Utilizzare modelli di base proprietari da Amazon SageMaker JumpStart in Amazon SageMaker Studio.
'Use proprietary base models from Amazon SageMaker JumpStart in Amazon SageMaker Studio.'
Amazon SageMaker JumpStart è un hub di machine learning (ML) che può aiutarti ad accelerare il tuo percorso di ML. Con SageMaker JumpStart, puoi scoprire e distribuire modelli di base di proprietà pubblica e privata su istanze dedicate di Amazon SageMaker per le tue applicazioni AI generative. SageMaker JumpStart ti consente di distribuire modelli di base da un ambiente isolato dalla rete e non condivide i dati di formazione e inferenza del cliente con i fornitori di modelli.
In questo post, ti guideremo su come iniziare con modelli di proprietà di fornitori di modelli come AI21, Cohere e LightOn da Amazon SageMaker Studio. SageMaker Studio è un ambiente di notebook in cui i clienti scienziati dei dati aziendali di SageMaker valutano e costruiscono modelli per le loro prossime applicazioni AI generative.
Modelli di base in SageMaker
I modelli di base sono modelli di ML su larga scala che contengono miliardi di parametri e sono pre-addestrati su terabyte di dati di testo e immagini in modo da poter eseguire una vasta gamma di attività, come la sintesi di articoli e la generazione di testo, immagini o video. Poiché i modelli di base sono pre-addestrati, possono aiutare a ridurre i costi di formazione e infrastruttura e consentire la personalizzazione per il tuo caso d’uso.
SageMaker JumpStart fornisce due tipi di modelli di base:
- A.I. potrebbe un giorno compiere miracoli medici. Per ora, aiuta a sbrigare la burocrazia.
- La stampa 3D di ceramiche potrebbe aumentare l’efficienza del carburante delle turbine a gas.
- I maschi delle mosche sono migliori nell’accoppiamento dopo aver respinto un rivale robotico.
- Modelli di proprietà – Questi modelli provengono da fornitori come AI21 con i modelli Jurassic-2, Cohere con Cohere Command e LightOn con Mini addestrati su algoritmi e dati proprietari. Non è possibile visualizzare gli artefatti del modello, come il peso e gli script, ma è comunque possibile distribuire su istanze SageMaker per l’infrazione.
- Modelli disponibili pubblicamente – Questi provengono da hub di modelli popolari come Hugging Face con Stable Diffusion, Falcon e FLAN addestrati su algoritmi e dati disponibili pubblicamente. Per questi modelli, gli utenti hanno accesso agli artefatti del modello e sono in grado di affinare con i propri dati prima della distribuzione per l’infrazione.
Scopri i modelli
Puoi accedere ai modelli di base attraverso SageMaker JumpStart nell’interfaccia utente di SageMaker Studio e nell’SDK di Python di SageMaker. In questa sezione, vediamo come scoprire i modelli nell’interfaccia utente di SageMaker Studio.
SageMaker Studio è un ambiente di sviluppo integrato (IDE) basato sul web per ML che consente di creare, eseguire il training, il debug, la distribuzione e il monitoraggio dei modelli di ML. Per maggiori dettagli su come iniziare e configurare SageMaker Studio, consulta Amazon SageMaker Studio.
Una volta che ti trovi nell’interfaccia utente di SageMaker Studio, puoi accedere a SageMaker JumpStart, che contiene modelli pre-addestrati, notebook e soluzioni pre-costruite, sotto Soluzioni pre-costruite e automatizzate.
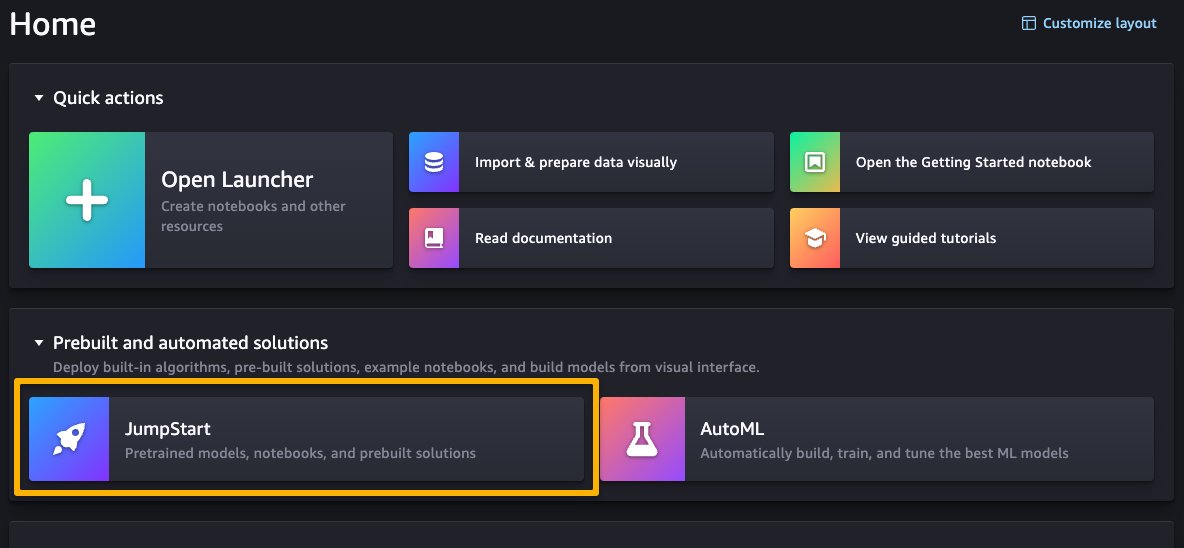
Dalla pagina principale di SageMaker JumpStart, puoi sfogliare soluzioni, modelli, notebook e altre risorse. La seguente schermata mostra un esempio della pagina principale con soluzioni e modelli di base elencati.
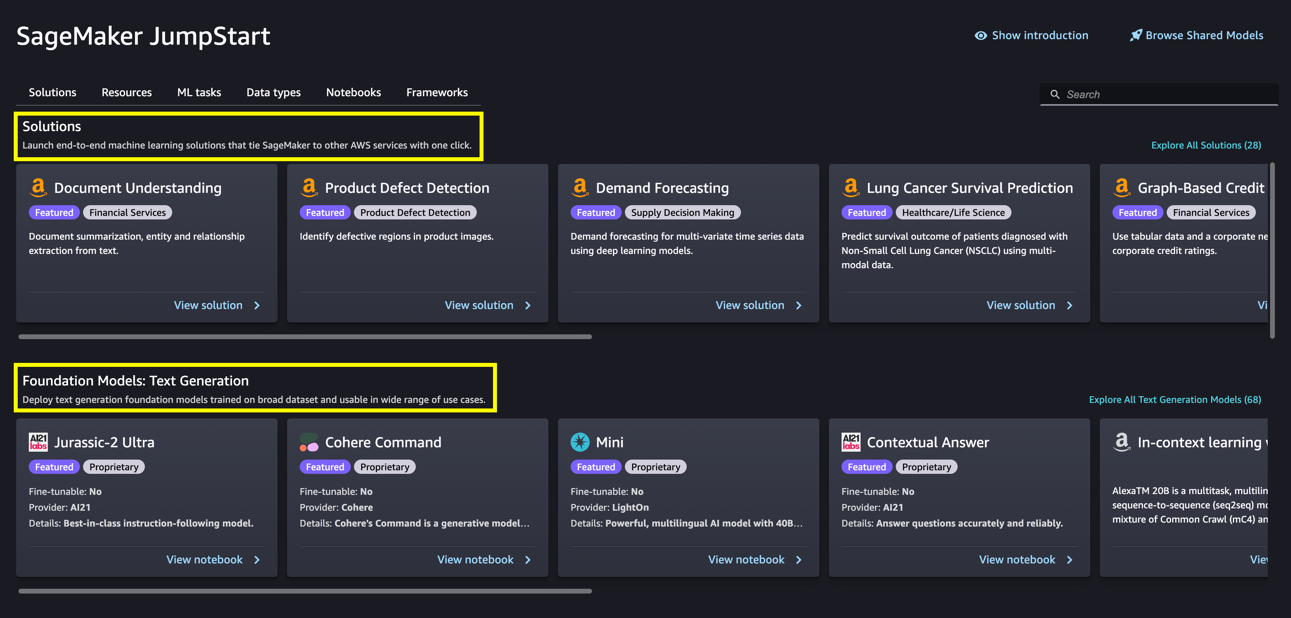
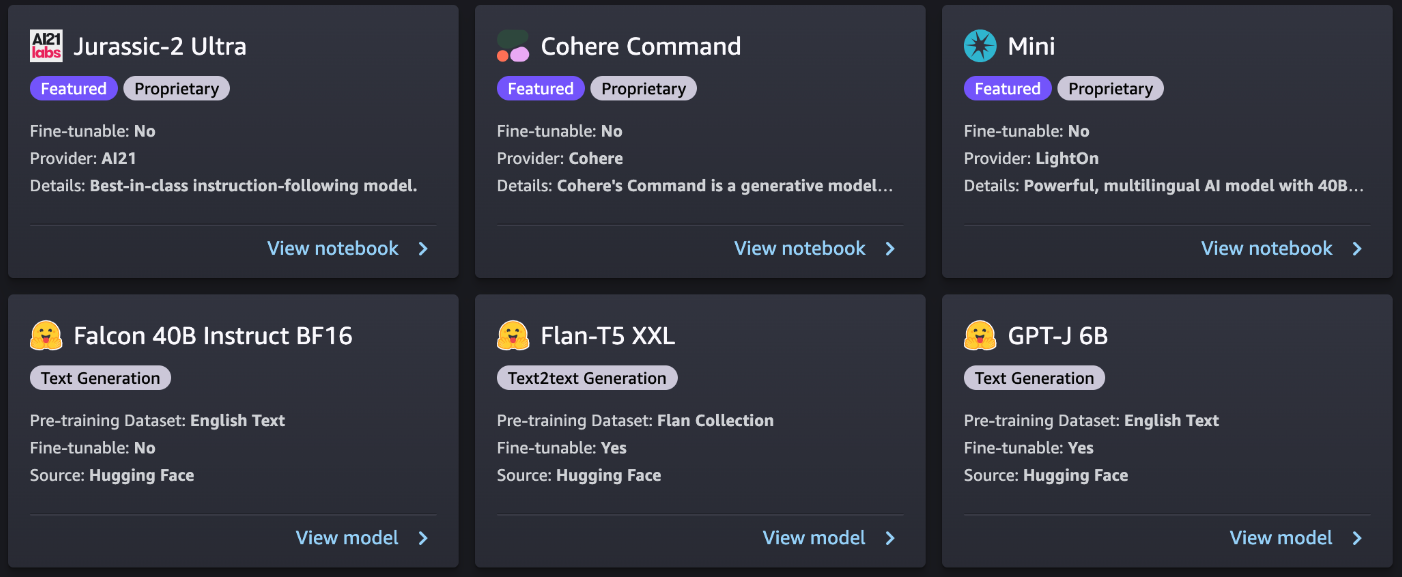
Ogni modello ha una scheda del modello, come mostrato nella seguente schermata, che contiene il nome del modello, se è possibile affinarlo o meno, il nome del fornitore e una breve descrizione sul modello. Puoi anche aprire la scheda del modello per saperne di più sul modello e iniziare la formazione o la distribuzione.
Abbonati in AWS Marketplace
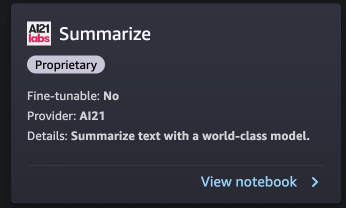
I modelli di proprietà in SageMaker JumpStart sono pubblicati dai fornitori di modelli come AI21, Cohere e LightOn. Puoi identificare i modelli proprietari dall’etichetta “Proprietario” sulle schede del modello, come mostrato nella seguente schermata.
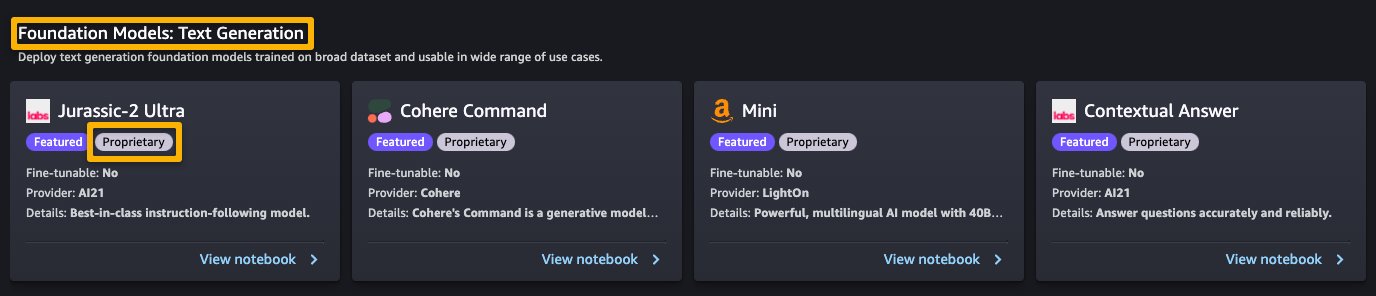
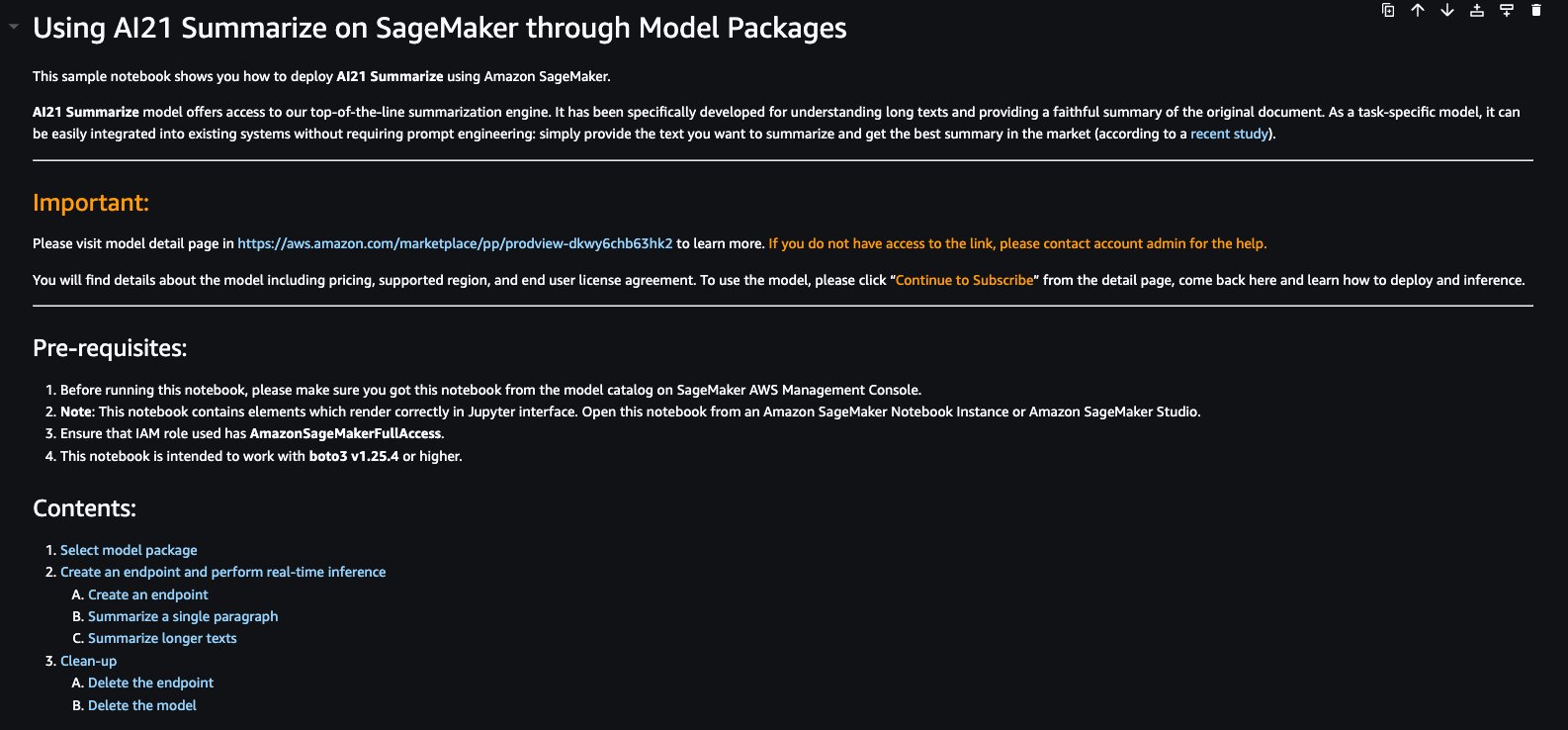
Puoi scegliere Visualizza notebook sulla scheda del modello per aprire il notebook in modalità di sola lettura, come mostrato nella seguente schermata. Puoi leggere il notebook per importanti informazioni sui prerequisiti e altre istruzioni d’uso.
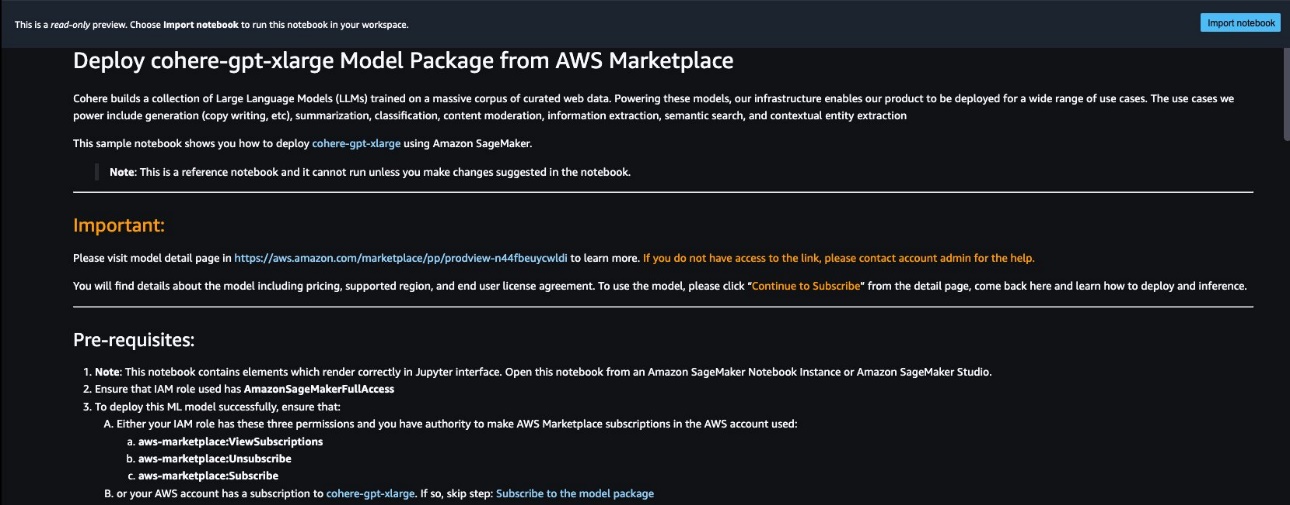
Dopo aver importato il notebook, devi selezionare l’ambiente notebook appropriato (immagine, kernel, tipo di istanza, ecc.) prima di eseguire i codici. Dovresti anche seguire le istruzioni di abbonamento e utilizzo per il notebook selezionato.
Prima di utilizzare un modello proprietario, è necessario abbonarsi al modello da AWS Marketplace:
- Apri la pagina di elenco del modello in AWS Marketplace.
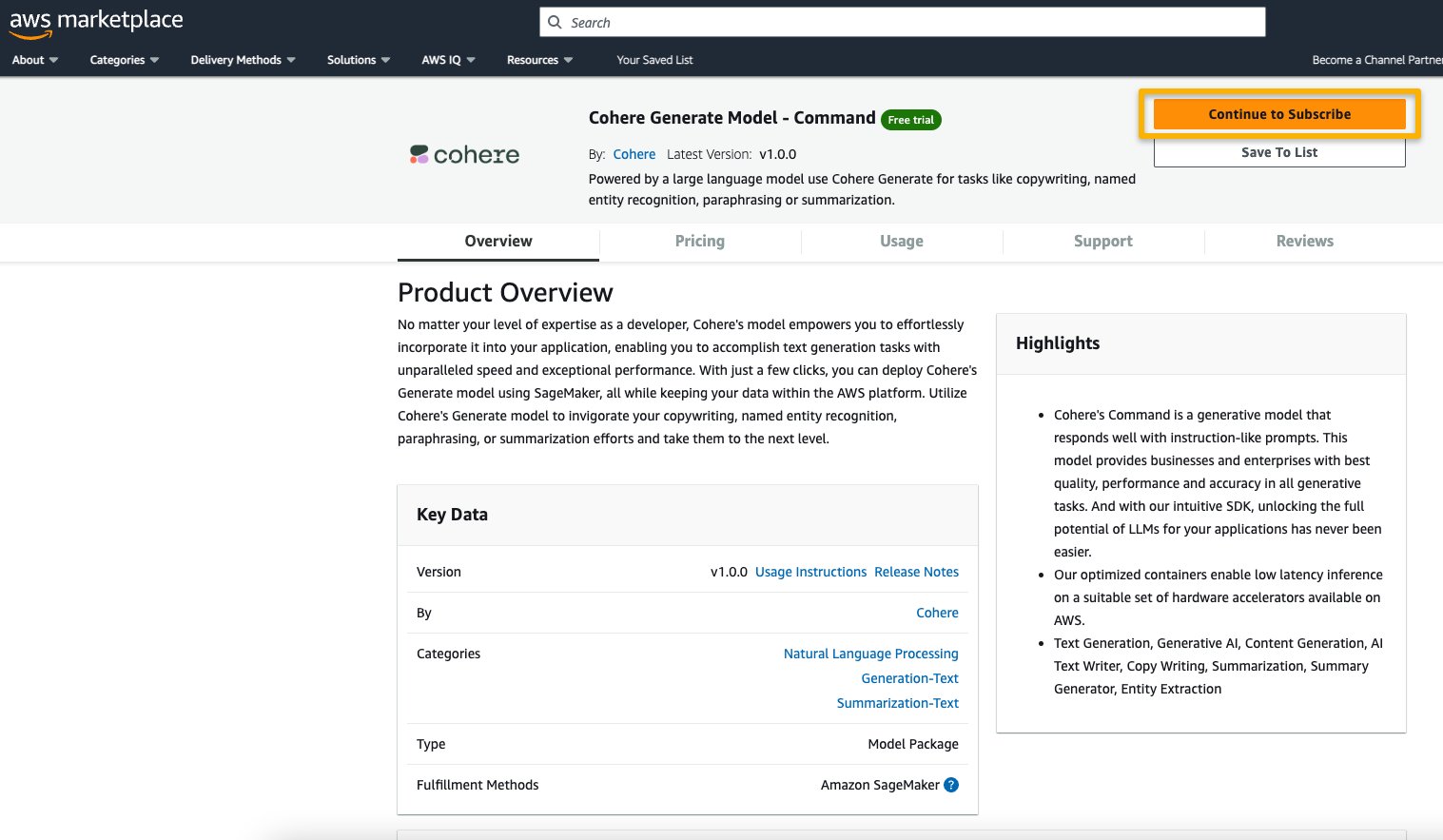
L’URL è fornito nella sezione Importante del notebook, o puoi accedervi dalla pagina del servizio SageMaker JumpStart. La pagina di elenco mostra una panoramica, i prezzi, l’utilizzo e le informazioni di supporto sul modello.
- Nella pagina di elenco di AWS Marketplace, scegli Continua per abbonarti.
Se non hai le autorizzazioni necessarie per visualizzare o abbonarti al modello, contatta il tuo amministratore IT o il punto di contatto degli acquisti per abbonarti al modello al tuo posto. Molte aziende possono limitare le autorizzazioni di AWS Marketplace per controllare le azioni che una persona con tali autorizzazioni può eseguire nel portale di gestione di AWS Marketplace.
- Nella Pagina di abbonamento a questo software, controlla i dettagli e scegli Accetto offerta se tu e la tua organizzazione siete d’accordo con i termini dell’EULA, i prezzi e i termini di supporto.
Se hai domande o richieste di sconto sul volume, contatta direttamente il fornitore del modello tramite l’e-mail di supporto fornita sulla pagina dei dettagli o contatta il tuo team di account AWS.
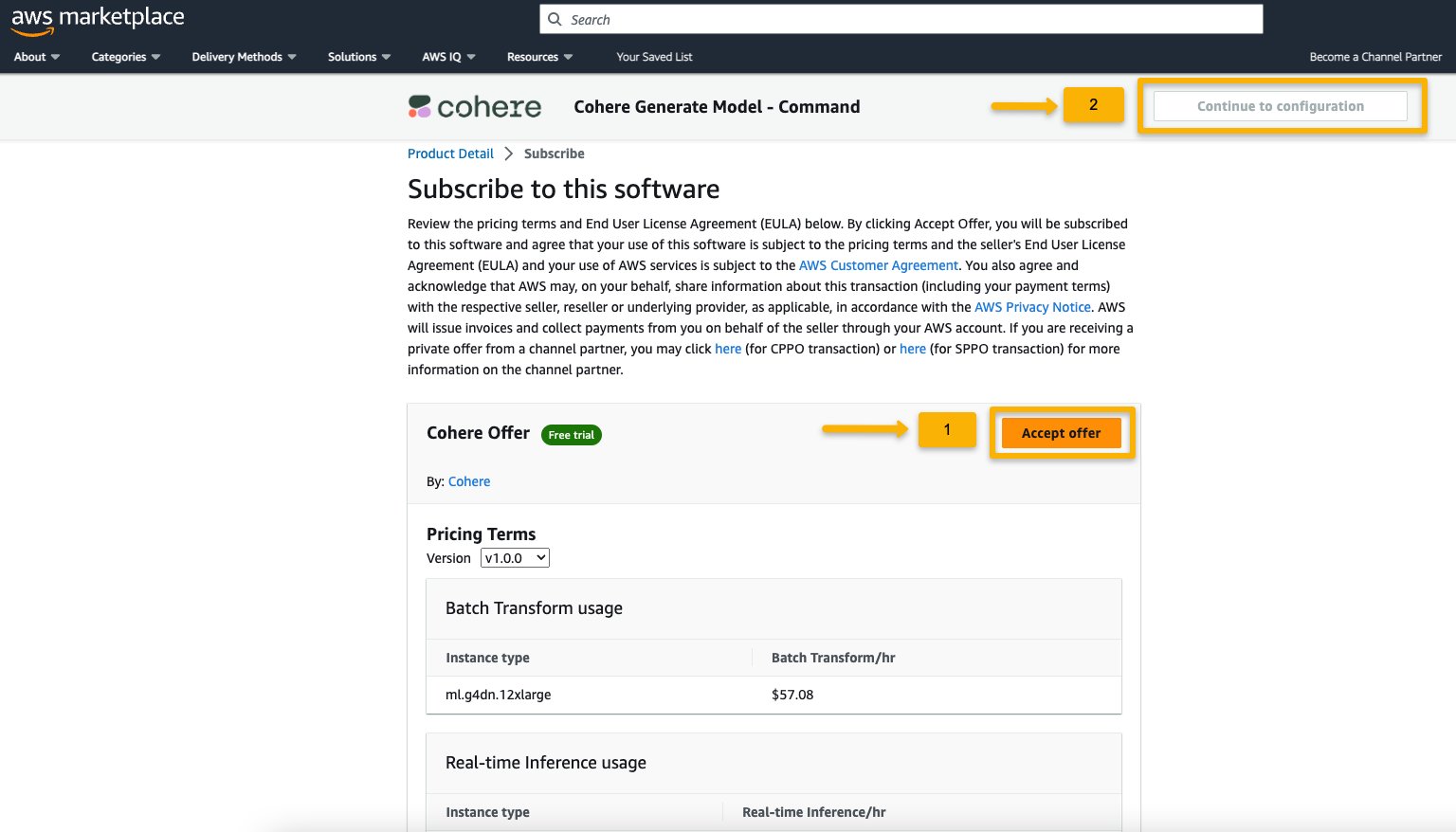
- Scegli Continua per la configurazione e scegli una regione.
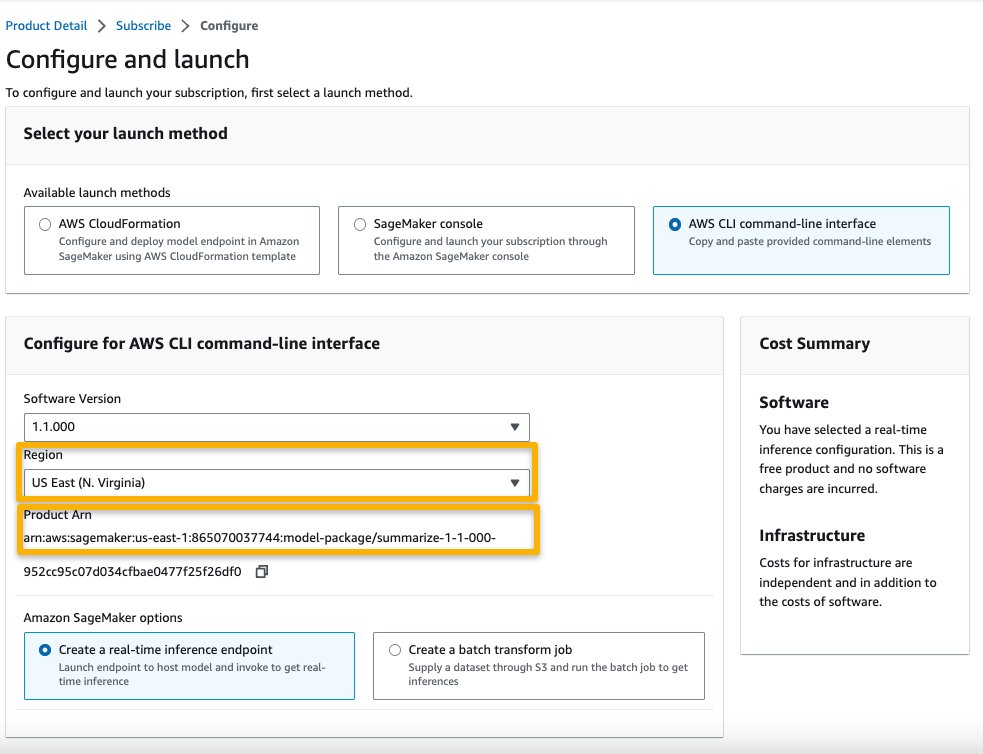
Vedrai visualizzato un ARN di prodotto. Questo è l’ARN del pacchetto modello di cui hai bisogno per specificare durante la creazione di un modello distribuibile utilizzando Boto3.
- Copia l’ARN corrispondente alla tua regione e specifica lo stesso nelle istruzioni della cella del notebook.
Esempi di inferenza con prompt di esempio
Guardiamo alcuni dei modelli fondamentali di esempio di A21 Labs, Cohere e LightOn che sono scopribili da SageMaker JumpStart in SageMaker Studio. Tutti loro hanno le stesse istruzioni per abbonarsi da AWS Marketplace e importare e configurare il notebook.
AI21 Sommarizzazione
Il modello di sommarizzazione di A121 Labs condensa i testi lunghi in brevi frammenti facili da leggere che rimangono coerenti con la fonte. Il modello è addestrato per generare sommari che catturano le idee chiave basate su un corpo di testo. Non richiede alcun prompt. Basta inserire il testo che deve essere riassunto. Il tuo testo di origine può contenere fino a 50.000 caratteri, che corrispondono a circa 10.000 parole o impressionanti 40 pagine.
Il notebook di esempio per il modello di sommarizzazione AI21 fornisce importanti prerequisiti che devono essere seguiti. Ad esempio, il modello è abbonato da AWS Marketplace, ha le appropriate autorizzazioni di ruoli IAM e la versione richiesta di boto3, ecc. Ti guida attraverso come selezionare il pacchetto modello, creare i punti finali per l’inferenza in tempo reale e quindi pulire.
Il pacchetto modello selezionato contiene la mappatura di ARN alle regioni. Questa è l’informazione che hai acquisito dopo aver scelto Continua alla configurazione sulla pagina di sottoscrizione del Marketplace AWS (nella sezione Valuta e sottoscrivi nel Marketplace) e quindi selezionando una regione per la quale vedrai l’ARN del prodotto corrispondente.
Il notebook potrebbe già avere ARN precompilati.

Quindi importi alcune librerie necessarie per eseguire questo notebook e installi wikipedia, che è una libreria Python che facilita l’accesso e l’analisi dei dati da Wikipedia. Il notebook lo utilizza successivamente per mostrare come riassumere un lungo testo da Wikipedia.
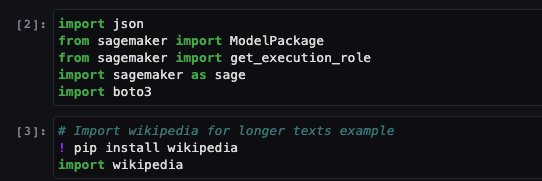
Il notebook procede anche all’installazione del SDK Python ai21, che è un wrapper intorno alle API di SageMaker come deploy e invoke endpoint.
I successivi pochi blocchi del notebook seguono i seguenti passaggi:
- Seleziona la regione e recupera l’ARN del pacchetto modello dalla mappa del pacchetto modello
- Crea il tuo endpoint di inferenza selezionando un tipo di istanza (a seconda del tuo caso d’uso e dell’istanza supportata per il modello; vedi Modelli specifici per attività per maggiori dettagli) su cui eseguire il modello
- Crea un modello distribuibile dal pacchetto modello
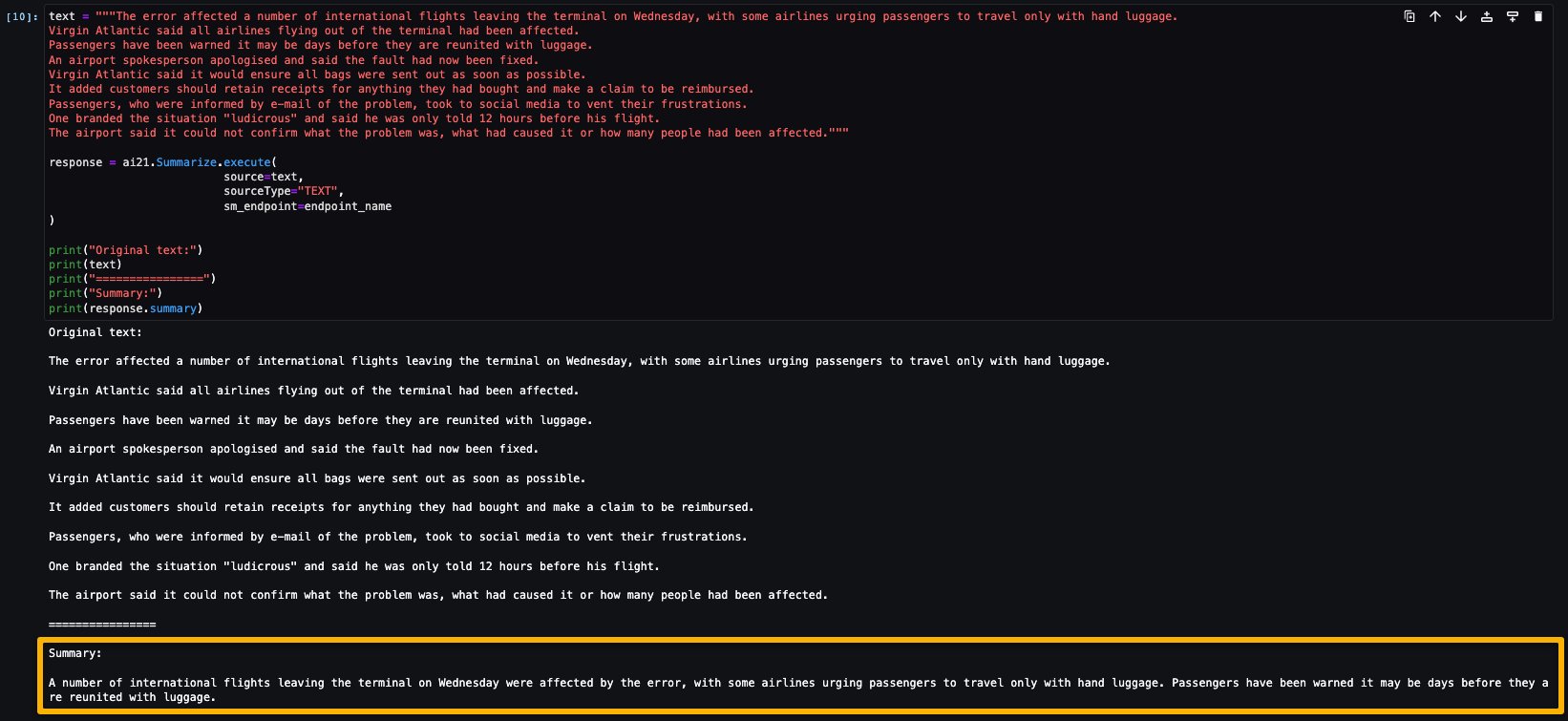
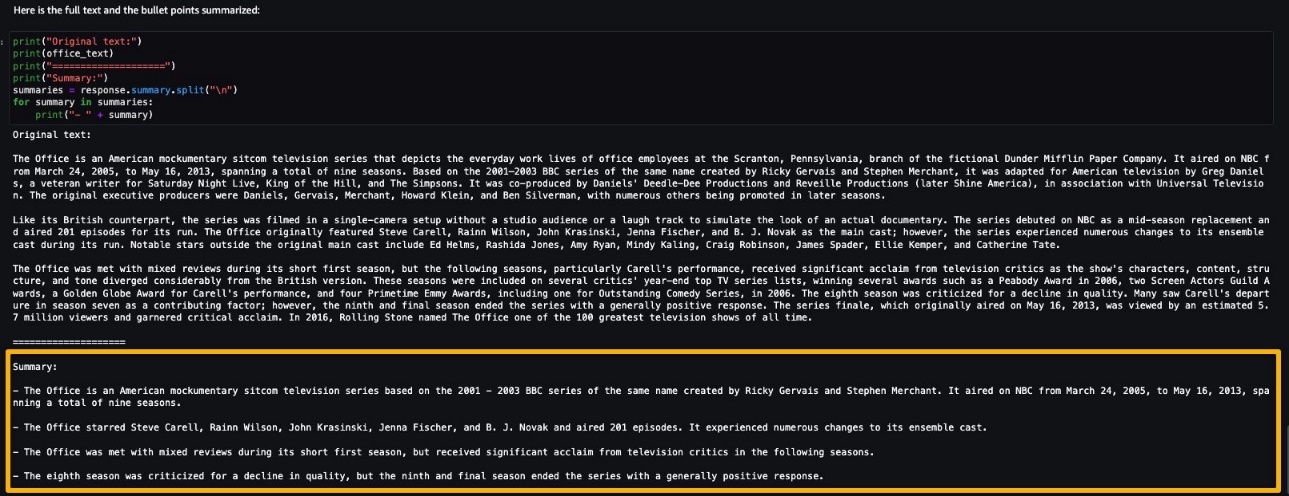
Eseguiamo quindi l’inferenza per generare un riassunto di un singolo paragrafo tratto da un articolo di notizie. Come puoi vedere nell’output, il testo riassunto è presentato come output dal modello.
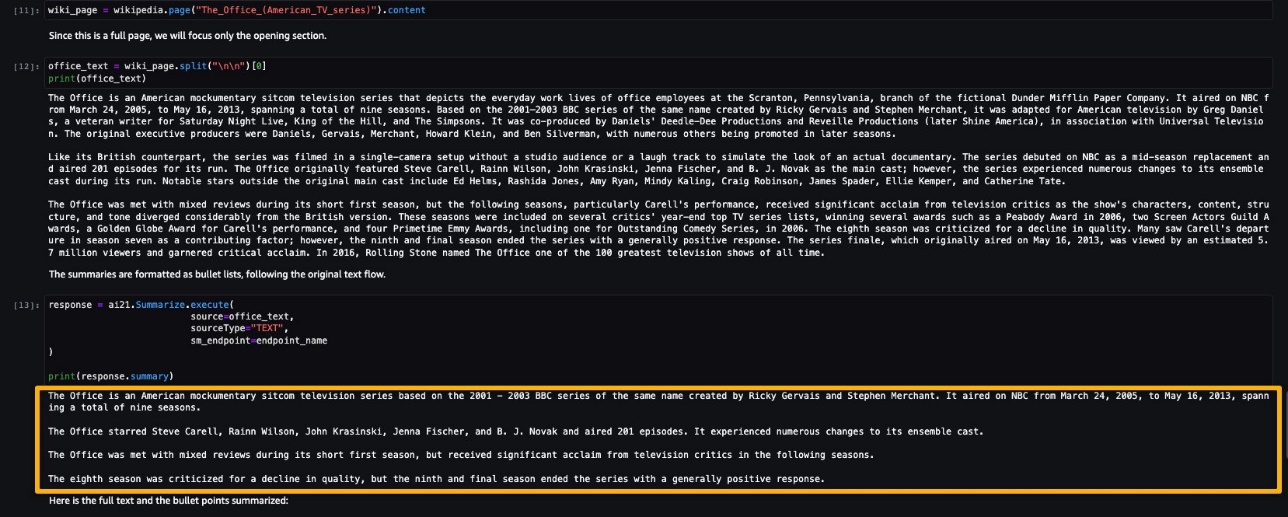
AI21 Summarize può gestire input fino a 50.000 caratteri. Ciò si traduce approssimativamente in 10.000 parole o 40 pagine. Come dimostrazione del comportamento del modello, carichiamo una pagina da Wikipedia.
Ora che hai eseguito un’inferenza in tempo reale per il test, potresti non aver più bisogno dell’endpoint. Puoi eliminare l’endpoint per evitare di essere addebitato.
Comando Cohere
Il Comando Cohere è un modello generativo che risponde bene con prompt di istruzioni. Questo modello fornisce alle aziende e alle imprese la migliore qualità, prestazioni e precisione in tutte le attività generative. Puoi utilizzare il modello Command di Cohere per rinvigorire i tuoi sforzi di copywriting, riconoscimento di entità nominate, parafrasi o riassunto e portarli al livello successivo.
Il notebook di esempio per il modello Cohere Command fornisce importanti prerequisiti che devono essere seguiti. Ad esempio, il modello è sottoscritto dal AWS Marketplace, ha le appropriate autorizzazioni IAM, la versione di boto3 richiesta, ecc. Ti guida attraverso come selezionare il pacchetto del modello, creare endpoint per l’inferenza in tempo reale e poi ripulirli.
Alcuni dei compiti sono simili a quelli trattati nell’esempio precedente del notebook, come l’installazione di Boto3, l’installazione di cohere-sagemaker (il pacchetto fornisce la funzionalità sviluppata per semplificare l’interfacciamento con il modello Cohere) e l’ottenimento della sessione e della Regione.
Esploriamo la creazione dell’endpoint. Fornisci il pacchetto del modello ARN, il nome dell’endpoint, il tipo di istanza da utilizzare e il numero di istanze. Una volta creato, l’endpoint appare nella sezione endpoint di SageMaker.

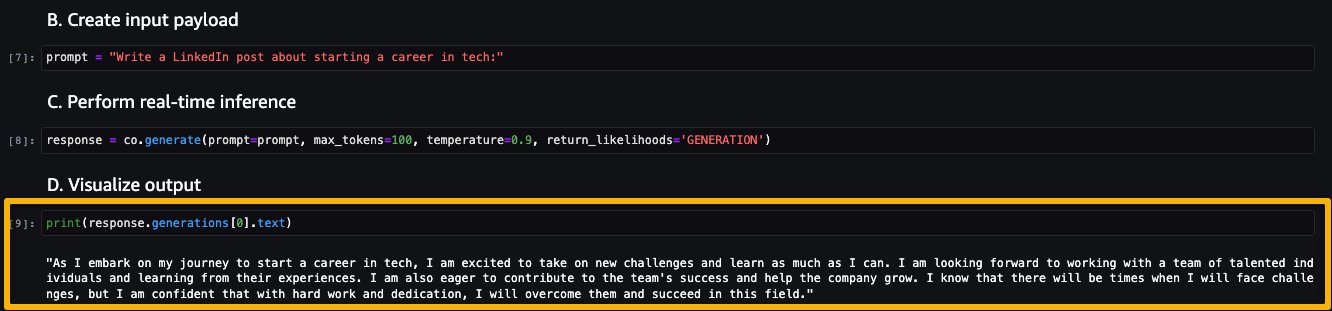
Ora eseguiamo l’inferenza per vedere alcuni degli output del modello Command.
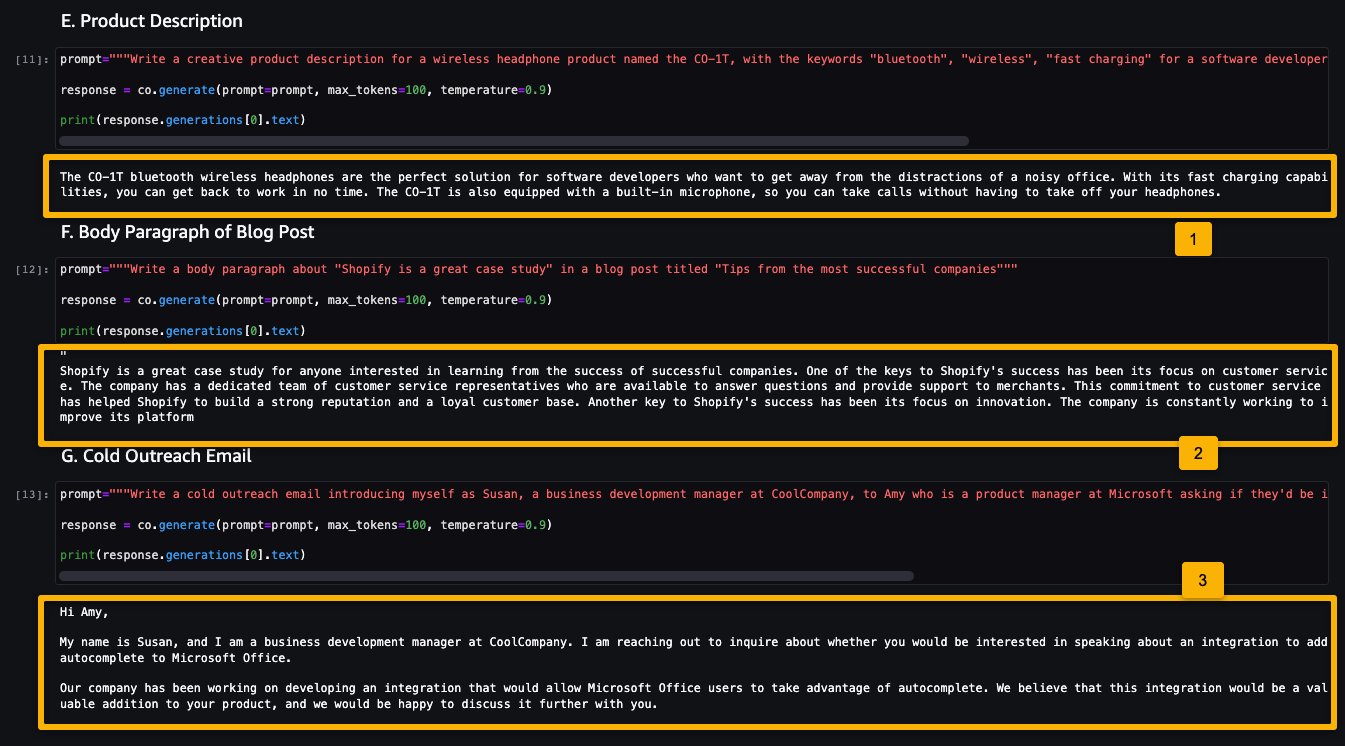
La seguente schermata mostra un esempio di generazione di un lavoro e il suo output. Come puoi vedere, il modello ha generato un post a partire dal prompt fornito.
Ora guardiamo gli esempi seguenti:
- Generare una descrizione del prodotto
- Generare un paragrafo di un post di un blog
- Generare una email di outreach
Come puoi vedere, il modello Cohere Command ha generato testo per varie attività generative.
Ora che hai eseguito l’inferenza in tempo reale per testare, potresti non aver più bisogno dell’endpoint. Puoi eliminare l’endpoint per evitare addebiti.
LightOn Mini-instruct
Mini-instruct, un modello AI con 40 miliardi di miliardi di parametri creato da LightOn, è un potente sistema AI multilingue che è stato addestrato utilizzando dati di alta qualità provenienti da numerose fonti. È stato costruito per comprendere il linguaggio naturale e reagire a comandi specifici alle tue esigenze. Si comporta in modo eccellente in prodotti per i consumatori come assistenti vocali, chatbot e dispositivi intelligenti. Ha anche una vasta gamma di applicazioni aziendali, tra cui l’assistenza all’agente e la produzione di linguaggio naturale per la cura del cliente automatizzata.
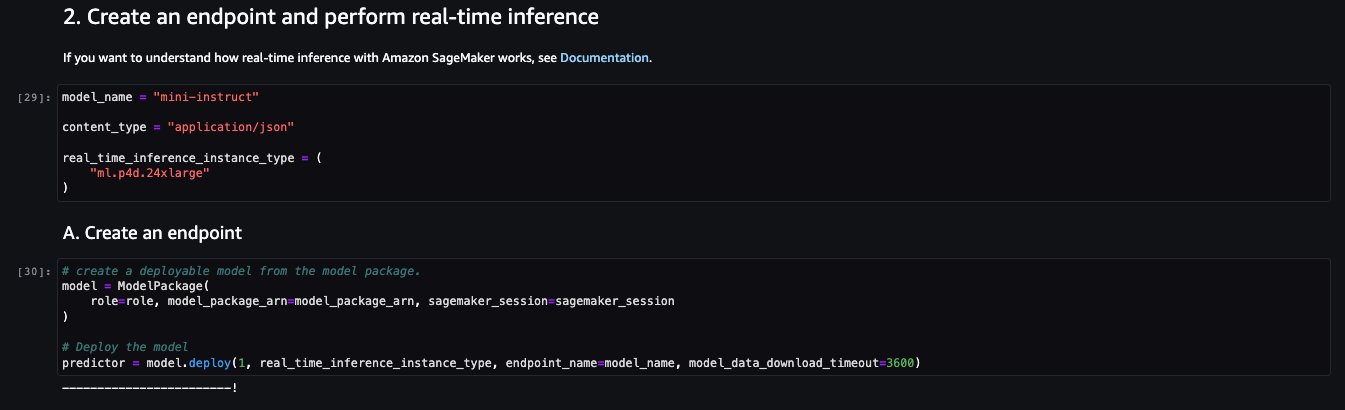
Il notebook di esempio per il modello LightOn Mini-instruct fornisce importanti prerequisiti che devono essere seguiti. Ad esempio, il modello è sottoscritto dal AWS Marketplace, ha le appropriate autorizzazioni IAM, la versione di boto3 richiesta, ecc. Ti guida attraverso come selezionare il pacchetto del modello, creare endpoint per l’inferenza in tempo reale e poi ripulirli.
Alcuni dei compiti sono simili a quelli trattati nell’esempio precedente del notebook, come l’installazione di Boto3 e l’ottenimento della sessione e della Regione.
Guardiamo alla creazione dell’endpoint. Innanzitutto, fornisci il pacchetto del modello ARN, il nome dell’endpoint, il tipo di istanza da utilizzare e il numero di istanze. Una volta creato, l’endpoint appare nella sezione endpoint di SageMaker.
Ora proviamo ad inferire il modello chiedendogli di generare una lista di idee per articoli su un argomento, in questo caso acquerello.
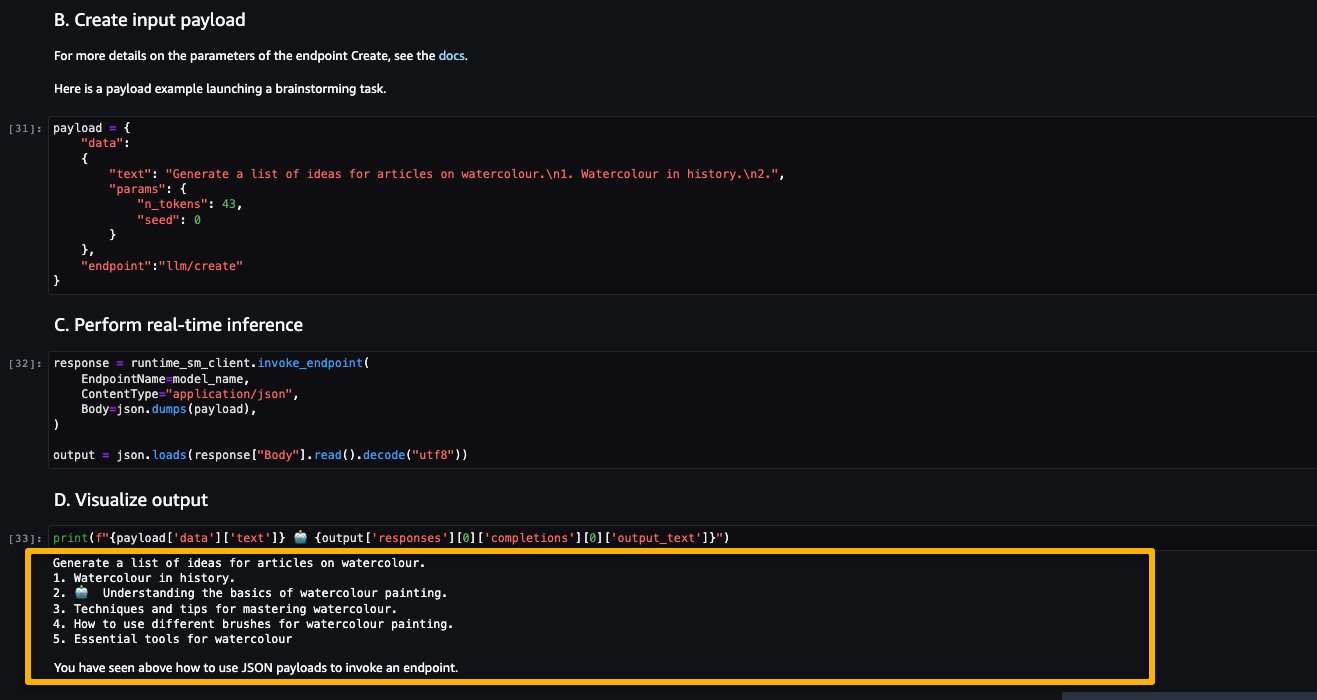
Come puoi vedere, il modello LightOn Mini-instruct è stato in grado di fornire testo generato in base alla richiesta fornita.
Pulizia
Dopo aver testato i modelli e creato i punti di ingresso per gli esempi di modelli proprietari Foundation Models, assicurati di eliminare i punti di ingresso di inferenza di SageMaker e cancellare i modelli per evitare addebiti.
Conclusioni
In questo post, ti abbiamo mostrato come iniziare con i modelli proprietari di fornitori di modelli come AI21, Cohere e LightOn in SageMaker Studio. I clienti possono scoprire e utilizzare i modelli Foundation proprietari in SageMaker JumpStart da Studio, l’SDK di SageMaker e la Console di SageMaker. Con questo, hanno accesso a modelli di ML su larga scala che contengono miliardi di parametri e sono preaddestrati su terabyte di dati di testo e immagini in modo che i clienti possano svolgere una vasta gamma di compiti come la sintesi di articoli e la generazione di testo, immagini o video. Poiché i modelli di base sono preaddestrati, possono anche aiutare a ridurre i costi di formazione e infrastruttura e consentire la personalizzazione per il tuo caso d’uso.
Risorse
- Documentazione di SageMaker JumpStart
- Documentazione dei modelli Foundation di SageMaker JumpStart
- Pagina dei dettagli del prodotto SageMaker JumpStart
- Catalogo dei modelli SageMaker JumpStart