casuale, e il discriminatore, che mira a distinguere tra immagini reali e false.
- Attraverso il processo di apprendimento, siamo riusciti a creare un insieme di immagini che somigliano molto ai numeri scritti a mano, come mostrato nell’immagine di esempio.
- Per ottimizzare le prestazioni della GAN, forniamo metriche di corrispondenza e funzioni di perdita che aiutano a distinguere tra immagini reali e false. Valutando le GAN su dati non visti e utilizzando i generatori, possiamo generare nuove immagini mai viste prima.
- In generale, le GAN offrono interessanti possibilità nella generazione di immagini e hanno un grande potenziale per diverse applicazioni come l’apprendimento automatico e la visione artificiale.
Domande Frequenti
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e sono utilizzati a discrezione dell’autore.
