Oltre l’accuratezza Abbracciare serendipità e novità nelle raccomandazioni per il mantenimento a lungo termine degli utenti
Abbracciare serendipità e novità nelle raccomandazioni per il mantenimento a lungo termine degli utenti.
SISTEMI DI RACCOMANDAZIONE
Un esame dei fattori che contribuiscono a una buona raccomandazione e alla fidelizzazione a lungo termine degli utenti

Un Legame di Fiducia Formatosi in un Bar
Sei seduto in un bar, gustando la tua variante di caffè preferita (un cappuccino, ovviamente) e immerso in conversazione con un amico. Mentre la conversazione fluisce, l’argomento passa alla più recente serie TV avvincente a cui entrambi siete stati appassionati. L’eccitazione condivisa crea un legame di fiducia, tanto da spingere il tuo amico a rivolgersi a te con entusiasmo e a chiedere: “Cosa dovrei guardare ora? Hai qualche raccomandazione?”
In quel momento, diventi il curatore della loro esperienza di intrattenimento. Senti un senso di responsabilità per preservare la loro fiducia e fornire suggerimenti che sono garantiti per catturarli. Inoltre, sei entusiasta all’idea di poter eventualmente introdurre loro un genere o una trama leggermente diversi da quelli esplorati in precedenza.
Ma quali sono i fattori che influenzano il tuo processo decisionale nel considerare le raccomandazioni perfette per il tuo amico?
Cosa fa una buona raccomandazione?

Prima di tutto, attingi alla tua conoscenza dei gusti e degli interessi del tuo amico. Ti ricordi della loro predilezione per trame intricate e umorismo nero; inoltre, sai che hanno apprezzato i drammi criminali come “Sherlock” e i thriller psicologici come “Black Mirror”. Armato di questa conoscenza, navighi nella tua libreria mentale di programmi TV.
- Da Python a Julia Feature Engineering e ML
- Atlante dei Vasi Sanguigni del Cervello Umano Evidenzia le Modifiche nella Malattia di Alzheimer.
- La Variabile PATH per il Data Scientist Confuso Come Gestirla
Giocare sicuro?
Sei tentato di suggerire un elenco di programmi che sono quasi identici, con lievi variazioni, a quello su cui hai appena esclamato, che comprendono sia crimine che thriller. Pensi anche a come altri con gusti simili hanno apprezzato questi programmi per restringere le tue scelte. Dopotutto, sono praticamente garantiti ad apprezzare questo set; è la scelta sicura ed facile. Tuttavia, consideri che fare affidamento esclusivamente sui loro favoriti passati potrebbe limitare la loro esposizione a nuovi e diversi contenuti e non vuoi particolarmente fare affidamento sulla scelta facile e sicura.
Ti ricordi di una serie di fantascienza recente che mescola in modo geniale mistero, avventura e intrighi soprannaturali. Anche se si discosta dal loro genere tipico, sei sicuro che fornirà un cambiamento narrativo rinfrescante e coinvolgente.
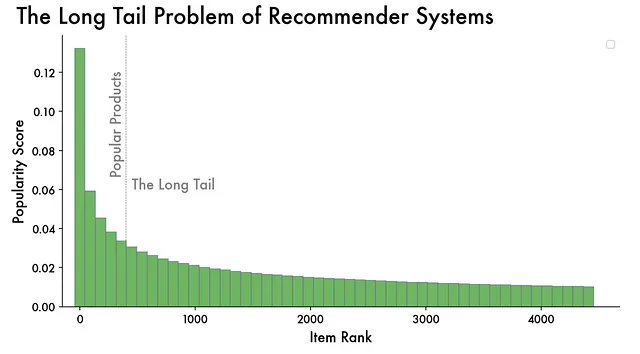
Il Problema della Coda Lunga, il Feedback Loop e le Bolle dei Filtri
I sistemi di raccomandazione mirano a replicare questo processo su scala più ampia. Analizzando grandi quantità di dati sulle preferenze, i comportamenti e le esperienze passate degli individui, questi sistemi si sforzano di generare raccomandazioni personalizzate che comprendono la complessità della decisione umana.
Tuttavia, tradizionalmente, i sistemi di raccomandazione si sono concentrati principalmente – se non esclusivamente – nel giocare sicuro e fare affidamento sulle raccomandazioni che sono garantite per soddisfare (almeno a breve termine).
Uno dei modi in cui ciò avviene è la priorità data ai contenuti popolari o mainstream. Di conseguenza, questi contenuti popolari ricevono più esposizione e interazioni (popularity bias), creando un feedback loop che ne rafforza la prominenza. Purtroppo, ciò spesso lascia ai contenuti meno conosciuti o di nicchia difficoltà a guadagnare visibilità e raggiungere il pubblico previsto (il problema della coda lunga).
In effetti, negli ultimi anni c’è stata molta letteratura che esamina la “giustizia” nei sistemi di raccomandazione. Ad esempio, in “Fairness in Music Recommender Systems: A Stakeholder-Centered Mini Review”, Karlijn Dinnissen e Christine Bauer esplorano la questione della giustizia nei sistemi di raccomandazione musicale; analizzano l’equità di genere e il bias di popolarità dal punto di vista di più stakeholder, ad esempio l’impatto del bias di popolarità sulla rappresentazione degli artisti.
Nell’articolo “Equità in questione: gli algoritmi di raccomandazione musicale valorizzano la diversità?”, Julie Knibbe condivide:
Come ex direttore del prodotto presso una piattaforma di streaming, spesso ricevo domande come “i servizi di streaming scelgono di promuovere artisti popolari rispetto a quelli indipendenti e di nicchia?” Intuitivamente, le persone assumono che su queste grandi piattaforme “i ricchi diventano sempre più ricchi”.
In seguito nell’articolo, Knibbe ribadisce anche il sentimento di Dinnissen e Bauer:
“Nel contesto della raccomandazione musicale […] l’equità è spesso definita in termini di esposizione o attenzione. I servizi di streaming sono anche un mercato a due facce, il che significa che “il trattamento imparziale e giusto” deve applicarsi sia agli utenti dei servizi di streaming che agli artisti.
Entrambe le fonti sottolineano la natura duplice dell’equità nei sistemi di raccomandazione, sottolineando l’importanza di considerare un “trattamento imparziale e giusto” per gli utenti e i creatori di contenuti.
Come dovrebbe essere il risultato ideale?
Naturalmente, esiste un dislivello intrinseco nella distribuzione dei contenuti. Parte di ciò che rende ricca l’esperienza umana risiede nella sua complessità di rete; alcuni contenuti risuonano con un pubblico più ampio, mentre altri creano connessioni all’interno di gruppi di nicchia, sviluppando un senso di ricchezza e personalizzazione. L’obiettivo non è quello di promuovere artificialmente contenuti meno popolari per il gusto di farlo, cercando una distribuzione uniforme. Piuttosto, il nostro obiettivo è di mettere in evidenza i contenuti di nicchia alle persone che si relazionano genuinamente e possono apprezzare il lavoro del creatore di contenuti, minimizzando così le opportunità mancate per connessioni significative.
Cosa dice l’industria a riguardo?
Nel 2020, il team di ricerca di Spotify ha pubblicato un articolo dal titolo “Effetti algoritmici sulla diversità del consumo su Spotify”. Nella loro ricerca, hanno esaminato la relazione tra la diversità di ascolto e i risultati degli utenti.
Hanno cercato di rispondere alle domande: “Come si relaziona la diversità con importanti risultati degli utenti? Gli utenti che ascoltano in modo diversificato sono più o meno soddisfatti di quelli che ascoltano in modo ristretto?”
I ricercatori hanno scoperto che “gli utenti con un ascolto diversificato sono tra il 10-20% meno propensi a disdire rispetto a quelli con un ascolto meno diversificato […] la diversità di ascolto è associata alla conversione degli utenti e alla fidelizzazione.”
Inoltre, secondo Julie Knibbe:
“L’algoritmo di raccomandazione di TikTok è stato recentemente citato tra i primi 10 […] dalla rivista MIT Technology Review. Ciò che è innovativo nel loro approccio non è l’algoritmo stesso, ma le metriche che stanno ottimizzando, dando maggior peso alla diversità rispetto ad altri fattori.”
Ciò significa che c’è una connessione tra l’attributo di scoperta all’interno di una piattaforma e la fidelizzazione degli utenti. In altre parole, quando le raccomandazioni diventano prevedibili, gli utenti potrebbero cercare alternative che offrano un maggiore senso di “freschezza” nei contenuti, consentendo loro di sfuggire ai confini delle bolle di filtro.
Quindi come possono i sistemi di raccomandazione emulare la riflessione e l’intuizione che hai impiegato nel curare la perfetta raccomandazione per il tuo amico?
Il passaggio alle metriche di diversità
Bene, nell’articolo “Diversità, serendipità, novità e copertura: un’analisi empirica e di survey degli obiettivi al di là dell’accuratezza nei sistemi di raccomandazione”, gli autori Marius Kaminskas e Derek Bridge evidenziano:
“La ricerca sui sistemi di raccomandazione si è tradizionalmente concentrata sull’accuratezza […] tuttavia, si è riconosciuto che altre qualità della raccomandazione – come ad esempio se l’elenco delle raccomandazioni è diverso e se contiene elementi nuovi – possono avere un impatto significativo sulla qualità complessiva di un sistema di raccomandazione. Di conseguenza […] l’attenzione della ricerca sui sistemi di raccomandazione si è spostata per includere una gamma più ampia di obiettivi “oltre l’accuratezza”.
Quali sono questi obiettivi “oltre l’accuratezza”?
Diversità
Esaminando la letteratura nel tentativo di capire cosa sia la ‘diversità’ nei sistemi di raccomandazione è stato brutale, poiché ogni articolo presentava la propria definizione unica. La diversità può essere misurata sia a livello individuale che globale. Andremo attraverso tre modi per concettualizzare la diversità, nel contesto di dare raccomandazioni di spettacoli a un amico.
Diversità delle previsioni
La diversità delle previsioni si riferisce alla misura di quanto varie sono le raccomandazioni all’interno di un dato insieme. Quando consigli un insieme di spettacoli al tuo amico, la diversità delle previsioni valuta fino a che punto le raccomandazioni differiscono tra loro in termini di generi, temi o altri fattori rilevanti.
Una maggiore diversità delle previsioni indica una gamma più ampia di opzioni all’interno dell’insieme raccomandato, offrendo al tuo amico un’esperienza di visione più diversificata e potenzialmente arricchente.
Un modo per misurare questo è utilizzando diversità intra-lista (ILD), che è la dissimilarità media a coppie tra gli elementi raccomandati. Data la lista degli elementi raccomandati, la ILD è definita come segue:

Diversità dell’utente
La diversità dell’utente, nel contesto di fornire raccomandazioni di spettacoli a un amico, esamina la diversità media di tutte le raccomandazioni che hai mai dato a quel particolare amico. Considera la vastità e la varietà dei contenuti suggeriti nel tempo, catturando la gamma di generi, temi o altri fattori rilevanti coperti.
Puoi anche valutare la diversità dell’utente analizzando la dissimilarità media tra i vettori di rappresentazione degli elementi all’interno di ogni insieme di raccomandazioni per amico.
Diversità globale
D’altra parte, la diversità globale guarda oltre un amico specifico e valuta la diversità media di tutte le raccomandazioni che hai dato a qualsiasi amico.
A volte, questo è indicato come congestione – una riflessione dell’uniformità delle raccomandazioni o dell’affollamento delle raccomandazioni.
Un paio di metriche che puoi utilizzare per analizzare la diversità globale includono l’indice di Gini e l’entropia.
L’indice di Gini, adattato dal campo della misura dell’ineguaglianza dei redditi, può essere utilizzato per valutare l’equità e l’equilibrio delle distribuzioni delle raccomandazioni nei sistemi di raccomandazione. Un indice di Gini più basso indica una distribuzione più equa, dove le raccomandazioni sono distribuite uniformemente, promuovendo una maggiore diversità e esposizione a una gamma più ampia di contenuti. D’altra parte, un indice di Gini più alto suggerisce una concentrazione di raccomandazioni su pochi elementi popolari, potenzialmente limitando la visibilità dei contenuti di nicchia e riducendo la diversità delle raccomandazioni.
Entropia è una misura della quantità di informazioni contenute nel processo di raccomandazione. Quantifica il livello di incertezza o casualità nella distribuzione delle raccomandazioni. Similmente all’indice di Gini, l’entropia ottimale si raggiunge quando la distribuzione delle raccomandazioni è uniforme, il che significa che ogni elemento ha la stessa probabilità di essere raccomandato. Ciò indica un insieme equilibrato e diversificato di raccomandazioni. L’entropia maggiore suggerisce un sistema di raccomandazione più vario e imprevedibile, mentre un’entropia inferiore indica un insieme di raccomandazioni più concentrato e prevedibile.
Copertura
La copertura è definita come la porzione/proporzione di raccomandazioni possibili che l’algoritmo può produrre. In altre parole, quanto bene le raccomandazioni coprono il catalogo degli elementi disponibili.
Ad esempio, consideriamo una piattaforma di streaming musicale con una vasta libreria di brani che spaziano tra vari generi, artisti e decenni. La copertura dell’algoritmo di raccomandazione indicherebbe quanto efficacemente può coprire l’intera libreria musicale quando suggerisce brani agli utenti.
Svantaggio: questa metrica tratta un elemento raccomandato una volta come lo stesso di un elemento raccomandato migliaia di volte
Novità
La novità è una metrica utilizzata per valutare il livello di novità o originalità degli elementi raccomandati. Comprende due aspetti: novità dipendente dall’utente e novità indipendente dall’utente. La novità dipendente dall’utente misura quanto le raccomandazioni siano diverse o sconosciute per l’utente, indicando la presenza di contenuti freschi e inesplorati. Tuttavia, è diventato sempre più comune riferirsi alla novità di un elemento in modo indipendente dall’utente.
Per stimare la novità, un approccio comune è considerare la popolarità di un elemento, misurata come rarità dell’elemento. Questo approccio relaziona in modo inverso la novità di un elemento alla sua popolarità, riconoscendo che gli elementi meno popolari sono spesso percepiti come più nuovi a causa della loro deviazione dalle scelte mainstream o ampiamente conosciute. Integrando questa prospettiva, le metriche di novità forniscono insights sul livello di innovazione e diversità presenti negli elementi raccomandati, contribuendo a un’esperienza di raccomandazione più arricchente ed esplorativa.
Inatteso (Sorpresa)
La sorpresa nei sistemi di raccomandazione misura il livello di imprevedibilità degli elementi consigliati in base alle interazioni passate dell’utente. Un modo per quantificare la sorpresa è calcolare la similarità coseno tra gli elementi consigliati e le interazioni passate dell’utente. Una maggiore similarità indica meno sorpresa, mentre una minore similarità indica maggiore sorpresa nelle raccomandazioni.
Discoverability
La discoverability nei sistemi di raccomandazione si può intendere come la capacità dell’utente di trovare facilmente le raccomandazioni suggerite dal modello. È simile alla visibilità e all’accessibilità delle raccomandazioni nell’interfaccia utente o nella piattaforma.
Viene quantificata utilizzando una funzione di sconto di rango decrescente, che assegna maggiore importanza alle raccomandazioni nei primi posti della lista e gradualmente diminuisce il loro peso man mano che la posizione del rango diminuisce.
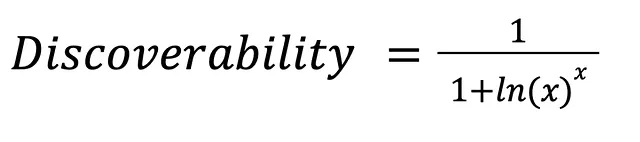
Serendipity
La serendipità nei sistemi di raccomandazione comprende due aspetti fondamentali: l’imprevedibilità e la rilevanza.
La serendipità si riferisce all’occorrenza di piacevoli sorprese o alla scoperta di raccomandazioni interessanti e impreviste. Per quantificare la serendipità, viene calcolata su base per utente e per elemento utilizzando la formula:
Moltiplicando l’imprevedibilità e la rilevanza, la metrica della serendipità combina gli elementi di piacevole sorpresa e idoneità. Quantifica il grado in cui una raccomandazione è sia imprevista che pertinente, fornendo una misura di esperienze serendipitose nel processo di raccomandazione.
La serendipità complessiva media tra gli utenti e gli elementi consigliati può essere calcolata come:
Considerazioni conclusive
Con l’evolversi dell’industria, c’è una crescente enfasi sul raffinamento degli algoritmi di raccomandazione per fornire raccomandazioni che comprendano l’intera gamma di preferenze dell’utente, inclusa una personalizzazione più ricca, serendipità e novità. Inoltre, i sistemi di raccomandazione che ottimizzano il bilanciamento tra queste dimensioni sono stati associati a metriche di retention e user experience migliorate. In definitiva, l’obiettivo è creare sistemi di raccomandazione che non solo soddisfino le preferenze conosciute degli utenti, ma li sorprendano e li delizino con raccomandazioni fresche, diverse e personalmente pertinenti, favorendo l’engagement e la soddisfazione a lungo termine.
Riferimenti
- Diversity, Serendipity, Novelty, and Coverage: A Survey and Empirical Analysis of Beyond-Accuracy Objectives in Recommender Systems
- Post Processing Recommender Systems for Diversity
- Diversity in recommender systems — A survey
- Avoiding congestion in recommender systems
- The Definition of Novelty in Recommendation System
- Novelty and Diversity in Recommender Systems: an Information Retrieval approach for evaluation and improvement
- Quantifying Availability and Discovery in Recommender Systems via Stochastic Reachability
- A new system-wide diversity measure for recommendations with efficient algorithms
- Automatic Evaluation of Recommendation Systems: Coverage, Novelty and Diversity
- Serendipity: Accuracy’s Unpopular Best Friend in Recommenders