Come utilizzare il metodo Pandas loc per lavorare efficientemente con il tuo DataFrame.
How to efficiently use the Pandas loc method with your DataFrame.
PYTHON
Consigli per esplorare e pulire un nuovo set di dati utilizzando Pandas con esempi di codice e spiegazioni
Una parte fondamentale del lavoro con un nuovo set di dati è comprenderlo.
Capire cose di base come quali colonne ci sono nei dati, quali sono i tipi di dati grezzi e le statistiche descrittive dei dati sono tutti importanti per lavorare correttamente con i dati in futuro.
Pandas ha diversi metodi integrati che puoi utilizzare per esplorare i tuoi dati in un notebook immediatamente. Mentre procedi con i primi passi dell’esplorazione dei dati, puoi contemporaneamente rendere i tuoi dati utilizzabili per ulteriori analisi o prepararli per la formazione di un modello di apprendimento automatico.
In questo pezzo, lavoriamo con un set di dati universitari per rispondere alle seguenti domande e mostrare cosa succede quando esplori e pulisci i dati contemporaneamente:
- Pandas 2.0 Una rivoluzione per i Data Scientist?
- Evoluzione del Paesaggio dei Dati
- Come Creare Grafici a Violino di Seaborn in Stile Cyberpunk con un Codice Python Minimale
- Quali università offrono solo partecipazione in presenza?
- Qual è l’intervallo di anni tra le università più vecchie e quelle più recenti fondate?
Innanzitutto, utilizzeremo principalmente il metodo loc in combinazione con alcuni altri metodi integrati di Pandas per rispondere a queste domande. Inizieremo con un’occhiata rapida a cosa fa il metodo loc, quindi andremo attraverso ciascuno di questi esempi passo dopo passo.
Sentiti libero di seguirci in un notebook! Puoi scaricare il set di dati da Kaggle disponibile gratuitamente per l’uso sotto la Licenza di dedica e dominio pubblico dei dati aperti comuni (PDDL) v1.0. Quindi importa ed esegui quanto segue e possiamo iniziare!
import pandas as pddf_raw = pd.read_csv("Top-Largest-Universities.csv")Una breve introduzione al metodo loc
In pratica, il metodo loc in Pandas ti consente di selezionare un sottoinsieme di righe o colonne del DataFrame di destinazione in base a una data condizione.
Ci sono alcuni input diversi che puoi passare a loc. Ad esempio, quando vuoi selezionare una porzione del DataFrame in base al suo indice, puoi utilizzare la stessa sintassi in Python quando stai lavorando con una lista come: [inizio:fine]. Tuttavia, in questo pezzo, ci concentreremo principalmente sull’utilizzo di loc con una dichiarazione condizionale. Se hai già utilizzato SQL, questo è simile alla scrittura della parte WHERE di una query per filtrare i tuoi dati.
In generale, l’utilizzo di loc in questo modo avrà questo aspetto:
df.loc[df["colonna"] == "condizione"]Ciò restituirà un sottoinsieme dei tuoi dati in cui la colonna è uguale alla condizione.
Passiamo ora ad alcuni esempi pratici di utilizzo del metodo loc durante l’analisi esplorativa dei dati per vedere cos’altro puoi fare con esso.
Risposta alle domande sulla partecipazione universitaria utilizzando il metodo Pandas loc
Quali università offrono solo partecipazione in presenza?
Innanzitutto, vediamo come possiamo utilizzare loc per selezionare una parte dei tuoi dati da utilizzare in ulteriori analisi.
Se i dati fossero già puliti, penseresti che per rispondere alla domanda, potresti semplicemente usare un groupby sulla colonna per contare il numero di istituzioni che offrono partecipazione in presenza. Farlo in Pandas sarebbe così:
df.groupby("Distanza / In-Presenza")["Istituzione"].count()
Purtroppo, i valori della colonna “Distanza / In-Presenza” non sono molto puliti. Ci sono alcuni problemi con gli spazi vuoti e alcune istituzioni offrono sia partecipazione a distanza che in presenza, anche se il modo in cui viene registrato non è standardizzato.
La prima cosa che possiamo fare per pulire questo dataframe è rinominare la colonna in modo che non abbia spazi o caratteri speciali.
df = df.rename(columns={"Distance / In-Person": "distance_or_in_person"})Successivamente, possiamo verificare che il cambiamento sia avvenuto selezionando tutte le colonne del DataFrame.
df.columns
Ora, tutte le colonne almeno non hanno più spazi o caratteri speciali. Se si vuole, è possibile standardizzare ulteriormente cambiando tutte le altre colonne in minuscolo, ma per ora lo salteremo.
In precedenza, abbiamo effettuato un’operazione di raggruppamento sulla colonna target e abbiamo contato i valori per ogni istituzione. Un altro modo per arrivare allo stesso risultato è utilizzare il metodo value_counts in Pandas. Questo restituisce una serie con il conteggio dei valori unici della colonna target su cui viene chiamato.
df["distance_or_in_person"].value_counts()
Si noti che in questo caso non abbiamo dovuto chiamare la colonna “Istituzioni”, ma questo perché, nel nostro DataFrame originale, ogni riga rappresenta un’istituzione.
Ora, per pulire questa colonna in modo che i valori per le istituzioni che offrono sia la partecipazione in presenza che a distanza siano raggruppati in un unico valore, possiamo utilizzare la colonna loc per filtrare il DataFrame su quei valori e assegnare il valore della colonna distance_or_in_person a un nuovo valore “Entrambi”.
df.loc[ ~df["distance_or_in_person"].isin(["In-Person", "Distance"]), "distance_or_in_person"] = "Entrambi"Qui, filtriamo la colonna corrente distance_or_in_person che non è uguale a “In-Person” o “Distance” utilizzando l’operatore ~ e quindi selezioniamo la colonna distance_or_in_person. Poi lo impostiamo a “Entrambi”, che aggiorna il DataFrame originale. Possiamo verificare i cambiamenti controllando il DataFrame di nuovo:
df.head()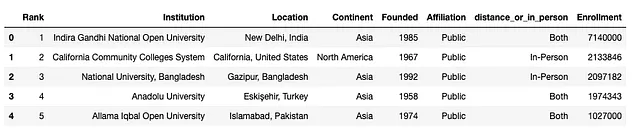
Adesso, vedrai che la colonna aggiornata conterrà solo tre possibili valori, e possiamo di nuovo chiamare value_counts per ottenere la risposta alla nostra domanda originale:
df["distance_or_in_person"].value_counts()
Ora sappiamo che, in base ai dati puliti, 59 università offrono solo la partecipazione in presenza.
Con questa nuova condizione, se si vuole sapere quali istituzioni specifiche offrono la partecipazione in presenza, possiamo di nuovo filtrare il DataFrame utilizzando il metodo loc e quindi utilizzare il metodo tolist per ottenere tutti i valori in una lista di Python:
df.loc[df["distance_or_in_person"] == "In-Person"]["Institution"].tolist()
Ora abbiamo una lista di istituzioni, ma ci sono alcuni caratteri speciali che possiamo rimuovere. Il “\xa0” in Python rappresenta una spazio non separabile, il che significa che possiamo eliminarlo utilizzando il metodo strip in Pandas che elimina gli spazi vuoti su entrambi i lati del valore della stringa.
Possiamo modificare il nostro codice di tolist iniziale per pulire l’output finale in questo modo:
df.loc[df["distance_or_in_person"] == "In-Person"]["Institution"].str.strip().tolist()
Ora, abbiamo una lista finale di università che offrono solo la partecipazione in presenza!
Qual è l’intervallo di anni tra le università più vecchie e più recenti fondate?
Successivamente, utilizziamo il metodo loc e alcuni altri metodi nativi di Pandas per filtrare il nostro DataFrame e rispondere a una domanda specifica di analisi dei dati.
Possiamo prima dare un’occhiata alla colonna Founded per capire con cosa stiamo lavorando:
df["Founded"]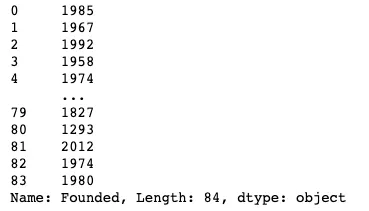
Sembra che abbiamo una colonna che è piena di valori di anno. Poiché vogliamo confrontare le date tra loro, potremmo trasformare la colonna in un tipo datetime per semplificare l’analisi.
pd.to_datetime(df["Founded"])
Tuttavia, utilizzando il metodo to_datetime sulla colonna ci dà un ParserError.
Sembra che ci sia una stringa che non corrisponde a ciò che abbiamo visto inizialmente dalla colonna Founded. Possiamo controllare la riga utilizzando il metodo loc per filtrare il DataFrame sul valore per fondato che corrisponde specificamente a ciò che abbiamo visto nel ParserError:
df.loc[df["Founded"] == "1948 and 2014"]
C’è un’università apparentemente che ha due diverse date di fondazione. Inoltre, ora che conosciamo l’indice della riga (9), c’è anche un esempio dell’utilizzo del metodo loc per filtrare il DataFrame sul valore dell’indice specificamente:
df.loc[9]
Sembra che questa sia l’unica riga nel DataFrame in cui il valore per la colonna “Founded” ha più di un anno.
A seconda di ciò che si vuole fare con i dati, si potrebbe cercare di pulire i dati scegliendo forse un anno (la prima data di fondazione) o creando due righe per questa istituzione in modo che entrambe le date di fondazione siano su righe separate.
In questo caso, poiché stiamo lavorando solo con questi dati per rispondere a una semplice domanda (qual è l’intervallo di anni della data di fondazione per le istituzioni in questo set di dati), possiamo semplicemente rimuovere questa riga in questo modo:
df.drop(9).head(10) # rimozione della riga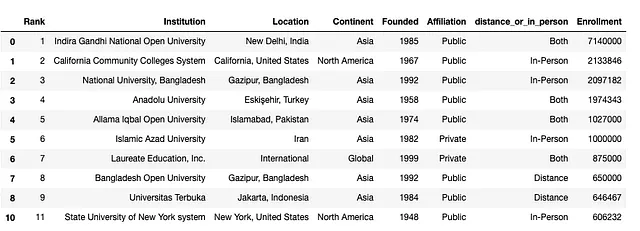
Controllando il DataFrame risultante, si può vedere che la riga con l’indice “9” che aveva più valori per la colonna Founded non è più nella tabella. È possibile far sì che la rimozione sia permanente riassegnando il DataFrame dopo aver eliminato la riga:
df = df.drop(9)Successivamente, possiamo utilizzare nuovamente il metodo to_datetime sulla colonna Founded e vedere cosa succede.
pd.to_datetime(df["Founded"], errors="coerce")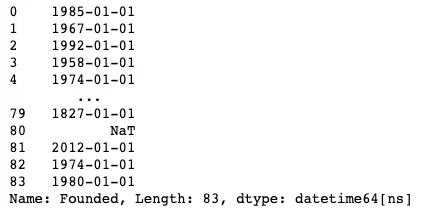
In realtà c’è un altro errore che compare qui, motivo per cui ho incluso errors="coerce" per garantire che se ci fossero altri problemi di conversione della stringa in un tipo datetime, il valore sarebbe diventato nullo.
Finalmente, possiamo assegnare il tipo datetime alla versione della colonna “Founded” ad una nuova colonna. Successivamente, per verificare la data di fondazione più antica di un’istituzione, possiamo utilizzare il metodo min in Python:
df["founded_date"] = pd.to_datetime(df["Founded"], errors="coerce")min(df["founded_date"])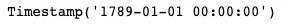
Puoi vedere le date del timestamp più antiche e più recenti della colonna founded_date utilizzando i metodi min e max per ottenere l’intervallo di anni tra le università più vecchie e quelle più recenti.
È qui che ho realizzato che possiamo fare tutto molto più rapidamente se tutto ciò di cui abbiamo bisogno è rispondere ad una sola domanda veloce. Invece di convertire in un tipo datetime, potremmo semplicemente trasformare la colonna in un tipo intero e poi sottrarre il valore massimo e minimo tra di loro per ottenere l’intervallo.
df["Founded"] = df["Founded"].astype("int")max(df["Founded"]) - min(df["Founded"])Ciò restituisce 719.
Non dovresti sempre prendere la strada facile e convertire la colonna degli anni in un tipo intero. Nel caso in cui si desideri effettuare un’analisi più complicata o si stia specificatamente lavorando con una serie temporale, c’è molto valore aggiunto se si pulisce correttamente i dati e si ottiene la colonna della data in un tipo datetime. Tuttavia, se hai solo bisogno di fare un’analisi veloce, può risparmiarti il tempo e il mal di testa di cercare gli errori per trovare il modo più veloce di risolvere un problema invece del “migliore” modo per risolverlo.
Ci sono molti modi diversi di combinare i metodi di Pandas per pulire e analizzare le tue date. Il metodo loc è versatile e ti consente di utilizzare diversi metodi insieme per filtrare, tagliare e aggiornare il tuo DataFrame in modo che funzioni per le specifiche domande e problemi che desideri risolvere.
Pulire i dati è un processo iterativo che va di pari passo con l’esplorazione dei dati. Spero che questi esempi con loc ti siano stati utili per la tua stessa analisi in futuro.
Se ti piacciono i miei contenuti, considera di seguirmi e iscriviti per diventare membro di Nisoo utilizzando il mio link di riferimento qui sotto. Costa solo $5 al mese e avrai accesso illimitato a tutto su Nisoo. L’iscrizione utilizzando il mio link mi consente di guadagnare una piccola commissione. E se sei già iscritto per seguirmi, grazie mille per il tuo supporto!
Iscriviti a Nisoo con il mio link di riferimento – Byron Dolon
Come membro di Nisoo, una parte della tua quota di iscrizione va ai writer che leggi e hai accesso completo ad ogni storia…
byrondolon.medium.com
Altri contenuti da me: – 3 modi efficienti per filtrare una colonna DataFrame di Pandas per sottostringa – 5 consigli pratici per gli aspiranti analisti dei dati – Migliorare le tue visualizzazioni dei dati con grafici a barre impilati in Python – Selezione e assegnazione condizionali con .loc in Pandas – 5 (e mezzo) righe di codice per capire i tuoi dati con Pandas




