Consigliare e filtrare dinamicamente gli articoli in base al contesto dell’utente in Amazon Personalize
Recommend and dynamically filter articles based on user context in Amazon Personalize.
Le organizzazioni investono continuamente tempo ed energie nello sviluppo di soluzioni intelligenti di raccomandazione per fornire contenuti personalizzati e rilevanti ai propri utenti. Gli obiettivi possono essere molteplici: trasformare l’esperienza dell’utente, generare interazioni significative e stimolare il consumo di contenuti. Alcune di queste soluzioni utilizzano modelli comuni di apprendimento automatico (ML) basati su modelli di interazione storici, attributi demografici degli utenti, similarità dei prodotti e comportamenti di gruppo. Oltre a questi attributi, il contesto (come il meteo, la posizione e così via) al momento dell’interazione può influenzare le decisioni degli utenti durante la navigazione dei contenuti.
In questo post, mostriamo come utilizzare il tipo di dispositivo attuale dell’utente come contesto per migliorare l’efficacia delle raccomandazioni basate su Amazon Personalize. Inoltre, mostriamo come utilizzare tale contesto per filtrare dinamicamente le raccomandazioni. Sebbene questo post mostri come Amazon Personalize possa essere utilizzato per un caso d’uso di video on demand (VOD), è importante sottolineare che Amazon Personalize può essere utilizzato in molteplici settori.
Cos’è Amazon Personalize?
Amazon Personalize consente agli sviluppatori di creare applicazioni basate sullo stesso tipo di tecnologia di intelligenza artificiale utilizzata da Amazon.com per le raccomandazioni personalizzate in tempo reale. Amazon Personalize è in grado di fornire una vasta gamma di esperienze di personalizzazione, tra cui raccomandazioni specifiche di prodotti, riposizionamento personalizzato dei prodotti e marketing diretto personalizzato. Inoltre, come servizio di intelligenza artificiale completamente gestito, Amazon Personalize accelera le trasformazioni digitali dei clienti con l’apprendimento automatico, semplificando l’integrazione di raccomandazioni personalizzate in siti web esistenti, applicazioni, sistemi di marketing via email e altro ancora.
Perché è importante il contesto?
Utilizzare i metadati contestuali di un utente come posizione, ora del giorno, tipo di dispositivo e meteo fornisce esperienze personalizzate per gli utenti esistenti e aiuta a migliorare la fase di avvio a freddo per gli utenti nuovi o non identificati. La fase di avvio a freddo si riferisce al periodo in cui il motore di raccomandazione fornisce raccomandazioni non personalizzate a causa della mancanza di informazioni storiche su quell’utente. In situazioni in cui sono presenti altre esigenze di filtraggio e promozione degli elementi (ad esempio, notizie e meteo), l’aggiunta del contesto attuale dell’utente (stagione o ora del giorno) aiuta a migliorare l’accuratezza includendo ed escludendo raccomandazioni.
- Emulando il nuoto dei krill per costruire una piattaforma robotica per la navigazione oceanica
- Sensore simile alla carta, senza batteria, abilitato all’IA per il monitoraggio olistico delle ferite
- Dropbox svela strumenti rivoluzionari alimentati da intelligenza artificiale una nuova era di produttività e collaborazione
Prendiamo ad esempio una piattaforma VOD che raccomanda spettacoli, documentari e film all’utente. Sulla base dell’analisi del comportamento, sappiamo che gli utenti VOD tendono a consumare contenuti di durata più breve come sitcom su dispositivi mobili e contenuti di durata più lunga come film sulla loro TV o desktop.
Panoramica della soluzione
Approfondendo l’esempio della considerazione del tipo di dispositivo dell’utente, mostriamo come fornire queste informazioni come contesto in modo che Amazon Personalize possa apprendere automaticamente l’influenza del dispositivo dell’utente sui suoi tipi preferiti di contenuti.
Seguiamo lo schema architetturale mostrato nel diagramma seguente per illustrare come il contesto possa essere automaticamente passato a Amazon Personalize. Il contesto derivato automaticamente è ottenuto attraverso gli header di Amazon CloudFront inclusi nelle richieste, come ad esempio una REST API in Amazon API Gateway che chiama una funzione AWS Lambda per recuperare le raccomandazioni. Fare riferimento all’esempio di codice completo disponibile nel nostro repository GitHub. Forniamo un modello AWS CloudFormation per creare le risorse necessarie.
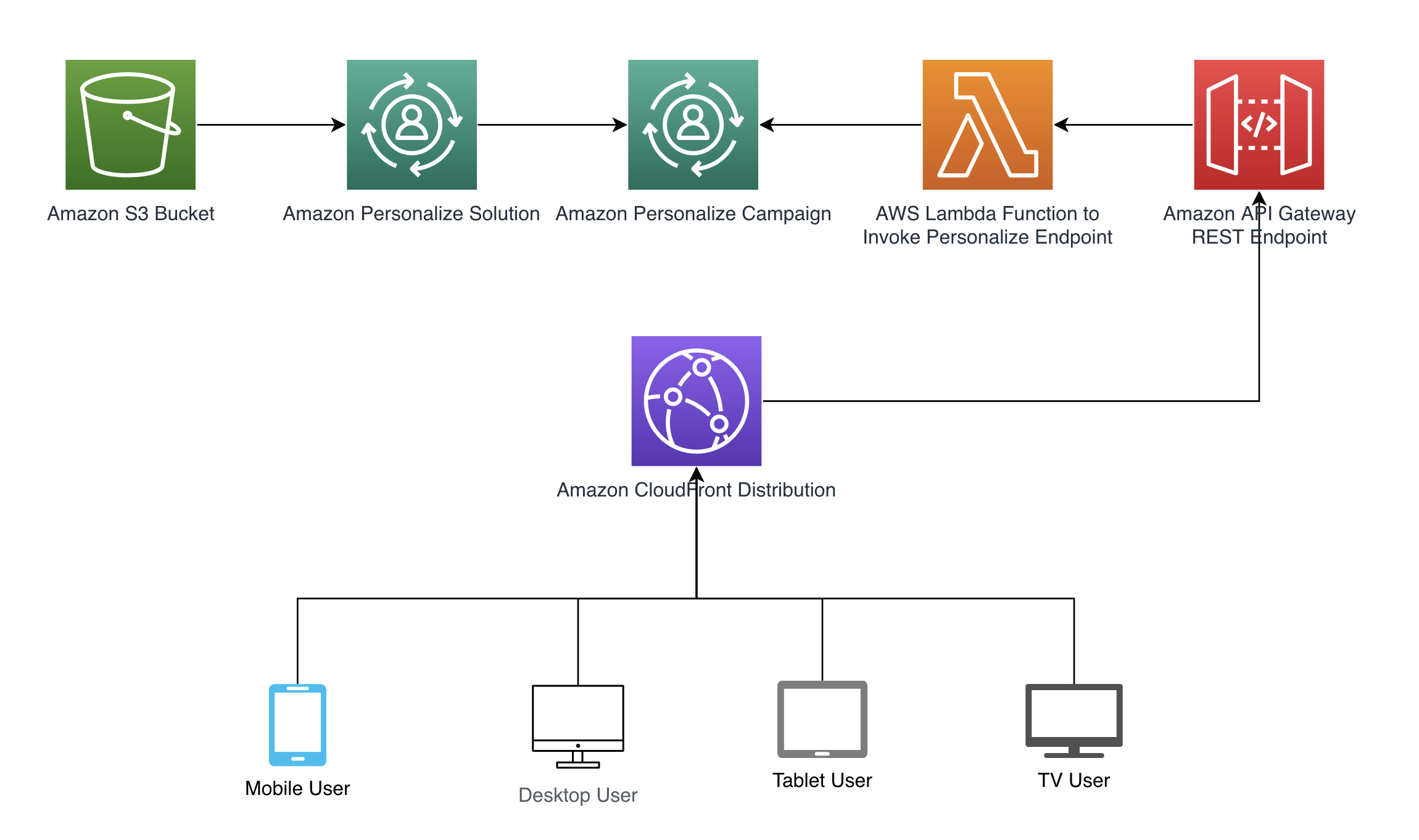
Nelle sezioni seguenti, illustreremo come configurare ogni passaggio del modello di architettura di esempio.
Scegli una ricetta
Le ricette sono algoritmi di Amazon Personalize preparati per casi d’uso specifici. Amazon Personalize fornisce ricette basate su casi d’uso comuni per l’addestramento dei modelli. Per il nostro caso d’uso, creiamo un semplice raccomandatore personalizzato di Amazon Personalize utilizzando la ricetta User-Personalization. Prevede gli elementi con cui un utente interagirà in base all’insieme di interazioni. Inoltre, questa ricetta utilizza anche gli insiemi di elementi e utenti per influenzare le raccomandazioni, se forniti. Per saperne di più su come funziona questa ricetta, fare riferimento alla ricetta User-Personalization.
Crea ed importa un dataset
Sfruttare il contesto richiede di specificare i valori del contesto nelle interazioni in modo che i raccomandatori possano utilizzare il contesto come feature durante l’addestramento dei modelli. Dobbiamo inoltre fornire il contesto attuale dell’utente durante l’inferenza. Lo schema delle interazioni (vedi il codice seguente) definisce la struttura dei dati di interazione utente-elemento storici e in tempo reale. I campi USER_ID, ITEM_ID e TIMESTAMP sono richiesti da Amazon Personalize per questo dataset. DEVICE_TYPE è un campo categorico personalizzato che stiamo aggiungendo per questo esempio per catturare il contesto attuale dell’utente e includerlo nell’addestramento del modello. Amazon Personalize utilizza questo dataset di interazioni per addestrare i modelli e creare campagne di raccomandazioni.
{
"type": "record",
"name": "Interazioni",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "USER_ID",
"type": "string"
},
{
"name": "ITEM_ID",
"type": "string"
},
{
"name": "TIPO_DISPOSITIVO",
"type": "string",
"categorical": true
},
{
"name": "TIMESTAMP",
"type": "long"
}
],
"version": "1.0"
}In modo simile, lo schema degli elementi (vedi il codice seguente) definisce la struttura dei dati di catalogo prodotto e video. L’ITEM_ID è richiesto da Amazon Personalize per questo dataset. TIMESTAMP_CREAZIONE è un nome di colonna riservato ma non è obbligatorio. GENERE e PAESI_AMMESSI sono campi personalizzati che stiamo aggiungendo per questo esempio per catturare il genere del video e i paesi in cui i video possono essere riprodotti. Amazon Personalize utilizza questo dataset di elementi per addestrare modelli e creare campagne di raccomandazione.
{
"type": "record",
"name": "Elementi",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "ITEM_ID",
"type": "string"
},
{
"name": "GENERE",
"type": "string",
"categorical": true
},
{
"name": "PAESI_AMMESSI",
"type": "string",
"categorical": true
},
{
"name": "TIMESTAMP_CREAZIONE",
"type": "long"
}
],
"version": "1.0"
}Nel nostro contesto, i dati storici si riferiscono alla cronologia delle interazioni degli utenti finali con video ed elementi sulla piattaforma VOD. Questi dati vengono di solito raccolti e memorizzati nel database dell’applicazione.
A scopo dimostrativo, utilizziamo la libreria Faker di Python per generare alcuni dati di test simulando il dataset delle interazioni con diversi elementi, utenti e tipi di dispositivi nel corso di un periodo di 3 mesi. Dopo aver definito lo schema e la posizione del file di input delle interazioni, i passaggi successivi consistono nel creare un gruppo di dataset, includere il dataset delle interazioni all’interno del gruppo di dataset e infine importare i dati di addestramento nel dataset, come illustrato nei frammenti di codice seguenti:
create_dataset_group_response = personalize.create_dataset_group(
name = "personalize-auto-context-demo-gruppo-dataset"
)
create_interactions_dataset_response = personalize.create_dataset(
name = "personalize-auto-context-demo-interazioni-dataset",
datasetType = 'INTERAZIONI',
datasetGroupArn = arn_gruppo_dataset_interazioni,
schemaArn = arn_schema_interazioni
)
create_interactions_dataset_import_job_response = personalize.create_dataset_import_job(
jobName = "personalize-auto-context-demo-import-dataset",
datasetArn = arn_dataset_interazioni,
dataSource = {
"dataLocation": "s3://{}/{}".format(bucket, nome_file_interazioni)
},
roleArn = arn_ruolo
)
create_items_dataset_response = personalize.create_dataset(
name = "personalize-auto-context-demo-elementi-dataset",
datasetType = 'ELEMENTI',
datasetGroupArn = arn_gruppo_dataset_elementi,
schemaArn = arn_schema_elementi
)
create_items_dataset_import_job_response = personalize.create_dataset_import_job(
jobName = "personalize-auto-context-demo-import-elementi-dataset",
datasetArn = arn_dataset_elementi,
dataSource = {
"dataLocation": "s3://{}/{}".format(bucket, nome_file_elementi)
},
roleArn = arn_ruolo
)Raccogliere dati storici e addestrare il modello
In questo passaggio, definiamo la ricetta scelta e creiamo una soluzione e una versione della soluzione facendo riferimento al gruppo di dataset precedentemente definito. Quando si crea una soluzione personalizzata, si specifica una ricetta e si configurano i parametri di addestramento. Quando si crea una versione della soluzione per la soluzione, Amazon Personalize addestra il modello che supporta la versione della soluzione in base alla ricetta e alla configurazione di addestramento. Vedere il codice seguente:
arn_ricetta = "arn:aws:personalize:::recipe/aws-user-personalization"
create_solution_response = personalize.create_solution(
name = "personalize-auto-context-demo-soluzione",
datasetGroupArn = arn_gruppo_dataset,
recipeArn = arn_ricetta
)
create_solution_version_response = personalize.create_solution_version(
solutionArn = arn_soluzione
)Creare un endpoint di campagna
Dopo aver addestrato il tuo modello, lo distribuisci in una campagna. Una campagna crea e gestisce un endpoint a ridimensionamento automatico per il tuo modello addestrato che puoi utilizzare per ottenere raccomandazioni personalizzate utilizzando l’API GetRecommendations. In un passaggio successivo, utilizziamo questo endpoint di campagna per passare automaticamente il tipo di dispositivo come contesto e ricevere raccomandazioni personalizzate. Ecco il codice seguente:
create_campaign_response = personalize.create_campaign(
name = "personalize-auto-context-demo-campaign",
solutionVersionArn = solution_version_arn
)Creare un filtro dinamico
Quando si ottengono raccomandazioni dalla campagna creata, è possibile filtrare i risultati in base a criteri personalizzati. Per il nostro esempio, creiamo un filtro per soddisfare il requisito di raccomandare video che sono consentiti solo dalla nazione corrente dell’utente. Le informazioni sulla nazione vengono passate dinamicamente dall’intestazione HTTP di CloudFront.
create_filter_response = personalize.create_filter(
name = 'personalize-auto-context-demo-country-filter',
datasetGroupArn = dataset_group_arn,
filterExpression = 'INCLUDE ItemID WHERE Items.ALLOWED_COUNTRIES IN ($CONTEXT_COUNTRY)'
) Creare una funzione Lambda
Il passaggio successivo nella nostra architettura è creare una funzione Lambda per elaborare le richieste API provenienti dalla distribuzione CloudFront e rispondere invocando l’endpoint della campagna Amazon Personalize. In questa funzione Lambda, definiamo la logica per analizzare le seguenti intestazioni HTTP della richiesta CloudFront e i parametri della stringa di query per determinare rispettivamente il tipo di dispositivo dell’utente e l’ID dell’utente:
CloudFront-Is-Desktop-ViewerCloudFront-Is-Mobile-ViewerCloudFront-Is-SmartTV-ViewerCloudFront-Is-Tablet-ViewerCloudFront-Viewer-Country
Il codice per creare questa funzione viene distribuito tramite il modello CloudFormation.
Creare un’API REST
Per rendere la funzione Lambda e l’endpoint della campagna Amazon Personalize accessibili alla distribuzione CloudFront, creiamo un endpoint di API REST configurato come proxy Lambda. API Gateway fornisce strumenti per creare e documentare API che indirizzano le richieste HTTP alle funzioni Lambda. La funzionalità di integrazione proxy Lambda consente a CloudFront di chiamare una singola funzione Lambda astraggendo le richieste verso l’endpoint della campagna Amazon Personalize. Il codice per creare questa funzione viene distribuito tramite il modello CloudFormation.
Creare una distribuzione CloudFront
Quando si crea una distribuzione CloudFront, poiché questa è una configurazione demo, disabilitiamo la memorizzazione nella cache utilizzando una politica di memorizzazione nella cache personalizzata, garantendo che la richiesta venga inviata all’origine ogni volta. Inoltre, utilizziamo una politica di richiesta di origine specificando le intestazioni HTTP richieste e i parametri della stringa di query richiesti che sono inclusi in una richiesta di origine. Il codice per creare questa funzione viene distribuito tramite il modello CloudFormation.
Testare le raccomandazioni
Quando l’URL della distribuzione CloudFront viene accessato da dispositivi diversi (desktop, tablet, telefono, ecc.), possiamo vedere raccomandazioni video personalizzate che sono più rilevanti per il loro dispositivo. Inoltre, se viene presentato un utente nuovo, vengono presentate le raccomandazioni personalizzate per il dispositivo dell’utente. Negli esempi di output seguenti, i nomi dei video vengono utilizzati solo per rappresentare il loro genere e durata per renderlo relazionabile.
Nel codice seguente, viene presentato un utente noto che ama le commedie basate su interazioni passate e sta accedendo da un dispositivo mobile, vengono presentate sitcom più brevi:
Raccomandazioni per l'utente: 460
ITEM_ID GENERE PAESI_CONSENTITI
380 Commedia RU|GR|LT|NO|SZ|VN
540 Sitcom US|PK|NI|JM|IN|DK
860 Commedia RU|GR|LT|NO|SZ|VN
600 Commedia US|PK|NI|JM|IN|DK
580 Commedia US|FI|CN|ES|HK|AE
900 Satira US|PK|NI|JM|IN|DK
720 Sitcom US|PK|NI|JM|IN|DKAll’utente noto seguente vengono presentati film quando accede da un dispositivo smart TV in base alle interazioni passate:
Raccomandazioni per l'utente: 460
ITEM_ID GENERE PAESI_CONSENTITI
780 Romance US|PK|NI|JM|IN|DK
100 Horror US|FI|CN|ES|HK|AE
400 Azione US|FI|CN|ES|HK|AE
660 Horror US|PK|NI|JM|IN|DK
720 Horror US|PK|NI|JM|IN|DK
820 Mistero US|FI|CN|ES|HK|AE
520 Mistero US|FI|CN|ES|HK|AEUn utente sconosciuto (freddo) che accede da un telefono viene presentato con spettacoli più brevi ma popolari:
Raccomandazioni per l'utente: 666
ITEM_ID GENRE ALLOWED_COUNTRIES
940 Satira US|FI|CN|ES|HK|AE
760 Satira US|FI|CN|ES|HK|AE
160 Sitcom US|FI|CN|ES|HK|AE
880 Commedia US|FI|CN|ES|HK|AE
360 Satira US|PK|NI|JM|IN|DK
840 Satira US|PK|NI|JM|IN|DK
420 Satira US|PK|NI|JM|IN|DK Un utente sconosciuto (freddo) che accede da un desktop viene presentato con i migliori film di fantascienza e documentari:
Raccomandazioni per l'utente: 666
ITEM_ID GENRE ALLOWED_COUNTRIES
120 Fantascienza US|PK|NI|JM|IN|DK
160 Fantascienza US|FI|CN|ES|HK|AE
680 Fantascienza RU|GR|LT|NO|SZ|VN
640 Fantascienza US|FI|CN|ES|HK|AE
700 Documentario US|FI|CN|ES|HK|AE
760 Fantascienza US|FI|CN|ES|HK|AE
360 Documentario US|PK|NI|JM|IN|DK L’utente noto successivo che accede da un telefono restituisce raccomandazioni filtrate in base alla posizione (US):
Raccomandazioni per l'utente: 460
ITEM_ID GENRE ALLOWED_COUNTRIES
300 Sitcom US|PK|NI|JM|IN|DK
480 Satira US|PK|NI|JM|IN|DK
240 Commedia US|PK|NI|JM|IN|DK
900 Sitcom US|PK|NI|JM|IN|DK
880 Commedia US|FI|CN|ES|HK|AE
220 Sitcom US|FI|CN|ES|HK|AE
940 Sitcom US|FI|CN|ES|HK|AE Conclusion
In questo post, abbiamo descritto come utilizzare il tipo di dispositivo dell’utente come dati contestuali per rendere le tue raccomandazioni più pertinenti. L’utilizzo di metadati contestuali per addestrare i modelli di Amazon Personalize ti aiuterà a consigliare prodotti pertinenti sia a nuovi che a utenti esistenti, non solo dai dati del profilo ma anche dalla piattaforma di navigazione del dispositivo. Non solo, il contesto come la posizione (paese, città, regione, codice postale) e il tempo (giorno della settimana, weekend, giorno feriale, stagione) apre l’opportunità di fare raccomandazioni pertinenti all’utente. Puoi eseguire l’esempio di codice completo utilizzando il modello CloudFormation fornito nel nostro repository GitHub e clonando i notebook in Amazon SageMaker Studio.






