Gestione dei costi di archiviazione cloud delle applicazioni Big-Data
Cloud storage cost management for Big-Data applications.
Consigli per ridurre i costi dell’uso di storage basato su Cloud

Con la crescente dipendenza di quantità sempre maggiori di dati, le aziende moderne sono più dipendenti che mai da soluzioni di archiviazione dati ad alta capacità e scalabilità. Per molte aziende, questa soluzione si presenta sotto forma di servizi di storage basati su Cloud, come Amazon S3, Google Cloud Storage e Azure Blob Storage, ognuno dei quali viene fornito con una vasta gamma di API e funzionalità (ad esempio, storage multi-tier) che supportano una vasta gamma di design di storage dati. Naturalmente, i servizi di storage cloud hanno anche un costo associato. Questo costo è di solito composto da un certo numero di componenti, tra cui la dimensione complessiva dello spazio di storage utilizzato, nonché le attività di trasferimento dei dati in, fuori o all’interno dello storage cloud. Il prezzo di Amazon S3, ad esempio, include (al momento della scrittura di questo testo) sei componenti di costo, ognuno dei quali deve essere preso in considerazione. È facile capire come gestire il costo dello storage cloud possa diventare complicato, e sono stati sviluppati appositi calcolatori (ad esempio, qui) per assistere nell’operazione.
In un recente post, abbiamo ampliato l’importanza di progettare i dati e l’utilizzo dei dati in modo da ridurre i costi associati all’archiviazione dei dati. Il nostro focus era sull’utilizzo della compressione dei dati come modo per ridurre la dimensione complessiva dei dati. In questo post ci concentriamo su una componente di costo a volte trascurata dello storage cloud – il costo delle richieste API effettuate sui tuoi bucket di storage cloud e sugli oggetti dati. Dimostreremo, ad esempio, perché questa componente viene spesso sottovalutata e come possa diventare una parte significativa del costo della tua applicazione big data, se non gestita correttamente. Discuteremo quindi un paio di modi semplici per mantenere questo costo sotto controllo.
Dichiarazioni di non responsabilità
Sebbene le nostre dimostrazioni utilizzeranno Amazon S3, i contenuti di questo post sono altrettanto applicabili a qualsiasi altro servizio di storage cloud. Si prega di non interpretare la nostra scelta di Amazon S3 o qualsiasi altro strumento, servizio o libreria che dobbiamo menzionare, come un’approvazione del loro uso. La migliore opzione per te dipenderà dai dettagli unici del tuo progetto. Inoltre, si prega di tenere presente che ogni scelta di progettazione riguardo a come archiviare e utilizzare i tuoi dati avrà i suoi pro e contro che dovrebbero essere valutati attentamente in base ai dettagli del tuo progetto.
Questo post includerà una serie di esperimenti che sono stati eseguiti su un’istanza Amazon EC2 c5.4xlarge (con 16 vCPU e “fino a 10 Gbps” di larghezza di banda di rete). Condivideremo i loro output come esempi dei risultati comparativi che potresti vedere. Tieni presente che gli output possono variare notevolmente in base all’ambiente in cui vengono eseguiti gli esperimenti. Si prega di non fare affidamento sui risultati presentati qui per le tue decisioni di progettazione. Ti incoraggiamo vivamente a eseguire questi e altri esperimenti prima di decidere cosa sia meglio per i tuoi progetti.
- Svelare il Cox un oscuro segreto nascosto della regressione di Cox.
- Analizza le tendenze del ghiaccio artico con Python
- Come utilizzare il metodo Pandas loc per lavorare efficientemente con il tuo DataFrame.
Un semplice esperimento mentale
Supponiamo di avere un’applicazione di trasformazione dati che opera su campioni di dati da 1 MB da S3 e produce output di dati da 1 MB che vengono caricati su S3. Supponiamo che tu abbia il compito di trasformare 1 miliardo di campioni di dati eseguendo la tua applicazione su un’opportuna istanza Amazon EC2 (nella stessa regione del tuo bucket S3 per evitare costi di trasferimento dati). Ora supponiamo che Amazon S3 addebiti $0,0004 per ogni 1000 operazioni GET e $0,005 per ogni 1000 operazioni PUT (al momento della scrittura di questo testo). A prima vista, questi costi potrebbero sembrare così bassi da essere trascurabili rispetto agli altri costi relativi alla trasformazione dei dati. Tuttavia, un semplice calcolo mostra che le sole chiamate alle API di Amazon S3 ammontano a ben $5.400!! Questo può facilmente diventare il fattore di costo dominante del tuo progetto, anche più del costo dell’istanza di calcolo. Torneremo a questo esperimento mentale alla fine del post.
Raggruppare i dati in grandi file
Il modo ovvio per ridurre i costi delle chiamate alle API è di raggruppare i campioni insieme in file di dimensioni maggiori ed eseguire la trasformazione su batch di campioni. Denotando la nostra dimensione di batch con N, questa strategia potrebbe potenzialmente ridurre il nostro costo di un fattore N (assumendo che il trasferimento di file multi-part non venga utilizzato – vedere sotto). Questa tecnica risparmierebbe denaro non solo sulle chiamate PUT e GET ma su tutte le componenti di costo di Amazon S3 che dipendono dal numero di file oggetto anziché dalla dimensione complessiva dei dati (ad esempio, richieste di transizione del ciclo di vita).
Ci sono diversi svantaggi nel raggruppare i campioni insieme. Ad esempio, quando si archiviano i campioni individualmente, si può accedere liberamente a ognuno di essi a piacere. Questo diventa più difficile quando i campioni sono raggruppati insieme. (Vedi questo post per maggiori informazioni sui pro e contro del batching dei campioni in file grandi.) Se si opta per il raggruppamento dei campioni insieme, la grande domanda è come scegliere la dimensione N. Un N più grande potrebbe ridurre i costi di archiviazione, ma potrebbe introdurre latenza, aumentare il tempo di calcolo e, di conseguenza, aumentare i costi di calcolo. Trovare il numero ottimale potrebbe richiedere un po’ di sperimentazione che tenga conto di questi e di ulteriori fattori.
Ma non illudiamoci. Fare questo tipo di cambiamento non sarà facile. I tuoi dati potrebbero avere molti consumatori (sia umani che artificiali), ognuno con il proprio particolare insieme di esigenze e vincoli. Archiviare i tuoi campioni in file separati può rendere più facile mantenere tutti felici. Trovare una strategia di batching che soddisfi tutti sarà difficile.
Compromesso Possibile: Batched Puts, Individual Gets
Un compromesso che si potrebbe considerare è caricare file grandi con campioni raggruppati e consentire l’accesso ai singoli campioni. Un modo per farlo è mantenere un file di indice con le posizioni di ogni campione (il file in cui è raggruppato, l’offset di inizio e l’offset di fine) e esporre uno strato API sottile a ciascun consumatore che consentirebbe loro di scaricare liberamente i singoli campioni. L’API sarebbe implementata utilizzando il file di indice e un’API S3 che consente di estrarre intervalli specifici dai file oggetto (ad esempio, la funzione get_object di Boto3). Anche se questo tipo di soluzione non risparmierebbe denaro sulle chiamate GET (poiché stiamo ancora recuperando lo stesso numero di campioni individuali), le chiamate PUT più costose sarebbero ridotte poiché caricheremmo un numero inferiore di file più grandi. Si noti che questo tipo di soluzione pone alcune limitazioni sulla libreria che utilizziamo per interagire con S3 in quanto dipende da un’API che consente di estrarre parti parziali degli oggetti dei file grandi. In precedenti post (ad esempio, qui) abbiamo discusso i diversi modi di interfacciarsi con S3, molti dei quali non supportano questa caratteristica.
Il blocco di codice qui sotto mostra come implementare un semplice dataset PyTorch (con la versione PyTorch 1.13) che utilizza l’API get_object di Boto3 per estrarre campioni individuali da 1 MB da file grandi di campioni raggruppati. Confrontiamo la velocità di iterazione dei dati in questo modo con l’iterazione dei campioni che sono archiviati in file individuali.
import os, boto3, time, numpy as npimport torchfrom torch.utils.data import Datasetfrom statistics import mean, varianceKB = 1024MB = KB * KBGB = KB ** 3sample_size = MBnum_samples = 100000# modificare per variare la dimensione dei filessamples_per_file = 2000 # per file da 2 GBnum_files = num_samples//samples_per_filebucket = '<s3 bucket>'single_sample_path = '<path in s3>'large_file_path = '<path in s3>'class SingleSampleDataset(Dataset): def __init__(self): super().__init__() self.bucket = bucket self.path = single_sample_path self.client = boto3.client("s3") def __len__(self): return num_samples def get_bytes(self, key): response = self.client.get_object( Bucket=self.bucket, Key=key ) return response['Body'].read() def __getitem__(self, index: int): key = f'{self.path}/{index}.image' image = np.frombuffer(self.get_bytes(key),np.uint8) return {"image": image}class LargeFileDataset(Dataset): def __init__(self): super().__init__() self.bucket = bucket self.path = large_file_path self.client = boto3.client("s3") def __len__(self): return num_samples def get_bytes(self, file_index, sample_index): response = self.client.get_object( Bucket=self.bucket, Key=f'{self.path}/{file_index}.bin', Range=f'bytes={sample_index*MB}-{(sample_index+1)*MB-1}' ) return response['Body'].read() def __getitem__(self, index: int): file_index = index // num_files sample_index = index % samples_per_file image = np.frombuffer(self.get_bytes(file_index, sample_index), np.uint8) return {"image": image}# passare dai file di singoli campioni ai file grandiuse_grouped_samples = Trueif use_grouped_samples: dataset = LargeFileDataset()else: dataset = SingleSampleDataset()# impostare il numero di worker paralleli in base al numero di vCPUsdl = torch.utils.data.DataLoader(dataset, shuffle=True, batch_size=4, num_workers=16)stats_lst = []t0 = time.perf_counter()for batch_idx, batch in enumerate(dl, start=1): if batch_idx % 100 == 0: t = time.perf_counter() - t0 stats_lst.append(t) t0 = time.perf_counter()mean_calc = mean(stats_lst)var_calc = variance(stats_lst)print(f'media {mean_calc} varianza {var_calc}')La tabella qui sotto riassume la velocità di attraversamento dei dati per diverse scelte della dimensione di raggruppamento del campione, N.
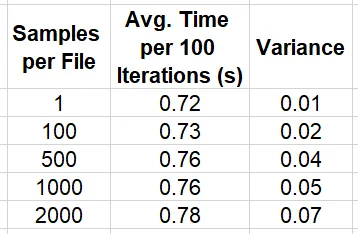
Si noti che sebbene questi risultati implicano fortemente che il raggruppamento dei campioni in file di grandi dimensioni ha un impatto relativamente limitato sulle prestazioni dell’estrazione individuale, abbiamo scoperto che i risultati comparativi variano in base alla dimensione del campione, alla dimensione del file, ai valori degli offsets del file, al numero di letture concorrenti dallo stesso file, ecc. Sebbene non siamo a conoscenza del funzionamento interno del servizio Amazon S3, non sorprende che considerazioni come la dimensione della memoria, l’allineamento della memoria e la limitazione della velocità possano influire sulle prestazioni. Trovare la configurazione ottimale per i tuoi dati richiederà probabilmente un po’ di sperimentazione.
Un fattore significativo che potrebbe interferire con la strategia di raggruppamento che abbiamo descritto qui per risparmiare denaro è l’uso del download e upload multi-parti, che discuteremo nella prossima sezione.
Usa strumenti che consentano il controllo sul trasferimento dei dati multi-parti
Molti fornitori di servizi di archiviazione cloud supportano l’opzione di caricamento e download multi-parti di file oggetto. Nel trasferimento di dati multi-parti, i file che superano una determinata soglia vengono divisi in più parti che vengono trasferite contemporaneamente. Questa è una funzione critica se si vuole velocizzare il trasferimento di dati di grandi dimensioni. AWS consiglia di utilizzare il caricamento multi-parti per i file di dimensioni superiori a 100 MB. Nell’esempio semplice seguente, confrontiamo il tempo di download di un file di 2 GB con soglia e dimensione del chunk multi-parti impostati su valori diversi:
import boto3, timeKB = 1024MB = KB * KBGB = KB ** 3s3 = boto3.client('s3')bucket = '<nome del bucket>'key = '<chiave del file di 2 GB>'local_path = '/tmp/2GB.bin'num_trials = 10for size in [8*MB, 100*MB, 500*MB, 2*GB]: print(f'dimensione multi-parti: {size}') stats = [] for i in range(num_trials): config = boto3.s3.transfer.TransferConfig(multipart_threshold=size, multipart_chunksize=size) t0 = time.time() s3.download_file(bucket, key, local_path, Config=config) stats.append(time.time()-t0) print(f'dimensione multi-parti {size} media {mean(stats)}')I risultati di questo esperimento sono riassunti nella tabella qui sotto:
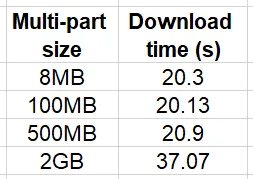
Si noti che il confronto relativo dipenderà molto dall’ambiente di prova e in particolare dalla velocità e dalla larghezza di banda della comunicazione tra l’istanza e il bucket S3. Il nostro esperimento è stato eseguito su un’istanza che si trovava nella stessa regione del bucket. Tuttavia, all’aumentare della distanza, aumenterà anche l’impatto dell’utilizzo del download multi-parti.
Per quanto riguarda l’argomento della nostra discussione, è importante notare le implicazioni sui costi del trasferimento dei dati multi-parti. In particolare, quando si utilizza il trasferimento dei dati multi-parti, si viene addebitati per l’operazione API di ciascuna delle parti del file. Di conseguenza, l’utilizzo del caricamento/download multi-parti limiterà il potenziale di risparmio sui costi del raggruppamento dei campioni di dati in file di grandi dimensioni.
Molte API utilizzano di default il download multi-parti. Questo è ottimo se il tuo interesse principale è ridurre la latenza della tua interazione con S3. Ma se ti preoccupa limitare i costi, questo comportamento predefinito non funziona a tuo favore. Boto3, ad esempio, è una popolare API di Python per il caricamento e il download di file da S3. Se non specificato, le API S3 di boto3 come upload_file e download_file utilizzeranno una TransferConfig predefinita, che applica il caricamento/download multi-parti con una dimensione di chunk di 8 MB a qualsiasi file più grande di 8 MB. Se sei responsabile del controllo dei costi cloud nella tua organizzazione, potresti scoprire con dispiacere che queste API vengono ampiamente utilizzate con le loro impostazioni predefinite. In molti casi, potresti trovare queste impostazioni ingiustificate e aumentare la soglia multi-parti e i valori della dimensione del chunk o disabilitare completamente il trasferimento dei dati multi-parti avrà poco impatto sulle prestazioni della tua applicazione.
Esempio – Impatto delle dimensioni di trasferimento dei file multiparti sulla velocità e sui costi
Nel blocco di codice qui sotto creiamo una semplice funzione di trasformazione multi-processo e misuriamo l’effetto della dimensione delle parti multiparti sulla sua performance e sui costi:
import os, boto3, time, mathfrom multiprocessing import Poolfrom statistics import mean, varianceKB = 1024MB = KB * KBsample_size = MBnum_files = 64samples_per_file = 500file_size = sample_size*samples_per_filenum_processes = 16bucket = '<s3 bucket>'large_file_path = '<path in s3>'local_path = '/tmp'num_trials = 5cost_per_get = 4e-7cost_per_put = 5e-6for multipart_chunksize in [1*MB, 8*MB, 100*MB, 200*MB, 500*MB]: def empty_transform(file_index): s3 = boto3.client('s3') config = boto3.s3.transfer.TransferConfig( multipart_threshold=multipart_chunksize, multipart_chunksize=multipart_chunksize ) s3.download_file(bucket, f'{large_file_path}/{file_index}.bin', f'{local_path}/{file_index}.bin', Config=config) s3.upload_file(f'{local_path}/{file_index}.bin', bucket, f'{large_file_path}/{file_index}.out.bin', Config=config) stats = [] for i in range(num_trials): with Pool(processes=num_processes) as pool: t0 = time.perf_counter() pool.map(empty_transform, range(num_files)) transform_time = time.perf_counter() - t0 stats.append(transform_time) num_chunks = math.ceil(file_size/multipart_chunksize) num_operations = num_files*num_chunks transform_cost = num_operations * (cost_per_get + cost_per_put) if num_chunks > 1: # se si utilizza la funzione multipart aggiungi il costo delle chiamate API CreateMultipartUpload e CompleteMultipartUpload transform_cost += 2 * num_files * cost_per_put print(f'dimensione parte {multipart_chunksize}') print(f'tempo di trasformazione {mean(stats)} varianza {variance(stats)} print(f'costo delle chiamate API {transform_cost}')In questo esempio abbiamo fissato la dimensione del file a 500 MB e applicato le stesse impostazioni multiparti sia per il download che per l’upload. Un’analisi più completa varierà la dimensione dei file di dati e le impostazioni multiparti.
Nella tabella sottostante riassumiamo i risultati dell’esperimento.
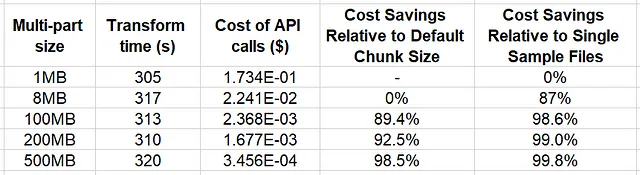
I risultati indicano che fino ad una dimensione di parte multiparti di 500 MB (la dimensione dei nostri file), l’impatto sul tempo di trasformazione dei dati è minimo. D’altra parte, il potenziale risparmio sui costi delle API di archiviazione cloud è significativo, fino al 98,4% rispetto all’utilizzo della dimensione predefinita di Boto3 (8MB). Questo esempio non solo dimostra il beneficio del costo di gruppare insieme i campioni, ma implica anche un’ulteriore opportunità di risparmio attraverso la configurazione appropriata delle impostazioni di trasferimento dati multiparti.
Conclusione
Applichiamo i risultati del nostro ultimo esempio al pensiero che abbiamo introdotto all’inizio di questo post. Abbiamo dimostrato che l’applicazione di una semplice trasformazione a 1 miliardo di campioni di dati costerebbe $5.400 se i campioni fossero archiviati in file individuali. Se raggruppassimo i campioni in 2 milioni di file, ognuno con 500 campioni, e applicassimo la trasformazione senza il trasferimento dati multiparti (come nell’ultimo esempio), il costo delle chiamate API sarebbe ridotto a $10,8!! Allo stesso tempo, assumendo lo stesso ambiente di test, l’impatto che ci aspetteremmo (sulla base dei nostri esperimenti) sulla durata complessiva sarebbe relativamente basso. Direi che è un affare molto vantaggioso per te, non trovi?
Sommario
Nello sviluppo di applicazioni big-data basate su cloud è essenziale che conosciamo tutti i dettagli dei costi delle nostre attività. In questo post ci siamo concentrati sul componente “Richieste e recupero dati” della strategia di prezzo di Amazon S3. Abbiamo dimostrato come questo componente possa diventare una parte significativa del costo complessivo di un’applicazione big-data. Abbiamo discusso due dei fattori che possono influire su questo costo: il modo in cui i campioni di dati vengono raggruppati insieme e il modo in cui viene utilizzato il trasferimento dati multiparti.
Naturalmente, ottimizzare solo un componente di costo è probabile che aumenti gli altri componenti in modo tale da aumentare il costo complessivo. Un design appropriato per la conservazione dei dati dovrà prendere in considerazione tutti i fattori potenziali di costo e dipenderà molto dalle esigenze specifiche dei tuoi dati e dai modelli di utilizzo.
Come al solito, non esitare a contattarci per commenti e correzioni.