Diffusione stabile Intuizione di base dietro l’IA generativa
Stable diffusion Basic intuition behind generative AI
Questo articolo fornisce una panoramica generale sulla Diffusione Stabile e si concentra sulla costruzione di una comprensione di base di come funziona l’intelligenza artificiale generativa.

Introduzione
Il mondo dell’IA si è spostato drasticamente verso la modellazione generativa negli ultimi anni, sia nella Computer Vision che nell’Elaborazione del Linguaggio Naturale. Dalle-2 e Midjourney hanno attirato l’attenzione delle persone, portandole a riconoscere il lavoro eccezionale che viene realizzato nel campo dell’IA generativa.
La maggior parte delle immagini generate dall’IA attualmente prodotte si basano su modelli di diffusione come fondamento. Lo scopo di questo articolo è chiarire alcuni dei concetti che circondano la Diffusione Stabile e offrire una comprensione fondamentale della metodologia impiegata.
- Costruzione di modelli linguistici Una guida passo-passo all’implementazione di BERT
- 5 Libri Gratuiti su Elaborazione del Linguaggio Naturale da Leggere nel 2023
- Incontra Wanda Un Approccio Semplice ed Efficace per la Potatura di Grandi Modelli Linguistici
Architettura Semplificata
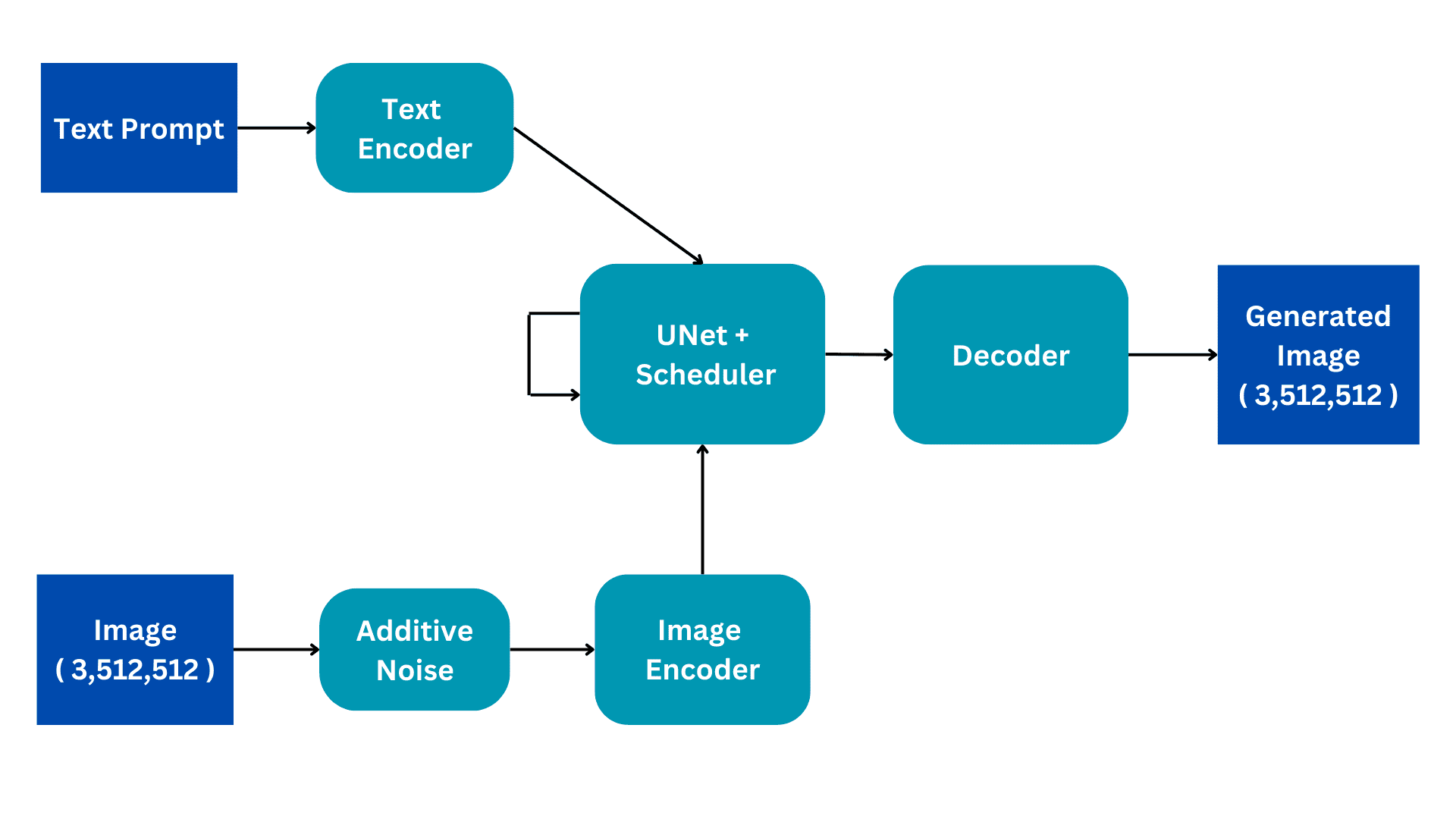
Questo diagramma di flusso mostra la versione semplificata di un’architettura di Diffusione Stabile. Lo analizzeremo pezzo per pezzo per creare una migliore comprensione del funzionamento interno. Approfondiremo il processo di addestramento per una migliore comprensione, con l’inferenza che presenta solo alcune sottili modifiche.
Input
I modelli di Diffusione Stabile vengono addestrati su set di dati di descrizione delle immagini in cui ogni immagine ha una didascalia o un prompt associato che descrive l’immagine. Pertanto, il modello ha due input; un prompt testuale in linguaggio naturale e un’immagine di dimensioni (3,512,512) con 3 canali di colore e dimensioni di dimensione 512.
Rumore Additivo
L’immagine viene convertita in rumore completo aggiungendo rumore gaussiano all’immagine originale. Questo viene fatto in passaggi consecutivi, ad esempio, viene aggiunta una piccola quantità di rumore all’immagine per 50 passaggi consecutivi fino a quando l’immagine diventa completamente rumorosa. Il processo di diffusione mirerà a rimuovere questo rumore e riprodurre l’immagine originale. Come verrà spiegato ulteriormente, questo avviene.
Image Encoder
L’Image encoder funziona come componente di un Variational AutoEncoder, convertendo l’immagine in uno ‘spazio latente’ e ridimensionandola a dimensioni più piccole, ad esempio (4, 64, 64), includendo anche una dimensione batch aggiuntiva. Questo processo riduce i requisiti computazionali e migliora le prestazioni. A differenza dei modelli di diffusione originali, la Diffusione Stabile incorpora il passaggio di codifica nella dimensione latente, riducendo così i calcoli, così come il tempo di addestramento e inferenza.
Text Encoder
Il prompt in linguaggio naturale viene trasformato in un embedding vettorializzato dal text encoder. Questo processo impiega un modello di linguaggio basato su Transformer, come BERT o modelli di testo CLIP basati su GPT. I modelli di text encoder migliorano significativamente la qualità delle immagini generate. L’output risultante del text encoder consiste in un array di vettori di embedding a 768 dimensioni per ogni parola. Al fine di controllare la lunghezza del prompt, viene impostato un limite massimo di 77. Di conseguenza, il text encoder produce un tensore con dimensioni (77, 768).
UNet
Questa è la parte più computazionalmente costosa dell’architettura e qui avviene il principale processo di diffusione. Riceve come input l’encoding del testo e l’immagine latente rumorosa. Questo modulo mira a riprodurre l’immagine originale a partire dall’immagine rumorosa che riceve. Lo fa attraverso diversi passaggi di inferenza che possono essere impostati come iperparametro. Normalmente, 50 passaggi di inferenza sono sufficienti.
Consideriamo uno scenario semplice in cui un’immagine in ingresso subisce una trasformazione in rumore introducendo gradualmente piccole quantità di rumore in 50 passaggi consecutivi. Questa aggiunta cumulativa di rumore trasforma alla fine l’immagine originale in rumore completo. L’obiettivo dell’UNet è invertire questo processo prevedendo il rumore aggiunto al passo precedente. Durante il processo di denoising, l’UNet inizia prevedendo il rumore aggiunto al 50° passo per il passo iniziale. Sottrae quindi questo rumore previsto dall’immagine in ingresso e ripete il processo. In ogni passaggio successivo, l’UNet prevede il rumore aggiunto al passo precedente, ripristinando gradualmente l’immagine di input originale dal rumore completo. Durante questo processo, l’UNet si affida internamente al vettore di embedding testuale come fattore condizionante.
L’UNet produce un tensore di dimensione (4, 64, 64) che viene passato alla parte di decodifica del Variational AutoEncoder.
Decoder
Il decoder inverte la conversione della rappresentazione latente effettuata dall’encoder. Prende una rappresentazione latente e la converte nuovamente nello spazio delle immagini. Pertanto, produce un’immagine di dimensioni (3,512,512), delle stesse dimensioni dello spazio di input originale. Durante l’addestramento, l’obiettivo è minimizzare la perdita tra l’immagine originale e l’immagine generata. Dato che, dato un prompt testuale, possiamo generare un’immagine correlata al prompt da un’immagine completamente rumorosa.
Unire tutto insieme
Durante l’inferenza, non abbiamo alcuna immagine di input. Lavoriamo solo in modalità testo-immagine. Rimuoviamo la parte dell’aggiunta di rumore e invece utilizziamo un tensore generato casualmente delle dimensioni richieste. Il resto dell’architettura rimane lo stesso.
L’UNet è stato addestrato per generare un’immagine a partire da rumore completo, sfruttando l’embedding del prompt di testo. Questo input specifico viene utilizzato durante la fase di inferenza, consentendoci di generare con successo immagini sintetiche dal rumore. Questo concetto generale serve come intuizione fondamentale di tutti i modelli generativi di visione artificiale. Muhammad Arham è un ingegnere di apprendimento profondo che lavora in visione artificiale e elaborazione del linguaggio naturale. Ha lavorato sulla distribuzione e l’ottimizzazione di diverse applicazioni di intelligenza artificiale generativa che hanno raggiunto le classifiche globali di Vyro.AI. È interessato alla costruzione e all’ottimizzazione di modelli di apprendimento automatico per sistemi intelligenti e crede nell’impegno per il miglioramento continuo.