Generazione sicura di immagini e modelli di diffusione con i servizi di moderazione dei contenuti di Amazon AI
'Sicura generazione di immagini e modelli di diffusione con i servizi di moderazione dei contenuti di Amazon AI'
La tecnologia AI generativa sta migliorando rapidamente ed è ora possibile generare testo e immagini basate su input di testo. Stable Diffusion è un modello di testo-immagine che ti permette di creare applicazioni fotorealistiche. Puoi facilmente generare immagini da testo utilizzando i modelli Stable Diffusion tramite Amazon SageMaker JumpStart.
Di seguito sono riportati esempi di testi di input e le corrispondenti immagini di output generate da Stable Diffusion. Gli input sono “Un pugile che balla su un tavolo”, “Una signora in costume da bagno sulla spiaggia, in stile acquerello” e “Un cane in un abito”.

Sebbene le soluzioni AI generative siano potenti e utili, possono essere vulnerabili alla manipolazione e all’abuso. I clienti che le utilizzano per la generazione di immagini devono dare la priorità alla moderazione dei contenuti per proteggere gli utenti, la piattaforma e il marchio, implementando pratiche di moderazione solide per creare un’esperienza utente sicura e positiva e preservare la reputazione del marchio e della piattaforma.
- Quanto sicuri sono i sistemi di autenticazione vocale?
- Un Ponte tra Diverse Criptovalute
- Incontra il nuovo strumento di intelligenza artificiale di Google per la prevenzione del riciclaggio di denaro nelle banche
In questo post, esploreremo l’utilizzo dei servizi AI di AWS Amazon Rekognition e Amazon Comprehend, insieme ad altre tecniche, per moderare in modo efficace il contenuto generato dal modello Stable Diffusion in tempo quasi reale. Per scoprire come lanciare e generare immagini da testo utilizzando un modello di Stable Diffusion su AWS, consulta Generare immagini da testo con il modello di diffusione stabile su Amazon SageMaker JumpStart.
Panoramica della soluzione
Amazon Rekognition e Amazon Comprehend sono servizi AI gestiti che forniscono modelli di ML pre-addestrati e personalizzabili tramite un’interfaccia API, eliminando la necessità di competenze in machine learning (ML). Amazon Rekognition Content Moderation automatizza e semplifica la moderazione di immagini e video. Amazon Comprehend utilizza l’ML per analizzare il testo e scoprire informazioni e relazioni preziose.
Il riferimento seguente illustra la creazione di un’API proxy RESTful per moderare immagini generate dal modello Stable Diffusion di testo-immagine quasi in tempo reale. In questa soluzione, abbiamo lanciato e distribuito un modello Stable Diffusion (base v2-1) utilizzando JumpStart. La soluzione utilizza prompt negativi e soluzioni di moderazione del testo come Amazon Comprehend e un filtro basato su regole per moderare gli input dei prompt. Utilizza inoltre Amazon Rekognition per moderare le immagini generate. L’API RESTful restituirà l’immagine generata e gli avvisi di moderazione al client se vengono rilevate informazioni non sicure.
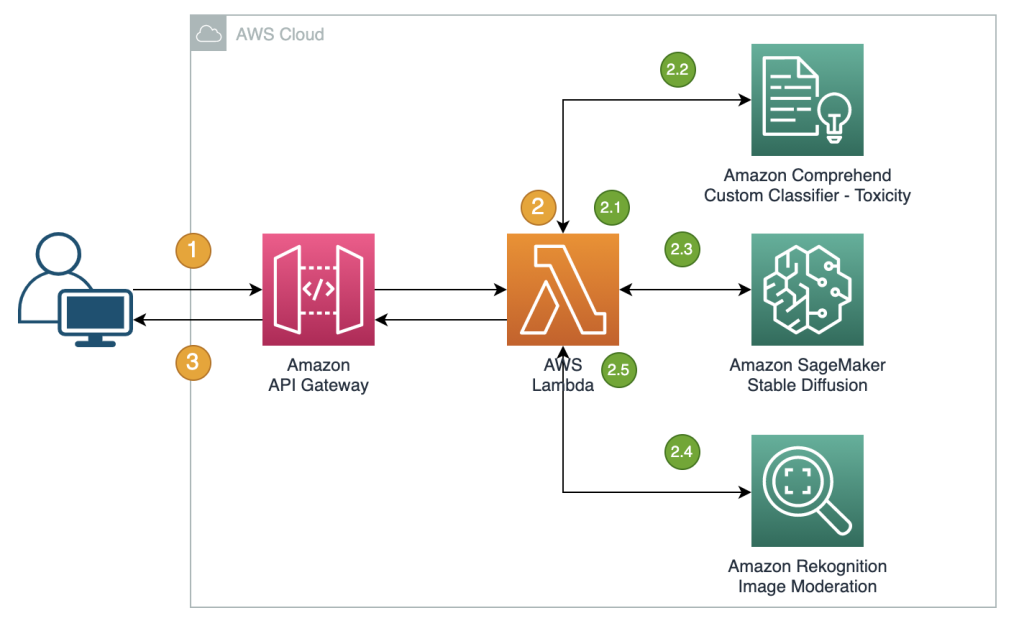
I passaggi del flusso di lavoro sono i seguenti:
- L’utente invia un prompt per generare un’immagine.
- Una funzione AWS Lambda coordina la generazione dell’immagine e la moderazione utilizzando Amazon Comprehend, JumpStart e Amazon Rekognition:
- Applica una condizione basata su regole ai prompt di input nelle funzioni Lambda, imponendo la moderazione dei contenuti con la rilevazione di parole vietate.
- Utilizza il classificatore personalizzato di Amazon Comprehend per analizzare il testo del prompt per la classificazione di tossicità.
- Invia il prompt al modello Stable Diffusion attraverso il punto di ingresso di SageMaker, passando sia i prompt come input utente che i prompt negativi da un elenco predefinito.
- Invia i byte dell’immagine restituiti dal punto di ingresso di SageMaker all’API Amazon Rekognition
DetectModerationLabelper la moderazione dell’immagine. - Costruisce un messaggio di risposta che include i byte dell’immagine e gli avvisi se i passaggi precedenti hanno rilevato informazioni inappropriate nel prompt o nell’immagine generata.
- Invia la risposta al client.
La seguente schermata mostra un’app di esempio creata utilizzando l’architettura descritta. L’interfaccia utente web invia prompt di input dell’utente all’API proxy RESTful e visualizza l’immagine e gli avvisi di moderazione ricevuti nella risposta. L’app demo sfoca l’immagine effettivamente generata se contiene contenuti non sicuri. Abbiamo testato l’app con il prompt di esempio “Una signora sexy”.
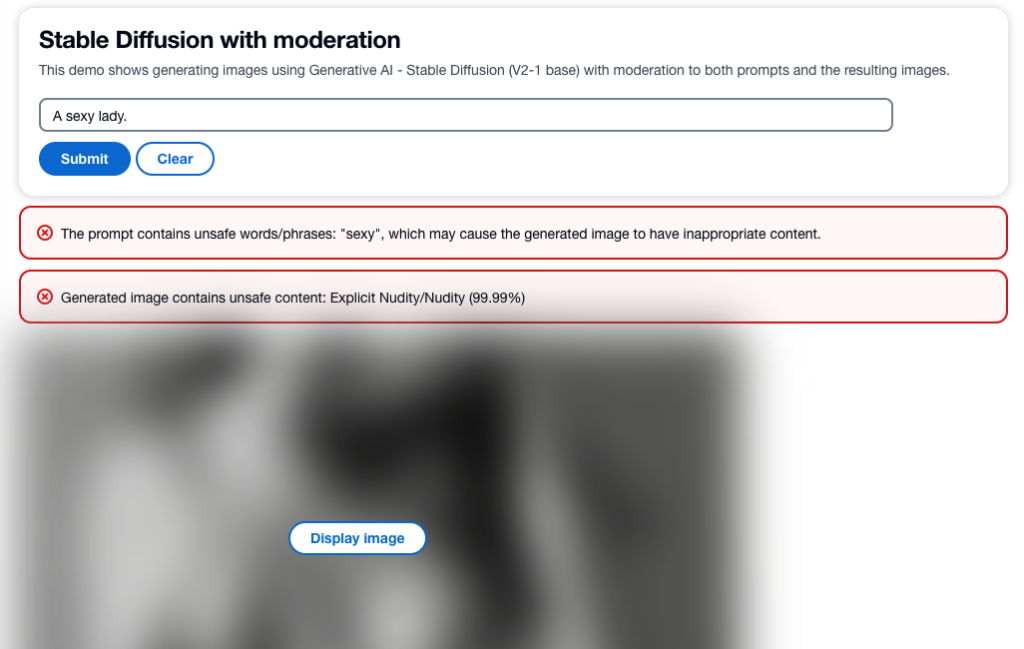
Puoi implementare logiche più sofisticate per un’esperienza utente migliore, come rifiutare la richiesta se i prompt contengono informazioni non sicure. Inoltre, potresti avere una politica di ripetizione per rigenerare l’immagine se il prompt è sicuro, ma l’output non lo è.
Predefinire una lista di prompt negativi
Stable Diffusion supporta i prompt negativi, che ti consente di specificare i prompt da evitare durante la generazione di immagini. Creare una lista predefinita di prompt negativi è un approccio pratico e proattivo per impedire al modello di produrre immagini non sicure. Includendo prompt come “naked”, “sexy” e “nudity”, che sono noti per portare a immagini inappropriate o offensive, il modello può riconoscerli ed evitarli, riducendo il rischio di generare contenuti non sicuri.
L’implementazione può essere gestita nella funzione Lambda durante la chiamata al punto di accesso SageMaker per eseguire l’infereza del modello Stable Diffusion, passando sia i prompt dall’input dell’utente che i prompt negativi da una lista predefinita.
Sebbene questo approccio sia efficace, potrebbe influire sui risultati generati dal modello Stable Diffusion e limitarne la funzionalità. È importante considerarlo come una delle tecniche di moderazione, combinata ad altri approcci come la moderazione del testo e delle immagini usando Amazon Comprehend e Amazon Rekognition.
Moderare i prompt di input
Un approccio comune alla moderazione del testo consiste nell’utilizzare un metodo di ricerca basato su parole chiave per identificare se il testo di input contiene parole o frasi vietate da una lista predefinita. Questo metodo è relativamente facile da implementare, con un impatto sulle prestazioni minimo e costi ridotti. Tuttavia, il principale svantaggio di questo approccio è che è limitato solo alla rilevazione di parole incluse nella lista predefinita e non può rilevare nuove o variazioni modificate di parole vietate non incluse nell’elenco. Gli utenti possono anche cercare di aggirare le regole utilizzando grafie alternative o caratteri speciali per sostituire le lettere.
Per affrontare le limitazioni di una moderazione del testo basata su regole, molte soluzioni hanno adottato un approccio ibrido che combina la ricerca basata su parole chiave con la rilevazione della tossicità basata su ML. La combinazione di entrambi gli approcci consente una soluzione di moderazione del testo più completa ed efficace, in grado di rilevare un’ampia gamma di contenuti inappropriati e migliorare l’accuratezza dei risultati di moderazione.
In questa soluzione, utilizziamo un classificatore personalizzato Amazon Comprehend per addestrare un modello di rilevamento della tossicità, che utilizziamo per rilevare contenuti potenzialmente dannosi nei prompt di input nei casi in cui non vengono rilevate parole vietate esplicite. Con il potere dell’apprendimento automatico, possiamo insegnare al modello a riconoscere modelli nel testo che possono indicare tossicità, anche quando tali modelli non sono facilmente rilevabili tramite un approccio basato su regole.
Con Amazon Comprehend come servizio IA gestito, l’addestramento e l’inferenza sono semplificati. Puoi facilmente addestrare e distribuire la classificazione personalizzata di Amazon Comprehend con solo due passaggi. Dai un’occhiata al nostro laboratorio di workshop per ulteriori informazioni sul modello di rilevamento della tossicità utilizzando un classificatore personalizzato di Amazon Comprehend. Il laboratorio fornisce una guida passo passo per creare e integrare un classificatore personalizzato di tossicità nella tua applicazione. Il diagramma seguente illustra questa architettura di soluzione.
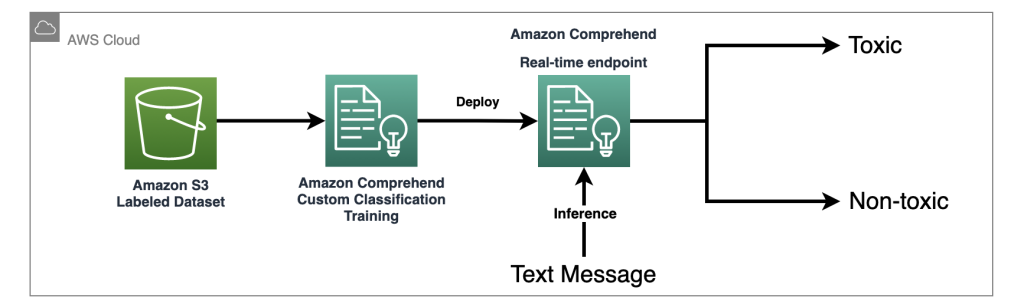
Questo classificatore di esempio utilizza un set di dati di addestramento dei social media e effettua una classificazione binaria. Tuttavia, se hai requisiti più specifici per le tue esigenze di moderazione del testo, considera l’utilizzo di un set di dati più personalizzato per addestrare il tuo classificatore personalizzato di Amazon Comprehend.
Moderare le immagini di output
Sebbene la moderazione dei prompt di testo di input sia importante, non garantisce che tutte le immagini generate dal modello Stable Diffusion siano sicure per il pubblico previsto, poiché le uscite del modello possono contenere un certo livello di casualità. Pertanto, è altrettanto importante moderare le immagini generate dal modello Stable Diffusion.
In questa soluzione, utilizziamo Amazon Rekognition Content Moderation, che utilizza modelli di apprendimento automatico preaddestrati, per rilevare contenuti inappropriati in immagini e video. In questa soluzione, utilizziamo l’API Amazon Rekognition DetectModerationLabel per moderare le immagini generate dal modello Stable Diffusion in tempo quasi reale. Amazon Rekognition Content Moderation fornisce API preaddestrate per analizzare una vasta gamma di contenuti inappropriati o offensivi, come violenza, nudità, simboli di odio e altro ancora. Per una lista completa delle tassonomie di moderazione dei contenuti di Amazon Rekognition Content Moderation, consulta la moderazione dei contenuti .
Il seguente codice illustra come chiamare l’API Amazon Rekognition DetectModerationLabel per moderare le immagini all’interno di una funzione Lambda utilizzando la libreria Python Boto3. Questa funzione prende i byte dell’immagine restituiti da SageMaker e li invia all’API di moderazione delle immagini.
import boto3
# Inizializza l'oggetto client Amazon Rekognition
rekognition = boto3.client('rekognition')
# Chiama l'API di moderazione immagine di Rekognition e memorizza i risultati
response = rekognition.detect_moderation_labels(
Image={
'Bytes': base64.b64decode(img_bytes)
}
)
# Stampa la risposta dell'API
print(response)Per ulteriori esempi dell’API di Moderazione Immagini di Amazon Rekognition, consulta il nostro Laboratorio Immagini Moderazione Contenuti.
Tecniche efficaci di moderazione delle immagini per il fine-tuning dei modelli
Il fine-tuning è una tecnica comune utilizzata per adattare modelli pre-addestrati a compiti specifici. Nel caso di Stable Diffusion, il fine-tuning può essere utilizzato per generare immagini che incorporano oggetti, stili e personaggi specifici. La moderazione dei contenuti è fondamentale durante la formazione di un modello Stable Diffusion per prevenire la creazione di immagini inappropriati o offensive. Ciò comporta la revisione e il filtraggio attento di eventuali dati che potrebbero portare alla generazione di tali immagini. In questo modo, il modello apprende da una serie di dati più diversificata e rappresentativa, migliorandone l’accuratezza e prevenendo la diffusione di contenuti dannosi.
JumpStart semplifica il fine-tuning del modello Stable Diffusion fornendo gli script di trasferimento di apprendimento utilizzando il metodo DreamBooth. Devi solo preparare i tuoi dati di addestramento, definire gli iperparametri e avviare il processo di addestramento. Per ulteriori dettagli, consulta Fine-tune text-to-image Stable Diffusion models with Amazon SageMaker JumpStart.
Il dataset per il fine-tuning deve essere una singola directory di Amazon Simple Storage Service (Amazon S3) che include le immagini e il file di configurazione dell’istanza dataset_info.json, come mostrato nel codice seguente. Il file JSON associa le immagini con l’istanza di prompt in questo modo: {'instance_prompt':<<instance_prompt>>}.
input_directory
|---instance_image_1.png
|---instance_image_2.png
|---instance_image_3.png
|---instance_image_4.png
|---instance_image_5.png
|---dataset_info.jsonOvviamente, puoi revisionare e filtrare manualmente le immagini, ma ciò può richiedere tempo e persino essere impraticabile quando lo fai su larga scala su molti progetti e team. In tali casi, puoi automatizzare un processo batch per controllare centralmente tutte le immagini utilizzando l’API Amazon Rekognition DetectModerationLabel e contrassegnare o rimuovere automaticamente le immagini in modo che non contaminino il tuo addestramento.
Latency e costo della moderazione
In questa soluzione, viene utilizzato un pattern sequenziale per moderare testo e immagini. Viene chiamata una funzione basata su regole e Amazon Comprehend per la moderazione del testo, e Amazon Rekognition viene utilizzato per la moderazione delle immagini, sia prima che dopo l’invocazione di Stable Diffusion. Sebbene questo approccio moderi efficacemente i prompt di input e le immagini di output, potrebbe aumentare il costo complessivo e la latenza della soluzione, cosa da considerare.
Latency
Sia Amazon Rekognition che Amazon Comprehend offrono API gestite che sono altamente disponibili e hanno una scalabilità integrata. Nonostante le potenziali variazioni di latenza dovute alla dimensione dell’input e alla velocità della rete, le API utilizzate in questa soluzione da entrambi i servizi offrono inference quasi in tempo reale. Gli endpoint dei classificatori personalizzati di Amazon Comprehend possono offrire una velocità inferiore a 200 millisecondi per dimensioni di testo di input inferiori a 100 caratteri, mentre l’API di Moderazione Immagini di Amazon Rekognition serve circa 500 millisecondi per dimensioni dei file medie inferiori a 1 MB. (I risultati si basano sul test condotto utilizzando l’applicazione di esempio, che soddisfa i requisiti quasi in tempo reale.)
Nel complesso, le chiamate alle API di moderazione di Amazon Rekognition e Amazon Comprehend aggiungeranno 700 millisecondi alla chiamata API. È importante notare che la richiesta di Stable Diffusion di solito richiede più tempo a seconda della complessità dei prompt e della capacità dell’infrastruttura sottostante. Nel conto di test, utilizzando un tipo di istanza di ml.p3.2xlarge, il tempo di risposta medio per il modello Stable Diffusion tramite un endpoint SageMaker era di circa 15 secondi. Pertanto, la latenza introdotta dalla moderazione è approssimativamente il 5% del tempo di risposta complessivo, rappresentando un impatto minimo sulle prestazioni complessive del sistema.
Costo
Amazon Rekognition Image Moderation API utilizza un modello di pagamento in base al consumo in base al numero di richieste. Il costo varia a seconda della regione AWS utilizzata e segue una struttura di prezzi a tier. Man mano che il volume delle richieste aumenta, il costo per richiesta diminuisce. Per ulteriori informazioni, consulta Amazon Rekognition pricing.
In questa soluzione, abbiamo utilizzato un classificatore personalizzato di Amazon Comprehend e lo abbiamo distribuito come endpoint di Amazon Comprehend per facilitare l’inference in tempo reale. Questa implementazione comporta sia un costo di addestramento unico che costi di inference continui. Per informazioni dettagliate, consulta Amazon Comprehend Pricing.
Jumpstart ti consente di lanciare e distribuire rapidamente il modello Stable Diffusion come un pacchetto singolo. L’esecuzione dell’inference sul modello Stable Diffusion comporterà costi per l’istanza sottostante di Amazon Elastic Compute Cloud (Amazon EC2) così come per il trasferimento dei dati in ingresso e in uscita. Per informazioni dettagliate, consulta Amazon SageMaker Pricing.
Sommario
In questo post, abbiamo fornito una panoramica di una soluzione di esempio che mostra come moderare le prompt di input e le immagini di output di Stable Diffusion utilizzando Amazon Comprehend e Amazon Rekognition. Inoltre, è possibile definire prompt negativi in Stable Diffusion per evitare la generazione di contenuti non sicuri. Implementando più livelli di moderazione, il rischio di produrre contenuti non sicuri può essere notevolmente ridotto, garantendo un’esperienza utente più sicura e affidabile.
Scopri di più sulla moderazione dei contenuti su AWS e sui nostri casi d’uso di moderazione dei contenuti basati su machine learning e compi il primo passo verso una razionalizzazione delle operazioni di moderazione dei tuoi contenuti con AWS.






