Dall’valutazione all’illuminazione Approfondire le previsioni fuori campione nella validazione incrociata
Prediction extrapolation in cross-validation from evaluation to illumination.
Svelare intuizioni e superare limitazioni attraverso le previsioni out-of-fold.
Comprendere la cross-validazione e applicarla nel lavoro quotidiano pratico è una competenza indispensabile per ogni data scientist. Mentre lo scopo principale della cross-validazione è valutare le prestazioni del modello e ottimizzare gli iperparametri, offre ulteriori risultati che vanno presi in considerazione. Ottenendo e combinando le previsioni per ogni fold, possiamo generare previsioni del modello per l’intero set di addestramento, comunemente conosciute come previsioni out-of-sample o out-of-fold.
È fondamentale non sottovalutare queste previsioni, in quanto contengono una ricchezza di informazioni preziose sull’approccio di modellazione e sul dataset stesso. Esplorandole a fondo, è possibile scoprire risposte a domande come perché il modello non funziona come previsto, come migliorare l’ingegneria delle caratteristiche e se ci sono limitazioni intrinseche nel dataset.
L’approccio generale è semplice: indagare i campioni in cui il modello mostra una grande confidenza ma commette errori. Nel post, mostrerò come queste previsioni mi hanno aiutato in tre progetti del mondo reale.
Individuare le limitazioni dei dati
Ho lavorato su un progetto di manutenzione predittiva in cui l’obiettivo era prevedere i guasti dei veicoli in anticipo. Uno degli approcci che ho esplorato è stato addestrare un classificatore binario. È stato un metodo relativamente semplice e diretto.
- Progetto di Data Science per la previsione delle valutazioni dei film di Rotten Tomatoes Primo Approccio
- Cos’è il dato sintetico? Tipi, casi d’uso e applicazioni per l’apprendimento automatico e la privacy.
- Previsione del tempo di impatto l’altro modo per la previsione probabilistica delle serie temporali.
Dopo l’addestramento utilizzando le cross-validazioni su serie temporali, ho esaminato le previsioni out-of-sample. In particolare, mi sono concentrato sui falsi positivi e falsi negativi, ossia i campioni in cui il modello ha faticato ad imparare. Queste previsioni errate non sono sempre causate da un errore del modello. È possibile che alcuni campioni abbiano conflitti tra loro e confondano il modello.
Ho trovato diversi casi di falsi negativi etichettati come guasti, ma il modello li considerava raramente come tali. Questa osservazione ha suscitato la mia curiosità. Approfondendo ulteriormente l’indagine, ho scoperto molti campioni negativi accurati praticamente identici a quelli falsi negativi.
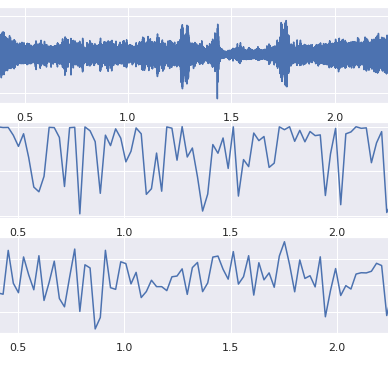
La Figura 1 confronta i falsi negativi e i veri negativi tramite la visualizzazione dei dati. Non entrerò nei dettagli. L’idea è eseguire gli algoritmi dei nearest-neighbors basati sulla distanza euclidea o sulla distanza di Mahalanobis nello spazio dei dati grezzi; ho trovato campioni estremamente vicini a quei campioni falsi negativi che sono tutti veri negativi. In altre parole, queste istanze di guasto sono circondate da molti buoni esempi.


Ora ci troviamo di fronte a una tipica limitazione di un dataset: campioni confusi. O i label sono sbagliati, o abbiamo bisogno di più informazioni (più dimensioni) per separarli. C’è una possibile terza via: che ne dici di trasferire l’intero spazio in uno spazio nuovo in cui i campioni confusi possano essere facilmente distinti? Non funzionerà qui. Primo, la confusione è avvenuta nei dati di input grezzi. È come se per un dataset di classificazione delle immagini, un’immagine fosse etichettata come cane e l’altra quasi identica fosse etichettata come gatto. Secondo, il modo di pensare è incentrato sul modello e generalmente aumenta la complessità del modello.
Dopo aver sollevato queste questioni al cliente, hanno confermato che i label erano corretti. Tuttavia, hanno ammesso che alcuni veicoli che sembravano funzionare bene potevano improvvisamente subire guasti senza alcun sintomo precedente, il che è piuttosto difficile da prevedere. I campioni falsi negativi che ho trovato hanno mostrato perfettamente questi guasti imprevisti.
Conducendo questa analisi delle previsioni out-of-sample dalle cross-validazioni, ho non solo acquisito una comprensione più profonda del problema e dei dati, ma ho anche fornito al cliente esempi tangibili che mostravano le limitazioni del dataset. Questo è stato un prezioso contributo sia per me che per il cliente.
Ispirare l’ingegneria delle caratteristiche
In questo progetto, il cliente desiderava utilizzare i dati stradali del veicolo per classificare determinati eventi, come i cambi di corsia effettuati dal veicolo stesso o l’accelerazione e i cambi di corsia dei veicoli precedenti. I dati sono principalmente dati di serie temporali raccolti da diversi sensori sonar. Alcune informazioni critiche sono la velocità relativa degli oggetti circostanti e le distanze (nelle direzioni x e y) del veicolo stesso rispetto agli altri veicoli e corsie circostanti. Ci sono anche registrazioni video da cui gli annotatori etichettano gli eventi.
Nel momento in cui eseguivo la classificazione sugli eventi di cambio corsia del veicolo davanti, ho incontrato un paio di casi interessanti in cui il modello etichettava l’evento come se stesse accadendo, ma la verità era diversa. In termini di data science, erano falsi positivi con previsioni con una probabilità molto alta.
Per fornire al cliente una rappresentazione visiva delle previsioni del modello, ho presentato loro delle brevi animazioni, come mostrato nella Figura 2. Il modello avrebbe erroneamente etichettato il veicolo davanti come “cambio di corsia” tra le 19:59 e le 20:02.
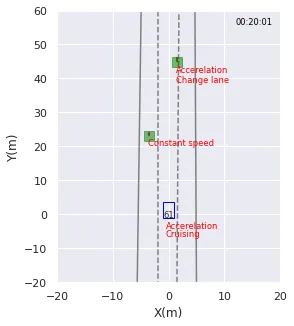
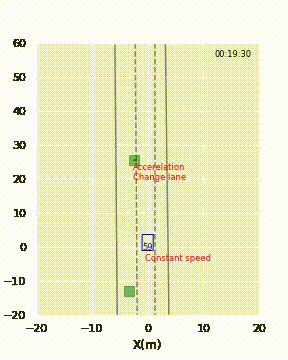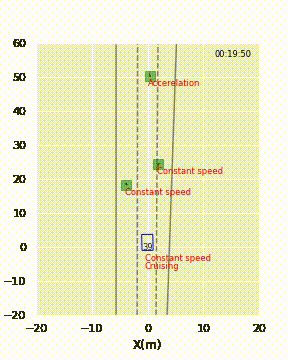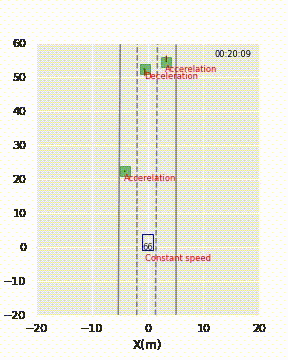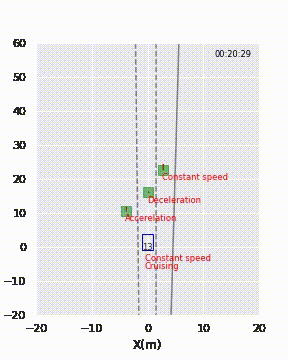
Per risolvere questo mistero, ho guardato il video associato a queste istanze. Si è scoperto che le strade erano curve in quei momenti! Supponiamo che le corsie fossero dritte, allora il modello era corretto. Il modello ha fatto previsioni errate perché non aveva mai imparato che le corsie potessero essere curve.
I dati non contenevano informazioni sulla distanza dei veicoli circostanti dalle corsie. Pertanto, il modello è stato addestrato a utilizzare le distanze dei veicoli circostanti al veicolo stesso e la distanza del veicolo stesso alle corsie per capire la loro posizione relativa alle corsie. Per risolvere queste situazioni, il modello deve conoscere la curvatura delle corsie. Dopo aver parlato con il cliente, ho scoperto le informazioni sulla curvatura nel dataset e ho creato delle caratteristiche esplicite che misurano le distanze dei veicoli circostanti e delle corsie basate su formule di geometria. Ora le prestazioni del modello sono migliorate e non si verificheranno più falsi positivi del genere.
Correzione degli errori di etichetta
Nel terzo esempio, abbiamo cercato di prevedere i risultati specifici dei test delle macchine (passati o falliti), che possono essere considerati come un problema di classificazione binaria.
Ho sviluppato un classificatore con una performance molto alta, suggerendo che il dataset dovrebbe contenere informazioni rilevanti sufficienti per prevedere il target. Per migliorare il modello e comprendere meglio il dataset, concentriamoci sulle previsioni fuori campione dalle cross-validazioni in cui il modello commette errori. I falsi positivi e i falsi negativi sono giacimenti d’oro degni di esplorazione.
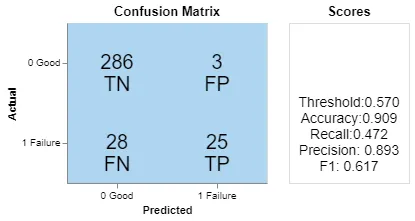
La Figura 3 è una matrice di confusione con una soglia relativamente alta. I tre falsi positivi implicano che il modello li etichetterà come fallimenti, ma la verità di riferimento li etichetta come buoni. Possiamo migliorare l’ingegneria delle caratteristiche per correggerli come nell’esempio precedente, o porci questa domanda: e se le etichette fornite fossero sbagliate e il modello fosse effettivamente corretto? Le persone commettono errori. Proprio come i valori delle altre colonne potrebbero essere anomalie o mancanti, la colonna di destinazione stessa potrebbe essere rumorosa e soggetta ad imprecisioni.
Non è stato facile dimostrare che questi tre campioni sono sbagliati con l’evidenza dell’approccio dei vicini più prossimi perché lo spazio dei dati era sparso. Quindi ho discusso con il cliente del modo in cui i dati erano etichettati. Abbiamo concordato sul fatto che alcuni criteri per determinare i risultati dei test fossero difettosi e che le etichette di alcuni campioni fossero potenzialmente errate o sconosciute. Dopo la pulizia, le etichette di questi tre campioni sono state corrette e le prestazioni del modello sono migliorate.
Non possiamo sempre incolpare la qualità dei dati. Ma ricorda, queste due cose sono altrettanto importanti per i tuoi lavori di scienza dei dati: migliorare il modello e correggere i dati. Non spendere tutta la tua energia nel modellare e assumere che tutti i dati forniti siano privi di errori. Invece, dedicare attenzione ad entrambi gli aspetti è cruciale. Le previsioni fuori campione dalle cross-validation sono uno strumento potente per individuare problemi nei dati.
Per ulteriori informazioni, labelerrors.com elenca errori di etichetta da dataset di benchmark popolari.
Conclusione
La cross-validation ha molteplici scopi oltre a fornire un punteggio. Oltre alla valutazione numerica, offre l’opportunità di estrarre preziose intuizioni dalle previsioni fuori piega. Esaminando attentamente le previsioni riuscite, possiamo comprendere meglio i punti di forza del modello e identificare le caratteristiche più influenti. Allo stesso modo, analizzare le previsioni non riuscite fa luce sulle limitazioni sia dei dati che del modello, ispirando idee per possibili miglioramenti.
Spero che questo strumento si riveli prezioso per migliorare le tue competenze in scienza dei dati.
Se pensi che questo articolo meriti un plauso, mi farebbe piacere. Puoi plaudire più volte se vuoi; grazie!

Ning Jia
Data Science per le serie temporali
Visualizza elenco 6 storie