Mantieni la formattazione originale del PDF per visualizzare i documenti tradotti con Amazon Textract, Amazon Translate e PDFBox.
Keep the original PDF formatting to view translated documents with Amazon Textract, Amazon Translate, and PDFBox.
Le aziende in diversi settori creano, scansionano e archiviano grandi volumi di documenti in formato PDF. In molti casi, il contenuto è denso di testo e spesso scritto in una lingua diversa e richiede una traduzione. Per affrontare questa situazione, è necessaria una soluzione automatica per estrarre i contenuti all’interno di questi PDF e tradurli in modo rapido ed efficiente dal punto di vista dei costi.
Molte aziende hanno utenti globali diversificati e necessitano di tradurre il testo per consentire la comunicazione interlinguistica tra di loro. Questo richiede uno sforzo manuale, lento ed oneroso da parte di professionisti umani. C’è la necessità di trovare una soluzione scalabile, affidabile ed economica per tradurre i documenti mantenendo la formattazione originale.
Per settori come l’assistenza sanitaria, a causa dei requisiti normativi, i documenti tradotti richiedono la verifica della validità da parte di un professionista umano.
Se il documento tradotto non mantiene la formattazione e la struttura originali, perde il suo contesto. Ciò può rendere difficile per un revisore umano convalidare e apportare correzioni.
- Migliori Newsletter sulla Sicurezza Informatica nel 2023
- L’influenza rivoluzionaria dell’IA generativa nell’industria automobilistica
- Meta Open-Sources tutti i loro Progetti Promettenti | Scopri Perché
In questo articolo viene mostrato come creare un nuovo PDF tradotto da un PDF scannerizzato mantenendo la struttura e la formattazione originale utilizzando un approccio basato sulla geometria con Amazon Textract, Amazon Translate e Apache PDFBox.
Panoramica della soluzione
La soluzione presentata in questo articolo utilizza i seguenti componenti:
- Amazon Textract – Un servizio di apprendimento automatico (ML) completamente gestito che estrae automaticamente testi stampati, scrittura a mano e altri dati da documenti scannerizzati che vanno oltre il semplice riconoscimento ottico dei caratteri (OCR) per identificare, comprendere ed estrarre dati da moduli e tabelle. Amazon Textract può rilevare il testo in una varietà di documenti, tra cui relazioni finanziarie, cartelle cliniche e moduli fiscali.
- Amazon Translate – Un servizio di traduzione automatica neurale che fornisce traduzioni linguistiche rapide, di alta qualità e convenienti. Amazon Translate offre capacità di traduzione su richiesta e in batch di alta qualità in oltre 2.970 coppie di lingue, riducendo i costi di traduzione.
- PDF Translate – Una libreria open-source scritta in Java e pubblicata su AWS Samples in GitHub. Questa libreria contiene la logica per generare documenti PDF tradotti nella lingua desiderata utilizzando Amazon Textract e Amazon Translate. Utilizza anche la libreria open-source Java Apache PDFBox per creare documenti PDF. Esistono librerie di elaborazione PDF simili disponibili in altri linguaggi di programmazione, ad esempio Node PDFBox.
Durante le traduzioni automatiche, potresti trovarti in situazioni in cui desideri preservare specifiche sezioni di testo dalla traduzione, come nomi o identificatori univoci. Amazon Translate consente modifiche ai tag, che ti permettono di specificare quali testi non devono essere tradotti. Amazon Translate supporta anche la personalizzazione della formalità, che ti permette di personalizzare il livello di formalità nella traduzione finale.
Per i dettagli sui limiti di Amazon Textract, consulta le Quotas in Amazon Textract.
La soluzione è limitata alle lingue che possono essere estratte da Amazon Textract, che attualmente supporta inglese, spagnolo, italiano, portoghese, francese e tedesco. Queste lingue sono supportate anche da Amazon Translate. Per la lista completa delle lingue supportate da Amazon Translate, consulta Lingue supportate e codici di lingua.
Utilizziamo il seguente PDF per mostrare come tradurre il testo dall’inglese allo spagnolo. La soluzione supporta anche la generazione del documento tradotto senza alcuna formattazione. La posizione del testo tradotto viene mantenuta. I documenti PDF di origine e tradotti possono essere trovati anche nel repository AWS Samples GitHub.
Nelle sezioni seguenti, mostriamo come eseguire il codice di traduzione su una macchina locale e analizziamo più nel dettaglio il codice di traduzione.

Prerequisiti
Prima di iniziare, configura il tuo account AWS e l’interfaccia a linea di comando AWS (AWS CLI). Per accedere ai servizi AWS come Textract e Translate, sono necessarie le autorizzazioni IAM appropriate. Consigliamo di utilizzare le autorizzazioni a privilegi minimi. Per saperne di più sulle autorizzazioni IAM, consulta le Politiche e le autorizzazioni in IAM, nonché Come funziona Amazon Textract con IAM e Come funziona Amazon Translate con IAM.
Esegui il codice di traduzione su una macchina locale
Questa soluzione si concentra sul codice Java autonomo per estrarre e tradurre un documento PDF. Questo è utile per facilitare i test e le personalizzazioni per ottenere il miglior documento PDF tradotto reso. Il codice può quindi essere integrato in una soluzione automatizzata da distribuire ed eseguire su AWS. Consulta la traduzione di documenti PDF utilizzando Amazon Translate e Amazon Textract per un’architettura di esempio che utilizza Amazon Simple Storage Service (Amazon S3) per archiviare i documenti e AWS Lambda per eseguire il codice.
Per eseguire il codice su una macchina locale, seguire i seguenti passaggi. Gli esempi di codice sono disponibili nel repo GitHub.
-
Clonare il repo GitHub:
git clone https://github.com/aws-samples/amazon-translate-pdf -
Eseguire il seguente comando:
cd amazon-translate-pdf -
Eseguire il seguente comando per tradurre dall’inglese allo spagnolo:
java -jar target/translate-pdf-1.0.jar --source en --translated es
Vengono creati due documenti PDF tradotti nella cartella “documents”, uno con e uno senza la formattazione originale (SampleOutput-es.pdf e SampleOutput-min-es.pdf).
Codice per generare il PDF tradotto
I seguenti frammenti di codice mostrano come prendere un documento PDF e generare un corrispondente documento PDF tradotto. Estrae il testo utilizzando Amazon Textract e crea il PDF tradotto aggiungendo il testo tradotto come livello all’immagine. Si basa sulla soluzione mostrata nel post Generazione automatica di PDF ricercabili da documenti scannerizzati con Amazon Textract.
Il codice ottiene prima ogni riga di testo con Amazon Textract. Amazon Translate viene utilizzato per ottenere il testo tradotto e salvare la geometria del testo tradotto.
Region region = Region.US_EAST_1;
TextractClient textractClient = TextractClient.builder()
.region(region)
.build();
// Ottieni l'oggetto Document di input come byte
Document pdfDoc = Document.builder()
.bytes(SdkBytes.fromByteBuffer(imageBytes))
.build();
TranslateClient translateClient = TranslateClient.builder()
.region(region)
.build();
DetectDocumentTextRequest detectDocumentTextRequest = DetectDocumentTextRequest.builder()
.document(pdfDoc)
.build();
// Invoca l'operazione Detect
DetectDocumentTextResponse textResponse = textractClient.detectDocumentText(detectDocumentTextRequest);
List<Block> blocks = textResponse.blocks();
List<TextLine> lines = new ArrayList<>();
BoundingBox boundingBox;
for (Block block : blocks) {
if ((block.blockType()).equals(BlockType.LINE)) {
String source = block.text();
TranslateTextRequest requestTranslate = TranslateTextRequest.builder()
.sourceLanguageCode(sourceLanguage)
.targetLanguageCode(destinationLanguage)
.text(source)
.build();
TranslateTextResponse resultTranslate = translateClient.translateText(requestTranslate);
boundingBox = block.geometry().boundingBox();
lines.add(new TextLine(boundingBox.left(),
boundingBox.top(),
boundingBox.width(),
boundingBox.height(),
resultTranslate.translatedText(),
source));
}
}
return lines;La dimensione del carattere viene calcolata come segue e può essere facilmente configurata:
int fontSize = 20;
float textWidth = font.getStringWidth(text) / 1000 * fontSize;
float textHeight = font.getFontDescriptor().getFontBoundingBox().getHeight() / 1000 * fontSize;
if (textWidth > bbWidth) {
while (textWidth > bbWidth) {
fontSize -= 1;
textWidth = font.getStringWidth(text) / 1000 * fontSize;
textHeight = font.getFontDescriptor().getFontBoundingBox().getHeight() / 1000 * fontSize;
}
} else if (textWidth < bbWidth) {
while (textWidth < bbWidth) {
fontSize += 1;
textWidth = font.getStringWidth(text) / 1000 * fontSize;
textHeight = font.getFontDescriptor().getFontBoundingBox().getHeight() / 1000 * fontSize;
}
}Il PDF tradotto viene creato dalla geometria salvata e dal testo tradotto. È possibile configurare facilmente le modifiche al colore del testo tradotto.
float width = image.getWidth();
float height = image.getHeight();
PDRectangle box = new PDRectangle(width, height);
PDPage page = new PDPage(box);
page.setMediaBox(box);
this.document.addPage(page); //org.apache.pdfbox.pdmodel.PDDocument
PDImageXObject pdImage;
if(imageType == ImageType.JPEG){
pdImage = JPEGFactory.createFromImage(this.document, image);
} else {
pdImage = LosslessFactory.createFromImage(this.document, image);
}
PDPageContentStream contentStream = new PDPageContentStream(document, page, PDPageContentStream.AppendMode.OVERWRITE, false);
contentStream.drawImage(pdImage, 0, 0);
contentStream.setRenderingMode(RenderingMode.FILL);
for (TextLine cline : lines){
String clinetext = cline.text;
String clinetextOriginal = cline.originalText;
FontInfo fontInfo = calculateFontSize(clinetextOriginal, (float) cline.width * width, (float) cline.height * height, font);
// Configurazione per includere la struttura del documento originale - sovrapposizione con l'originale
contentStream.setNonStrokingColor(Color.WHITE);
contentStream.addRect((float) cline.left * width, (float) (height - height * cline.top - fontInfo.textHeight), (float) cline.width * width, (float) cline.height * height);
contentStream.fill();
fontInfo = calculateFontSize(clinetext, (float) cline.width * width, (float) cline.height * height, font);
// Configurazione per includere la struttura del documento originale - sovrapposizione con il tradotto
contentStream.setNonStrokingColor(Color.WHITE);
contentStream.addRect((float) cline.left * width, (float) (height - height * cline.top - fontInfo.textHeight), (float) cline.width * width, (float) cline.height * height);
contentStream.fill();
// Cambia qui il colore del testo di output
fontInfo = calculateFontSize(clinetext.length() <= clinetextOriginal.length() ? clinetextOriginal : clinetext, (float) cline.width * width, (float) cline.height * height, font);
contentStream.setNonStrokingColor(Color.BLACK);
contentStream.beginText();
contentStream.setFont(font, fontInfo.fontSize);
contentStream.newLineAtOffset((float) cline.left * width, (float) (height - height * cline.top - fontInfo.textHeight));
contentStream.showText(clinetext);
contentStream.endText();
}
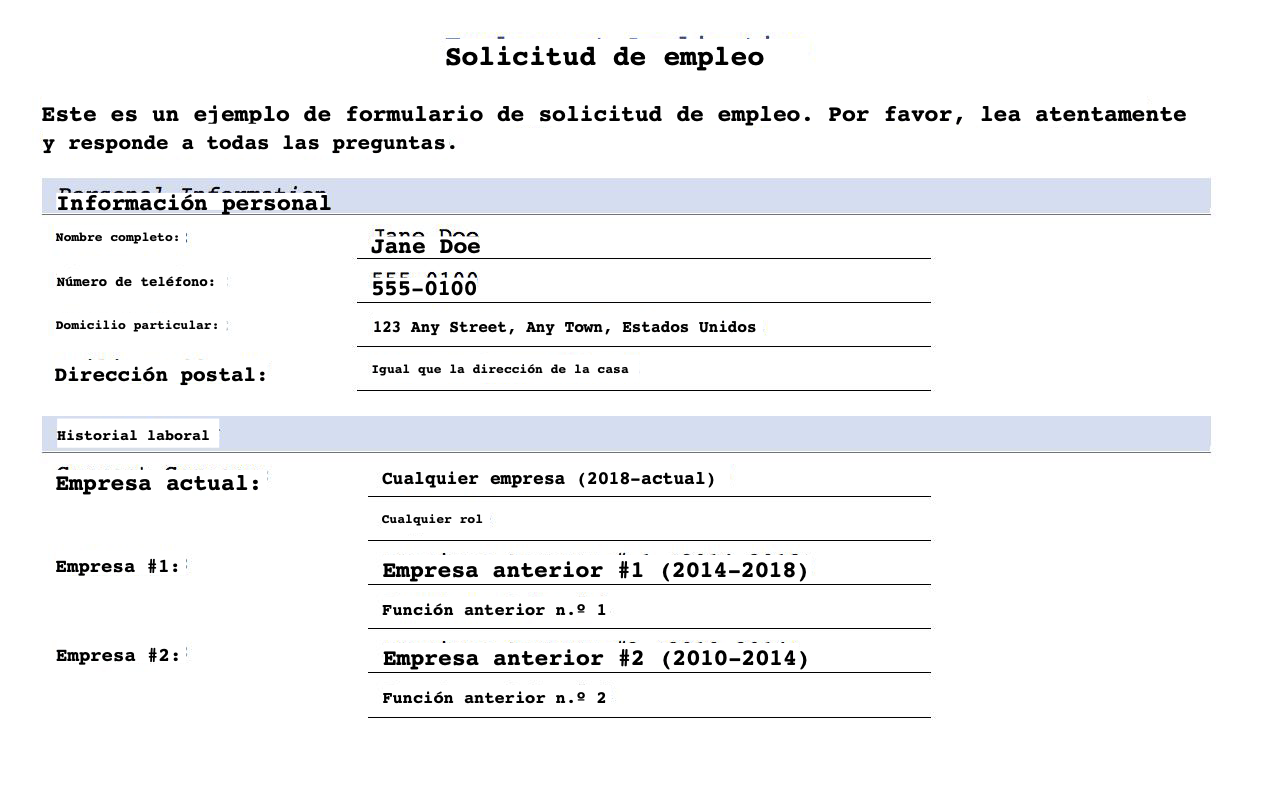
contentStream.close()La seguente immagine mostra il documento tradotto in spagnolo con la formattazione originale (SampleOutput-es.pdf).
La seguente immagine mostra il PDF tradotto in spagnolo senza alcuna formattazione (SampleOutput-min-es.pdf).

Tempo di elaborazione
Il modulo di candidatura per l’impiego ha impiegato circa 10 secondi per estrarre, elaborare e renderizzare il PDF tradotto. Il tempo di elaborazione per documenti contenenti molto testo, come ad esempio la Dichiarazione di Indipendenza, è stato inferiore a un minuto.
Costo
Con Amazon Textract, paghi in base al numero di pagine e immagini elaborate. Con Amazon Translate, paghi in base al numero di caratteri di testo elaborati. Consulta i prezzi di Amazon Textract e Amazon Translate per conoscere i costi effettivi.
Conclusioni
Questo post ha mostrato come utilizzare Amazon Textract e Amazon Translate per generare documenti PDF tradotti mantenendo la struttura originale del documento. È possibile post-elaborare i risultati di Amazon Textract per migliorare la qualità della traduzione, ad esempio le parole estratte possono essere sottoposte a controlli ortografici basati su intelligenza artificiale come SymSpell per la validazione dei dati, oppure possono essere utilizzati algoritmi di clustering per preservare l’ordine di lettura. È anche possibile utilizzare Amazon Augmented AI (Amazon A2I) per creare flussi di lavoro di revisione umana in cui è possibile utilizzare la propria forza lavoro privata per revisionare i documenti PDF originali e tradotti al fine di fornire maggiore accuratezza e contesto. Per iniziare, consulta la progettazione di flussi di lavoro di revisione umana con Amazon Translate e Amazon Augmented AI e la creazione di un flusso di lavoro di traduzione di documenti multilingue con personalizzazioni specifiche per dominio e lingua.





