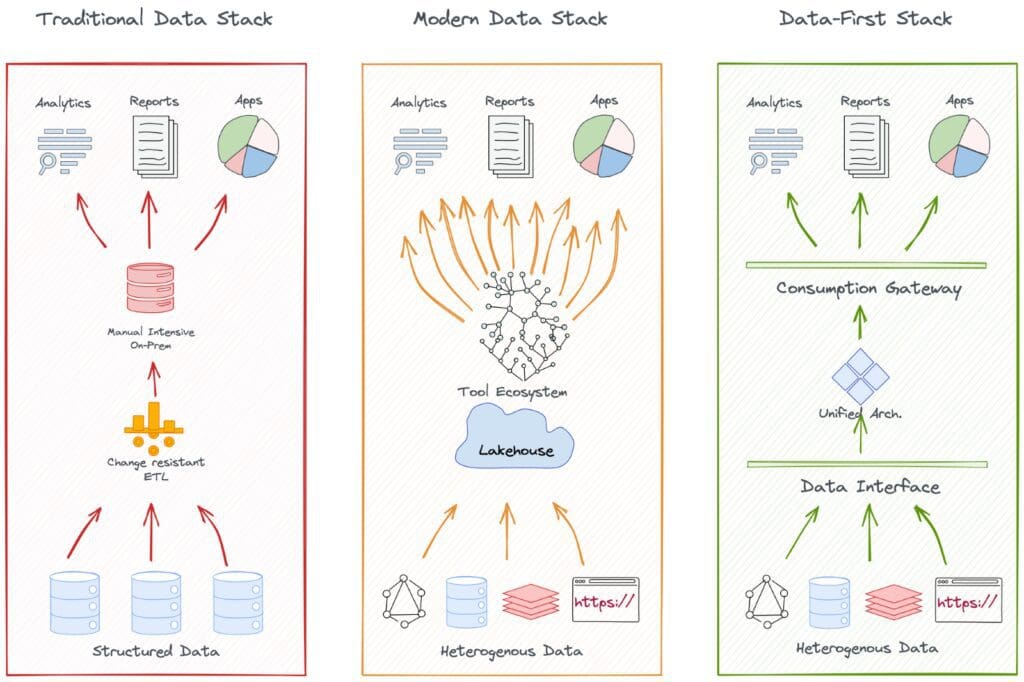
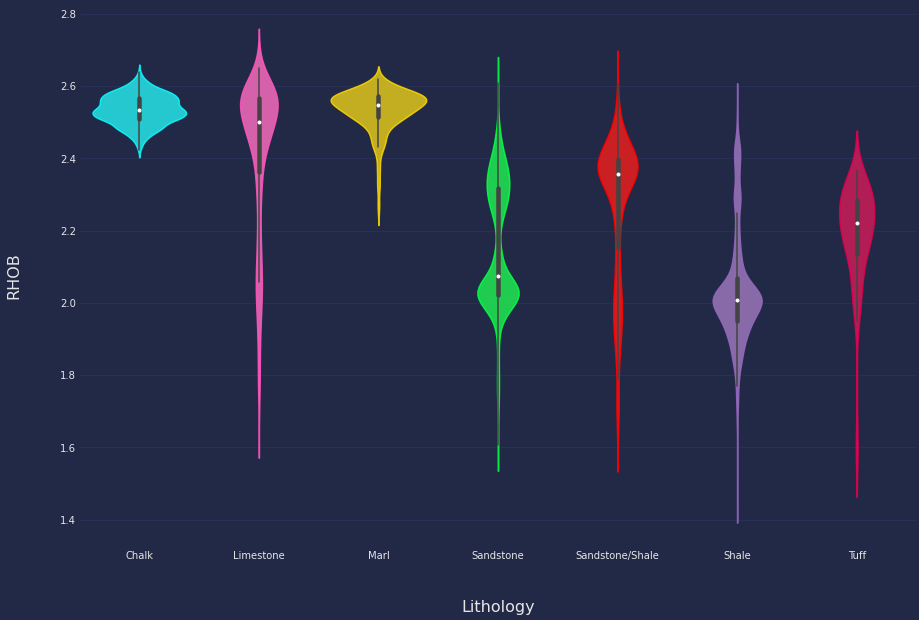
Cos’è il dato sintetico? Tipi, casi d’uso e applicazioni per l’apprendimento automatico e la privacy.
What is synthetic data? Types, use cases, and applications for machine learning and privacy.


Il campo della Data Science e del Machine Learning sta crescendo ogni singolo giorno. Con il tempo, vengono proposti nuovi modelli e algoritmi che hanno bisogno di enormi quantità di dati per il training e il testing. I modelli di Deep Learning stanno diventando sempre più popolari e sono anche molto esigenti in termini di dati. Ottenere una quantità così enorme di dati in relazione a diversi problemi è un processo estremamente complicato, costoso e che richiede molto tempo. I dati vengono raccolti da scenari reali, il che solleva questioni di sicurezza e privacy. La maggior parte dei dati è privata e protetta da leggi e regolamenti sulla privacy, il che ostacola la condivisione e il movimento dei dati tra organizzazioni o talvolta tra diversi dipartimenti di un’unica organizzazione, ritardando gli esperimenti e il testing dei prodotti. Quindi sorge la domanda su come risolvere questo problema. Come rendere i dati più accessibili e aperti senza destare preoccupazioni sulla privacy di qualcuno?
La soluzione a questo problema è qualcosa noto come dati sintetici.
Quindi, cos’è il dato sintetico?
Per definizione, il dato sintetico è generato artificialmente o algoritmico e somiglia da vicino alla struttura e alle proprietà dei dati effettivi. Se i dati sintetizzati sono buoni, sono indistinguibili dai dati reali.
- Previsione del tempo di impatto l’altro modo per la previsione probabilistica delle serie temporali.
- Dopo Twitter
- Gestione dei costi di archiviazione cloud delle applicazioni Big-Data
Quanti tipi diversi di dati sintetici possono esserci?
La risposta a questa domanda è molto aperta, poiché i dati possono assumere molte forme, ma principalmente abbiamo:
- Dati di testo
- Dati audio o visivi (ad esempio, immagini, video e audio)
- Dati tabulari
Casi d’uso dei dati sintetici per il machine learning
Discuteremo solo dei casi d’uso di tre tipi di dati sintetici, come sopra indicato.
- Uso di dati di testo sintetici per il training di modelli NLP
I dati sintetici hanno applicazioni nel campo dell’elaborazione del linguaggio naturale. Ad esempio, il team di Alexa AI di Amazon utilizza dati sintetici per completare il set di training per il loro sistema NLU (comprensione del linguaggio naturale). Ciò fornisce loro una solida base per addestrare nuove lingue senza dati di interazione con i consumatori esistenti o sufficienti.
- Utilizzo di dati sintetici per l’addestramento di algoritmi di visione
Discutiamo qui di un caso d’uso molto diffuso. Supponiamo di voler sviluppare un algoritmo per rilevare o contare il numero di volti in un’immagine. Possiamo utilizzare una GAN o qualche altra rete generativa per generare volti umani realistici, ovvero volti che non esistono nel mondo reale, per addestrare il modello. Un altro vantaggio è che possiamo generare quanti dati vogliamo da questi algoritmi senza violare la privacy di nessuno. Ma non possiamo utilizzare dati reali perché contengono i volti di alcune persone, quindi alcune politiche sulla privacy vietano l’utilizzo di tali dati.
Un altro caso d’uso è il reinforcement learning in un ambiente simulato. Supponiamo di voler testare un braccio robotico progettato per prendere un oggetto e metterlo in una scatola. Viene progettato un algoritmo di reinforcement learning per questo scopo. Dobbiamo fare esperimenti per testarlo perché è così che l’algoritmo di reinforcement learning impara. L’impostazione di un esperimento in uno scenario reale è piuttosto costosa e richiede molto tempo, limitando il numero di esperimenti diversi che possiamo effettuare. Ma se facciamo gli esperimenti nell’ambiente simulato, allora l’impostazione dell’esperimento è relativamente economica poiché non richiederà un prototipo di braccio robotico.
- Usi di dati tabulari
I dati tabulari sintetici sono dati generati artificialmente che imitano i dati del mondo reale memorizzati in tabelle. Questi dati sono strutturati in righe e colonne. Queste tabelle possono contenere qualsiasi tipo di dati, come una playlist musicale. Per ogni canzone, il tuo lettore musicale mantiene una serie di informazioni: il nome, il cantante, la durata, il genere, ecc. Può anche essere un record finanziario come le transazioni bancarie, i prezzi delle azioni, ecc.
I dati tabulari sintetici relativi alle transazioni bancarie vengono utilizzati per addestrare modelli e progettare algoritmi per rilevare transazioni fraudolente. I dati dei prezzi delle azioni del passato possono essere utilizzati per addestrare e testare modelli per la previsione dei prezzi futuri delle azioni.
Uno dei vantaggi significativi dell’utilizzo di dati sintetici nel machine learning è che lo sviluppatore ha il controllo sui dati; può apportare modifiche ai dati secondo necessità per testare qualsiasi idea e sperimentare con essa. Nel frattempo, uno sviluppatore può testare il modello sui dati sintetici e ottenere un’idea molto chiara di come il modello si comporterà sui dati reali. Se uno sviluppatore vuole provare un modello e aspetta i dati reali, acquisire i dati può richiedere settimane o addirittura mesi, ritardando lo sviluppo e l’innovazione della tecnologia.
Ora siamo pronti per discutere come i dati sintetici aiutino a risolvere i problemi legati alla privacy dei dati.
Molte industrie dipendono dai dati generati dai loro clienti per l’innovazione e lo sviluppo, ma quei dati contengono Informazioni di Identificazione Personale (PII), e le leggi sulla privacy regolamentano rigorosamente l’elaborazione di tali dati. Ad esempio, il Regolamento Generale sulla Protezione dei Dati (GDPR) vieta l’utilizzo che non è stato esplicitamente consentito quando l’organizzazione ha raccolto i dati. Poiché i dati sintetici assomigliano molto da vicino alla struttura sottostante dei dati reali e, allo stesso tempo, garantiscono che nessun individuo presente nei dati reali possa essere identificato nuovamente dai dati sintetici. Di conseguenza, l’elaborazione e la condivisione di dati sintetici hanno molte meno regolamentazioni, il che porta a sviluppi e innovazioni più rapidi e facile accesso ai dati.
Conclusione
I dati sintetici hanno molti vantaggi significativi. Danno ai programmatori di ML il controllo sugli esperimenti e aumentano la velocità di sviluppo poiché i dati sono ora più accessibili. Promuovono la collaborazione su una scala più ampia poiché i dati sono liberamente condivisibili. Inoltre, i dati sintetici garantiscono di proteggere la privacy degli individui dai dati reali.
Le migliori soluzioni/startup di dati sintetici per i modelli di apprendimento automatico nel 2022
L’articolo Cos’è il dato sintetico? I loro tipi, casi d’uso e applicazioni per l’apprendimento automatico e la privacy è apparso per la prima volta su MarkTechPost.