AI responsabile presso Google Research AI per il bene sociale
'AI responsabile at Google Research AI for social good.'
Pubblicato da Jimmy Tobin e Katrin Tomanek, Ingegneri del Software, Google Research, AI for Social Good
Il team AI for Social Good di Google è composto da ricercatori, ingegneri, volontari e altri con uno scopo comune di impatto sociale positivo. La nostra missione è dimostrare il beneficio sociale dell’IA consentendo un valore reale nel mondo reale, con progetti che spaziano dal lavoro sulla salute pubblica, l’accessibilità, la risposta alle crisi, il clima e l’energia, e la natura e la società. Crediamo che il modo migliore per guidare un cambiamento positivo nelle comunità svantaggiate sia quello di collaborare con i fautori del cambiamento e le organizzazioni che servono.
In questo post sul blog discutiamo del lavoro svolto dal Progetto Euphonia, un team all’interno di AI for Social Good, che mira a migliorare il riconoscimento automatico della lingua parlata (ASR) per le persone con disturbi del linguaggio. Per le persone con linguaggio tipico, il tasso di errore delle parole (WER) di un modello ASR può essere inferiore al 10%. Ma per le persone con pattern di linguaggio disordinato, come balbuzie, disartria e aprassia, il WER potrebbe raggiungere il 50% o addirittura il 90% a seconda dell’eziologia e della gravità. Per contribuire a risolvere questo problema, abbiamo lavorato con più di 1.000 partecipanti per raccogliere oltre 1.000 ore di campioni di linguaggio disordinato e abbiamo utilizzato i dati per dimostrare che la personalizzazione ASR è una via praticabile per colmare il divario delle prestazioni per gli utenti con linguaggio disordinato. Abbiamo dimostrato che la personalizzazione può avere successo con appena 3-4 minuti di formazione del linguaggio utilizzando tecniche di congelamento del livello.
Questo lavoro ha portato alla sviluppo del Progetto Relate per chiunque abbia un linguaggio atipico che potrebbe beneficiare di un modello di linguaggio personalizzato. Costruito in collaborazione con il team Speech di Google, il Progetto Relate consente alle persone che trovano difficile essere comprese dalle altre persone e dalla tecnologia di addestrare i propri modelli. Le persone possono utilizzare questi modelli personalizzati per comunicare in modo più efficace e acquisire maggiore indipendenza. Per rendere ASR più accessibile e utilizzabile, descriviamo come abbiamo ottimizzato il Modello di linguaggio universale di Google (USM) per comprendere meglio il linguaggio disordinato fuori dalla scatola, senza personalizzazione, per l’uso con tecnologie di assistente digitale, app di dettatura e conversazioni.
- Ricercatori di Deepmind Open-Source TAPIR Un Nuovo Modello di AI per Tracciare Qualsiasi Punto (TAP) che Traccia Efficacemente un Punto di Query in una Sequenza Video.
- Amministrazione Biden sceglie il presidente di Google per lo sforzo di ricerca sui chip.
- Progettare auto elettriche è diventato più veloce con l’AI di Toyota.
Affrontare le sfide
Lavorando a stretto contatto con gli utenti del Progetto Relate, è diventato chiaro che i modelli personalizzati possono essere molto utili, ma per molti utenti, registrare decine o centinaia di esempi può essere difficile. Inoltre, i modelli personalizzati non sempre si comportavano bene in una conversazione informale.
Per affrontare queste sfide, gli sforzi di ricerca di Euphonia si sono concentrati sul riconoscimento automatico della lingua parlata indipendente dall’oratore (SI-ASR) per rendere i modelli funzionanti fuori dalla scatola per le persone con linguaggio disordinato in modo che non sia necessario alcun ulteriore addestramento.
Dataset di linguaggio parlato guidato per SI-ASR
Il primo passo per costruire un modello SI-ASR robusto è stato creare divisioni rappresentative del dataset. Abbiamo creato il dataset di linguaggio parlato guidato suddividendo il corpus di Euphonia in porzioni di addestramento, validazione e test, assicurandoci che ogni suddivisione coprisse una gamma di gravità di disabilità del linguaggio e di eziologia sottostante e che nessun altoparlante o frase apparisse in più suddivisioni. La porzione di addestramento consiste in oltre 950.000 enunciati di linguaggio parlato da oltre 1.000 parlanti con linguaggio disordinato. Il set di test contiene circa 5.700 enunciati da oltre 350 parlanti. Gli specialisti del linguaggio-parlato hanno esaminato manualmente tutti i discorsi nel set di test per l’accuratezza della trascrizione e la qualità audio.
Set di test di conversazioni reali
Il linguaggio parlato spontaneo o conversazionale differisce dal linguaggio guidato in diversi modi. Nella conversazione, le persone parlano più velocemente e pronunciano meno. Ripetono parole, riparano parole errate e usano un vocabolario più ampio che è specifico e personale per sé e per la propria comunità. Per migliorare un modello per questo caso d’uso, abbiamo creato il set di test di conversazioni reali per valutare le prestazioni.
Il set di test di conversazioni reali è stato creato con l’aiuto di tester affidabili che si sono registrati mentre parlavano durante le conversazioni. L’audio è stato esaminato, qualsiasi informazione identificabile personalmente (PII) è stata rimossa e poi i dati sono stati trascritti da specialisti del linguaggio-parlato. Il set di test di conversazioni reali contiene oltre 1.500 enunciati da 29 parlanti.
Adattare USM al linguaggio disordinato
Poi abbiamo sintonizzato USM sulla porzione di addestramento dell’insieme di linguaggio parlato guidato di Euphonia per migliorare le sue prestazioni sul linguaggio disordinato. Invece di sintonizzare il modello completo, la nostra sintonizzazione si basava su adattatori residui, un approccio di sintonizzazione efficiente dei parametri che aggiunge strati di bottlenecks sintonizzabili come residui tra i livelli del trasformatore. Solo questi strati sono sintonizzati, mentre il resto dei pesi del modello non viene toccato. Abbiamo dimostrato in precedenza che questo approccio funziona molto bene per adattare i modelli ASR al linguaggio disordinato. Gli adattatori residui sono stati aggiunti solo ai livelli dell’encoder, e la dimensione del bottleneck è stata impostata su 64.
Risultati
Per valutare l’USM adattato, lo abbiamo confrontato con modelli ASR più vecchi utilizzando i due set di test descritti in precedenza. Per ogni test, confrontiamo l’USM adattato con il modello pre-USM più adatto a quel compito: (1) Per una breve conversazione guidata, confrontiamo il modello di produzione ASR di Google ottimizzato per l’ASR a breve termine; (2) per una conversazione reale più lunga, confrontiamo un modello addestrato per l’ASR a lungo termine. Il miglioramento dell’USM rispetto ai modelli pre-USM può essere spiegato dall’aumento di dimensioni relative dell’USM, da 120M a 2B di parametri, e da altri miglioramenti discussi nel post del blog USM.
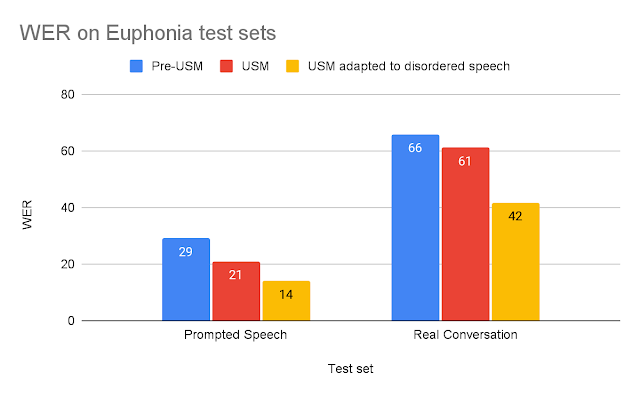 |
| Tassi di errore delle parole del modello (WER) per ogni set di test (più basso è meglio). |
Vediamo che l’USM adattato con discorsi disordinati supera significativamente gli altri modelli. Il WER dell’USM adattato nella conversazione reale è del 37% migliore rispetto al modello pre-USM e nel set di test della conversazione guidata, l’USM adattato funziona il 53% meglio.
Questi risultati suggeriscono che l’USM adattato è significativamente più utilizzabile per un utente finale con discorsi disordinati. Possiamo dimostrare questo miglioramento osservando le trascrizioni delle registrazioni del set di test Real Conversation di un tester affidabile di Euphonia e Project Relate (vedi sotto).
| Audio 1 | Verità fondamentale | Modello ASR pre-USM | USM adattato | |||
| Ora ho un controller adattativo Xbox sulle ginocchia. | ora ho molto e quel consulente sulla bocca | Ora ho avuto un controller Xbox adattatore sul lampione. | ||||
| Ho parlato per un po’ adesso. Vediamo. | abbastanza a lungo adesso | Ho parlato per un po’ adesso. |
| Esempi audio e trascrizioni del discorso di un tester affidabile dal set di test Real Conversation. |
Un confronto tra le trascrizioni del pre-USM e dell’USM adattato ha rivelato alcuni vantaggi chiave:
- Il primo esempio mostra che l’USM adattato è migliore nel riconoscere i modelli di discorso disordinati. La linea base perde parole chiave come “XBox” e “controller” che sono importanti per un ascoltatore per capire ciò che stanno cercando di dire.
- Il secondo esempio è un buon esempio di come le cancellazioni siano un problema primario con i modelli ASR che non sono addestrati con discorsi disordinati. Sebbene il modello di base abbia trascritto una parte correttamente, gran parte dell’enunciato non è stato trascritto, perdendo il messaggio inteso dallo speaker.
Conclusione
Crediamo che questo lavoro rappresenti un passo importante verso l’accessibilità della riconoscimento vocale alle persone con disturbi del linguaggio. Continuiamo a lavorare per migliorare le prestazioni dei nostri modelli. Con i rapidi progressi nella tecnologia di riconoscimento vocale automatico (ASR), ci proponiamo di garantire che anche le persone con disturbi del linguaggio ne traggano beneficio.
Ringraziamenti
I principali contribuenti a questo progetto includono Fadi Biadsy, Michael Brenner, Julie Cattiau, Richard Cave, Amy Chung-Yu Chou, Dotan Emanuel, Jordan Green, Rus Heywood, Pan-Pan Jiang, Anton Kast, Marilyn Ladewig, Bob MacDonald, Philip Nelson, Katie Seaver, Joel Shor, Jimmy Tobin, Katrin Tomanek e Subhashini Venugopalan. Riconosciamo con gratitudine il supporto ricevuto dal Team di ricerca USM, tra cui Yu Zhang, Wei Han, Nanxin Chen e molti altri. In particolare, vorremmo ringraziare i più di 2.200 partecipanti che hanno registrato campioni di voce e le numerose organizzazioni che ci hanno aiutato a metterci in contatto con questi partecipanti.
1 Il volume audio è stato regolato per facilitare l’ascolto, ma i file originali sarebbero più consistenti con quelli utilizzati per l’addestramento e presenterebbero pause, silenzi, volume variabile, ecc. ↩︎






