Ricercatori del Max Plank propongono MIME un modello di intelligenza artificiale generativo che prende la cattura del movimento umano 3D e genera scene 3D plausibili che sono coerenti con il movimento.
Max Plank researchers propose MIME, a generative AI model that takes 3D human motion capture and generates plausible 3D scenes that are consistent with the motion.


Gli esseri umani interagiscono costantemente con l’ambiente che li circonda. Si muovono in uno spazio, toccano oggetti, si siedono su sedie o dormono su letti. Queste interazioni dettagliano come la scena è organizzata e dove si trovano gli oggetti. Un mimo è un artista che utilizza la sua comprensione di tali relazioni per creare un ambiente tridimensionale ricco e immaginativo con nulla più che i movimenti del suo corpo. Potrebbero insegnare a un computer a imitare le azioni umane e creare la scena tridimensionale appropriata? Numerosi campi, tra cui l’architettura, i giochi, la realtà virtuale e la sintesi di dati sintetici, potrebbero trarre vantaggio da questa tecnica. Ad esempio, esistono ampi dataset di movimento umano tridimensionale, come AMASS, ma questi dataset raramente includono dettagli sulla configurazione tridimensionale in cui sono stati raccolti.
Potrebbero creare scenografie tridimensionali credibili per tutti i movimenti utilizzando AMASS? In tal caso, potrebbero creare dati di formazione con interazione umana-scena realistica utilizzando AMASS. Hanno sviluppato una nuova tecnica chiamata MIME (Mining Interaction and Movement to infer 3D Environments), che crea scenari tridimensionali interni credibili basati su movimenti umani tridimensionali per rispondere a tali domande. Cosa lo rende possibile? Le supposizioni fondamentali sono le seguenti: (1) Il movimento umano nello spazio indica l’assenza di oggetti, definendo essenzialmente le aree dell’immagine prive di mobili. Inoltre, questo limita il tipo e la posizione degli oggetti tridimensionali quando si entra in contatto con la scena; ad esempio, una persona seduta deve essere seduta su una sedia, un divano, un letto, ecc.
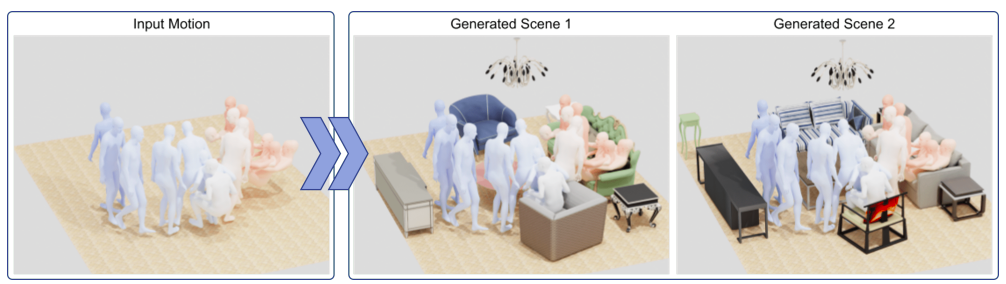
Ricercatori del Max Planck Institute for Intelligent Systems in Germania e di Adobe hanno creato MIME, una tecnica di generazione di scene tridimensionali auto-regressive basata su transformer, per dare una forma tangibile a queste intuizioni. Dato un piano vuoto e una sequenza di movimento umano, MIME prevede il mobilio che entrerà in contatto con l’essere umano. Inoltre, prevede oggetti credibili che non entrano in contatto con le persone ma si inseriscono con gli altri oggetti e rispettano le restrizioni dello spazio libero imposte dai movimenti delle persone. Suddividono il movimento in frammenti di contatto e non di contatto per condizionare la creazione della scena tridimensionale per il movimento umano. Stimano le possibili pose di contatto utilizzando POSA. Le posture non di contatto proiettano i vertici dei piedi sul piano del pavimento per stabilire lo spazio libero della stanza, che registrano come mappe del pavimento 2D.
- I ricercatori di AI di SalesForce presentano OVIS senza maschera un generatore di maschere di segmentazione di istanze a vocabolario aperto.
- Come ringiovanire utilizzando l’AI scoperta una nuova droga anti-invecchiamento.
- Un gruppo di ricercatori cinesi ha sviluppato WebGLM un sistema di domande e risposte potenziato per il web basato sul Modello di Linguaggio Generale (GLM).
I vertici di contatto previsti da POSA creano scatole di delimitazione tridimensionali che riflettono le posture di contatto e i modelli tridimensionali del corpo umano associati. Gli oggetti che soddisfano i criteri di contatto e di spazio libero vengono previsti in modo autoregressivo utilizzando questi dati come input per il transformer; vedi Fig. 1. Hanno ampliato il dataset di scenari sintetici su larga scala 3D-FRONT per creare un nuovo dataset chiamato 3D-FRONT HUMAN per addestrare MIME. Aggiungono automaticamente persone agli scenari 3D, comprese persone non di contatto (una serie di movimenti a piedi e persone in piedi) e persone di contatto (persone sedute, che toccano e che si trovano distese). Per fare ciò, utilizzano pose di contatto statiche da scansioni RenderPeople e sequenze di movimento da AMASS.
MIME crea una disposizione realistica della scena tridimensionale per il movimento in input al momento dell’infrazione, rappresentata come scatole di delimitazione tridimensionali. Sceglie modelli tridimensionali dalla collezione 3D-FUTURE in base a questa disposizione; quindi, affina la loro posizione tridimensionale in base alle restrizioni geometriche tra le posizioni umane e la scena. Il loro metodo produce un insieme tridimensionale che supporta il tocco e il movimento umano mentre posiziona oggetti convincenti in spazi liberi, a differenza dei sistemi di creazione di scene puramente tridimensionali come ATISS. Il loro approccio consente lo sviluppo di oggetti non in contatto con la persona, anticipando la scena completa invece di oggetti individuali, a differenza del modello generativo recente condizionato da Pose2Room. Mostrano che il loro approccio funziona senza alcun adeguamento su sequenze di movimento genuine registrate, come PROX-D.
In conclusione, contribuiscono quanto segue:
• Un nuovo modello generativo condizionato al movimento per scene tridimensionali che crea in modo auto-regressivo oggetti che entrano in contatto con le persone evitando di occupare spazi vuoti definiti dal movimento.
• Un nuovo set di dati di scene tridimensionali composto da persone che interagiscono e persone in spazi liberi è stato creato riempiendo 3D FRONT con dati di movimento da AMASS e pose statiche di contatto/in piedi da RenderPeople.
Il codice è disponibile su GitHub insieme a una demo video. Hanno anche una spiegazione video del loro approccio.






