Aggregazione dei dati in Python con Pandas Analisi dei dati di litologia geologica
Data aggregation in Python with Pandas Geological lithology data analysis
Esplorazione delle variazioni di litologia all’interno del Gruppo di Zechstein della Pancia Norvegese

L’utilizzo delle tecniche di aggregazione dei dati può aiutarci a trasformare un dataset numerico schiacciante e quasi incomprensibile in qualcosa di facilmente comprensibile e molto più leggibile. Il processo di aggregazione dei dati consiste nel riassumere più punti dati in metriche singole che possono essere utilizzate per fornire una panoramica generale dei dati.
Un modo in cui possiamo applicare questo processo nella petrofisica e nelle scienze della Terra è quello di riassumere la composizione litologica delle formazioni geologiche che sono state interpretate dalle misurazioni dei log dei pozzi.
In questo breve tutorial, vedremo come possiamo prendere un grande dataset composto da più di 90 pozzi della Pancia Norvegese e estrarre la composizione litologica del Gruppo di Zechstein.
Importazione delle librerie e caricamento dei dati
Per iniziare, dobbiamo importare la libreria pandas, che verrà utilizzata per caricare il nostro file di dati da CSV e per effettuare le aggregazioni.
- Sostituirà ChatGPT i Data Scientist?
- Ricercatori insegnano all’IA a scrivere didascalie di grafici migliori
- Utilizzo di GAN in TensorFlow per generare immagini
import pandas as pdUna volta importata la libreria pandas, possiamo quindi leggere il file CSV utilizzando pd.read_csv().
I dati che utilizzeremo provengono dalla competizione combinata di apprendimento automatico XEEK e Force 2020, che aveva lo scopo di prevedere la litologia dalle misurazioni dei log dei pozzi. Il dataset che stiamo utilizzando rappresenta tutti i dati di addestramento disponibili. Ulteriori dettagli su questo dataset possono essere trovati alla fine dell’articolo.
Dato che questo file CSV contiene dati separati da un punto e virgola anziché da una virgola, dobbiamo passare un punto e virgola al parametro sep.
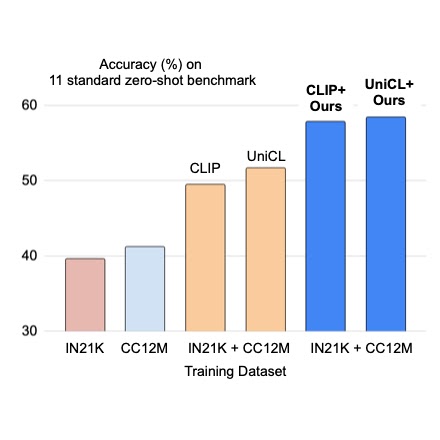
df = pd.read_csv('data/train.csv', sep=';')Possiamo quindi eseguire questo codice per avviare il processo di caricamento. Poiché abbiamo un grande dataset (oltre 11 milioni di righe), potrebbe richiedere diversi secondi. Ma una volta completato il caricamento, possiamo visualizzare il nostro dataframe richiamando l’oggetto df. Questo restituirà il nostro dataframe e mostrerà le prime cinque e le ultime cinque righe.
Utilizzo di pandas .map() per convertire i codici numerici in stringhe di litologia
All’interno di questo dataset, i dati sulla litologia sono memorizzati nella colonna FORCE_2020_LITHOFACIES_LITHOLOGY. Tuttavia, se osserviamo da vicino i nostri dati, vedremo che i valori della litologia sono codificati numericamente. A meno che non si conosca la chiave, sarà difficile decifrare quale numero rappresenta quale litologia.
Fortunatamente per questo dataset, abbiamo la chiave e possiamo creare un dizionario con le coppie chiave e litologia.
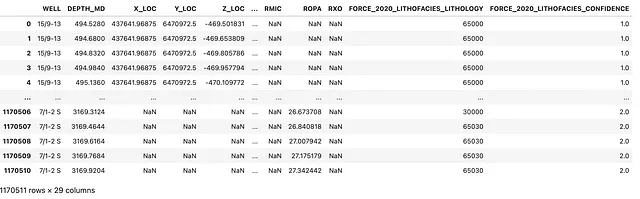
lithology_numbers = {30000: 'Arenaria', 65030: 'Arenaria/Scisto', 65000: 'Scisto', 80000: 'Marna', 74000: 'Dolomite', 70000: 'Calcarenite', 70032: 'Gesso', 88000: 'Halite', 86000: 'Anidrite', 99000: 'Tufite', 90000: 'Carbone', 93000: 'Basamento'}Per applicare questo al nostro dataset, possiamo utilizzare la funzione map() di pandas, che effettuerà una ricerca nel nostro dizionario e assegnerà l’etichetta di litologia corretta al valore numerico.
df['LITH'] = df['FORCE_2020_LITHOFACIES_LITHOLOGY'].map(lithology_numbers)Una volta eseguito questo comando, possiamo visualizzare nuovamente il dataframe per assicurarci che il mapping sia stato eseguito correttamente e una nuova colonna LITH sia stata aggiunta alla fine del dataframe.
Filtrare il Dataframe per un Gruppo Geologico Specifico
Dato che abbiamo un dataset piuttosto grande con 11.705.511 righe, sarebbe utile concentrarsi su un particolare gruppo geologico per la nostra analisi compositiva della litologia.
In questo caso, effettueremo una suddivisione dei dati e analizzeremo il Gruppo Zechstein.
Possiamo farlo utilizzando il metodo query() e passando una semplice stringa: GROUP == "ZECHSTEIN GP."
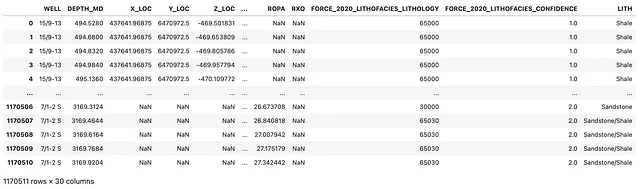
df_zechstein = df.query('GROUP == "ZECHSTEIN GP."')df_zechstein.WELL.unique()Possiamo verificare quanti pozzi abbiamo nel sottoinsieme chiamando df_zechstein.WELL.unique(), che restituisce l’array seguente contenente 8 pozzi.
array(['15/9-13', '16/1-2', '16/10-1', '16/11-1 ST3', '16/2-16', '16/2-6', '16/4-1', '17/11-1'], dtype=object)Dato che siamo interessati solo alle litologie, possiamo estrarre semplicemente il nome del pozzo e le colonne della litologia. Questo renderà anche più facile eseguire l’aggregazione.
df_zechstein_liths = df_zechstein[['WELL', 'LITH']]
Aggregare i Dati Utilizzando Funzioni Pandas Annidate
Ora che abbiamo i dati in un formato con cui possiamo lavorare, possiamo iniziare il processo di aggregazione. Per farlo, concateniamo più metodi pandas in una singola chiamata.
Prima di tutto, raggruppiamo i dati per colonna WELL utilizzando la funzione groupby. Questo crea essenzialmente sottoinsiemi del dataframe per ogni nome di pozzo unico all’interno della colonna WELL.
Successivamente, contiamo le occorrenze di ciascun tipo di litologia all’interno di ogni gruppo. La parte normalize=True significa che restituirà una proporzione (compresa tra 0 e 1) anziché un conteggio assoluto. Ad esempio, se in un pozzo (gruppo) ‘arenaria’ compare 5 volte e ‘argilla’ compare 15 volte, la funzione restituirà 0,25 per ‘arenaria’ e 0,75 per ‘argilla’ anziché 5 e 15.
Infine, dobbiamo riorganizzare il nostro dataframe risultante in modo che l’indice di riga contenga i nomi dei pozzi e le colonne contengano i nomi delle litologie. Se un pozzo non ha istanze di una determinata litologia, verranno riempite con zero, grazie a fill_value=0.
summary_df = df_zechstein_liths.groupby('WELL').value_counts(normalize=True).unstack(fill_value=0)summary_dfCiò che otteniamo è il seguente dataframe con le proporzioni decimali di ciascuna litologia all’interno di ciascun pozzo.
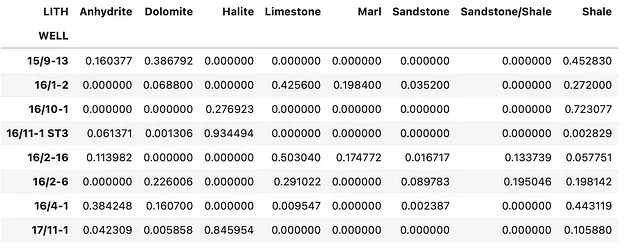
Se vogliamo visualizzarli come percentuali, possiamo cambiare il modo in cui vengono visualizzati utilizzando il seguente codice:
summary_df.style.format('{:.2%}')Quando eseguiamo il codice, otteniamo il seguente DataFrame che fornisce una tabella più leggibile e può essere incorporata in un rapporto.
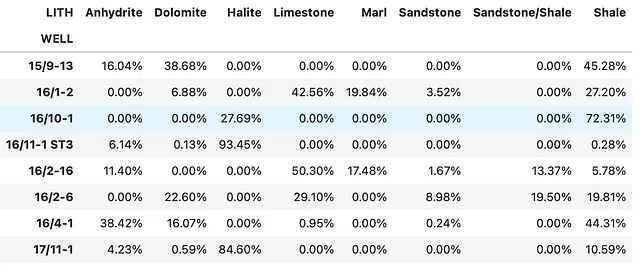
L’applicazione di questo stile non cambia i valori effettivi. Rimarranno comunque memorizzati come i loro equivalenti decimali.
Se vogliamo cambiare i valori permanentemente in percentuali, possiamo farlo moltiplicando il DataFrame per 100.
summary_df = summary_df * 100summary_df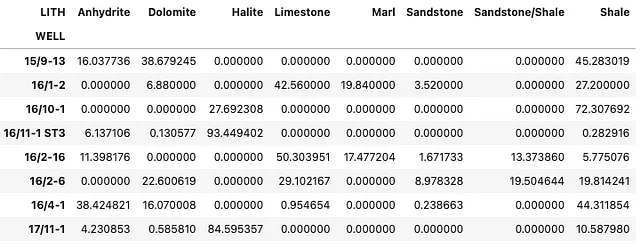
Una volta che i dati sono in questo formato, possiamo utilizzarli per creare qualcosa di simile all’infografica sottostante, che mostra le percentuali per le litologie di ciascun pozzo.
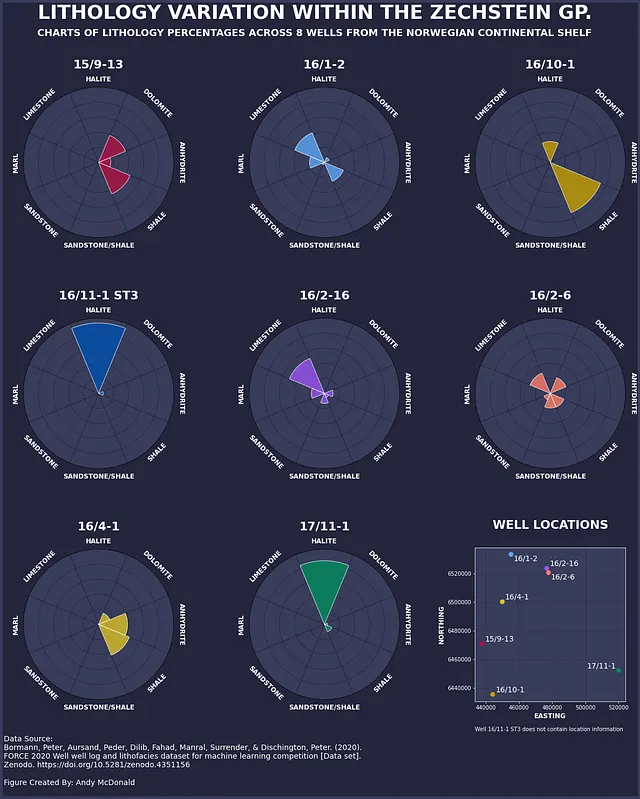
Riepilogo
In questo breve tutorial, abbiamo visto come possiamo prendere un’ampia collezione di dati di registri di pozzi (da più di 90 pozzi) ed estrarre e riassumere un determinato gruppo geologico. Ciò ci consente di comprendere la composizione litologica del gruppo geologico in un formato facile da leggere e comprensibile, che può essere incorporato in un rapporto o una presentazione.
Dataset utilizzato in questo tutorial
Set di dati di addestramento utilizzato come parte di una competizione di Machine Learning organizzata da Xeek e FORCE 2020 (Bormann et al., 2020). Questo dataset è concesso in licenza con Creative Commons Attribution 4.0 International.
È possibile accedere al set di dati completo al seguente link: https://doi.org/10.5281/zenodo.4351155.
Grazie per la lettura. Prima di andare, dovresti sicuramente iscriverti ai miei contenuti e ricevere i miei articoli nella tua casella di posta. Puoi farlo qui!
In secondo luogo, puoi ottenere la piena esperienza Nisoo e sostenere migliaia di altri scrittori e me iscrivendoti a un abbonamento. Costa solo $5 al mese e hai pieno accesso a tutti gli articoli fantastici di Nisoo, nonché la possibilità di guadagnare con la tua scrittura.
Se ti iscrivi utilizzando il mio link, mi supporterai direttamente con una parte della tua quota e non ti costerà di più. Se lo fai, grazie mille per il tuo supporto.