Evoluzione del Paesaggio dei Dati
Data Landscape Evolution.
L’articolo segue la storia dell’evoluzione nello spazio dei dati attraverso la lente dei modelli evolutivi. Parla dello stato di importanti traguardi nel percorso evolutivo, dei loro successi, sfide e del prossimo traguardo che ha risolto tali sfide. L’articolo viene presentato sia da una prospettiva commerciale che tecnica…
Co-Autore: Srujan e Travis Thompson
Il dominio dei dati è maturato profondamente ed è giunto molto lontano dall’avvento dei file spessi nel seminterrato. Il viaggio è stato niente meno che affascinante ed altrettanto emozionante che la rivoluzione del software. La parte migliore è che siamo proprio nel bel mezzo della rivoluzione dei dati e abbiamo l’opportunità di essere testimoni di questo cambiamento.
Cinque-dieci anni fa ci trovavamo di fronte a problemi completamente diversi, oggi ci troviamo di fronte ad un insieme completamente nuovo di problemi. Alcuni sono sorti come conseguenza dell’esplosione cambriana dei dati, altri sono sorprendentemente sorti come conseguenza delle soluzioni ideate per risolvere i problemi iniziali.
- Come Creare Grafici a Violino di Seaborn in Stile Cyberpunk con un Codice Python Minimale
- Cos’è la gestione dei dati e perché è importante?
- Perché il testing delle ipotesi dovrebbe prendere spunto da Amleto
Ciò ha portato a molte transizioni attraverso una moltitudine di stack e architetture di dati. Tuttavia, ciò che si è distinto sono stati tre stack semplici ma fondamentalmente pivanti: lo stack di dati tradizionale, lo stack di dati moderno e lo stack di dati-prima. Vediamo come si è sviluppato.
Fondamentali evolutivi: Pattern che hanno scaturito il cambiamento nel panorama dei dati
Ci sono due ampi pattern di evoluzione: Divergente e Convergente. Questi ampi pattern si applicano anche al panorama dei dati.
La diversità delle specie sulla Terra è dovuta all’evoluzione divergente. Allo stesso modo, l’evoluzione divergente porta ad una vasta gamma di strumenti e servizi nell’industria dei dati conosciuti come il panorama MAD oggi. L’evoluzione convergente crea varianti di strumenti con funzionalità condivise nel tempo. Ad esempio, topi e tigri sono animali molto diversi, ma entrambi hanno caratteristiche simili come baffi, pelliccia, arti e coda.
L’evoluzione convergente porta a denominatori comuni tra le soluzioni di strumentazione, il che significa che gli utenti pagano per funzionalità ridondanti. L’evoluzione divergente comporta costi di integrazione ancora più elevati e richiede esperti per comprendere e mantenere la filosofia unica di ciascuno strumento.
Si noti che i denominatori comuni non significano che le soluzioni puntuali convergano verso una soluzione unificata. Invece, ogni punto sta sviluppando soluzioni che si intersecano con altre soluzioni di altri punti in base alla domanda. Queste capacità comuni hanno linguaggi e filosofie separate e richiedono esperti di nicchia.
Ad esempio, Immuta e Atlan sono soluzioni di governance e catalogo dati, rispettivamente. Tuttavia, Immuta sta sviluppando anche un catalogo dati e Atlan sta aggiungendo capacità di governance. I clienti tendono a sostituire le funzionalità secondarie con strumenti specializzati in esse. Ciò comporta:
- Tempo investito nella comprensione del linguaggio e della filosofia di ciascun prodotto
- Costo ridondante dell’onboarding di due strumenti con offerte simili
- Costi di risorse elevati di esperti di nicchia; ancora più difficile poiché c’è una carenza di buon talento
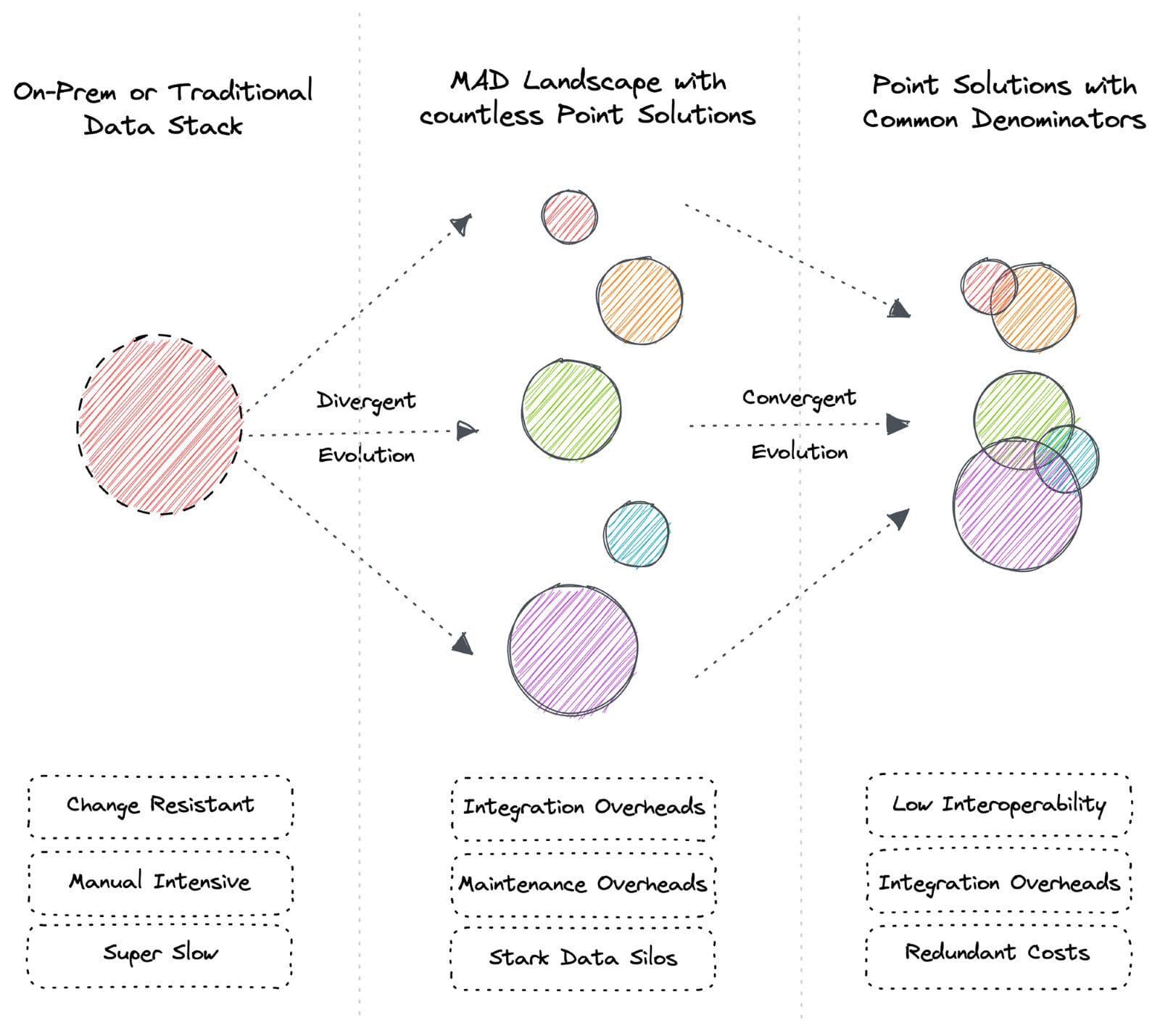
Ora che abbiamo una comprensione a livello generale dei pattern evolutivi, vediamo come si manifestano nel dominio dei dati. Non andremo troppo indietro per la brevità.
Tornando indietro di alcuni anni
I problemi che abbiamo come industria dei dati oggi erano nettamente diversi da quelli di 5-6 anni fa. La sfida principale che le organizzazioni affrontavano in quel periodo era la massiccia transizione dai sistemi on-prem al cloud. I sistemi big data on-prem e i data warehouse SQL (o lo stack di dati tradizionale TDS) non erano solo difficili da mantenere con un uptime estremamente basso ma anche estremamente lenti quando si trattava della lunghezza del percorso dai dati alle informazioni. In breve, la scala e l’efficienza erano lontane, soprattutto a causa dei seguenti ostacoli:
Esercito di ingegneri dei dati
Qualsiasi numero di ingegneri dei dati non era sufficiente per mantenere i sistemi interni. Tutto, dal data warehouse e dall’ETL ai dashboard e ai flussi di lavoro BI, doveva essere progettato internamente, portando la maggior parte delle risorse dell’organizzazione a essere spese per la costruzione e la manutenzione anziché per attività generatrici di entrate.
Sovraccarico di pipeline
Le pipeline dei dati erano complicate e interconnesse, molte di esse create per rispondere alle nuove esigenze aziendali. A volte, una nuova pipeline era necessaria per rispondere ad una singola domanda o per creare un gran numero di tabelle di data warehouse da un numero inferiore di tabelle di origine. Questa complessità poteva essere schiacciante e difficile da gestire.
Tolleranza ai guasti zero
I dati non erano né sicuri né affidabili senza alcun backup, ripristino o RCA. La qualità e la governance dei dati erano pensate in seguito e talvolta anche al di là della descrizione del lavoro degli ingegneri che si affaticavano sotto il peso delle attività di plumbing.
Costo del Movimento dei Dati
La migrazione di grandi quantità di dati tra i sistemi legacy era un altro segnale di allarme e consumava enormi risorse e tempo. Inoltre, spesso portava a dati corrotti e problemi di formato, che richiedevano altri mesi per essere risolti o venivano abbandonati.
Resistenza al Cambiamento
Le pipeline nei sistemi on-premise erano estremamente fragili e, quindi, resistenti ai cambiamenti frequenti o a qualsiasi cambiamento, diventando un disastro per le operazioni dinamiche e suscettibili di cambiamenti dei dati e rendendo gli esperimenti costosi.
Ritmo Estenuante
Mesi e anni passavano per implementare nuove pipeline per rispondere alle domande di business generiche. Le richieste di business dinamiche erano fuori discussione. Per non parlare della perdita di attività durante i frequenti downtime.
Carenza di Competenze
Un alto debito o cruft portava a resistenze nel passaggio di progetti a causa di dipendenze critiche. La mancanza delle giuste competenze sul mercato non ha aiutato la situazione e spesso ha portato a mesi di tracce duplicate per pipeline critiche.
Soluzioni del Tempo e i Problemi Risultanti dalle Soluzioni
L’Emergere del Cloud e l’Obbligo di Diventare Cloud-Native
Un decennio fa, i dati non venivano considerati un asset tanto quanto lo sono oggi. Specialmente poiché le organizzazioni non ne avevano abbastanza da sfruttare come asset e anche perché dovevano affrontare innumerevoli problemi per generare anche un solo cruscotto funzionante. Ma col tempo, poiché i processi e le organizzazioni sono diventati più digitali e orientati ai dati, c’è stata una crescita esponenziale improvvisa nella generazione e cattura dei dati.
Le organizzazioni si sono rese conto che potevano migliorare i loro processi comprendendo i modelli storici che erano evidenti in volumi maggiori della loro capacità. Per affrontare i problemi persistenti del TDS e potenziare le applicazioni dati, sono emerse molteplici soluzioni puntuali che si sono integrate in un data lake centrale. Abbiamo chiamato questa combinazione il Modern Data Stack (MDS). Era indubbiamente una soluzione quasi perfetta per i problemi dell’industria dei dati in quel momento.
➡️ Transizione al Modern Data Stack (MDS)
Il MDS ha risolto alcuni problemi persistenti nel panorama dei dati dell’epoca. La sua più grande conquista è forse stata la rivoluzionaria transizione al cloud, che ha reso i dati non solo più accessibili ma anche recuperabili. Soluzioni come Snowflake, Databricks e Redshift hanno aiutato le grandi organizzazioni a migrare i dati nel cloud, aumentando l’affidabilità e la tolleranza ai guasti.
I leader dei dati che erano a favore del TDS per vari motivi, tra cui vincoli di budget, si sono sentiti obbligati a passare al cloud e rimanere competitivi dopo aver visto transizioni di successo in altre organizzazioni. Ciò ha richiesto di convincere il CFO a dare priorità e investire nella transizione, il che è stato realizzato promettendo valore nel prossimo futuro.
Ma diventare cloud-native non si è limitato alla sola migrazione nel cloud, che di per sé era un costo considerevole. Diventare veramente cloud-native ha significato anche integrare una serie di soluzioni per operazionalizzare i dati nel cloud. Il piano sembrava buono, ma il MDS ha finito per scaricare tutti i dati in un’unica massa, creando paludi di dati ingestibili in tutti i settori.
💰 Investimenti in Promesse Fantasma
- Costo della migrazione di enormi asset di dati nel cloud
- Costo di mantenere il cloud attivo
- Costo delle licenze individuali per le soluzioni puntuali necessarie per operazionalizzare il cloud
- Costo di denominatori comuni o ridondanti tra le soluzioni puntuali
- Costo del carico cognitivo e delle competenze specialistiche per comprendere le filosofie variabili di ogni strumento
- Costo dell’integrazione continua ogni volta che un nuovo strumento entra nell’ecosistema
- Costo della manutenzione continua delle integrazioni e di conseguenza dell’inondazione delle pipeline
- Costo dell’allestimento di infrastrutture di progettazione dei dati per operazionalizzare le soluzioni puntuali
- Costo di team di piattaforma dedicati per mantenere l’infrastruttura attiva
- Costo di memorizzazione, movimento e calcolo per il 100% dei dati in paludi di dati
- Costo di governance isolata per ogni punto di esposizione o punto di integrazione
- Costo di rischi dati frequenti a causa di molteplici punti di esposizione
- Costo di decomplessificazione delle dipendenze durante il passaggio di progetti frequenti
Come puoi immaginare, l’elenco è ben lontano dall’essere esaustivo.
🔄 Il Circolo Vizioso del ROI dei Dati
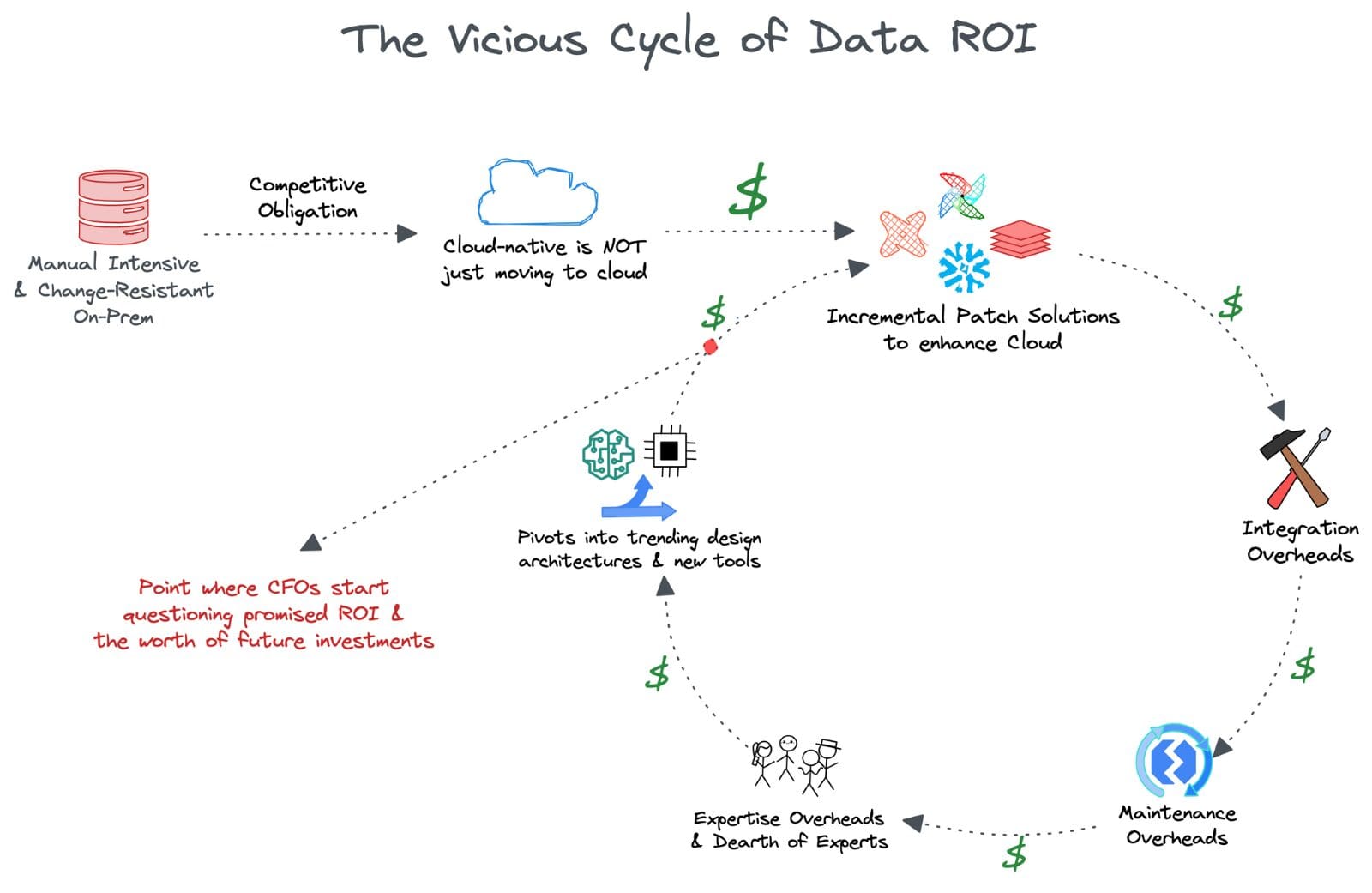
I leader dei dati, inclusi i CDO e i CTO, presto hanno sentito il peso delle promesse non mantenute sugli investimenti che erano su scala milionaria. Le soluzioni patch incrementalmente create hanno creato tanti problemi quanti ne hanno risolti, e i team dei dati sono tornati al problema fondamentale di non essere in grado di utilizzare i ricchi dati che possedevano.
L’assenza di futureproofing era un grave rischio per i leader, con la loro permanenza nelle organizzazioni ridotta a meno di 24 mesi. Per garantire che i CFO vedano i rendimenti, si sono agganciati alle tendenze delle architetture di progettazione dei dati e alle nuove innovazioni degli strumenti che hanno svelato nuove promesse.
A questo punto, l’ufficio del CFO ha inevitabilmente cominciato a mettere in dubbio la credibilità dei risultati promessi. In modo più pericoloso, hanno cominciato a mettere in dubbio il valore degli investimenti nei verticali centrati sui dati stessi. Non avrebbero milioni spesi su altre operazioni avuto un impatto molto migliore entro cinque anni?
Se guardiamo un po’ più a fondo e ci avviciniamo alle soluzioni effettive che abbiamo discusso sopra, si vedrà meglio come gli investimenti nei dati siano arrugginiti nel corso degli anni, specialmente a causa dei costi nascosti e imprevisti.
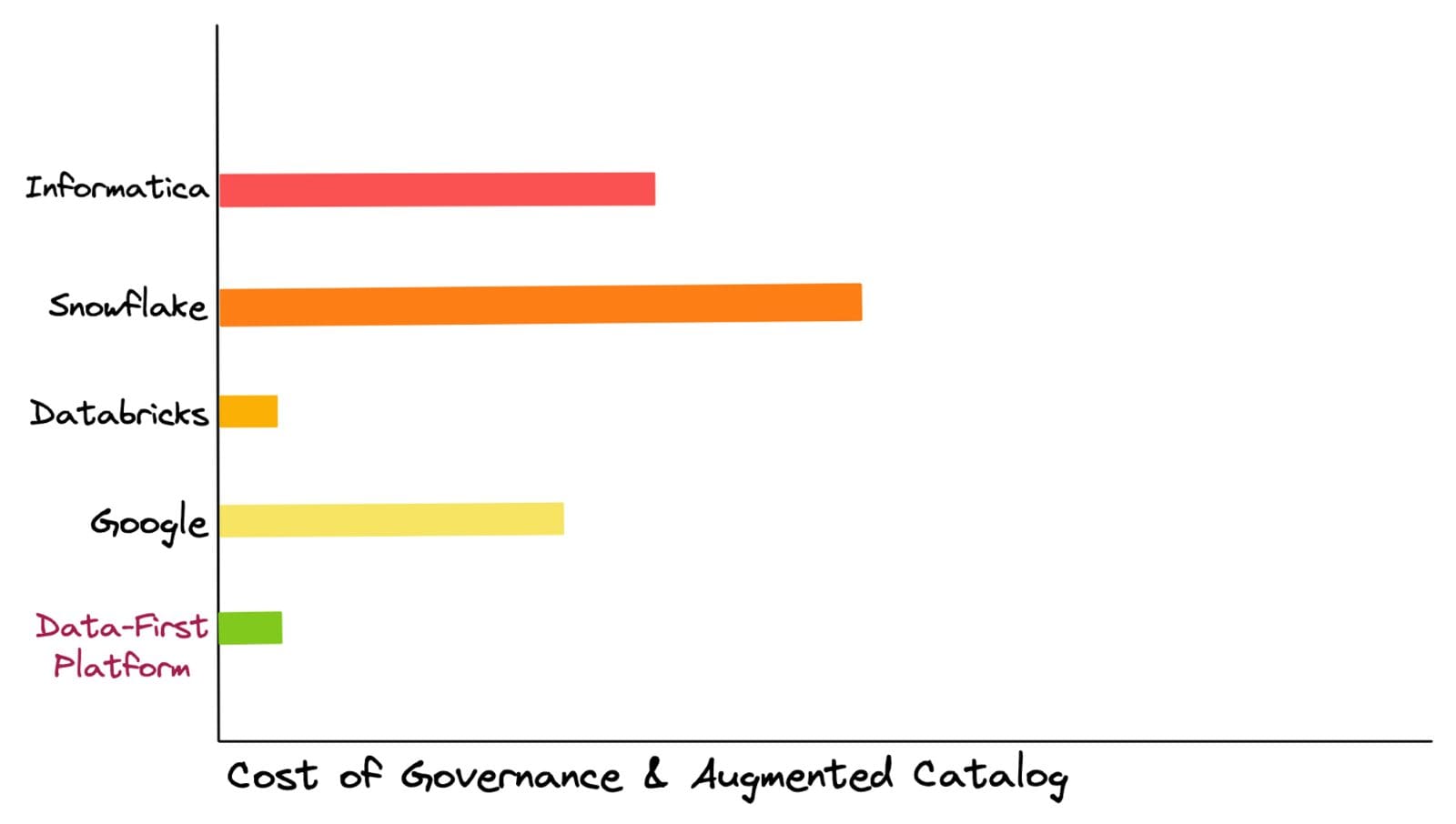
L’valutazione del TCO viene effettuata in base al costo degli esperti di nicchia, della migrazione, dell’installazione, del calcolo per la gestione di un carico di lavoro fisso, della memorizzazione, delle tariffe di licenza e del costo cumulativo di soluzioni puntuali come governance, catalogazione e strumenti BI. In base alle esperienze dei clienti con questi fornitori, abbiamo aggiunto barre a scacchi in alto poiché, più spesso che no, si verificano salti di costo imprevisti durante l’utilizzo di queste piattaforme.
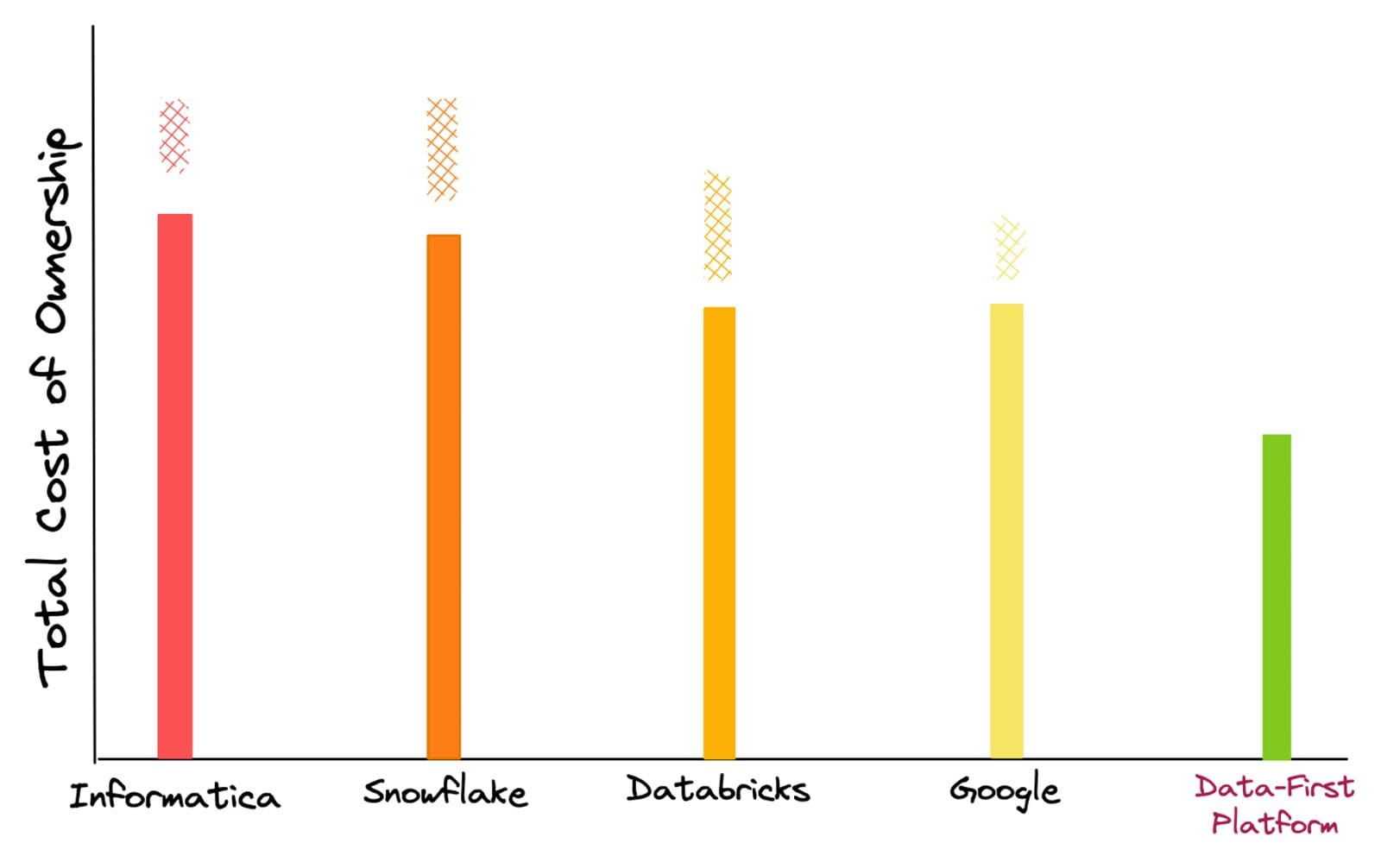
A causa della natura versatile di questi costi, che potrebbero essere variati come un aumento del carico di lavoro o query di background al modello di prezzo stesso, possono essere meglio classificati come “costi enigmatici”. D’altra parte, con un approccio incentrato sui dati che astrae le complessità degli strumenti, non ci sono salti imprevisti nel TCO. Vi è un controllo completo sul calcolo previsto per ogni carico di lavoro e sulla memorizzazione utilizzata.
💣 L’elevata proliferazione degli strumenti ha reso ogni manutenzione dello stack prima e i dati ultimi.
Con una vasta gamma di strumenti, come dimostrato dal MAD Landscape o dal MDS, sta diventando sempre più difficile per le organizzazioni concentrarsi sullo sviluppo di soluzioni che effettivamente portano risultati commerciali a causa dell’attenzione costante richiesta dai ticket di manutenzione.
I poveri ingegneri dei dati sono bloccati in un’economia in cui la manutenzione viene prima, l’integrazione in secondo luogo e i dati alla fine. Ciò comporta innumerevoli ore trascorse a risolvere i difetti dell’infrastruttura e a mantenere le pipeline dei dati. E l’infrastruttura necessaria per ospitare e integrare diversi strumenti non è meno dolorosa.
Gli ingegneri dei dati sono sopraffatti da un gran numero di file di configurazione, frequenti spostamenti di configurazione, personalizzazioni specifiche dell’ambiente per ogni file e innumerevoli oneri di dipendenza. In breve, gli ingegneri dei dati trascorrono notti insonni solo per garantire che l’infrastruttura dei dati corrisponda agli SLO di uptime.
La sovraccarico degli strumenti non è solo costosa in termini di tempo e sforzo, ma gli oneri di integrazione e manutenzione incidono direttamente sul ROI dei team di ingegneria in termini di costo letterale senza consentire alcun miglioramento diretto per le applicazioni di dati che guidano l’attività commerciale.
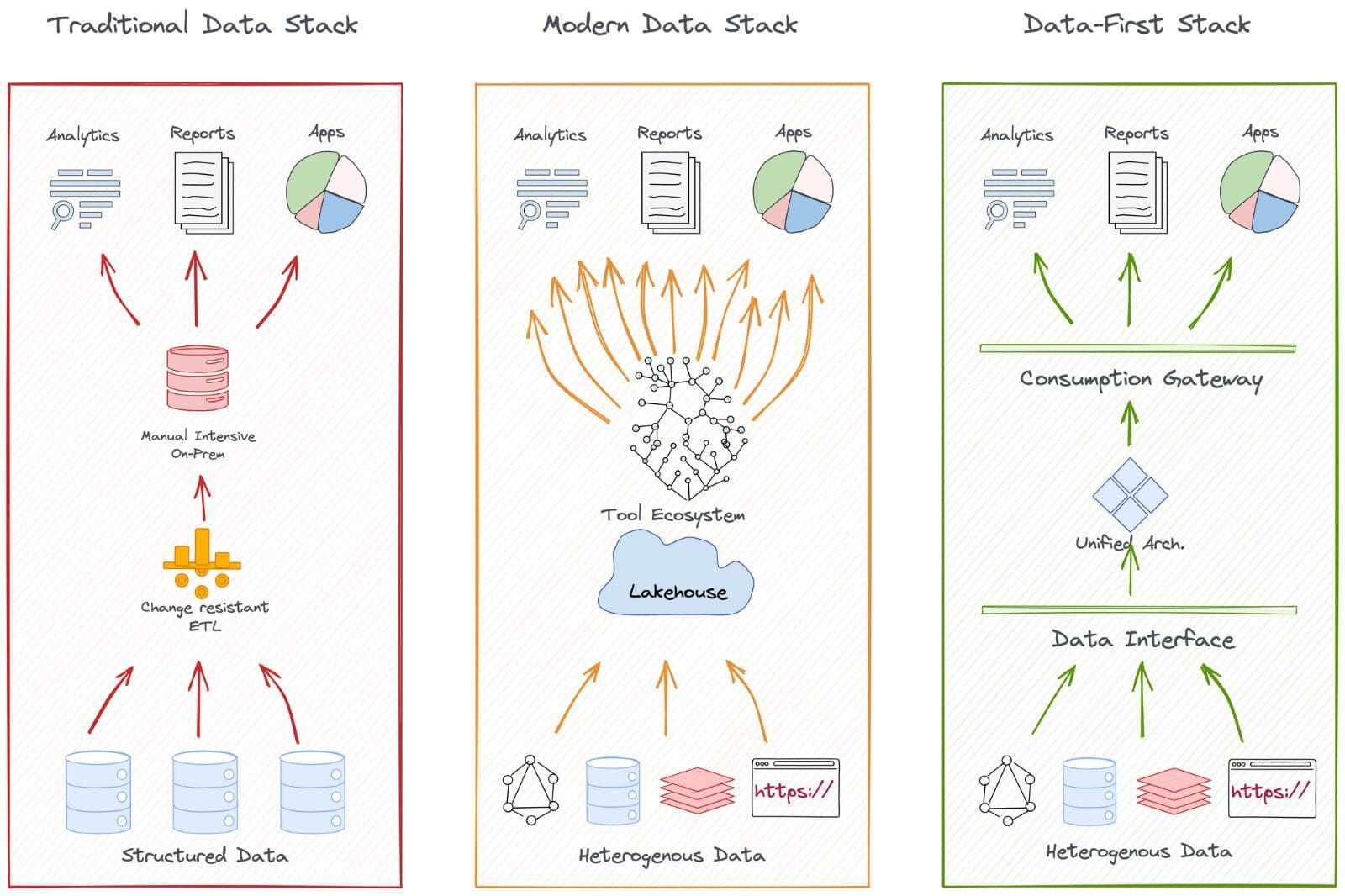
Ecco una rappresentazione del movimento dei dati aziendali attraverso i metodi ETL ed ELT convenzionali. Comprende il costo di integrazione di fonti dati batch e streaming e l’orchestrazione dei flussi di lavoro dei dati.
L’aumento dei costi nel corso degli anni si basa sull’ipotesi che, nel tempo, l’azienda aumenterà l’utilizzo della piattaforma in termini di numero di sistemi di origine integrati e di elaborazione dei dati successivi.
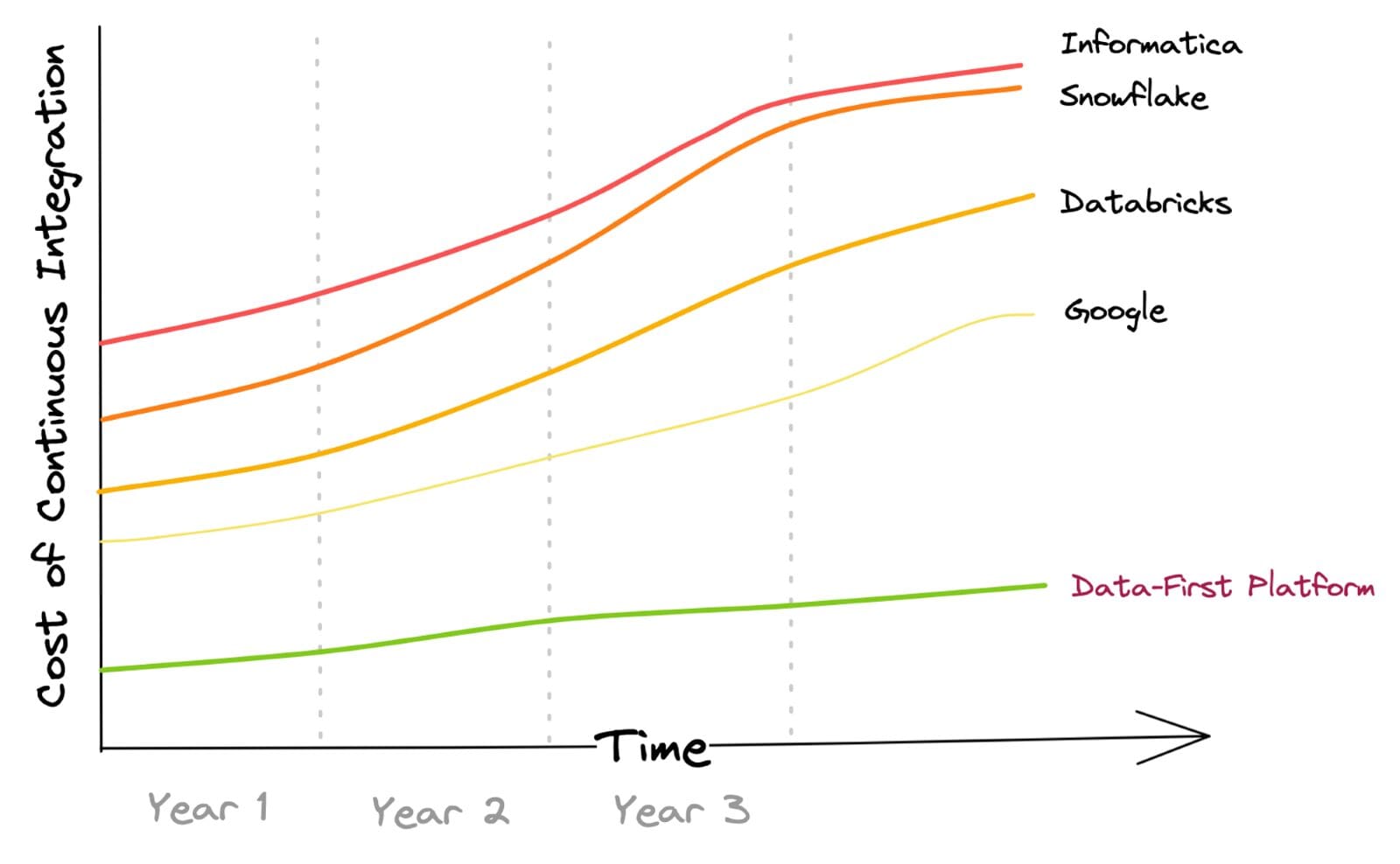
Ciò è stato riscontrato essere vero per la maggior parte dei clienti tra i fornitori. In un approccio incentrato sui dati, il costo di integrazione dei dati è nullo o minimo grazie alla sua convinzione globale nella Intelligent Data Movement e nella gestione dell’integrazione astratta che consente l’elaborazione dei dati con un minimo spostamento dei dati.
🚧 Le organizzazioni sono obbligate a sottostare alla filosofia degli strumenti.
Gestire un pacchetto di diverse soluzioni non è la fine. Le organizzazioni sono obbligate a seguire le direzioni e le filosofie predefinite di questi strumenti individuali. Ad esempio, se viene aggiunto uno strumento di Governance, lo sviluppatore di dati impara come utilizzare lo strumento, impara i modi specifici in cui parla con altri strumenti e riorganizza gli altri strumenti per soddisfare le specifiche del nuovo componente.
Ogni strumento ha una voce in architettura di progettazione a causa della propria filosofia, rendendo l’interoperabilità molto più complessa e selettiva. La mancanza di flessibilità è anche un motivo dietro l’alto costo di passare a nuovi e innovativi progetti di infrastruttura, come maglie e tessuti, che potrebbero potenzialmente aumentare il ROI promesso.
Un’abbondanza di strumenti con filosofie uniche richiede anche una grande esperienza. In termini pratici, assumere, formare, mantenere e collaborare con così tanti data engineer non è possibile. Ciò è ancora più vero con la carenza di professionisti esperti e qualificati nel campo.
🧩 Incapacità di catturare e operazionalizzare insight atomici
Un’infrastruttura rigida, a causa dell’abbondanza di strumenti e integrazioni, significa una bassa flessibilità nel sfruttare e indirizzare i byte di dati atomici verso i giusti endpoint rivolti ai clienti nel momento giusto. La mancanza di atomicità è anche il risultato di una bassa interoperabilità e di sottosistemi isolati che non hanno percorsi ben definiti per comunicare tra loro.
Un buon esempio è ogni strumento che mantiene il proprio motore di metadati separato per operazionalizzare i metadati. I motori di metadati hanno linguaggi e canali di trasmissione separati e sono difficilmente in grado di comunicare tra loro se non specificatamente progettati per farlo. Questi nuovi canali ingegnerizzati aggiungono anche alla tabella di manutenzione. I dati di utilizzo vengono persi nella traduzione e le verticali parallele non sono in grado di sfruttare gli insight tratti l’una dall’altra.
Inoltre, le operazioni sui dati nell’MDS sono spesso sviluppate, eseguite e distribuite a lotti a causa dell’incapacità di imporre pratiche simili al software in tutta la caotica diffusione dell’MDS. In pratica, DataOps non è fattibile a meno che i dati, l’unico componente non deterministico dello stack di dati, non siano inseriti in un livello unificato che potrebbe imporre commit atomici, test verticali lungo la linea di modifica e i principi CI/CD per eliminare non solo i silos di dati ma anche i silos del codice dei dati.
La soluzione che è emersa per contrastare i problemi conseguenti dell’MDS
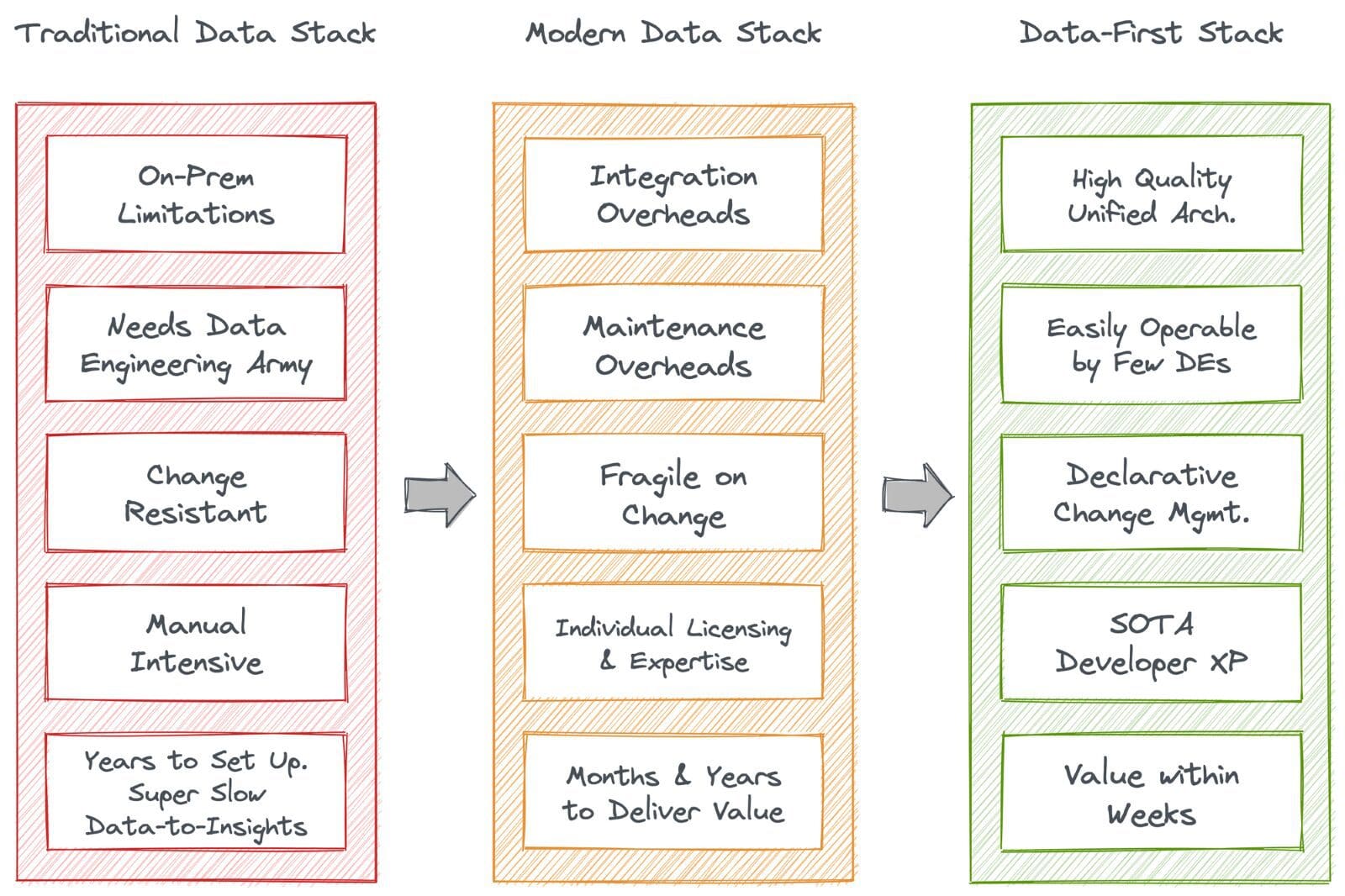
La transizione dal Traditional Data Stack al Modern Data Stack e infine al Data-First Stack (DFS) era in gran parte inevitabile. La necessità di DFS è stata sentita principalmente a causa dell’enorme accumulo di spazzatura tecnologica (debito tecnico) all’interno dei confini dell’ingegneria dei dati. DFS ha introdotto un approccio di unificazione o una soluzione ombrello che ha preso di mira i frammenti deboli di TDS e MDS nel complesso invece di proporre la loro filosofia di rattoppo.
DFS ha portato capacità self-serve ai team aziendali. Potrebbero portare la propria elaborazione invece di lottare per le risorse IT (che limitano gravemente l’accesso dei team aziendali ai dati in molte aziende). La condivisione dei dati con i partner e la loro monetizzazione in modo conforme sono diventati più facili con DFS. Invece di sforzarsi di integrare centinaia di soluzioni sparse, gli utenti potevano mettere i dati al primo posto e concentrarsi sugli obiettivi principali: costruire applicazioni dati che migliorano direttamente i risultati aziendali.
La riduzione dei costi delle risorse è una delle priorità per le organizzazioni nel mercato attuale, il che è quasi impossibile poiché i costi di conformità sono molto elevati quando si tratta di governare e catalogare un paesaggio disperso di molteplici soluzioni puntuali. L’infrastruttura unificata di DFS riduce questo costo componendo queste capacità puntuali in blocchi fondamentali e governando quei blocchi centralmente, migliorando istantaneamente la discoverability e la trasparenza.
La soluzione di catalogazione di DFS è completa, poiché le sue funzionalità di Data Discoverability & Observability sono integrate con la governance nativa e la conoscenza semantica ricca che consente la gestione attiva dei metadati. In cima ad essa, consente il controllo completo dell’accesso su tutte le applicazioni e i servizi dell’infrastruttura dati.
Il Data-First Stack è essenzialmente un sistema operativo (OS) che è un programma che gestisce tutti i programmi necessari affinché l’utente finale abbia un’esperienza basata sui risultati invece di capire “come” eseguire quei programmi. La maggior parte di noi ha sperimentato OS sui nostri laptop, telefoni e, infatti, su qualsiasi dispositivo basato sull’interfaccia. Siamo collegati a questi sistemi perché ci siamo astratti dai dolori dell’avvio, della manutenzione e dell’esecuzione delle sfumature a basso livello delle applicazioni quotidiane. Invece, usiamo tali applicazioni direttamente per guidare i risultati.
Il sistema operativo dati (DataOS) è quindi rilevante sia per le organizzazioni consapevoli dei dati che per quelle non consapevoli dei dati. In sintesi, consente un’infrastruttura di dati self-serve astraggendo gli utenti dalle complessità procedurali delle applicazioni e servendo dichiarativamente i risultati.
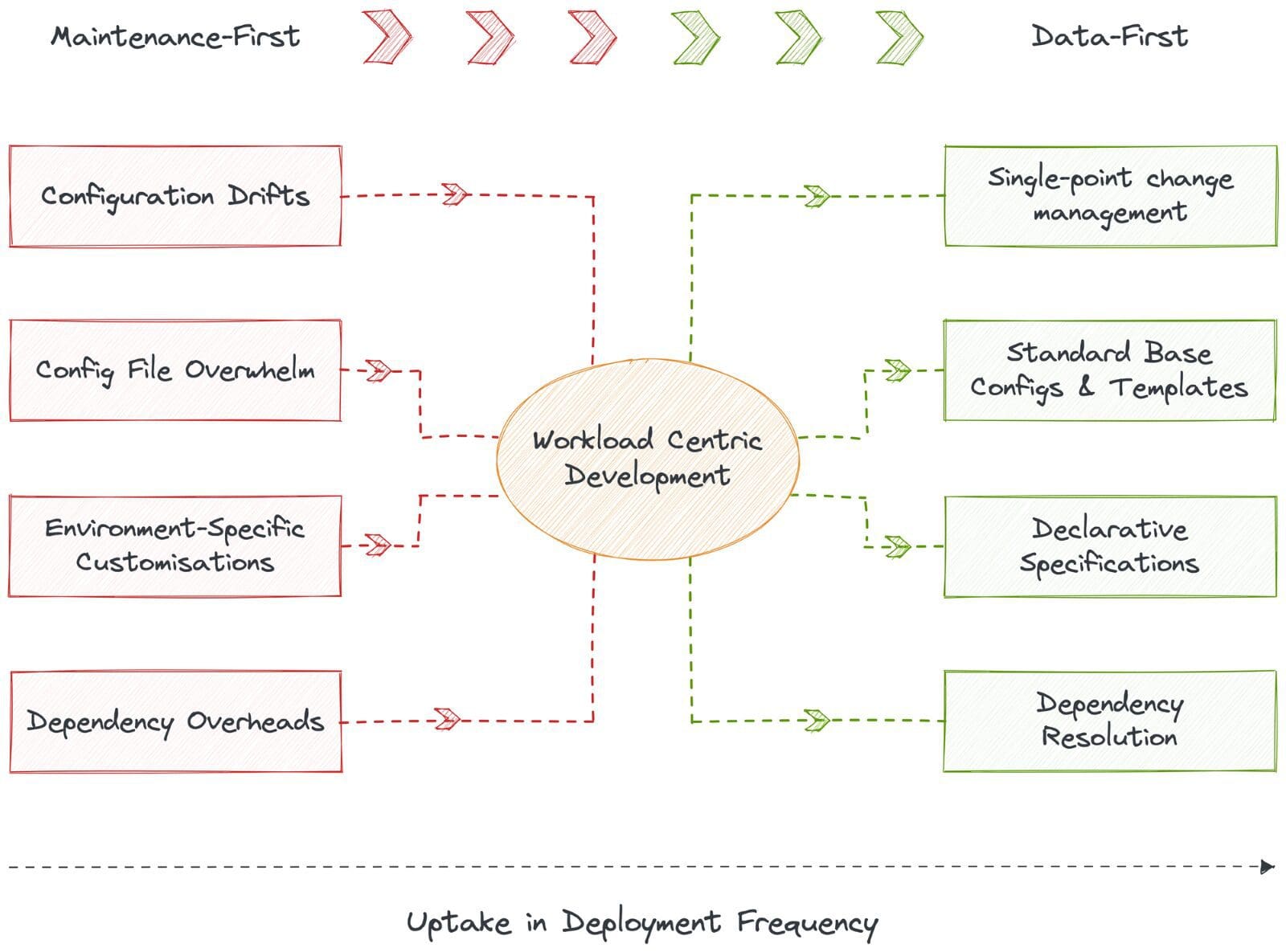
🥇 Transizione da manutenzione-first a data-first
Il sistema operativo dati (DataOS) è lo stack di dati che mette i dati al primo posto e capisce che le organizzazioni devono essere utenti di dati, non costruttori di infrastrutture dati. DataOS astrae tutte le sfumature della gestione dei dati a basso livello, che altrimenti assorbono la maggior parte delle ore attive dello sviluppatore di dati.
Un sistema gestito in modo dichiarativo elimina drasticamente la possibilità di fragilità e rende disponibili lenti RCA su richiesta, ottimizzando di conseguenza le risorse e il ROI. Ciò consente al talento ingegneristico di dedicare il proprio tempo e le proprie risorse ai dati e alla costruzione di applicazioni dati che hanno un impatto diretto sul business.
I data developer possono rapidamente distribuire i carichi di lavoro eliminando le deviazioni di configurazione e il vasto numero di file di configurazione attraverso configurazioni di base standard che non richiedono variabili specifiche dell’ambiente. Il sistema genera automaticamente file di manifesto per le app, consentendo operazioni CRUD, esecuzione e archiviazione meta in cima. In sintesi, DataOS fornisce uno sviluppo centrato sui carichi di lavoro in cui i data developer dichiarano i requisiti dei carichi di lavoro e DataOS fornisce risorse e risolve le dipendenze. L’impatto si realizza istantaneamente con un aumento visibile della frequenza di distribuzione.
💠 Convergenza verso un’architettura unificata
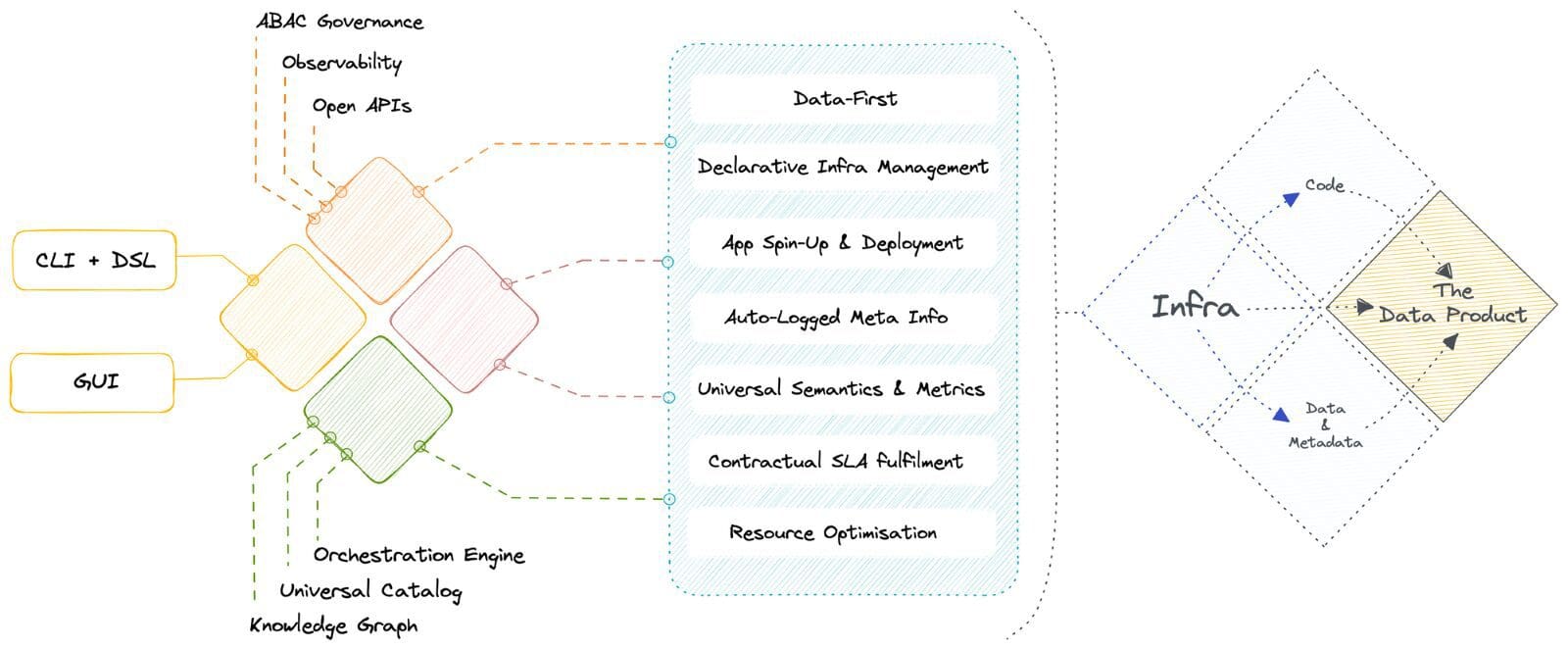
🧱 Transizione da soluzioni patchwork a blocchi di base primitivi
Divenire data-first in poche settimane è possibile grazie all’alta qualità interna dell’architettura componibile del sistema operativo dei dati: unificazione attraverso la modularizzazione. La modularizzazione è possibile attraverso un insieme finito di primitive che sono state identificate in modo univoco come essenziali per lo stack di dati nella sua forma più fondamentale. Queste primitive possono essere disposte in modo specifico per costruire componenti e applicazioni di ordine superiore.
Possiamo trattarle come artefatti che possono essere gestiti e controllati dalla sorgente utilizzando un sistema di controllo della versione. Ogni primitiva può essere considerata un’astrazione che consente di elencare obiettivi e risultati specifici in modo dichiarativo invece del processo arduo di definire “come raggiungere tali risultati”.
🦾 Unificazione degli strumenti preesistenti per la gestione dichiarativa
Essendo orientati all’artefatto con standard aperti, DataOS viene utilizzato come strato architetturale in cima a qualsiasi infrastruttura dati esistente. Ciò consente di interagire con componenti eterogenei nativi ed esterni a DataOS. Pertanto, le organizzazioni possono integrare la loro infrastruttura dati esistente con nuove e innovative tecnologie senza dover rinnovare completamente i propri sistemi esistenti.
Si tratta di un’interfaccia self-service completa per i data developer per la gestione dichiarativa delle risorse attraverso API e CLI. Gli utenti business raggiungono l’auto-servizio attraverso GUI intuitive per integrare direttamente la logica aziendale nei modelli di dati. L’interfaccia GUI consente inoltre ai developer di visualizzare l’allocazione delle risorse e semplificare la gestione delle risorse. Ciò consente di risparmiare tempo significativo e migliorare la produttività dei developer, che possono gestire facilmente le risorse senza una conoscenza tecnica approfondita.
☀️ Governance centrale, orchestrazione e gestione dei metadati
DataOS opera su un’architettura concettuale a doppio piano in cui il controllo è biforcato tra un piano centrale per i componenti verticali globali e uno o più piani dati per le operazioni localizzate. Il piano di controllo aiuta gli amministratori a governare l’ecosistema dei dati attraverso la gestione centralizzata e il controllo dei componenti verticali.
Gli utenti possono gestire centralmente il controllo degli accessi basati su politiche e finalizzati su diversi punti di contatto in ambienti nativi del cloud, con precedenza per la proprietà locale, orchestrare i carichi di lavoro dei dati, la gestione del ciclo di vita del cluster di calcolo, il controllo delle versioni delle risorse di DataOS e gestire i metadati di diversi tipi di asset dati.
⚛️ Insights atomici per casi d’uso esperienziali
L’industria sta rapidamente passando da casi d’uso transazionali a casi d’uso esperienziali. Gli insight di big bang tratti da grandi blocchi di dati su lotti periodici lunghi sono ora il requisito secondario. Gli insight atomici o di dimensioni byte derivati da dati puntuali in quasi tempo reale sono il nuovo gioco e i clienti sono più che disposti a pagare per questo.
Lo strato comune sottostante di primitive garantisce che i dati siano visibili su tutti i punti di contatto nell’architettura unificata e possano essere materializzati in qualsiasi canale attraverso astrazioni semantiche quando il caso d’uso aziendale lo richiede.
Animesh Kumar è il Chief Technology Officer e Co-Fondatore di @Modern, e co-creatore della Specifica di Infrastruttura del Sistema Operativo dei Dati. Durante i suoi oltre 30 anni nello spazio dell’ingegneria dei dati, ha progettato soluzioni di ingegneria per una vasta gamma di A-Players, tra cui NFL, GAP, Verizon, Rediff, Reliance, SGWS, Gensler, TOI e altri.
Srujan è il CEO e Co-Fondatore di @Modern. Nel corso di 30 anni di dati ed ingegneria, Srujan è stato attivamente impegnato nella comunità come imprenditore, dirigente di prodotto e leader aziendale con numerosi lanci di prodotto premiati presso organizzazioni come Motorola, TeleNav, Doot e Personagraph.
Travis Thompson (Co-Autore): Travis è l’architetto capo della Specifica dell’Infrastruttura del Sistema Operativo dei Dati. Nel corso di 30 anni in tutto ciò che riguarda i dati e l’ingegneria, ha progettato architetture e soluzioni all’avanguardia per le migliori organizzazioni, come GAP, Iterative, MuleSoft, HP e molte altre.





