Cattura più rapidamente informazioni sulla salute pubblica utilizzando il machine learning senza codice grazie all’utilizzo di Amazon SageMaker Canvas.
Cattura rapidamente informazioni sulla salute pubblica con l'uso di Amazon SageMaker Canvas, utilizzando il machine learning senza codice.
Le organizzazioni di sanità pubblica dispongono di una vasta quantità di dati su diversi tipi di malattie, tendenze sanitarie e fattori di rischio. Il loro personale ha da tempo utilizzato modelli statistici e analisi di regressione per prendere decisioni importanti come individuare le popolazioni con i fattori di rischio più elevati per una malattia e prevedere l’evoluzione di epidemie preoccupanti.
Quando emergono minacce per la sanità pubblica, la velocità dei dati aumenta, i dataset in ingresso possono diventare più grandi e la gestione dei dati diventa più impegnativa. Questo rende più difficile analizzare i dati in modo olistico e trarne informazioni. E quando il tempo è essenziale, la velocità e l’agilità nell’analisi dei dati e nell’elaborazione di informazioni diventano ostacoli fondamentali per la creazione di risposte sanitarie rapide e solide.
Le tipiche domande a cui le organizzazioni di sanità pubblica si trovano di fronte in periodi di stress includono:
– Ci saranno sufficienti terapie in una determinata località?
– Quali fattori di rischio influenzano gli esiti sanitari?
– Quali popolazioni hanno un rischio più elevato di reinfezione?
- TaatikNet Apprendimento sequenza-sequenza per la trascrizione ebraica
- Incontra ChatGLM2-6B la versione di seconda generazione del modello di chat open-source bilingue (cinese-inglese) ChatGLM-6B.
- Trasformazione della formazione specializzata di intelligenza artificiale – Incontra LMFlow un promettente toolkit per ottimizzare ed personalizzare in modo efficiente grandi modelli di base per prestazioni superiori.
Per rispondere a queste domande, è necessario comprendere le complesse relazioni tra molti diversi fattori, spesso mutevoli e dinamiche. Uno strumento potente a nostra disposizione è l’apprendimento automatico (ML), che può essere utilizzato per analizzare, prevedere e risolvere questi complessi problemi quantitativi. Sempre più spesso l’ML viene utilizzato per affrontare problemi sanitari difficili come la classificazione dei tumori cerebrali mediante l’analisi delle immagini e la previsione del bisogno di salute mentale per implementare programmi di intervento precoce.
Ma cosa succede se le organizzazioni di sanità pubblica hanno carenza di competenze necessarie per applicare l’ML a queste domande? L’applicazione dell’ML a problemi di sanità pubblica viene ostacolata e le organizzazioni di sanità pubblica perdono la possibilità di utilizzare potenti strumenti quantitativi per affrontare le loro sfide.
Come possiamo eliminare questi ostacoli? La risposta è democratizzare l’ML e consentire a un maggior numero di professionisti della salute con una profonda esperienza nel settore di utilizzarlo e applicarlo alle domande che desiderano risolvere.
Amazon SageMaker Canvas è uno strumento ML senza codice che consente ai professionisti della sanità pubblica come gli epidemiologi, gli informatisti e i bio-statistici di utilizzare l’ML per le loro domande, senza richiedere una formazione in scienze dei dati o competenze nell’ML. Possono dedicare il loro tempo ai dati, applicare la loro esperienza nel settore, testare rapidamente ipotesi e quantificare le informazioni. Canvas contribuisce a rendere la sanità pubblica più equa democratizzando l’ML, consentendo agli esperti di salute di valutare ampi dataset e di ottenere informazioni avanzate utilizzando l’ML.
In questo post, mostriamo come gli esperti di sanità pubblica possono prevedere la domanda di una determinata terapia per i prossimi 30 giorni utilizzando Canvas. Canvas fornisce un’interfaccia visuale che consente di generare previsioni accurate di ML autonomamente, senza richiedere alcuna esperienza nell’ML o la scrittura di una singola riga di codice.
Panoramica della soluzione
Supponiamo di lavorare su dati che abbiamo raccolto da diversi stati degli Stati Uniti. Potremmo formulare l’ipotesi che un certo comune o una determinata località non disponga di abbastanza terapie nelle prossime settimane. Come possiamo testare questa ipotesi in modo rapido e con un alto grado di precisione?
Per questo post, utilizziamo un dataset pubblicamente disponibile del Dipartimento della Salute e dei Servizi Umani degli Stati Uniti, che contiene dati storici aggregati per stato relativi al COVID-19, inclusa l’utilizzo degli ospedali, la disponibilità di determinate terapie e molto altro. Il dataset (COVID-19 Reported Patient Impact and Hospital Capacity by State Timeseries (RAW)) è scaricabile da healthdata.gov ed è composto da 135 colonne e oltre 60.000 righe. Il dataset viene aggiornato periodicamente.
Nelle sezioni seguenti, illustreremo come eseguire l’analisi esplorativa dei dati e la preparazione, creare il modello di previsione ML e generare previsioni utilizzando Canvas.
Esecuzione dell’analisi esplorativa dei dati e della preparazione
Quando si esegue una previsione di serie temporali in Canvas, è necessario ridurre il numero di caratteristiche o colonne in base alle quote di servizio. Inizialmente, riduciamo il numero di colonne a 12 che sono probabilmente le più rilevanti. Ad esempio, eliminiamo le colonne specifiche per età perché stiamo cercando di prevedere la domanda totale. Eliminiamo anche le colonne i cui dati sono simili ad altre colonne che abbiamo conservato. In future iterazioni, è ragionevole sperimentare con la conservazione di altre colonne e utilizzare l’esplicabilità delle caratteristiche in Canvas per quantificare l’importanza di queste caratteristiche e quali vogliamo conservare. Rinominiamo anche la colonna “state” in “location”.
Guardando il dataset, decidiamo anche di rimuovere tutte le righe per il 2020, poiché in quel periodo erano disponibili poche terapie. Questo ci permette di ridurre il rumore e migliorare la qualità dei dati su cui il modello ML deve apprendere.
La riduzione del numero di colonne può essere effettuata in modi diversi. È possibile modificare il dataset in un foglio di calcolo o direttamente all’interno di Canvas utilizzando l’interfaccia utente.
Puoi importare dati in Canvas da diverse fonti, inclusi file locali dal tuo computer, bucket di Amazon Simple Storage Service (Amazon S3), Amazon Athena, Snowflake (vedi Prepara set di dati di formazione e convalida per la classificazione delle facies utilizzando l’integrazione di Snowflake e addestra usando Amazon SageMaker Canvas) e oltre 40 altre fonti di dati.
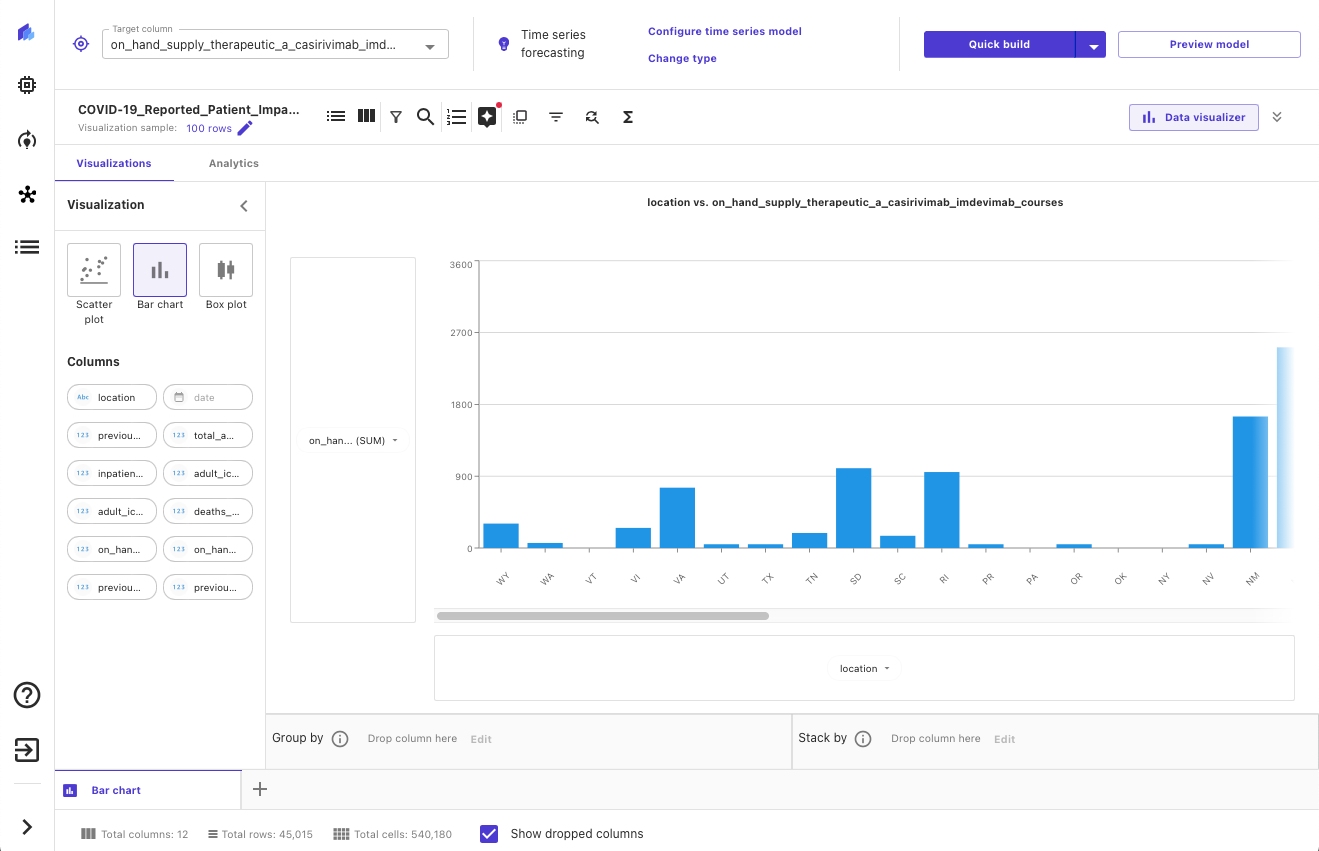
Dopo che i nostri dati sono stati importati, possiamo esplorarli e visualizzarli per ottenere ulteriori informazioni, ad esempio con scatterplot o grafici a barre. Esaminiamo anche la correlazione tra diverse caratteristiche per garantire di aver selezionato quelle che riteniamo essere le migliori. Lo screenshot seguente mostra un esempio di visualizzazione.
Costruisci il modello di previsione di machine learning
Ora siamo pronti per creare il nostro modello, che possiamo fare con pochi clic. Scegliamo la colonna che identifica le terapie disponibili come nostro obiettivo. Canvas identifica automaticamente il nostro problema come una previsione di serie temporale basata sulla colonna obiettivo appena selezionata e possiamo configurare i parametri necessari.
Configuriamo item_id, l’identificatore univoco, come posizione perché il nostro set di dati è fornito per posizione (stati degli Stati Uniti). Poiché stiamo creando una previsione di serie temporale, dobbiamo selezionare un timestamp, che è date nel nostro set di dati. Infine, specificiamo quanti giorni nel futuro vogliamo prevedere (per questo esempio, scegliamo 30 giorni). Canvas offre anche la possibilità di includere un calendario delle festività per migliorare l’accuratezza. In questo caso, utilizziamo le festività degli Stati Uniti perché si tratta di un set di dati basato negli Stati Uniti.
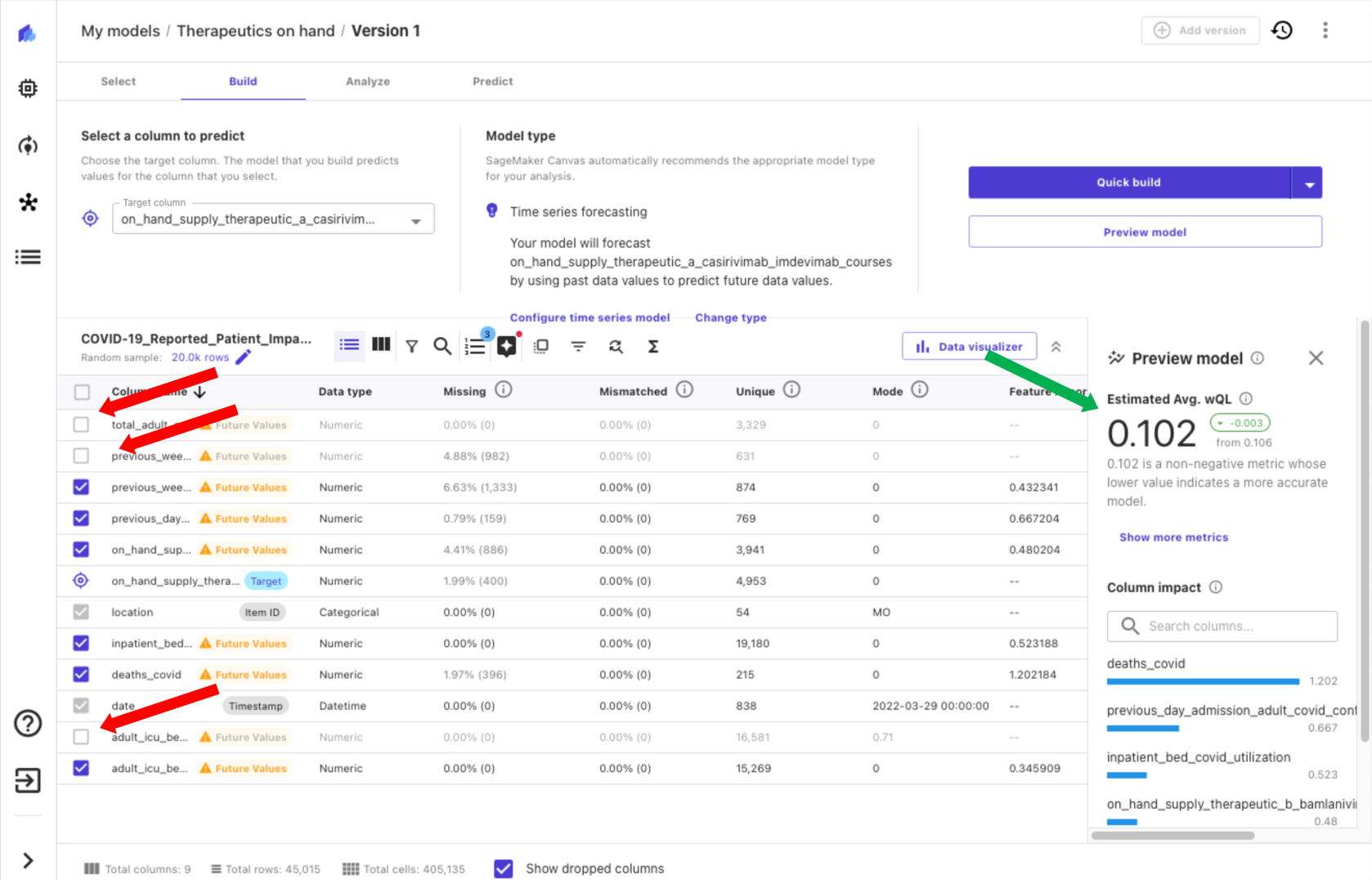
Con Canvas, puoi ottenere informazioni dai tuoi dati prima di costruire un modello scegliendo Anteprima modello. Questo ti fa risparmiare tempo e costi evitando di costruire un modello se i risultati sono improbabili che siano soddisfacenti. Previsualizzando il nostro modello, ci rendiamo conto che l’impatto di alcune colonne è basso, il che significa che il valore atteso della colonna per il modello è basso. Rimuoviamo le colonne deselezionandole in Canvas (frecce rosse nello screenshot seguente) e notiamo un miglioramento in una metrica di qualità stimata (flecha verde).
Passando alla costruzione del nostro modello, abbiamo due opzioni: Creazione rapida e Creazione standard. La creazione rapida produce un modello addestrato in meno di 20 minuti, privilegiando la velocità rispetto all’accuratezza. Questo è ottimo per sperimentazione ed è un modello più approfondito rispetto al modello di anteprima. La creazione standard produce un modello addestrato in meno di 4 ore, privilegiando l’accuratezza rispetto alla latenza, iterando attraverso una serie di configurazioni del modello per selezionare automaticamente il miglior modello.
Prima sperimentiamo con la creazione rapida per convalidare la nostra anteprima del modello. Poi, poiché siamo soddisfatti del modello, scegliamo la creazione standard per far sì che Canvas ci aiuti a costruire il modello migliore possibile per il nostro set di dati. Se il modello di creazione rapida avesse prodotto risultati insoddisfacenti, allora torneremmo indietro e regoleremmo i dati di input per ottenere un livello di accuratezza più alto. Potremmo farlo, ad esempio, aggiungendo o rimuovendo colonne o righe nel nostro set di dati originale. Il modello di creazione rapida supporta la sperimentazione rapida senza dover fare affidamento su risorse di data science scarse o attendere il completamento di un modello completo.
Genera previsioni
Ora che il modello è stato costruito, possiamo prevedere la disponibilità delle terapie per location. Vediamo come sarà il nostro inventario stimato disponibile per i prossimi 30 giorni, in questo caso per Washington, DC.
Canvas restituisce previsioni probabilistiche per la domanda di terapie, consentendoci di comprendere sia il valore mediano che i limiti superiori e inferiori. Nello screenshot seguente, puoi vedere la fine dei dati storici (i dati del set di dati originale). Puoi quindi vedere tre nuove linee: la previsione mediana (quantile 50esimo) in viola, il limite inferiore (quantile 10esimo) in azzurro chiaro e il limite superiore (quantile 90esimo) in blu scuro.
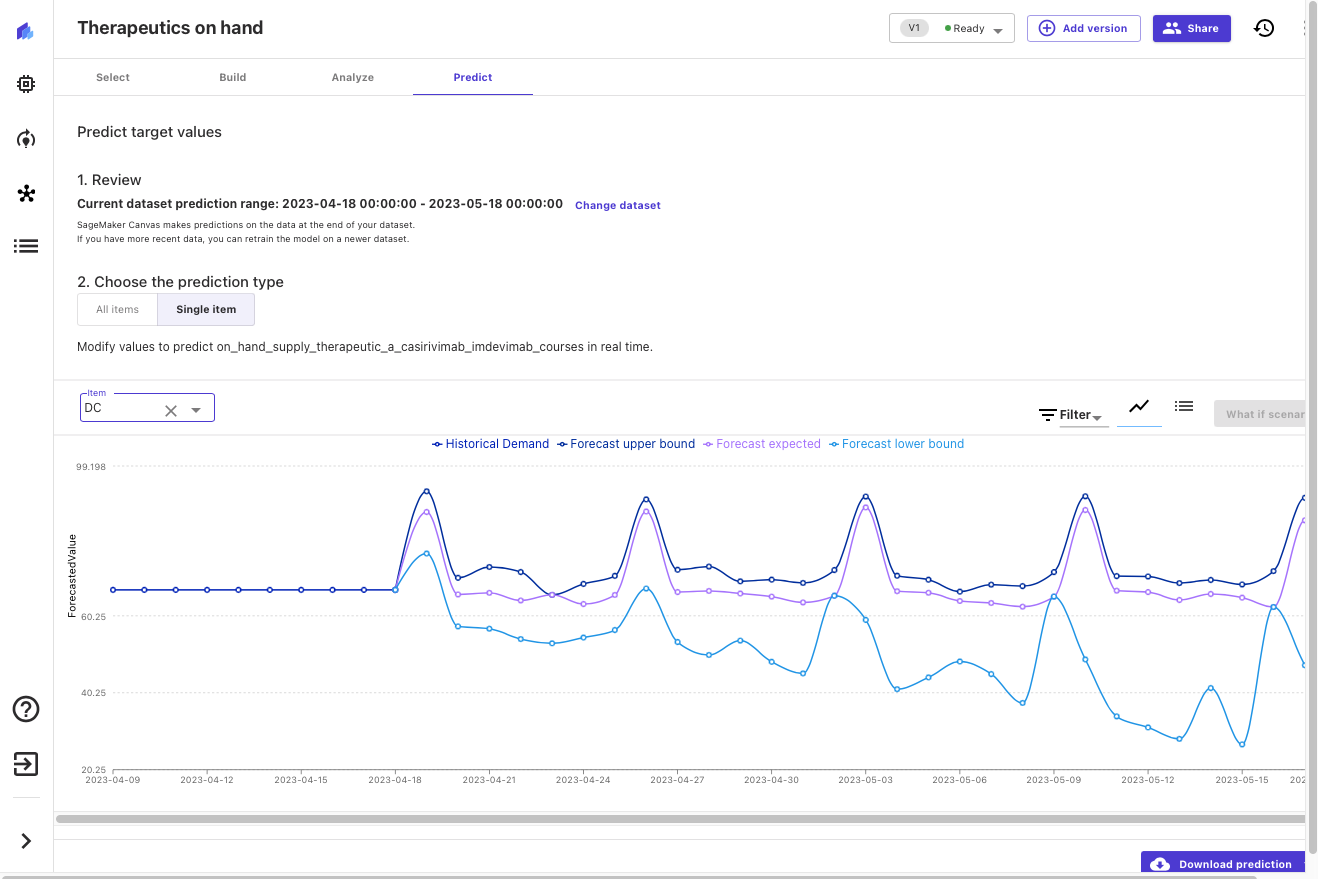
L’esame dei limiti superiori e inferiori fornisce una comprensione della distribuzione di probabilità delle previsioni e ci consente di prendere decisioni informate sui livelli desiderati di inventario locale per questo trattamento terapeutico. Possiamo aggiungere questa conoscenza ad altri dati (ad esempio, previsioni di progressione della malattia o efficacia terapeutica e adozione) per prendere decisioni informate su ordini futuri e livelli di inventario.
Conclusioni
Gli strumenti di machine learning senza codice consentono agli esperti di sanità pubblica di applicare rapidamente ed efficacemente il machine learning alle minacce per la salute pubblica. Questa democratizzazione del machine learning rende le organizzazioni di sanità pubblica più agili ed efficienti nella loro missione di proteggere la salute pubblica. Le analisi ad hoc che possono identificare importanti tendenze o punti di svolta nelle preoccupazioni per la salute pubblica possono ora essere eseguite direttamente dagli specialisti, senza dover competere per risorse limitate di esperti di machine learning e rallentare tempi di risposta e processi decisionali.
In questo post, abbiamo mostrato come una persona senza alcuna conoscenza di machine learning possa utilizzare Canvas per prevedere l’inventario disponibile di un determinato trattamento terapeutico. Questa analisi può essere eseguita da qualsiasi analista del settore, grazie alla potenza delle tecnologie cloud e del machine learning senza codice. In questo modo si distribuiscono ampiamente le capacità e si consente alle agenzie di sanità pubblica di essere più reattive e di utilizzare in modo più efficiente le risorse centralizzate e degli uffici sul campo per ottenere migliori risultati in materia di salute pubblica.
Che domande potresti farti e come possono aiutarti gli strumenti a basso/no codice a rispondere? Se sei interessato a saperne di più su Canvas, consulta Amazon SageMaker Canvas e inizia ad applicare il machine learning alle tue stesse domande quantitative sulla salute.






