Progetto di Data Science per la previsione delle valutazioni dei film di Rotten Tomatoes Primo Approccio
Data Science project for predicting Rotten Tomatoes movie ratings - First Approach.
Prevedere lo stato di un film basato su caratteristiche numeriche e categoriche.

Non è un segreto che prevedere il successo di un film nell’industria dell’intrattenimento possa fare o rompere le prospettive finanziarie di uno studio.
Previsioni accurate consentono agli studi di prendere decisioni ben informate su vari aspetti, come marketing, distribuzione e creazione di contenuti.
- Cos’è il dato sintetico? Tipi, casi d’uso e applicazioni per l’apprendimento automatico e la privacy.
- Previsione del tempo di impatto l’altro modo per la previsione probabilistica delle serie temporali.
- Dopo Twitter
Il bello è che queste previsioni possono aiutare a massimizzare i profitti e minimizzare le perdite ottimizzando l’allocazione delle risorse.
Felizmente, le tecniche di apprendimento automatico forniscono uno strumento potente per affrontare questo problema complesso. Non c’è dubbio che, sfruttando le intuizioni basate sui dati, gli studi possono migliorare significativamente il loro processo decisionale.
Questo progetto di scienza dei dati è stato utilizzato come compito a casa nel processo di reclutamento presso Meta (Facebook). In questo compito a casa, scopriremo come Rotten Tomatoes sta etichettando come ‘Marcio’, ‘Fresco’ o ‘Certified Fresh’.
Per fare ciò, svilupperemo due approcci diversi.
Durante la nostra esplorazione, discuteremo la pre-elaborazione dei dati, vari classificatori e possibili miglioramenti per migliorare le prestazioni dei nostri modelli.
Alla fine di questo post, avrai acquisito una comprensione di come l’apprendimento automatico possa essere impiegato per prevedere il successo dei film e come questa conoscenza possa essere applicata nell’industria dell’intrattenimento.
Ma prima di approfondire, scopriamo i dati su cui lavoreremo.
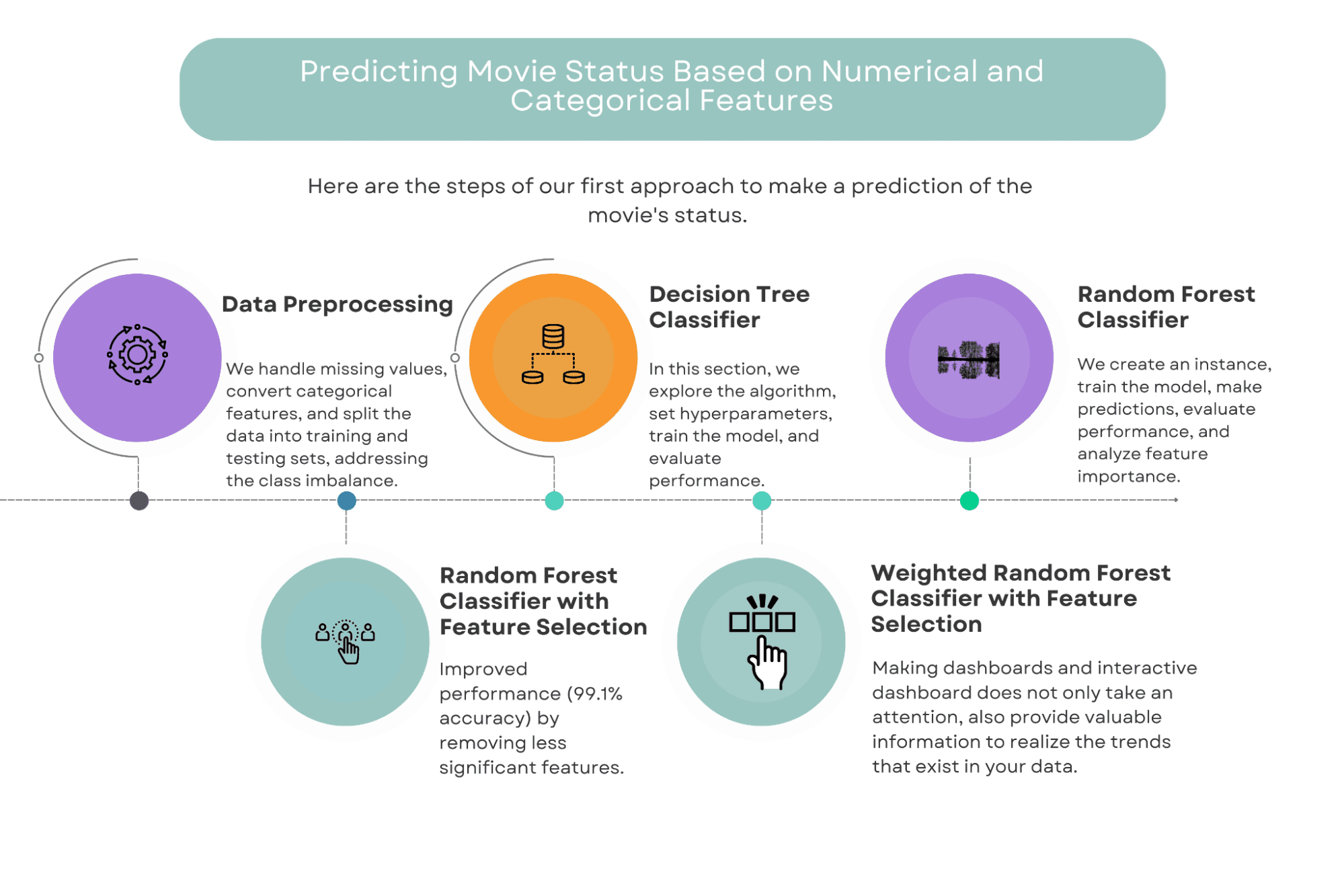
Primo Approccio: Prevedere lo Stato del Film Basato su Caratteristiche Numeriche e Categoriche
In questo approccio, utilizzeremo una combinazione di caratteristiche numeriche e categoriche per prevedere il successo di un film.
Le caratteristiche che prenderemo in considerazione includono fattori come budget, genere, durata e regista, tra gli altri.
Utilizzeremo diversi algoritmi di apprendimento automatico per costruire i nostri modelli, tra cui alberi decisionali, foreste casuali e foreste casuali ponderate con selezione delle caratteristiche.
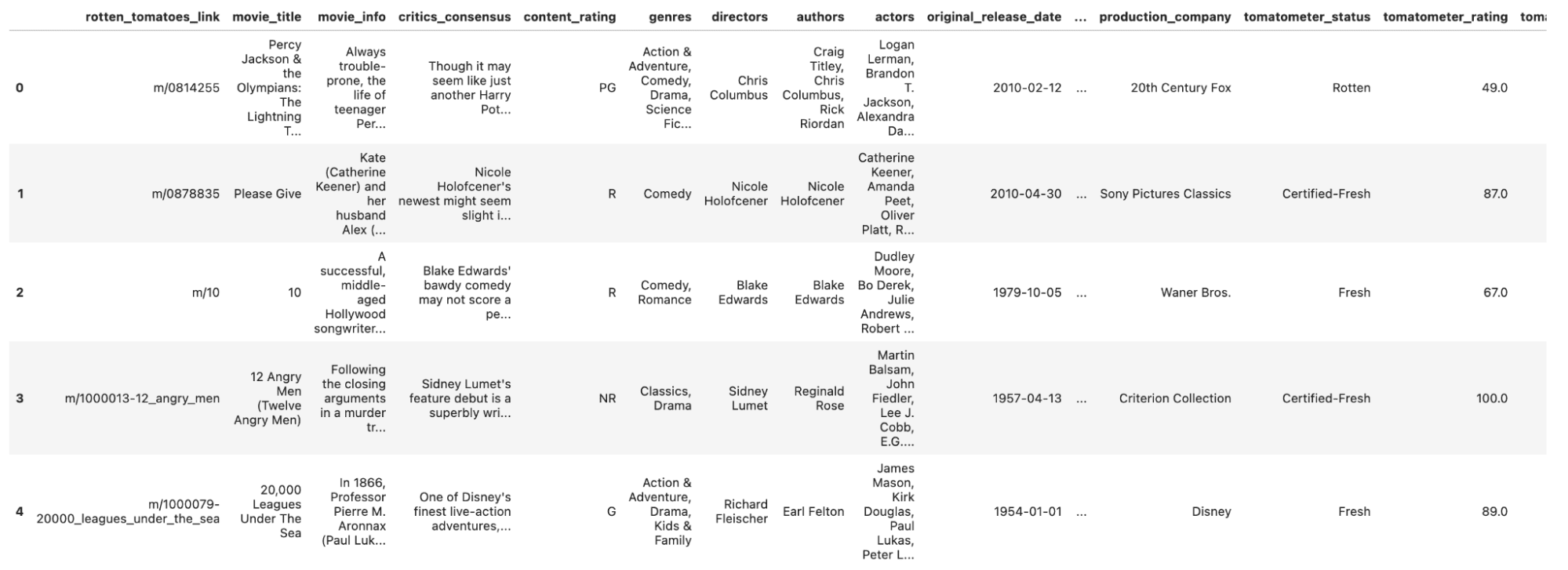
Leggiamo i nostri dati e diamo un’occhiata.
Ecco il codice.
df_movie = pd.read_csv('rotten_tomatoes_movies.csv')
df_movie.head()Ecco l’output.
Ora, iniziamo con la Pre-elaborazione dei Dati.
Ci sono molte colonne nel nostro set di dati.
Guardiamole.
Per sviluppare una migliore comprensione delle caratteristiche statistiche, utilizziamo il metodo describe(). Ecco il codice.
df_movie.describe()Ecco l’output.

Ora, abbiamo una panoramica veloce dei nostri dati, passiamo alla fase di pre-elaborazione.
Pre-elaborazione dei Dati
Prima di poter iniziare a costruire i nostri modelli, è essenziale pre-elaborare i nostri dati.
Ciò comporta la pulizia dei dati gestendo le caratteristiche categoriche e convertendole in rappresentazioni numeriche e la normalizzazione dei dati per garantire che tutte le caratteristiche abbiano uguale importanza.
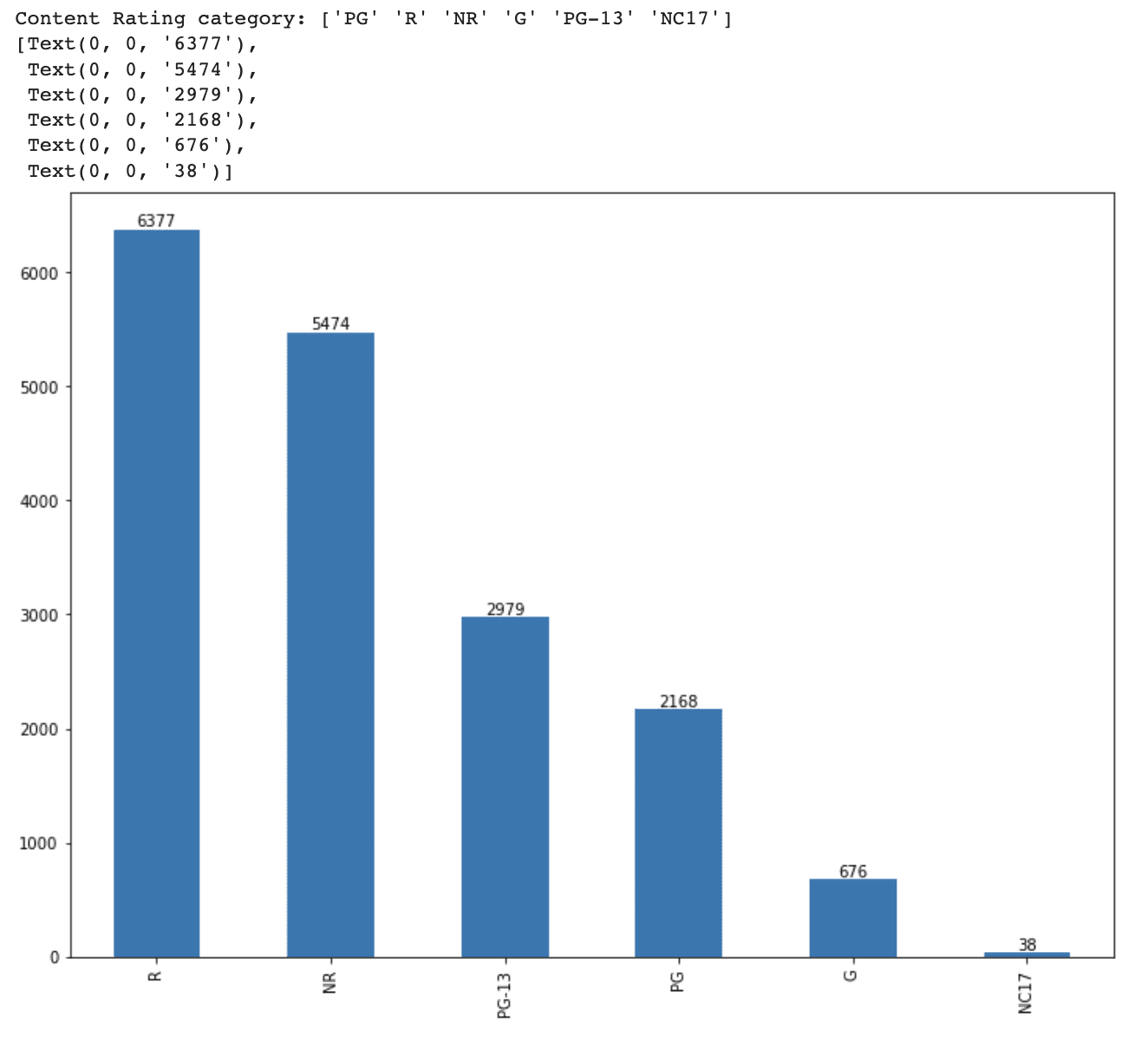
Abbiamo prima esaminato la colonna content_rating per vedere le categorie uniche e la loro distribuzione nel dataset.
print(f'Categorie di Content Rating: {df_movie.content_rating.unique()}')Successivamente, creeremo un grafico a barre per vedere la distribuzione di ogni categoria di content rating.
ax = df_movie.content_rating.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])Ecco il codice completo.
print(f'Categorie di Content Rating: {df_movie.content_rating.unique()}')
ax = df_movie.content_rating.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])Ecco l’output.
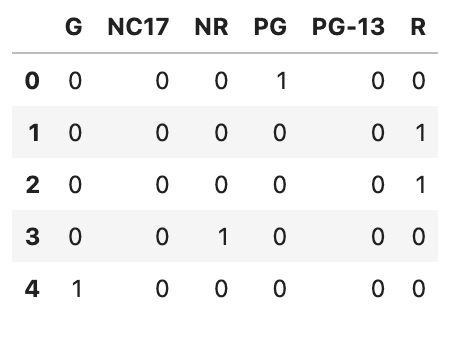
È essenziale convertire le caratteristiche categoriche in forme numeriche per i nostri modelli di apprendimento automatico che richiedono input numerici. Per diversi elementi in questo progetto di scienza dei dati, applicheremo due metodi generalmente accettati: la codifica ordinale e la codifica one-hot. La codifica ordinale è migliore quando le categorie implicano un grado di intensità, ma la codifica one-hot è ideale quando non viene fornita una rappresentazione di magnitudine. Per gli asset “content_rating”, utilizzeremo un metodo di codifica one-hot.
Ecco il codice.
content_rating = pd.get_dummies(df_movie.content_rating)
content_rating.head()Ecco l’output.
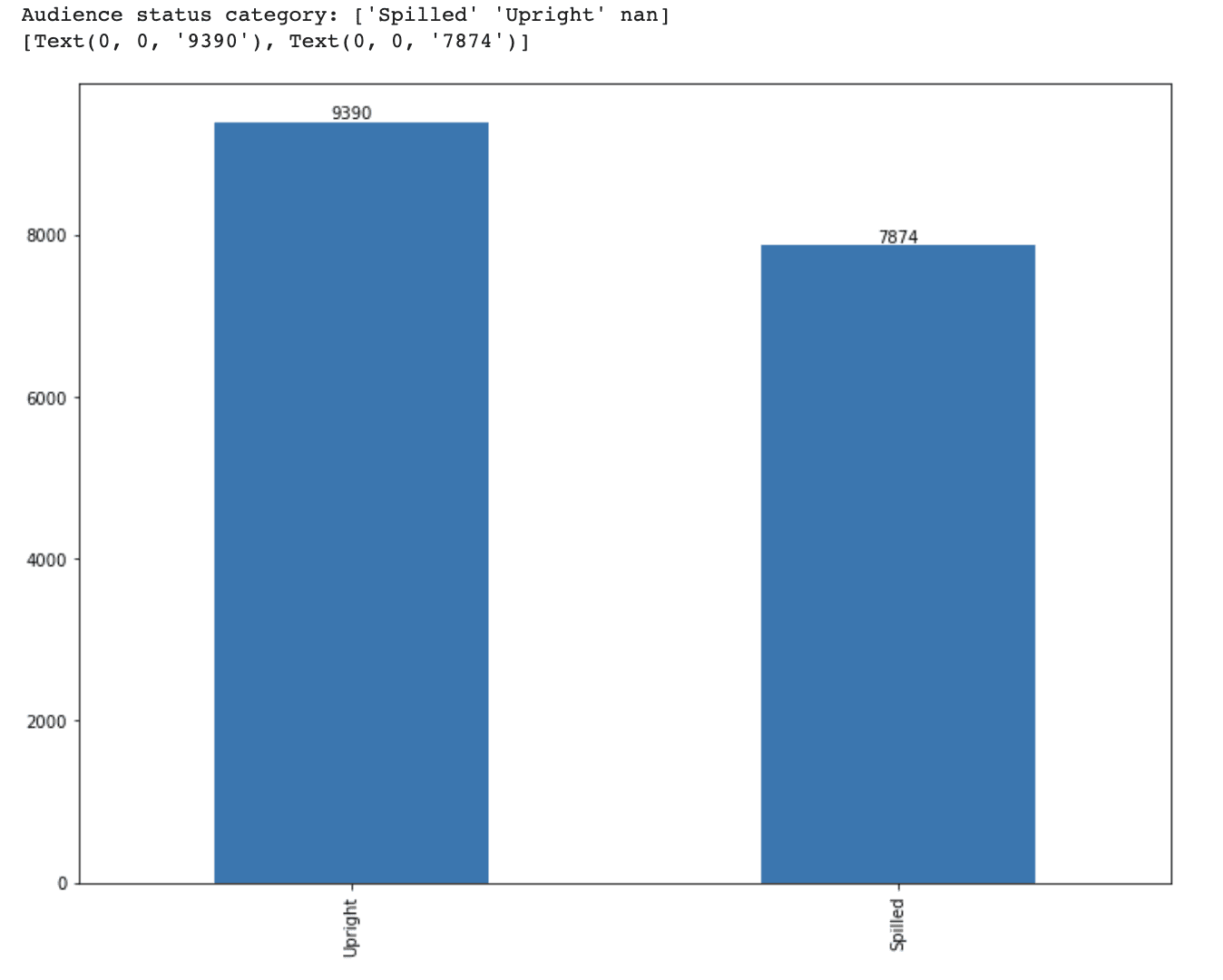
Andiamo avanti e elaboriamo un’altra caratteristica, audience_status.
Questa variabile ha due opzioni: ‘Spilled’ e ‘Upright’.
Abbiamo già applicato la codifica one-hot, quindi ora è il momento di trasformare questa variabile categorica in una variabile numerica utilizzando la codifica ordinale.
Poiché ogni categoria illustra un ordine di grandezza, trasformeremo queste in valori numerici utilizzando la codifica ordinale.
Come abbiamo fatto in precedenza, prima cerchiamo gli stati unici del pubblico.
print(f'Categoria dello stato del pubblico: {df_movie.audience_status.unique()}')Poi, creiamo un grafico a barre e stampiamo i valori in cima alle barre.
# Visualizza la distribuzione di ogni categoria
ax = df_movie.audience_status.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])Ecco il codice completo.
print(f'Categoria dello stato del pubblico: {df_movie.audience_status.unique()}')
# Visualizza la distribuzione di ogni categoria
ax = df_movie.audience_status.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])Ecco l’output.
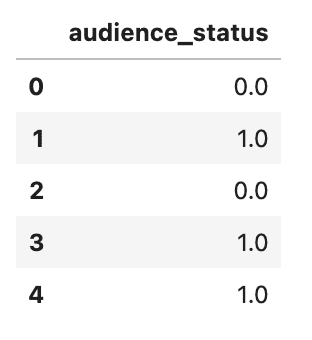
Ora è il momento di effettuare la codifica ordinale utilizzando il metodo replace.
Quindi visualizziamo le prime cinque righe utilizzando il metodo head().
Ecco il codice.
# Codifica la variabile dello stato del pubblico con la codifica ordinale
audience_status = pd.DataFrame(df_movie.audience_status.replace(['Spilled','Upright'],[0,1]))
audience_status.head()Ecco l’output.
Dal momento che la nostra variabile target, tomatometer_status, ha tre categorie distinte, ‘Rotten’, ‘Fresh’ e ‘Certified-Fresh’, queste categorie rappresentano anche un ordine di grandezza.
Ecco il codice.
# Codifica la variabile dello stato del tomatometro con la codifica ordinale
tomatometer_status = pd.DataFrame(df_movie.tomatometer_status.replace(['Rotten','Fresh','Certified-Fresh'],[0,1,2]))
tomatometer_statusEcco l’output.
Dopo aver cambiato le variabili categoriali in variabili numeriche, è ora il momento di combinare i due data frame. Utilizzeremo la funzione pd.concat() di Pandas per fare ciò e il metodo dropna() per rimuovere le righe con valori mancanti in tutte le colonne.
Successivamente, utilizzeremo la funzione head per guardare il DataFrame appena formato.
Ecco il codice.
df_feature = pd.concat([df_movie[['runtime', 'tomatometer_rating', 'tomatometer_count', 'audience_rating', 'audience_count', 'tomatometer_top_critics_count', 'tomatometer_fresh_critics_count', 'tomatometer_rotten_critics_count']], content_rating, audience_status, tomatometer_status], axis=1).dropna()
df_feature.head()Ecco l’output.

Ottimo, ora ispezioniamo le nostre variabili numeriche utilizzando il metodo describe.
Ecco il codice.
df_feature.describe()Ecco l’output.

Ora controlliamo la lunghezza del nostro DataFrame utilizzando il metodo len.
Ecco il codice.
len(df)Ecco l’output.

Dopo aver rimosso le righe con valori mancanti e aver effettuato la trasformazione per la creazione del machine learning, ora il nostro data frame ha 17017 righe.
Analizziamo ora la distribuzione delle nostre variabili target.
Come abbiamo fatto costantemente fin dall’inizio, disegneremo un grafico a barre e metteremo i valori in cima alla barra.
Ecco il codice.
ax = df_feature.tomatometer_status.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])Ecco l’output.

Il nostro dataset contiene 7375 film ‘Rotten’, 6475 film ‘Fresh’ e 3167 film ‘Certified-Fresh’, indicando un problema di sbilanciamento delle classi.
Il problema verrà affrontato in un secondo momento.
Per il momento, dividiamo il nostro dataset in set di test e di addestramento utilizzando una suddivisione dell’80% per il 20%.
Ecco il codice.
X_train, X_test, y_train, y_test = train_test_split(df_feature.drop(['tomatometer_status'], axis=1), df_feature.tomatometer_status, test_size= 0.2, random_state=42)
print(f'La dimensione dei dati di addestramento è {len(X_train)} e la dimensione dei dati di test è {len(X_test)}')Ecco l’output.

Classificatore ad Albero Decisionale
In questa sezione, analizzeremo il Classificatore ad Albero Decisionale, una tecnica di apprendimento automatico comunemente utilizzata per problemi di classificazione e talvolta per la regressione.
Il classificatore funziona suddividendo i punti dati in rami, ognuno dei quali ha un nodo interno (che include un insieme di condizioni) e un nodo foglia (che ha il valore previsto).
Seguendo questi rami e considerando le condizioni (Vero o Falso), i punti dati vengono separati nelle categorie appropriate. Il processo è illustrato di seguito.
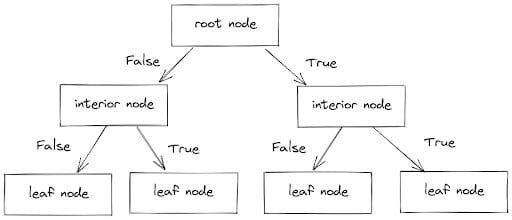 Immagine di Author
Immagine di Author
Quando applichiamo un Classificatore ad Albero Decisionale, possiamo modificare più iperparametri, come la profondità massima dell’albero e il numero massimo di nodi foglia.
Per il nostro primo tentativo, limiteremo il numero di nodi foglia a tre per rendere l’albero semplice e comprensibile.
Per iniziare, creeremo un oggetto Classificatore ad Albero Decisionale con un massimo di tre nodi foglia. Questo classificatore verrà quindi addestrato sui nostri dati di addestramento e utilizzato per generare previsioni sui dati di test. Infine, esamineremo le metriche di accuratezza, precisione e richiamo per valutare le prestazioni del nostro limitato Classificatore ad Albero Decisionale.
Ora implementiamo l’algoritmo dell’Albero Decisionale con sci-kit learn passo dopo passo.
Prima, definiamo un oggetto Decision Tree Classifier con un massimo di tre nodi foglia, utilizzando la funzione DecisionTreeClassifier() della libreria scikit-learn.
Il parametro random_state viene utilizzato per garantire che ogni volta che viene eseguito il codice, vengano prodotti gli stessi risultati.
tree_3_leaf = DecisionTreeClassifier(max_leaf_nodes= 3, random_state=2)È quindi il momento di addestrare il Classificatore ad Albero Decisionale sui dati di addestramento (X_train e y_train), utilizzando il metodo .fit().
tree_3_leaf.fit(X_train, y_train)Successivamente, effettuiamo previsioni sui dati di test (X_test) utilizzando il classificatore addestrato con il metodo predict.
y_predict = tree_3_leaf.predict(X_test)Qui stampiamo il punteggio di accuratezza e il report di classificazione dei valori previsti rispetto ai valori effettivi del target dei dati di test. Utilizziamo le funzioni accuracy_score() e classification_report() della libreria scikit-learn.
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))Infine, visualizzeremo la matrice di confusione per valutare le prestazioni del Classificatore ad Albero Decisionale sui dati di test. Utilizziamo la funzione plot_confusion_matrix() della libreria scikit-learn.
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(tree_3_leaf, X_test, y_test, cmap='cividis', ax=ax)Ecco il codice.
# Istanziare il Classificatore ad Albero Decisionale con un massimo di 3 foglie
tree_3_leaf = DecisionTreeClassifier(max_leaf_nodes= 3, random_state=2)
# Addestrare il classificatore sui dati di addestramento
tree_3_leaf.fit(X_train, y_train)
# Prevedere i dati di test con il classificatore addestrato
y_predict = tree_3_leaf.predict(X_test)
# Stampare l'accuratezza e il report di classificazione sui dati di test
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
# Visualizzare la matrice di confusione sui dati di test
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(tree_3_leaf, X_test, y_test, cmap ='cividis', ax=ax)Ecco l’output.

Dall’output è evidente che il nostro Albero Decisionale funziona bene, soprattutto tenendo conto del fatto che lo abbiamo limitato a tre foglie. Uno dei vantaggi di avere un classificatore semplice è che l’albero decisionale può essere visualizzato e comprensibile.
Ora, per capire come l’albero decisionale prende decisioni, visualizziamo il classificatore ad albero decisionale utilizzando il metodo plot_tree di sklearn.tree.
Ecco il codice.
fig, ax = plt.subplots(figsize=(12, 9))
plot_tree(tree_3_leaf, ax= ax)
plt.show()Ecco l’output.
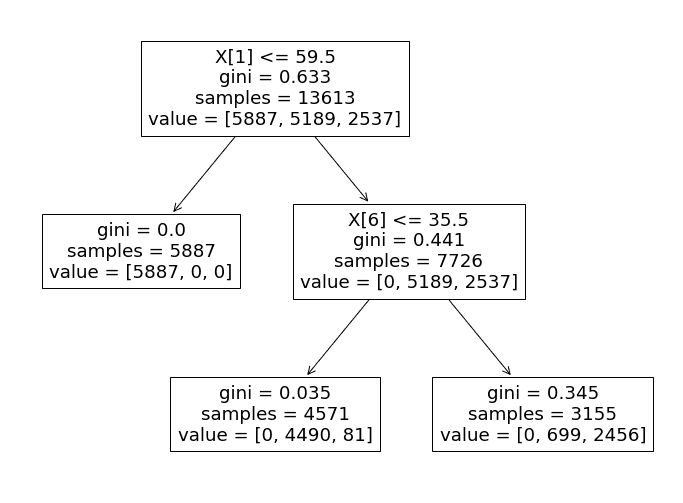
Ora analizziamo questo albero decisionale e scopriamo come effettua il processo decisionale.
In particolare, l’algoritmo utilizza la caratteristica ‘tomatometer_rating’ come determinante primario della classificazione di ciascun punto dei dati di test.
- Se ‘tomatometer_rating’ è inferiore o uguale a 59,5, il punto dei dati viene assegnato un’etichetta 0 (‘Rotten’). Altrimenti, il classificatore passa al ramo successivo.
- Nel secondo ramo, il classificatore utilizza la caratteristica ‘tomatometer_fresh_critics_count’ per classificare i restanti punti dei dati.
- Se il valore di questa caratteristica è inferiore o uguale a 35,5, il punto dei dati viene etichettato come 1 (‘Fresh’).
- Altrimenti, viene etichettato come 2 (‘Certified-Fresh’).
Questo processo decisionale si allinea strettamente alle regole e ai criteri che Rotten Tomatoes utilizza per assegnare lo stato dei film.
Secondo il sito web di Rotten Tomatoes, i film vengono classificati come
- ‘Fresh’ se il loro tomatometer_rating è pari o superiore al 60%.
- ‘Rotten’ se è inferiore al 60%.
Il nostro Classificatore ad Albero Decisionale segue una logica simile, classificando i film come ‘Rotten’ se il loro tomatometer_rating è inferiore a 59,5 e ‘Fresh’ altrimenti.
Tuttavia, quando si distingue tra film ‘Fresh’ e ‘Certified-Fresh’, il classificatore deve considerare diverse altre caratteristiche.
Secondo Rotten Tomatoes, i film devono soddisfare specifici criteri per essere classificati come ‘Certified-Fresh’, come ad esempio:
- Avere un punteggio di Tomatometer coerente di almeno il 75%
- Almeno cinque recensioni da parte dei migliori critici.
- Un minimo di 80 recensioni per i film distribuiti su larga scala.
Il nostro modello a albero decisionale limitato tiene conto solo del numero di recensioni da parte dei migliori critici per differenziare tra film “Fresh” e “Certified-Fresh”.
Ora, comprendiamo la logica dietro l’albero decisionale. Quindi, per aumentare le sue prestazioni, seguiamo gli stessi passaggi ma questa volta non aggiungeremo l’argomento max-leaf nodes.
Ecco la spiegazione passo-passo del nostro codice. Questa volta non espanderò troppo il codice come abbiamo fatto prima.
Definisci il classificatore ad albero decisionale.
tree = DecisionTreeClassifier(random_state=2)Allena il classificatore sui dati di addestramento.
tree.fit(X_train, y_train)Predici i dati di test con un classificatore ad albero addestrato.
y_predict = tree.predict(X_test)Stampa l’accuratezza e il rapporto di classificazione.
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))Traccia la matrice di confusione.
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(tree, X_test, y_test, cmap ='cividis', ax=ax)Ottimo, ora vediamoli insieme.
Ecco tutto il codice.
fig, ax = plt.subplots(figsize=(12, 9))
# Istanza del classificatore ad albero decisionale con impostazioni iperparametriche predefinite
tree = DecisionTreeClassifier(random_state=2)
# Allena il classificatore sui dati di addestramento
tree.fit(X_train, y_train)
# Predici i dati di test con il classificatore ad albero addestrato
y_predict = tree.predict(X_test)
# Stampa l'accuratezza e il rapporto di classificazione sui dati di test
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
# Traccia la matrice di confusione sui dati di test
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(tree, X_test, y_test, cmap ='cividis', ax=ax)Ecco l’output.
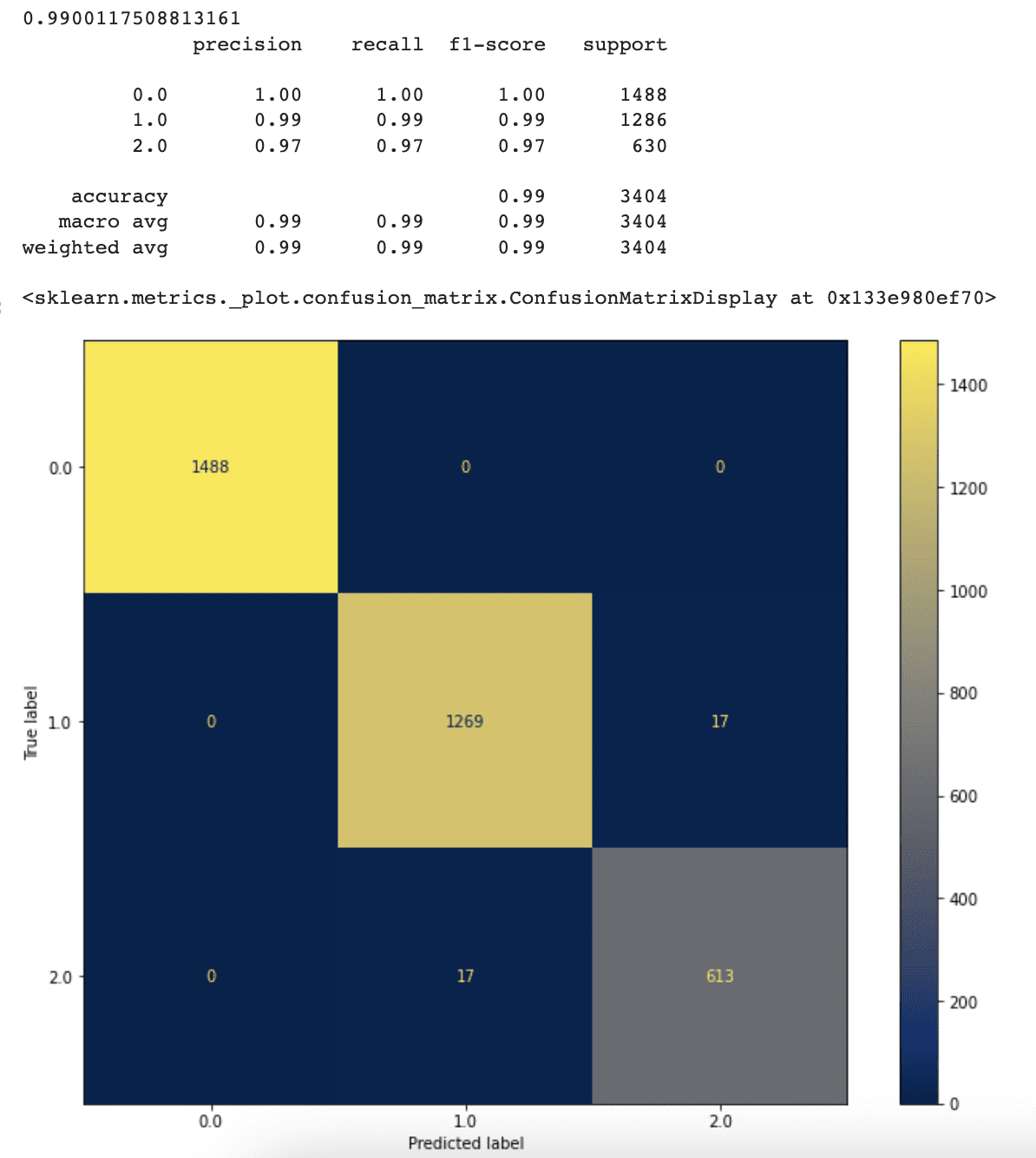
L’accuratezza, la precisione e il recall del nostro classificatore sono aumentati a seguito della rimozione del limite massimo di nodi foglia. Il classificatore raggiunge ora un’accuratezza del 99%, rispetto al 94% precedente.
Ciò dimostra che quando permettiamo al nostro classificatore di scegliere il numero ottimale di nodi foglia da solo, ottiene prestazioni migliori.
Anche se il risultato attuale sembra eccezionale, è ancora possibile effettuare ulteriori regolazioni per raggiungere un’accuratezza ancora migliore. Nella prossima parte, esamineremo questa opzione.
Classificatore Random Forest
Random Forest è un insieme di classificatori ad albero decisionale che sono stati combinati in un singolo algoritmo. Utilizza una strategia di bagging per addestrare ciascun albero decisionale, che include la selezione casuale di punti dati di addestramento. A causa di questa tecnica, ogni albero viene addestrato su un sottoinsieme separato dei dati di addestramento.
Il metodo di bagging è diventato noto per l’utilizzo di una metodologia di bootstrap per campionare i punti dati, consentendo lo stesso punto dati di essere selezionato per diversi alberi decisionali.
 Immagine di autore
Immagine di autore
È davvero facile applicare un classificatore Random Forest usando scikit-learn.
Utilizzare Scikit-learn per configurare l’algoritmo Random Forest è un processo semplice.
Le prestazioni dell’algoritmo, come quelle del classificatore ad albero decisionale, possono essere migliorate modificando i valori degli iperparametri come il numero di classificatori ad albero decisionale, i nodi foglia massimi e la profondità massima dell’albero.
Inizieremo utilizzando le opzioni predefinite qui.
Vediamo nuovamente il codice passo-passo.
Prima di tutto, istanzia un oggetto Random Forest Classifier utilizzando la funzione RandomForestClassifier() della libreria scikit-learn, con un parametro random_state impostato su 2 per la riproducibilità.
rf = RandomForestClassifier(random_state=2)Quindi, addestra il classificatore Random Forest sui dati di addestramento (X_train e y_train), utilizzando il metodo .fit().
rf.fit(X_train, y_train)Successivamente, utilizza il classificatore addestrato per effettuare previsioni sui dati di test (X_test), utilizzando il metodo .predict().
y_predict = rf.predict(X_test)Successivamente, stampa il punteggio di accuratezza e il report di classificazione dei valori predetti rispetto ai valori target effettivi dei dati di test.
Utilizziamo nuovamente le funzioni accuracy_score() e classification_report() della libreria scikit-learn.
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))Infine, visualizziamo una matrice di confusione per visualizzare le prestazioni del classificatore Random Forest sui dati di test. Utilizziamo la funzione plot_confusion_matrix() della libreria scikit-learn.
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, X_test, y_test, cmap ='cividis', ax=ax)Ecco il codice completo.
# Istanzia il classificatore Random Forest
rf = RandomForestClassifier(random_state=2)
# Addestra il classificatore Random Forest sui dati di addestramento
rf.fit(X_train, y_train)
# Predici i dati di test con il modello addestrato
y_predict = rf.predict(X_test)
# Stampa il punteggio di accuratezza e il report di classificazione
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
# Visualizza la matrice di confusione
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, X_test, y_test, cmap ='cividis', ax=ax)Ecco l’output. 
I risultati di accuratezza e matrice di confusione mostrano che l’algoritmo Random Forest è migliore rispetto al classificatore Decision Tree. Ciò dimostra il vantaggio delle tecniche ensemble come Random Forest rispetto agli algoritmi di classificazione individuali.
Inoltre, i metodi di apprendimento automatico basati su alberi ci consentono di identificare l’importanza di ciascuna caratteristica una volta che il modello è stato addestrato. Per questo motivo, Scikit-learn fornisce la funzione feature_importances_.
Perfetto, vediamo ancora una volta il codice passo dopo passo per comprenderlo.
Prima di tutto, l’attributo feature_importances_ dell’oggetto Random Forest Classifier viene utilizzato per ottenere il punteggio di importanza di ciascuna caratteristica nel dataset.
Il punteggio di importanza indica quanto ciascuna caratteristica contribuisce alle prestazioni di previsione del modello.
# Ottieni l'importanza delle caratteristiche
feature_importance = rf.feature_importances_Successivamente, le importanze delle caratteristiche vengono stampate in ordine decrescente di importanza, insieme ai rispettivi nomi delle caratteristiche.
# Stampa l'importanza delle caratteristiche
for i, feature in enumerate(X_train.columns):
print(f'{feature} = {feature_importance[i]}')Quindi, per visualizzare le caratteristiche dall’importanza maggiore a quella minore, utilizziamo il metodo argsort() di numpy.
# Visualizza le caratteristiche dall'importanza maggiore a quella minore
indices = np.argsort(feature_importance)Infine, viene creata un grafico a barre orizzontale per visualizzare le importanze delle caratteristiche, con le caratteristiche classificate dall’importanza maggiore a quella minore sull’asse y e i punteggi di importanza corrispondenti sull’asse x.
Questo grafico ci consente di identificare facilmente le caratteristiche più importanti nel dataset e di determinare quali caratteristiche hanno il maggior impatto sulle prestazioni del modello.
plt.figure(figsize=(12,9))
plt.title('Importanza delle caratteristiche')
plt.barh(range(len(indices)), feature_importance[indices], color='b', align='center')
plt.yticks(range(len(indices)), [X_train.columns[i] for i in indices])
plt.xlabel('Importanza Relativa')
plt.show()Ecco il codice completo.
# Ottieni l'importanza delle caratteristiche
feature_importance = rf.feature_importances_
# Stampa l'importanza delle caratteristiche
for i, feature in enumerate(X_train.columns):
print(f'{feature} = {feature_importance[i]}')
# Visualizza le caratteristiche dall'importanza maggiore a quella minore
indices = np.argsort(feature_importance)
plt.figure(figsize=(12,9))
plt.title('Importanza delle caratteristiche')
plt.barh(range(len(indices)), feature_importance[indices], color='b', align='center')
plt.yticks(range(len(indices)), [X_train.columns[i] for i in indices])
plt.xlabel('Importanza Relativa')
plt.show()Ecco l’output.
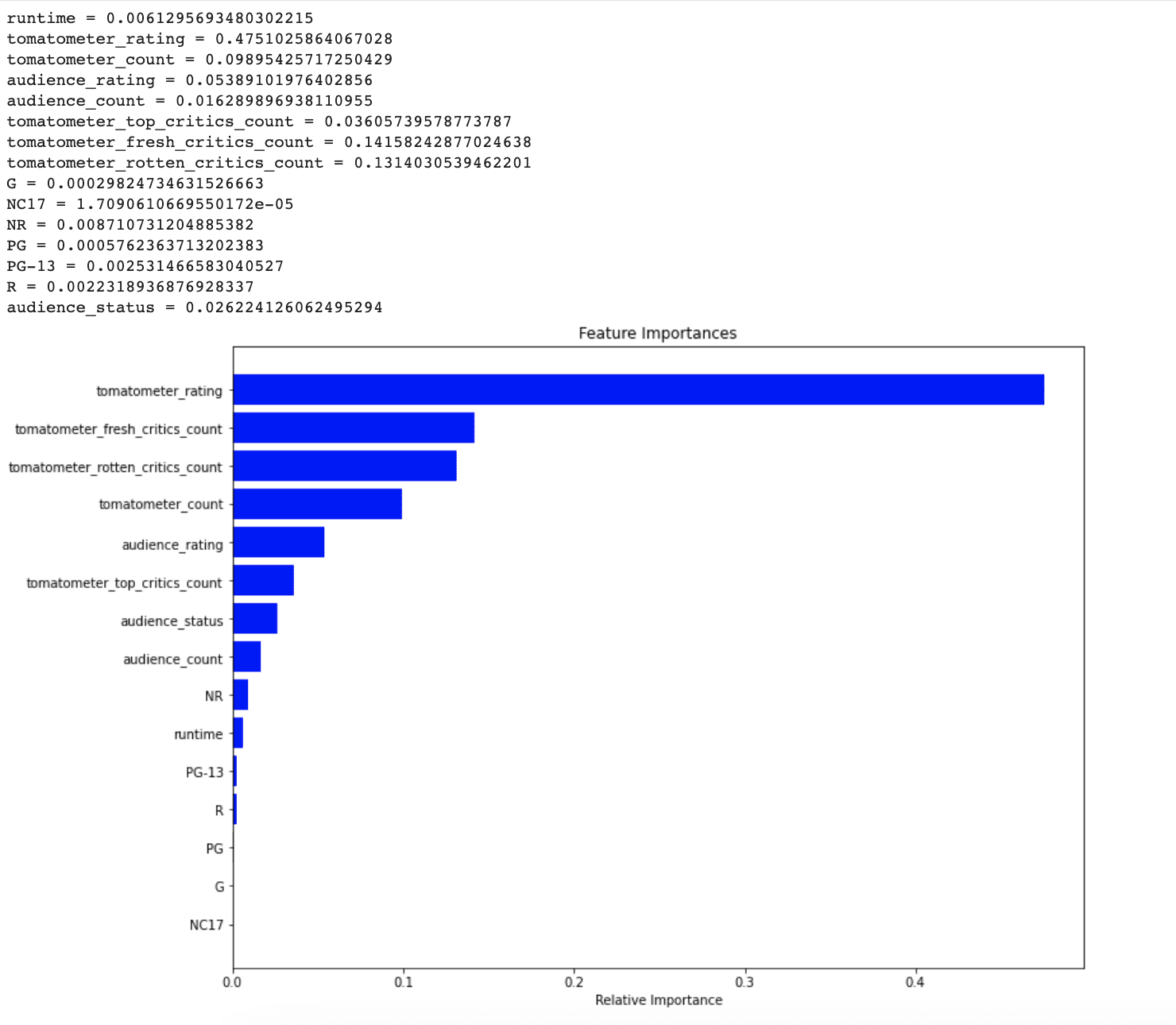
Analizzando questo grafico, è chiaro che NR, PG-13, R e runtime non sono considerati importanti dal modello per prevedere i punti dati non visti. Nella prossima sezione, vedremo se affrontando questa problematica possiamo aumentare le prestazioni del nostro modello o meno.
Random Forest Classifier con Selezione delle Caratteristiche
Ecco il codice.
Nella sezione precedente, abbiamo scoperto che alcune delle nostre caratteristiche sono considerate meno significative dal nostro modello Random Forest, nel fare previsioni.
Di conseguenza, per migliorare le prestazioni del modello, escludiamo queste caratteristiche meno rilevanti, tra cui NR, runtime, PG-13, R, PG, G e NC17.
Nel codice seguente, otteniamo prima l’importanza delle caratteristiche, poi dividiamo i dati in set di addestramento e di test, ma all’interno del blocco di codice eliminiamo queste caratteristiche meno significative. Quindi stampiamo le dimensioni dei set di addestramento e di test.
Ecco il codice.
# Ottieni l'importanza delle caratteristiche
feature_importance = rf.feature_importances_
X_train, X_test, y_train, y_test = train_test_split(df_feature.drop(['tomatometer_status', 'NR', 'runtime', 'PG-13', 'R', 'PG','G', 'NC17'], axis=1),df_feature.tomatometer_status, test_size= 0.2, random_state=42)
print(f'La dimensione dei dati di addestramento è {len(X_train)} e la dimensione dei dati di test è {len(X_test)}')Ecco l’output.
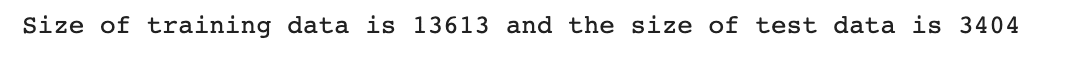
Perfetto, dato che abbiamo eliminato queste caratteristiche meno significative, vediamo se le nostre prestazioni sono migliorate o meno.
Poiché abbiamo fatto ciò troppe volte, spiegherò rapidamente i seguenti codici.
Nel codice seguente, inizializziamo prima un classificatore Random Forest e poi addestriamo il Random Forest sui dati di addestramento.
rf = RandomForestClassifier(random_state=2)
rf.fit(X_train, y_train)Quindi calcoliamo l’accuratezza e il report di classificazione utilizzando i dati di test e li stampiamo.
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))Infine, visualizziamo la matrice di confusione.
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, X_test, y_test, cmap ='cividis', ax=ax)Ecco l’intero codice.
# Inizializza la classe Random Forest
rf = RandomForestClassifier(random_state=2)
# Addestra il Random Forest sui dati di addestramento dopo la selezione delle caratteristiche
rf.fit(X_train, y_train)
# Prevedi il modello addestrato sui dati di test dopo la selezione delle caratteristiche
y_predict = rf.predict(X_test)
# Stampa l'accuratezza e il report di classificazione
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
# Visualizza la matrice di confusione
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, X_test, y_test, cmap ='cividis', ax=ax)Ecco l’output.
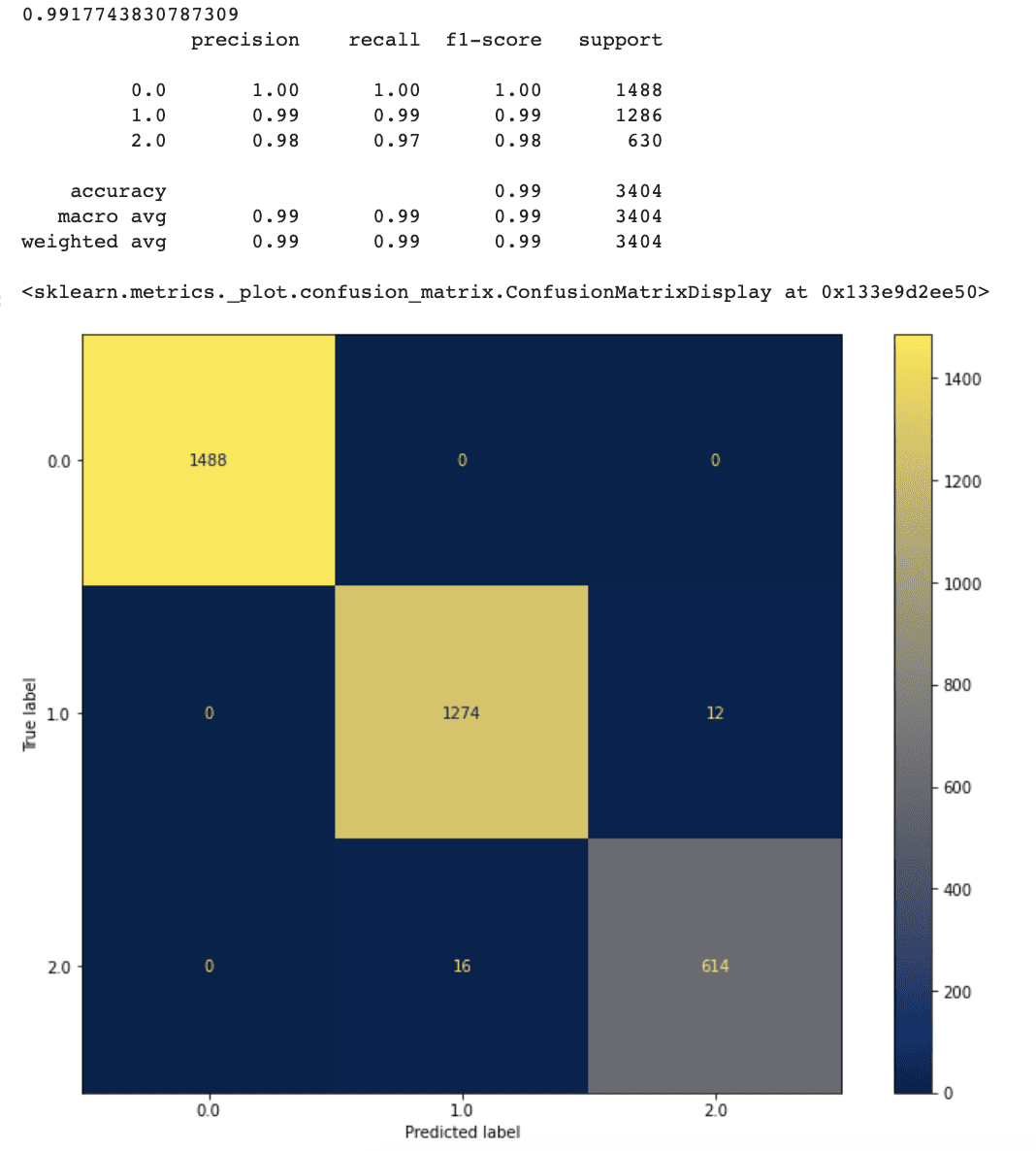
Sembra che il nostro nuovo approccio funzioni molto bene.
Dopo aver effettuato la selezione delle caratteristiche, l’accuratezza è aumentata al 99,1%.
I tassi di falsi positivi e falsi negativi del nostro modello sono anche leggermente diminuiti rispetto al modello precedente.
Ciò indica che avere più caratteristiche non implica sempre un modello migliore. Alcune caratteristiche insignificanti possono creare rumore, che potrebbe essere la ragione della diminuzione dell’accuratezza delle previsioni del modello.
Ora che le prestazioni del nostro modello sono migliorate fino a questo punto, scopriamo altri metodi per verificare se possiamo aumentarle ulteriormente.
Random Forest Classifier Ponderato con Selezione delle Caratteristiche
Nella prima sezione, ci siamo resi conto che le nostre caratteristiche erano leggermente sbilanciate. Abbiamo tre valori diversi, ‘Rotten’ (rappresentato da 0), ‘Fresh’ (rappresentato da 1) e ‘Certified-Fresh’ (rappresentato da 2).
Prima di tutto, vediamo la distribuzione delle nostre caratteristiche.
Ecco il codice per visualizzare la distribuzione delle etichette.
ax = df_feature.tomatometer_status.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])Ecco l’output.
È evidente che la quantità di dati con la funzionalità ‘Certified Fresh’ è molto inferiore rispetto agli altri.
Per risolvere il problema dello sbilanciamento dei dati, possiamo utilizzare approcci come l’algoritmo SMOTE per sovracampionare la classe minoritaria o fornire informazioni sul peso delle classi al modello durante la fase di addestramento.
Qui utilizzeremo il secondo approccio.
Per calcolare il peso delle classi, utilizzeremo la funzione compute_class_weight() della libreria scikit-learn.
All’interno di questa funzione, il parametro class_weight è impostato su ‘balanced’ per tenere conto delle classi sbilanciate, e il parametro classes è impostato sui valori unici della colonna tomatometer_status di df_feature.
Il parametro y è impostato sui valori della colonna tomatometer_status in df_feature.
class_weight = compute_class_weight(class_weight= 'balanced', classes= np.unique(df_feature.tomatometer_status),
y = df_feature.tomatometer_status.values)Successivamente, viene creato un dizionario per associare i pesi delle classi ai rispettivi indici.
Ciò viene fatto convertendo la lista dei pesi delle classi in un dizionario utilizzando la funzione dict() e la funzione zip().
La funzione range() viene utilizzata per generare una sequenza di interi corrispondenti alla lunghezza della lista dei pesi delle classi, che viene quindi utilizzata come chiavi per il dizionario.
class_weight_dict = dict(zip(range(len(class_weight.tolist())), class_weight.tolist()Infine, vediamo il nostro dizionario.
class_weight_dictEcco l’intero codice.
class_weight = compute_class_weight(class_weight= 'balanced', classes= np.unique(df_feature.tomatometer_status),
y = df_feature.tomatometer_status.values)
class_weight_dict = dict(zip(range(len(class_weight.tolist())), class_weight.tolist()))
class_weight_dictEcco l’output.
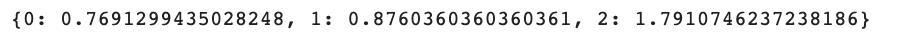
La classe 0 (‘Rotten’) ha il peso più basso, mentre la classe 2 (‘Certified-Fresh’) ha il peso più alto.
Quando applichiamo il nostro classificatore Random Forest, possiamo ora includere queste informazioni sul peso come argomento.
Il codice rimanente è lo stesso di quanto fatto in precedenza molte volte.
Costruiamo un nuovo modello Random Forest con i dati sul peso delle classi, lo addestriamo sul set di addestramento, prevediamo i dati di test e mostriamo il punteggio di accuratezza e la matrice di confusione.
Ecco il codice.
# Inizializza il modello Random Forest con le informazioni sul peso
rf_weighted = RandomForestClassifier(random_state=2, class_weight=class_weight_dict)
# Addestra il modello sui dati di addestramento
rf_weighted.fit(X_train, y_train)
# Prevedi i dati di test con il modello addestrato
y_predict = rf_weighted.predict(X_test)
# Stampa il punteggio di accuratezza e la relazione di classificazione
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
# Disegna la matrice di confusione
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf_weighted, X_test, y_test, cmap ='cividis', ax=ax)Ecco l’output.

Le prestazioni del nostro modello sono migliorate quando abbiamo aggiunto i pesi delle classi, e ora ha un’accuratezza del 99,2%.
Il numero di previsioni corrette per l’etichetta “Fresh” è aumentato di uno.
L’utilizzo dei pesi delle classi per affrontare il problema dello sbilanciamento dei dati è un metodo utile in quanto incoraggia il nostro modello a prestare maggiore attenzione alle etichette con pesi più alti durante la fase di addestramento.
Link a questo progetto di data science: https://platform.stratascratch.com/data-projects/rotten-tomatoes-movies-rating-prediction
Nate Rosidi è un data scientist e si occupa di strategie di prodotto. È anche professore a contratto di analisi e fondatore di StrataScratch, una piattaforma che aiuta i data scientist a prepararsi per i colloqui con domande di intervista reali provenienti dalle migliori aziende. Seguilo su Twitter: StrataScratch o LinkedIn.