Costruisci una ChatGPT per i video di YouTube con Langchain.
Build a ChatGPT for YouTube videos with Langchain.
Introduzione
Ti sei mai chiesto quanto sarebbe bello chattare con un video? Come blogger, a volte mi annoia guardare un video di un’ora per trovare informazioni rilevanti. A volte sembra un lavoro guardare un video per ottenere informazioni utili. Quindi ho creato un chatbot che ti permette di chattare con i video di YouTube o qualsiasi altro video. Questo è stato reso possibile da GPT-3.5-turbo, Langchain, ChromaDB, Whisper e Gradio. In questo articolo, farò una panoramica del codice per costruire un chatbot funzionale per i video di YouTube con Langchain.
Obiettivi di apprendimento
- Costruire l’interfaccia web utilizzando Gradio
- Gestire i video di YouTube e estrarre dati testuali da essi utilizzando Whisper
- Elaborare e formattare correttamente i testi
- Creare embedding dei dati testuali
- Configurare Chroma DB per archiviare i dati
- Inizializzare una catena di conversazione Langchain con OpenAI chatGPT, ChromaDB e la funzione di embedding
- Infine, interrogare e trasmettere risposte al chatbot Gradio
Prima di passare alla parte di codifica, familiarizziamo con gli strumenti e le tecnologie che useremo.
Questo articolo è stato pubblicato come parte del Data Science Blogathon.
Langchain
Langchain è uno strumento open-source scritto in Python che rende i grandi modelli di linguaggio consapevoli dei dati e agenti. Quindi, cosa significa davvero? La maggior parte dei modelli di linguaggio commercialmente disponibili, come GPT-3.5 e GPT-4, ha un limite sui dati su cui sono addestrati. Ad esempio, ChatGPT può rispondere solo alle domande che ha già visto. Tutto ciò che è successo dopo settembre 2021 è sconosciuto. Questo è il problema principale che Langchain risolve. Che si tratti di un documento di Word o di qualsiasi PDF personale, possiamo alimentare i dati in un LLM e ottenere una risposta simile a quella umana. Ha wrapper per strumenti come Vector DB, modelli di chat e funzioni di embedding, che rendono facile costruire un’applicazione di intelligenza artificiale utilizzando solo Langchain.
- Come Earth.com e Provectus hanno implementato la loro infrastruttura MLOps con Amazon SageMaker
- Utilizzare modelli di base proprietari da Amazon SageMaker JumpStart in Amazon SageMaker Studio.
- A.I. potrebbe un giorno compiere miracoli medici. Per ora, aiuta a sbrigare la burocrazia.

Langchain ci consente anche di costruire Agenti – bot LLM. Questi agenti autonomi possono essere configurati per molteplici compiti, tra cui l’analisi dei dati, la query SQL e persino la scrittura di codici di base. Ci sono molte cose che possiamo automatizzare utilizzando questi agenti. Questo è utile poiché possiamo esternalizzare il lavoro di conoscenza a basso livello a un LLM, risparmiando tempo ed energia.
In questo progetto, useremo gli strumenti Langchain per creare un’app di chat per i video. Per ulteriori informazioni su Langchain, visita il loro sito ufficiale.
Whisper
Whisper è un’altra progenie di OpenAI. È un modello di riconoscimento vocale generale che può convertire audio o video in testo. È addestrato su una grande quantità di audio diversi per eseguire la traduzione multilingue, il riconoscimento vocale e la classificazione.
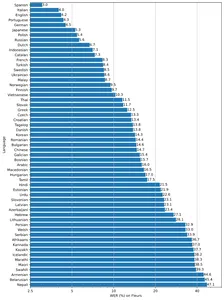
Il modello è disponibile in cinque diverse dimensioni: piccola, base, Nisoo, small e large, con compromessi tra velocità e precisione. Le prestazioni dei modelli dipendono anche dalla lingua. La figura seguente mostra una suddivisione WER (Word Error Rate) per lingue del dataset di Fleur utilizzando il modello large-v2.
Database a vettori
La maggior parte degli algoritmi di apprendimento automatico non può elaborare dati grezzi e non strutturati come immagini, audio, video e testi. Devono essere convertiti in matrici di embedding vettoriali. Questi embedding vettoriali rappresentano i dati in un piano multidimensionale. Per ottenere gli embedding, abbiamo bisogno di modelli di deep learning altamente efficienti capaci di catturare il significato semantico dei dati. Questo è molto importante per creare qualsiasi app di intelligenza artificiale. Per archiviare e interrogare questi dati, abbiamo bisogno di database capaci di gestirli in modo efficace. Ciò ha portato alla creazione di database specializzati chiamati database a vettori. Ci sono molti database open-source tra cui scegliere. Chroma, Milvus, Weaviate e FAISS sono tra i più popolari.
Un’altra caratteristica distintiva dei database a vettori è che possiamo eseguire operazioni di ricerca ad alta velocità sui dati non strutturati. Una volta ottenuti gli embedding, possiamo usarli per il clustering, la ricerca, la classificazione e il sorting. Poiché i punti dati si trovano in uno spazio vettoriale, possiamo calcolare la distanza tra di essi per sapere quanto sono strettamente correlati. Vengono utilizzati più algoritmi come la similarità coseno, la distanza euclidea, KNN e ANN (Approximate Nearest Neighbour) per trovare punti dati simili.
Useremo Chroma vector store – un database a vettori open-source. Chroma ha anche l’integrazione di Langchain, che sarà molto utile.
Gradio
Il quarto cavaliere della nostra app Gradio è una libreria open-source per condividere facilmente modelli di machine learning. Può anche aiutare a costruire app web demo con i suoi componenti ed eventi con Python.
Se non sei familiare con Gradio e Langchain, leggi i seguenti articoli prima di procedere.
- Costruiamo ChatGPT con Gradio
- Costruisci un ChatGPT per PDF
Cominciamo ora a costruirlo.
Impostare l’ambiente di sviluppo
Per impostare l’ambiente di sviluppo, crea un ambiente virtuale Python o crea un ambiente di sviluppo locale con Docker.
Ora installa tutte queste dipendenze
pytube==15.0.0
gradio == 3.27.0
openai == 0.27.4
langchain == 0.0.148
chromadb == 0.3.21
tiktoken == 0.3.3
openai-whisper==20230314Importare librerie
import os
import tempfile
import whisper
import datetime as dt
import gradio as gr
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from pytube import YouTube
from typing import TYPE_CHECKING, Any, Generator, ListCreare l’interfaccia web
Useremo i blocchi e i componenti di Gradio per costruire il front-end della nostra applicazione. Quindi, ecco come puoi creare l’interfaccia. Sentiti libero di personalizzare come preferisci.
with gr.Blocks() as demo:
with gr.Row():
# with gr.Group():
with gr.Column(scale=0.70):
api_key = gr.Textbox(placeholder='Inserisci la chiave API di OpenAI',
show_label=False, interactive=True).style(container=False)
with gr.Column(scale=0.15):
change_api_key = gr.Button('Cambia chiave')
with gr.Column(scale=0.15):
remove_key = gr.Button('Rimuovi chiave')
with gr.Row():
with gr.Column():
chatbot = gr.Chatbot(value=[]).style(height=650)
query = gr.Textbox(placeholder='Inserisci la query qui',
show_label=False).style(container=False)
with gr.Column():
video = gr.Video(interactive=True,)
start_video = gr.Button('Inizia trascrizione')
gr.HTML('O')
yt_link = gr.Textbox(placeholder='Incolla qui un link di YouTube',
show_label=False).style(container=False)
yt_video = gr.HTML(label=True)
start_ytvideo = gr.Button('Inizia trascrizione')
gr.HTML('Ripristina l\'app dopo averla usata per rimuovere le risorse')
reset = gr.Button('Ripristina app')
if __name__ == "__main__":
demo.launch() L’interfaccia apparirà così
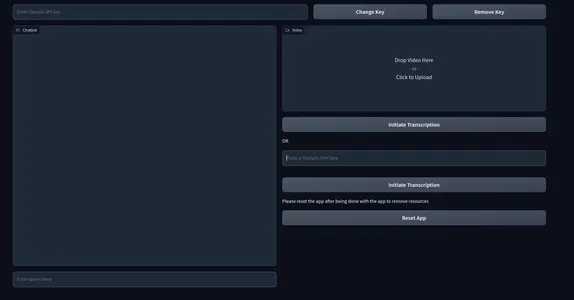
Qui abbiamo una casella di testo che prende la chiave OpenAI in input. E anche due chiavi per cambiare la chiave API e cancellare la chiave. Abbiamo anche un’interfaccia di chat a sinistra e una casella per la riproduzione di video locali a destra. Subito sotto la casella del video, abbiamo una casella che chiede un link di YouTube e pulsanti che dicono “Inizia trascrizione”.
Eventi di Gradio
Ora definiremo gli eventi per rendere l’app interattiva. Aggiungi i seguenti codici alla fine di gr.Blocks().
start_video.click(fn=lambda :(pause, update_yt),
outputs=[start2, yt_video]).then(
fn=embed_video, inputs=
,
outputs=
).success(
fn=lambda:resume,
outputs=[start2])
start_ytvideo.click(fn=lambda :(pause, update_video),
outputs=[start1,video]).then(
fn=embed_yt, inputs=[yt_link],
outputs = [yt_video, chatbot]).success(
fn=lambda:resume, outputs=[start1])
query.submit(fn=add_text, inputs=[chatbot, query],
outputs=[chatbot]).success(
fn=QuestionAnswer,
inputs=[chatbot,query,yt_link,video],
outputs=[chatbot,query])
api_key.submit(fn=set_apikey, inputs=api_key, outputs=api_key)
change_api_key.click(fn=enable_api_box, outputs=api_key)
remove_key.click(fn = remove_key_box, outputs=api_key)
reset.click(fn = reset_vars, outputs=[chatbot,query, video, yt_video, ])- start_video: Quando viene cliccato, attiva il processo di ottenere i testi dal video e crea una catena conversazionale.
- start_ytvideo: Quando viene cliccato, fa la stessa cosa, ma ora dal video di YouTube, e quando è completato, renderizza il video di YouTube appena sotto di esso.
- query: Responsabile per lo streaming della risposta da LLM all’interfaccia utente della chat.
Il resto degli eventi sono per gestire la chiave API e ripristinare l’app.
Abbiamo definito gli eventi ma non abbiamo definito le funzioni responsabili per attivare gli eventi.
Backend
Per non renderlo complicato e disordinato, delineeremo i processi con cui tratteremo nel backend.
- Gestire le chiavi API.
- Gestire il video caricato.
- Trascrivere i video per ottenere i testi.
- Creare dei pezzi di testi video.
- Creare gli embeddings dai testi.
- Memorizzare gli embeddings dei vettori nel ChromaDB vector store.
- Creare una catena di recupero conversazionale con Langchain.
- Inviare i documenti pertinenti al modello di chat OpenAI (gpt-3.5-turbo).
- Recuperare la risposta e trasmetterla nell’interfaccia utente della chat.
Faremo tutte queste cose insieme a una gestione delle eccezioni.
Definire alcune variabili d’ambiente.
chat_history = []
result = None
chain = None
run_once_flag = False
call_to_load_video = 0
enable_box = gr.Textbox.update(value=None,placeholder= 'Carica la tua chiave API OpenAI',
interactive=True)
disable_box = gr.Textbox.update(value = 'La chiave API OpenAI è impostata',interactive=False)
remove_box = gr.Textbox.update(value = 'La tua chiave API è stata rimossa con successo',
interactive=False)
pause = gr.Button.update(interactive=False)
resume = gr.Button.update(interactive=True)
update_video = gr.Video.update(value = None)
update_yt = gr.HTML.update(value=None) Gestire le Chiavi API
Quando un utente invia una chiave, viene impostata come variabile d’ambiente e disabilitiamo anche la casella di testo dall’ulteriore input. Premendo il pulsante di cambio chiave lo renderà di nuovo mutabile. Cliccando sul pulsante di rimozione rimuoveremo la chiave.
enable_box = gr.Textbox.update(value=None,placeholder= 'Carica la tua chiave API OpenAI',
interactive=True)
disable_box = gr.Textbox.update(value = 'La chiave API OpenAI è impostata',interactive=False)
remove_box = gr.Textbox.update(value = 'La tua chiave API è stata rimossa con successo',
interactive=False)
def set_apikey(api_key):
os.environ['OPENAI_API_KEY'] = api_key
return disable_box
def enable_api_box():
return enable_box
def remove_key_box():
os.environ['OPENAI_API_KEY'] = ''
return remove_boxGestire i Video
Successivamente, tratteremo i video caricati e i collegamenti di YouTube. Avremo due diverse funzioni che si occupano di ogni caso. Per i collegamenti di YouTube, creeremo un collegamento di embed iframe. In entrambi i casi, chiameremo un’altra funzione make_chain() responsabile per la creazione delle catene.
Queste funzioni vengono attivate quando qualcuno carica un video o fornisce un collegamento di YouTube e preme il pulsante di trascrizione.
def embed_yt(yt_link: str):
# Questa funzione incorpora un video di YouTube nella pagina.
# Controlla se il collegamento di YouTube è valido.
if not yt_link:
raise gr.Error('Incolla un collegamento di YouTube')
# Imposta la variabile globale `run_once_flag` su False.
# Questo viene utilizzato per impedire che la funzione venga chiamata più di una volta.
run_once_flag = False
# Imposta la variabile globale `call_to_load_video` su 0.
# Questo viene utilizzato per tenere traccia di quante volte la funzione è stata chiamata.
call_to_load_video = 0
# Crea una catena utilizzando il collegamento di YouTube.
make_chain(url=yt_link)
# Ottieni l'URL del video di YouTube.
url = yt_link.replace('watch?v=', '/embed/')
# Crea il codice HTML per il video di YouTube incorporato.
embed_html = f"""<iframe width="750" height="315" src="{url}"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write;
encrypted-media; gyroscope; picture-in-picture"
allowfullscreen></iframe>"""
# Restituisce il codice HTML e una lista vuota.
return embed_html, []
def embed_video(video=str | None):
# Questa funzione incorpora un video nella pagina.
# Controlla se il video è valido.
if not video:
raise gr.Error('Carica un video')
# Imposta la variabile globale `run_once_flag` su False.
# Questo viene utilizzato per impedire che la funzione venga chiamata più di una volta.
run_once_flag = False
# Crea una catena utilizzando il video.
make_chain(video=video)
# Restituisci il video e una lista vuota.
return video, []Creazione Catena
Questa è una delle fasi più importanti di tutte. Ciò comporta la creazione di uno store di vettori Chroma e di una catena Langchain. Utilizzeremo una catena di recupero conversazionale per il nostro caso d’uso. Utilizzeremo i embedding di OpenAI, ma per le implementazioni effettive, utilizziamo modelli di embedding gratuiti come gli encoder di frasi di Huggingface, ecc.
def make_chain(url=None, video=None) -> (ConversationalRetrievalChain | Any | None):
global chain, run_once_flag
# Verifica se è stato fornito un collegamento YouTube o un video
if not url and not video:
raise gr.Error('Fornisci un collegamento YouTube o carica un video')
if not run_once_flag:
run_once_flag = True
# Ottieni il titolo dal collegamento YouTube o dal video
title = get_title(url, video).replace(' ','-')
# Elabora il testo dal video
grouped_texts, time_list = process_text(url=url) if url else process_text(video=video)
# Converti time_list in formato di metadati
time_list = [{'source': str(t.time())} for t in time_list]
# Crea gli store di vettori dai testi elaborati con i metadati
vector_stores = Chroma.from_texts(texts=grouped_texts, collection_name='test',
embedding=OpenAIEmbeddings(),
metadatas=time_list)
# Crea una ConversationalRetrievalChain dagli store di vettori
chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.0),
retriever=
vector_stores.as_retriever(
search_kwargs={"k": 5}),
return_source_documents=True)
return chain- Ottieni testi e metadati da un collegamento YouTube o da un file video.
- Crea uno store di vettori Chroma dai testi e dai metadati.
- Crea una catena utilizzando OpenAI gpt-3.5-turbo e lo store di vettori Chroma.
- Ritorna la catena.
Elaborazione Testi
In questa fase, effettueremo un’adeguata suddivisione dei testi da video e creeremo anche l’oggetto di metadati che abbiamo utilizzato nel processo di creazione della catena sopra.
def process_text(video=None, url=None) -> tuple[list, list[dt.datetime]]:
global call_to_load_video
if call_to_load_video == 0:
print('yes')
# Chiama la funzione process_video in base al video o all'URL dati
result = process_video(url=url) if url else process_video(video=video)
call_to_load_video += 1
texts, start_time_list = [], []
# Estrarre il testo e l'ora di inizio da ogni segmento nel risultato
for res in result['segments']:
start = res['start']
text = res['text']
start_time = dt.datetime.fromtimestamp(start)
start_time_formatted = start_time.strftime("%H:%M:%S")
texts.append(''.join(text))
start_time_list.append(start_time_formatted)
texts_with_timestamps = dict(zip(texts, start_time_list))
# Converti le stringhe di timestamp in oggetti datetime
formatted_texts = {
text: dt.datetime.strptime(str(timestamp), '%H:%M:%S')
for text, timestamp in texts_with_timestamps.items()
}
grouped_texts = []
current_group = ''
time_list = [list(formatted_texts.values())[0]]
previous_time = None
time_difference = dt.timedelta(seconds=30)
# Raggruppare i testi in base alla differenza di tempo
for text, timestamp in formatted_texts.items():
if previous_time is None or timestamp - previous_time <= time_difference:
current_group += text
else:
grouped_texts.append(current_group)
time_list.append(timestamp)
current_group = text
previous_time = time_list[-1]
# Aggiungi l'ultimo gruppo di testi
if current_group:
grouped_texts.append(current_group)
return grouped_texts, time_list- La funzione process_text richiede un URL o un percorso video. Questo video viene quindi trascritto nella funzione process_video e otteniamo i testi finali.
- Successivamente, otteniamo l’ora di inizio di ogni frase (da Whisper) e li raggruppiamo in 30 secondi.
- Infine, restituiamo i testi raggruppati e l’ora di inizio di ogni gruppo.
Elaborazione Video
In questa fase, trascriviamo i file video o audio e otteniamo i testi. Utilizzeremo il modello base Whisper per la trascrizione.
def process_video(video=None, url=None) -> dict[str, str | list]:
if url:
file_dir = load_video(url)
else:
file_dir = video
print('Trascrizione video con il modello base di Whisper')
model = whisper.load_model("base")
result = model.transcribe(file_dir)
return resultPer i video di YouTube, poiché non possiamo elaborarli direttamente, dovremo gestirli separatamente. Utilizzeremo una libreria chiamata Pytube per scaricare l’audio o il video del video di YouTube. Ecco come puoi farlo.
def load_video(url: str) -> str:
# Questa funzione scarica un video di YouTube e restituisce il percorso del file scaricato.
# Crea un oggetto YouTube per l'URL fornito.
yt = YouTube(url)
# Ottieni la directory di destinazione.
target_dir = os.path.join('/tmp', 'Youtube')
# Se la directory di destinazione non esiste, creala.
if not os.path.exists(target_dir):
os.mkdir(target_dir)
# Ottieni lo stream audio del video.
stream = yt.streams.get_audio_only()
# Scarica lo stream audio nella directory di destinazione.
print('----DOWNLOADING AUDIO FILE----')
stream.download(output_path=target_dir)
# Ottieni il percorso del file scaricato.
path = target_dir + '/' + yt.title + '.mp4'
# Restituisci il percorso del file scaricato.
return path- Crea un oggetto YouTube per l’URL fornito.
- Crea un percorso temporaneo della directory di destinazione
- Verifica se il percorso esiste altrimenti crea la directory
- Scarica l’audio del file.
- Ottieni la directory del video
Questo è stato il processo bottom-up per ottenere testi dai video e creare la catena. Ora, tutto ciò che resta è configurare il chatbot.
Configura il Chatbot
Tutto ciò di cui abbiamo bisogno ora è inviare una query e una chat_history per recuperare le nostre risposte. Quindi, definiremo una funzione che si attiva solo quando viene inviata una query.
def add_text(history, text):
if not text:
raise gr.Error('inserisci il testo')
history = history + [(text,'')]
return history
def QuestionAnswer(history, query=None, url=None, video=None) -> Generator[Any | None, Any, None]:
# Questa funzione risponde a una domanda utilizzando una catena di modelli.
# Verifica se viene fornito un link YouTube o un file video locale.
if video and url:
# Solleva un errore se vengono forniti sia un link YouTube che un file video locale.
raise gr.Error('Carica un video o un link YouTube, non entrambi')
elif not url and not video:
# Solleva un errore se non viene fornito alcun input.
raise gr.Error('Fornisci un link YouTube o carica un video')
# Ottieni il risultato dell'elaborazione del video.
result = chain({"question": query, 'chat_history': chat_history}, return_only_outputs=True)
# Aggiungi la domanda e la risposta alla cronologia della chat.
chat_history += [(query, result["answer"])]
# Per ogni carattere nella risposta, aggiungilo all'ultimo elemento della cronologia.
for char in result['answer']:
history[-1][-1] += char
yield history, ''Forniamo la cronologia della chat con la query per mantenere il contesto della conversazione. Infine, trasmettiamo la risposta al chatbot. E non dimenticare di definire la funzionalità di ripristino per ripristinare tutti i valori.
Quindi, questo è tutto. Ora, avvia la tua applicazione e inizia a chattare con i video.
Ecco come appare il prodotto finale
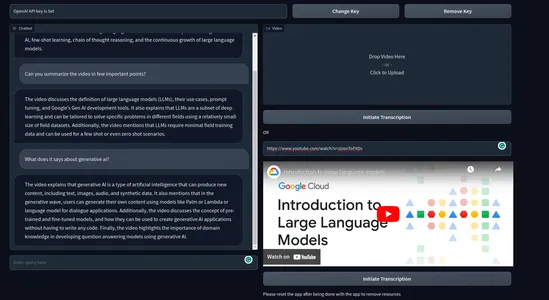
Video Demo:
Casi d’uso reali
Un’applicazione che consente all’utente finale di chattare con qualsiasi video o audio può avere una vasta gamma di casi d’uso. Ecco alcuni dei casi d’uso reali di questo chatbot.
- Educazione: gli studenti spesso seguono delle lezioni video di diverse ore. Questo chatbot può aiutare gli studenti a imparare dalle video-lezioni ed estrarre informazioni utili rapidamente, risparmiando tempo ed energia. Ciò migliorerà significativamente l’esperienza di apprendimento.
- Legale: i professionisti del diritto spesso attraversano lunghi procedimenti legali e deposizioni per analizzare il caso, preparare documenti, ricerca o monitoraggio della conformità. Un chatbot come questo può fare la differenza in queste attività.
- Riassunto dei contenuti: questa app può analizzare il contenuto video e generare versioni testuali riassunte. Ciò consente all’utente di cogliere i punti salienti del video senza guardarlo interamente.
- Interazione con il cliente: i brand possono incorporare una funzionalità di chatbot video per i propri prodotti o servizi. Ciò può essere utile per le aziende che vendono prodotti o servizi che sono a elevato costo o che richiedono molte spiegazioni.
- Traduzione video: possiamo tradurre il corpus di testo in altre lingue. Ciò può facilitare la comunicazione interlinguistica, l’apprendimento delle lingue o l’accessibilità per i non madrelingua.
Ecco alcuni dei possibili casi d’uso a cui ho pensato. Ci possono essere molte altre applicazioni utili di un chatbot per i video.
Conclusione
Quindi, questo è stato tutto sulla creazione di un’applicazione web demo funzionale per un chatbot per i video. Abbiamo coperto molti concetti in tutto l’articolo. Ecco i punti chiave dell’articolo.
- Abbiamo imparato su Langchain – un popolare strumento per creare applicazioni AI con facilità.
- Whisper è un potente modello di conversione del parlato in testo di OpenAI. Un modello open source che può convertire audio e video in testo.
- Abbiamo imparato come i database di vettori facilitino l’archiviazione e l’interrogazione efficaci di embedding di vettori.
- Abbiamo costruito un’applicazione web completamente funzionale da zero utilizzando modelli Langchain, Chroma e OpenAI.
- Abbiamo anche discusso dei potenziali casi d’uso della vita reale del nostro chatbot.
Questo è tutto, spero ti sia piaciuto, e considera di seguirmi su Twitter per altre cose legate allo sviluppo.
Repository GitHub: sunilkumardash9/chatgpt-for-videos. Se trovi questo utile, fai ⭐ al repository.
Domande frequenti
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e sono utilizzati a discrezione dell’autore.