Da Python a Julia Feature Engineering e ML
From Python to Julia Feature Engineering and ML

Un approccio basato su Julia per la creazione di un modello di rilevamento delle frodi
Questo è il secondo articolo della mia serie di due parti su come iniziare con Julia per la scienza dei dati applicata. Nel primo articolo, abbiamo esaminato alcuni esempi di semplice manipolazione dei dati ed esplorazione dei dati in Julia. In questo blog, continueremo il compito di costruire un modello di rilevamento delle frodi per identificare le transazioni fraudolente.
Per fare un breve riassunto, abbiamo utilizzato un set di dati di rilevamento delle frodi con carta di credito ottenuto da Kaggle. Il set di dati contiene 30 funzionalità, tra cui il tempo di transazione, l’importo e 28 funzionalità principali basate su componenti ottenute con PCA. Di seguito è riportata uno screenshot dei primi 5 casi del set di dati, caricati come dataframe in Julia. Si noti che la funzionalità del tempo di transazione registra il tempo trascorso (in secondi) tra la transazione corrente e la prima transazione nel set di dati.
Ingegneria delle caratteristiche
Prima di addestrare il modello di rilevamento delle frodi, prepariamo i dati pronti per il modello da utilizzare. Poiché lo scopo principale di questo blog è quello di introdurre Julia, non eseguiremo alcuna selezione delle funzionalità o sintesi delle funzionalità qui.
Divisione dei dati
Quando si addestra un modello di classificazione, i dati vengono tipicamente divisi per l’addestramento e il test in modo stratificato. Lo scopo principale è mantenere la distribuzione dei dati rispetto alla variabile di classe target sia nei dati di addestramento che nei dati di test. Ciò è particolarmente necessario quando si lavora con un set di dati con squilibrio estremo. Il pacchetto MLDataUtils in Julia fornisce una serie di funzioni di pre-elaborazione, tra cui la suddivisione dei dati, la codifica delle etichette e la normalizzazione delle funzionalità. Il codice seguente mostra come eseguire il campionamento stratificato utilizzando la funzione stratifiedobs di MLDataUtils. È possibile impostare un seme casuale in modo che la stessa suddivisione dei dati possa essere riprodotta.
- Atlante dei Vasi Sanguigni del Cervello Umano Evidenzia le Modifiche nella Malattia di Alzheimer.
- La Variabile PATH per il Data Scientist Confuso Come Gestirla
- Inserisci le tue innovazioni di sintesi dei dati per riformare la polizia e vincere denaro.
Dividi i dati per l’addestramento e il test – implementazione in Julia
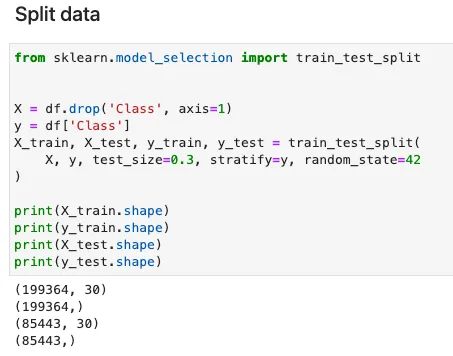
L’uso della funzione stratifiedobs è abbastanza simile alla funzione train_test_split della libreria sklearn in Python. Si noti che le funzionalità di input X devono passare due volte per il trasporto per ripristinare le dimensioni originali del set di dati. Questo può essere confuso per un principiante di Julia come me. Non sono sicuro del perché l’autore di MLDataUtils abbia sviluppato la funzione in questo modo.
L’implementazione equivalente in Python di sklearn è la seguente.
Ridimensionamento delle funzionalità
Come pratica consigliata nell’apprendimento automatico, il ridimensionamento delle funzionalità porta le funzionalità ai medesimi o simili intervalli di valori o distribuzione. Il ridimensionamento delle funzionalità aiuta a migliorare la velocità di convergenza durante l’addestramento delle reti neurali e impedisce anche la dominazione di qualsiasi funzionalità individuale durante l’addestramento.
Anche se non stiamo addestrando un modello di rete neurale in questo lavoro, mi piacerebbe comunque scoprire come eseguire il ridimensionamento delle funzionalità in Julia. Sfortunatamente, non ho trovato una libreria Julia che fornisca entrambe le funzioni di adattamento dello scalatore e trasformazione delle funzionalità. Le funzioni di normalizzazione delle funzionalità fornite nel pacchetto MLDataUtils consentono agli utenti di derivare la media e la deviazione standard delle funzionalità, ma non possono essere facilmente applicate sui set di dati di addestramento / test per trasformare le funzionalità. Poiché la media e la deviazione standard delle funzionalità possono essere facilmente calcolate in Julia, possiamo implementare manualmente il processo di ridimensionamento standard.
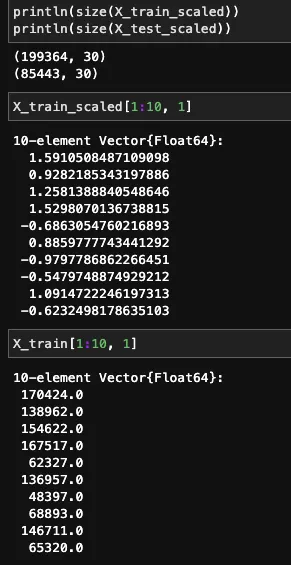
Il codice seguente crea una copia di X_train e X_test e calcola la media e la deviazione standard di ogni funzionalità in un ciclo.
Ridimensiona le funzionalità – implementazione in Julia
Le funzionalità trasformate e originali sono mostrate di seguito.
In Python, sklearn fornisce varie opzioni per la ridimensionamento delle caratteristiche, inclusa la normalizzazione e la standardizzazione. Dichiarando uno scaler delle caratteristiche, il ridimensionamento può essere fatto con due righe di codice. Il seguente codice dà un esempio di utilizzo di un RobustScaler .

Oversampling (tramite PyCall)
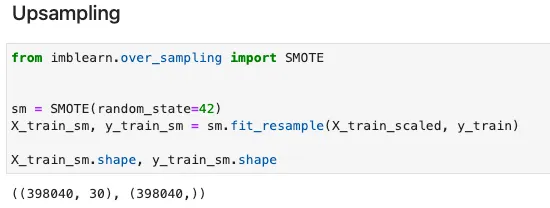
Un dataset di rilevamento delle frodi è tipicamente fortemente sbilanciato. Ad esempio, il rapporto di esempi negativi su quelli positivi del nostro dataset è superiore a 500:1. Poiché ottenere più punti dati non è possibile, la sottocampionatura comporterà una enorme perdita di punti dati dalla classe di maggioranza, l’oversampling diventa la migliore opzione in questo caso. Qui applico il metodo SMOTE popolare per creare esempi sintetici per la classe positiva.
Attualmente, non esiste una libreria Julia funzionante che fornisca l’implementazione di SMOTE. Il pacchetto ClassImbalance non è stato mantenuto per due anni e non può essere utilizzato con le versioni recenti di Julia. Fortunatamente, Julia ci consente di chiamare i pacchetti Python pronti all’uso utilizzando una libreria wrapper chiamata PyCall .
Per importare una libreria Python in Julia, dobbiamo installare PyCall e specificare il PYTHONPATH come variabile d’ambiente. Ho cercato di creare un ambiente virtuale Python qui ma non ha funzionato. Per qualche motivo, Julia non può riconoscere il percorso python dell’ambiente virtuale. Ecco perché devo specificare il percorso predefinito di python del sistema. Dopo questo, possiamo importare l’implementazione Python di SMOTE, che è fornita nella libreria imbalanced-learn. La funzione pyimport fornita da PyCall può essere utilizzata per importare le librerie Python in Julia. Il seguente codice mostra come attivare PyCall e chiedere aiuto a Python in un kernel di Julia.
Upsample dei dati di formazione con SMOTE – Implementazione in Julia
L’equivalente implementazione in Python è la seguente. Possiamo vedere che la funzione fit_resample viene utilizzata in modo simile in Julia.
Addestramento del modello
Ora raggiungiamo la fase di addestramento del modello. Addestreremo un classificatore binario, che può essere fatto con una varietà di algoritmi di ML, inclusa la regressione logistica, l’albero decisionale e le reti neurali. Attualmente, le risorse per ML in Julia sono distribuite su più librerie Julia. Elencherò alcune delle opzioni più popolari con il loro set specializzato di modelli.
- MLJ : algoritmi di ML tradizionali
- ScikitLearn : algoritmi di ML tradizionali
- Mocha : reti neurali
- Flux : reti neurali
Qui ho scelto XGBoost , considerando la sua semplicità e le prestazioni superiori rispetto ai problemi di regressione e classificazione tradizionali. Il processo di addestramento di un modello XGBoost in Julia è lo stesso di quello di Python, sebbene ci sia una differenza minore nella sintassi.
Formare un modello di rilevamento delle frodi con XGBoost – Implementazione in Julia
L’equivalente implementazione in Python è la seguente.
Valutazione del modello
Infine, vediamo come si comporta il nostro modello guardando la precisione, il richiamo ottenuti sui dati di test, così come il tempo impiegato per addestrare il modello. In Julia, la precisione, le metriche di richiamo possono essere calcolate utilizzando la libreria EvalMetrics. Un pacchetto alternativo è MLJBase per lo stesso scopo.
Fare previsioni e calcolare le metriche – Implementazione in Julia
In Python, possiamo impiegare sklearn per calcolare le metriche.
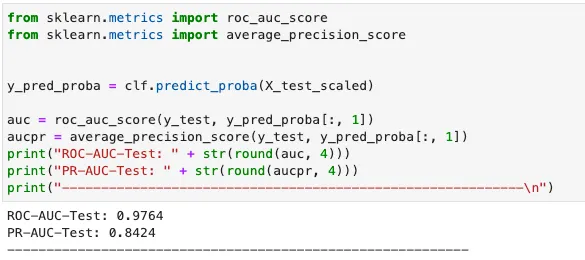
Quindi chi è il vincitore tra Julia e Python? Per fare un confronto equo, entrambi i modelli sono stati addestrati con gli iperparametri predefiniti, e tasso di apprendimento = 0,1, numero di estimatori = 1000. Le metriche di performance sono riassunte nella seguente tabella.
Si può osservare che il modello Julia raggiunge una precisione e un richiamo migliori con un tempo di addestramento leggermente più lungo. Poiché la libreria XGBoost utilizzata per addestrare il modello Python è scritta in C++ sotto il cofano, mentre la libreria Julia XGBoost è completamente scritta in Julia, Julia esegue velocemente come C++, proprio come dichiarato!
L’hardware utilizzato per il test sopra menzionato: 11th Gen Intel® Core™ i7–1165G7 @ 2.80GHz – 4 core.
Il notebook Jupyter può essere trovato su Github.
Takeaways
Vorrei concludere questa serie con un riassunto delle librerie Julia menzionate per diversi compiti di data science.
A causa della mancanza di supporto della comunità, l’usabilità di Julia al momento non può essere paragonata a Python. Tuttavia, data la sua performance superiore, Julia ha ancora un grande potenziale per il futuro.
Riferimenti
- Gruppo di Machine Learning di ULB (Université Libre de Bruxelles). (nessuna data). Rilevamento delle frodi con le carte di credito [Dataset]. H i i (Database Contents License (DbCL))
- Akshay Gupta. 13 maggio 2021. Iniziare il Machine Learning con Julia: le migliori librerie Julia per il Machine Learning. https://www.analyticsvidhya.com/blog/2021/05/top-julia-machine-learning-libraries/