Smetti di Codificare Duramente in un Progetto di Data Science – Usa invece File di Configurazione
Use Configuration Files Instead of Hard Coding in a Data Science Project - Stop Coding Hard.
Come interagire in modo efficiente con i file di configurazione in Python.
Problema
Nel tuo progetto di data science, alcuni valori tendono a cambiare frequentemente, come i nomi dei file, le feature selezionate, il rapporto di divisione tra training e test e gli iperparametri del tuo modello.

È possibile inserire questi valori direttamente nel codice quando si scrive un codice ad-hoc per testare ipotesi o dimostrare scopi. Tuttavia, man mano che la base di codice e il team si espandono, diventa essenziale evitare di inserire i valori direttamente nel codice, poiché può dare origine a vari problemi:
- Questo articolo sull’IA studia l’impatto dell’anonimizzazione per l’addestramento dei modelli di visione artificiale con un focus sui dataset di veicoli autonomi.
- Cosa fare dopo la laurea in Ingegneria?
- Come l’AI di Meta genera musica basata su una melodia di riferimento.
- Mantenibilità : se i valori sono sparsi in tutto il codice, la loro aggiornamento diventa più difficile. Ciò può portare ad errori o incongruenze durante gli aggiornamenti dei valori.
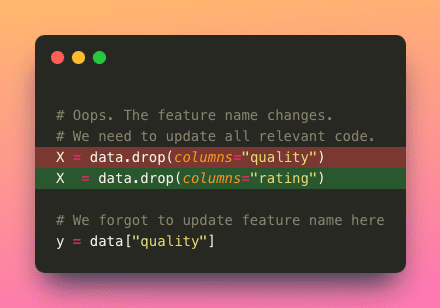
- Riusabilità : inserire i valori direttamente nel codice limita la riutilizzabilità del codice per diversi scenari.

- Preoccupazioni per la sicurezza : inserire informazioni sensibili come password o chiavi API direttamente nel codice può essere un rischio per la sicurezza. Se il codice viene condiviso o esposto, potrebbe portare ad accessi non autorizzati o violazioni dei dati.
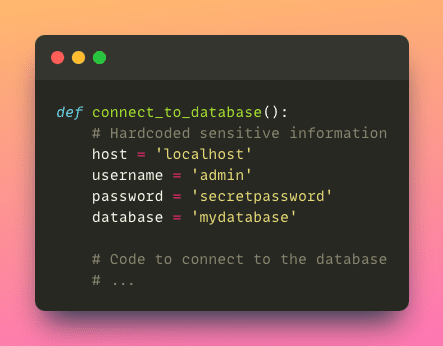
- Test e debugging : inserire i valori direttamente nel codice può rendere il testing e il debugging più complicati. Se i valori sono inseriti direttamente nel codice, diventa difficile simulare diversi scenari o testare i casi limite in modo efficace.

Soluzione – File di configurazione
I file di configurazione risolvono questi problemi offrendo i seguenti vantaggi:
- Separazione della configurazione dal codice : il file di configurazione consente di archiviare i parametri separatamente dal codice, migliorando la manutenibilità e la leggibilità del codice.
- Flessibilità e modificabilità : con un file di configurazione, è possibile modificare facilmente le configurazioni del progetto senza modificare il codice stesso. Questa flessibilità consente di effettuare rapidi esperimenti, di tarare i parametri e di adattare il progetto a diversi scenari o ambienti.
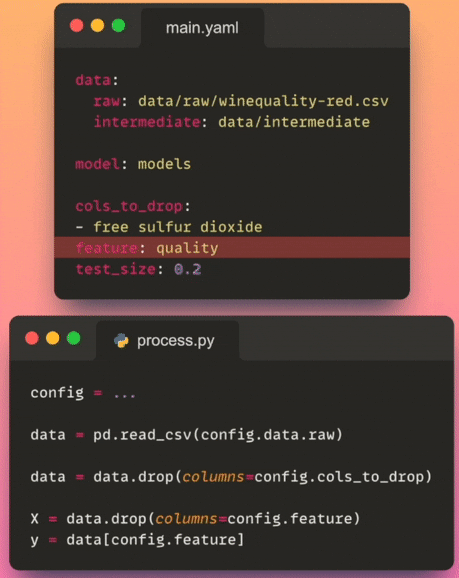
- Controllo di versione : archiviare il file di configurazione in un sistema di controllo di versione consente di tenere traccia delle modifiche alla configurazione nel tempo. Ciò aiuta a mantenere un registro storico delle configurazioni del progetto e facilita la collaborazione tra i membri del team.

- Implementazione e produzione : quando si implementa un progetto di data science in un ambiente di produzione, un file di configurazione consente di personalizzare facilmente le impostazioni specifiche dell’ambiente di produzione senza la necessità di modificare il codice. Questa separazione della configurazione dal codice semplifica il processo di implementazione.
Introduzione a Hydra
Tra le numerose librerie Python disponibili per creare file di configurazione, Hydra si distingue come il mio strumento preferito per la gestione della configurazione grazie al suo impressionante set di funzionalità, tra cui:
- Accesso conveniente ai parametri
- Override della configurazione da riga di comando
- Composizione di configurazioni da diverse fonti
- Esecuzione di più lavori con diverse configurazioni
Approfondiamo ognuna di queste funzionalità.
Gioca liberamente e forka il codice sorgente di questo articolo qui:
Visualizza su GitHub
Accesso conveniente ai parametri
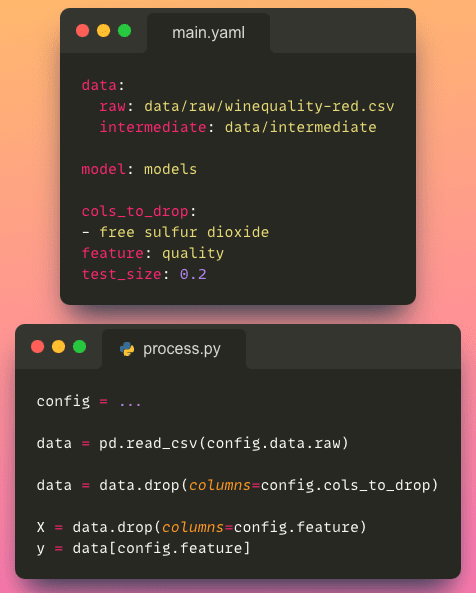
Supponiamo che tutti i file di configurazione siano archiviati nella cartella conf e tutti gli script Python siano archiviati nella cartella src.
.
├── conf/
│ └── main.yaml
└── src/
├── __init__.py
├── process.py
└── train_model.pyE il file main.yaml sembra così:

Accedere ad un file di configurazione all’interno di uno script Python è semplice come applicare un singolo decoratore alla tua funzione Python.
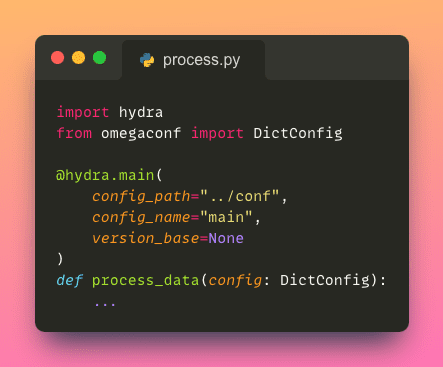
Per accedere ad un parametro specifico dal file di configurazione, possiamo utilizzare la notazione a punto (ad esempio, config.process.cols_to_drop), che è un modo più pulito e intuitivo rispetto all’utilizzo di parentesi quadre (ad esempio, config['process']['cols_to_drop']).
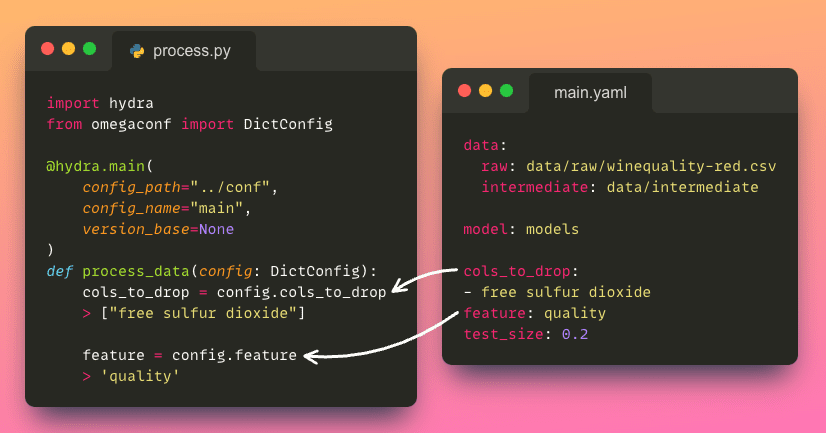
Questo approccio diretto ti consente di recuperare facilmente i parametri desiderati.
Sovrascrittura della configurazione da linea di comando
Supponiamo che tu stia sperimentando con diversi test_size. È tempo che consuma per aprire ripetutamente il tuo file di configurazione e modificare il valore di test_size.

Fortunatamente, Hydra rende facile sovrascrivere direttamente la configurazione dalla linea di comando. Questa flessibilità consente di apportare regolazioni e perfezionamenti rapidi senza modificare i file di configurazione sottostanti.

Composizione di configurazioni da fonti multiple
Immagina di voler sperimentare con varie combinazioni di metodi di elaborazione dati e iperparametri del modello. Mentre potresti modificare manualmente il file di configurazione ogni volta che esegui una nuova sperimentazione, questo approccio può richiedere molto tempo.

Hydra consente la composizione di configurazioni da fonti multiple con gruppi di configurazione. Per creare un gruppo di configurazione per l’elaborazione dati, crea una directory chiamata process per contenere un file per ogni metodo di elaborazione:
.
└── conf/
├── process/
│ ├── process1.yaml
│ └── process2.yaml
└── main.yaml
Se vuoi utilizzare il file process1.yaml per impostazione predefinita, aggiungilo alla lista predefinita di Hydra.

Segui le stesse procedure per creare un gruppo di configurazione per gli iperparametri di addestramento:
.
└── conf/
├── process/
│ ├── process1.yaml
│ └── process2.yaml
├── train/
│ ├── train1.yaml
│ └── train2.yaml
└── main.yaml
Imposta train1 come file di configurazione predefinito:

Ora l’esecuzione dell’applicazione utilizzerà i parametri nel file process1.yaml e nel file model1.yaml per impostazione predefinita:

Questa capacità è particolarmente utile quando è necessario combinare diversi file di configurazione in modo fluido.
Multi-run
Supponiamo che tu voglia condurre esperimenti con più metodi di elaborazione, applicando ciascuna configurazione una per volta può essere un compito che richiede molto tempo.

Fortunatamente, Hydra ti consente di eseguire contemporaneamente la stessa applicazione con diverse configurazioni.
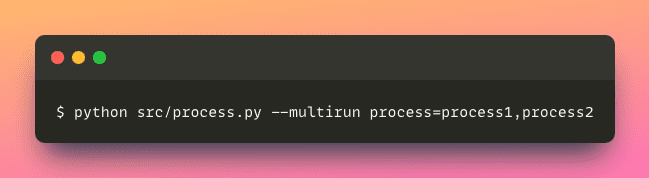
Questo approccio semplifica il processo di esecuzione di un’applicazione con diversi parametri, risparmiando tempo ed sforzi preziosi.
Conclusione
Congratulazioni! Hai appena appreso l’importanza dell’utilizzo dei file di configurazione e come crearne uno usando Hydra. Spero che questo articolo ti dia le conoscenze necessarie per creare i tuoi file di configurazione.
Khuyen Tran è una prolifica scrittrice di data science e ha scritto una notevole collezione di utili argomenti di data science insieme a codice e articoli. Khuyen sta attualmente cercando un ruolo di machine learning engineer, data scientist o developer advocate nell’area della Bay dopo maggio 2022, quindi contattala se stai cercando qualcuno con il suo set di competenze.
Originale. Ripubblicato con il permesso.