Abilitare esperienze utente deliziose attraverso modelli predittivi dell’attenzione umana.
Enable delightful user experiences through predictive models of human attention.
Pubblicato da Junfeng He, Senior Research Scientist, e Kai Kohlhoff, Staff Research Scientist, Google Research
Le persone hanno la notevole capacità di assorbire una quantità enorme di informazioni (stimata essere di ~10 10 bit/s che entrano nella retina) e selezionare attentamente alcune regioni rilevanti e interessanti per ulteriori processi (ad esempio, memoria, comprensione, azione). La modellizzazione dell’attenzione umana (il cui risultato è spesso chiamato un modello di salienza) è quindi stata di interesse in diversi campi come neuroscienze, psicologia, interazione uomo-computer (HCI) e visione artificiale. La capacità di prevedere quali regioni sono più probabili di attirare l’attenzione ha numerose applicazioni importanti in aree come grafica, fotografia, compressione e elaborazione delle immagini e la misurazione della qualità visiva.
In precedenza abbiamo discusso della possibilità di accelerare la ricerca sui movimenti oculari utilizzando l’apprendimento automatico e la stima dello sguardo basata su smartphone, che in precedenza richiedeva hardware specializzato costoso fino a $30.000 per unità. La ricerca correlata include “Look to Speak”, che aiuta gli utenti con esigenze di accessibilità (ad esempio, persone con SLA) a comunicare con i loro occhi, e la tecnica recentemente pubblicata “Differentially private heatmaps” per calcolare le mappe di calore, come quelle per l’attenzione, proteggendo la privacy degli utenti.
In questo blog, presentiamo due articoli (uno da CVPR 2022 e uno appena accettato per CVPR 2023) che evidenziano la nostra recente ricerca nell’area della modellizzazione dell’attenzione umana: “Deep Saliency Prior for Reducing Visual Distraction” e “Learning from Unique Perspectives: User-aware Saliency Modeling”, insieme alla recente ricerca sulla compressione delle immagini basata sulla salienza progressiva (1, 2). Mostreremo come i modelli predittivi dell’attenzione umana possano consentire esperienze utente piacevoli come la modifica delle immagini per minimizzare l’ingombro visivo, la distrazione o gli artefatti, la compressione delle immagini per un caricamento più veloce di pagine web o app e la guida dei modelli di apprendimento automatico verso un’interpretazione e una performance del modello più intuitive e simili a quelle umane. Ci concentreremo sulla modifica delle immagini e sulla compressione delle immagini e discuteremo i recenti progressi nella modellizzazione nel contesto di queste applicazioni.
- Generazione di Colonne nella Programmazione Lineare e il Problema del Taglio di Stock
- Rinascimento digitale la ricerca di NVIDIA Neuralangelo ricostruisce scene 3D.
- NYU, NVIDIA collaborano su un grande modello di lingua per prevedere il ricovero del paziente.
Modifica delle immagini guidata dall’attenzione
I modelli di attenzione umana di solito prendono un’immagine in input (ad esempio, un’immagine naturale o uno screenshot di una pagina web) e predicono una mappa di calore in output. La mappa di calore prevista sull’immagine viene valutata rispetto ai dati di attenzione di riferimento, che sono tipicamente raccolti da un tracker oculare o approssimati tramite il movimento del mouse. I modelli precedenti hanno sfruttato le caratteristiche artigianali per indizi visivi, come il contrasto di colore/luminosità, i bordi e la forma, mentre gli approcci più recenti apprendono automaticamente le caratteristiche discriminanti basate su reti neurali profonde, dalle reti neurali convoluzionali e ricorrenti alle reti di trasformatori di visione più recenti.
In “Deep Saliency Prior for Reducing Visual Distraction” (più informazioni su questo sito del progetto), sfruttiamo modelli di salienza profonda per modifiche drammatiche ma visivamente realistiche, che possono cambiare significativamente l’attenzione di un osservatore verso diverse regioni dell’immagine. Ad esempio, la rimozione di oggetti di distrazione sullo sfondo può ridurre l’ingombro nelle foto, portando a un aumento della soddisfazione dell’utente. Allo stesso modo, in videoconferenza, la riduzione dell’ingombro sullo sfondo può aumentare la concentrazione sul relatore principale (esempio demo qui).
Per esplorare che tipi di effetti di modifica possono essere ottenuti e come influiscono sull’attenzione degli spettatori, abbiamo sviluppato un framework di ottimizzazione per guidare l’attenzione visiva nelle immagini utilizzando un modello di salienza predittivo differenziabile. Il nostro metodo utilizza un modello di salienza profonda all’avanguardia. Dato un’immagine di input e una maschera binaria che rappresenta le regioni di distrazione, i pixel all’interno della maschera verranno modificati sotto la guida del modello di salienza predittivo in modo che la salienza all’interno della regione mascherata sia ridotta. Per assicurarci che l’immagine modificata sia naturale e realistica, abbiamo scelto attentamente quattro operatori di modifica dell’immagine: due operazioni di modifica dell’immagine standard, cioè ricolorazione e deformazione dell’immagine (spostamento), e due operatori appresi (non definiamo esplicitamente l’operazione di modifica), cioè un filtro convoluzionale a più strati e un modello generativo (GAN).
Con questi operatori, il nostro framework può produrre una varietà di effetti potenti, con esempi nella figura sottostante, tra cui ricolorazione, inpainting, camuffamento, modifica o inserimento di oggetti e modifica degli attributi facciali. È importante notare che tutti questi effetti sono guidati esclusivamente dal singolo modello di salienza pre-addestrato, senza alcuna supervisione o formazione aggiuntiva. Si noti che il nostro obiettivo non è quello di competere con i metodi dedicati per produrre ogni effetto, ma piuttosto di dimostrare come molteplici operazioni di modifica possano essere guidate dalla conoscenza incorporata nei modelli di salienza profonda.
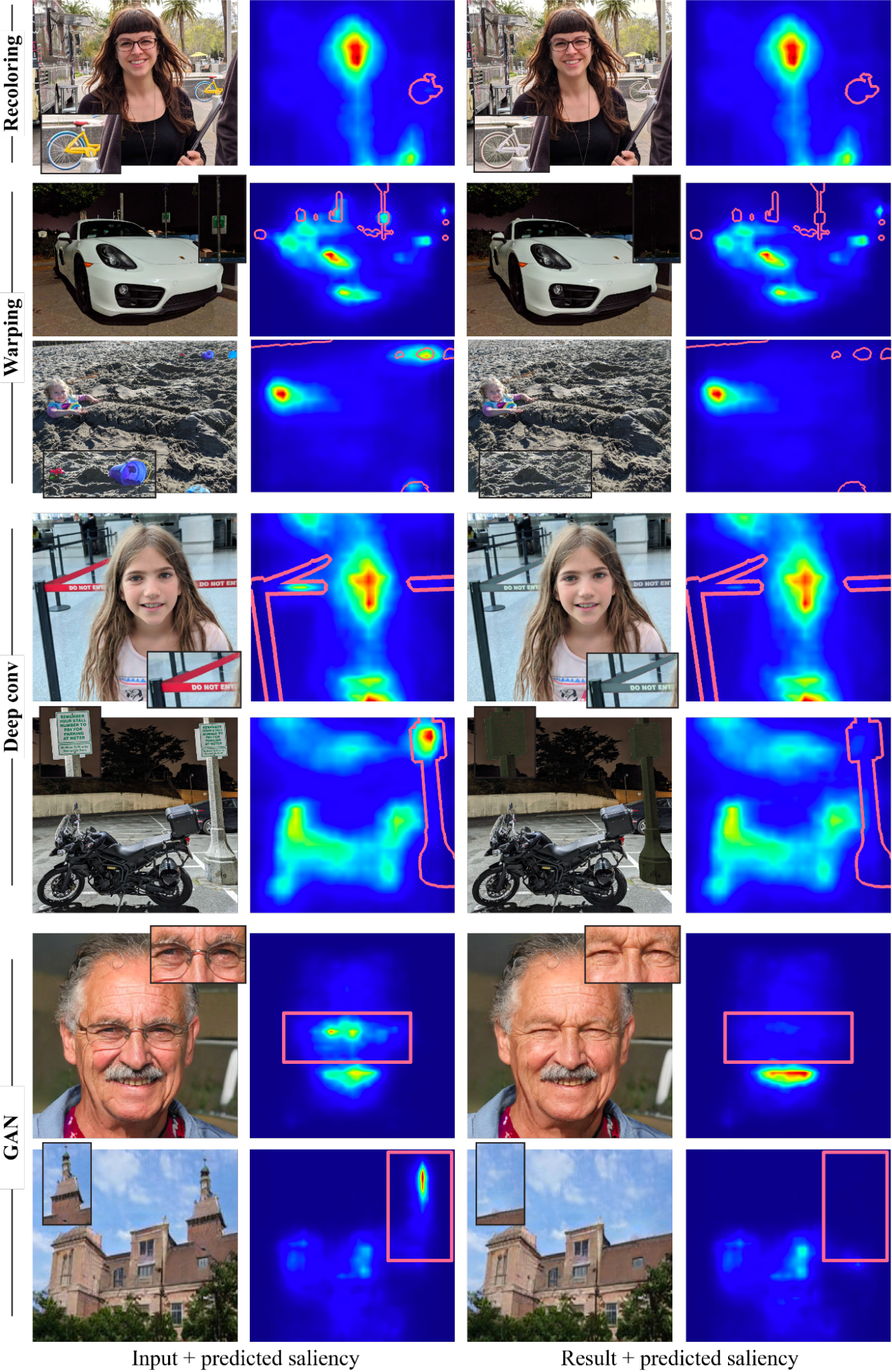 |
| Esempi di riduzione delle distrazioni visive, guidati dal modello di salienza con diversi operatori. La regione di distrazione è segnata sopra la mappa di salienza (bordo rosso) in ogni esempio. |
Arricchire le esperienze con la modellizzazione della salienza consapevole dell’utente
La ricerca precedente assume un singolo modello di salienza per l’intera popolazione. Tuttavia, l’attenzione umana varia tra gli individui – mentre la rilevazione degli indizi salienti è abbastanza coerente, il loro ordine, interpretazione e distribuzione dello sguardo possono differire sostanzialmente. Ciò offre opportunità per creare esperienze personalizzate per singoli o gruppi di utenti. In ” Learning from Unique Perspectives: User-aware Saliency Modeling “, introduciamo un modello di salienza consapevole dell’utente, il primo in grado di prevedere l’attenzione per un utente, un gruppo di utenti e la popolazione generale, con un singolo modello.
Come mostrato nella figura qui sotto, il nucleo del modello è la combinazione delle preferenze visive di ciascun partecipante con una mappa di attenzione per utente e maschere utente adattive. Ciò richiede che le annotazioni di attenzione per utente siano disponibili nei dati di formazione, ad es. il dataset di sguardo mobile OSIE per immagini naturali; dataset FiWI e WebSaliency per pagine web. Invece di prevedere una singola mappa di salienza che rappresenta l’attenzione di tutti gli utenti, questo modello prevede mappe di attenzione per utente per codificare i modelli di attenzione degli individui. Inoltre, il modello adotta una maschera utente (un vettore binario con dimensioni uguali al numero di partecipanti) per indicare la presenza di partecipanti nel campione corrente, il che rende possibile selezionare un gruppo di partecipanti e combinare le loro preferenze in un’unica mappa di calore.
 |
| Panoramica del framework del modello di salienza consapevole dell’utente. L’immagine di esempio proviene dal set di immagini OSIE. |
Durante l’infusione, la maschera utente consente di effettuare previsioni per qualsiasi combinazione di partecipanti. Nella figura seguente, le prime due righe sono previsioni di attenzione per due diversi gruppi di partecipanti (con tre persone in ciascun gruppo) su un’immagine. Un modello di previsione di attenzione convenzionale prevederà mappe di calore di attenzione identiche. Il nostro modello può distinguere i due gruppi (ad esempio, il secondo gruppo presta meno attenzione al volto e più attenzione al cibo rispetto al primo). Allo stesso modo, le ultime due righe sono previsioni su una pagina web per due partecipanti distinti, con il nostro modello che mostra preferenze diverse (ad esempio, il secondo partecipante presta più attenzione alla regione sinistra rispetto al primo).
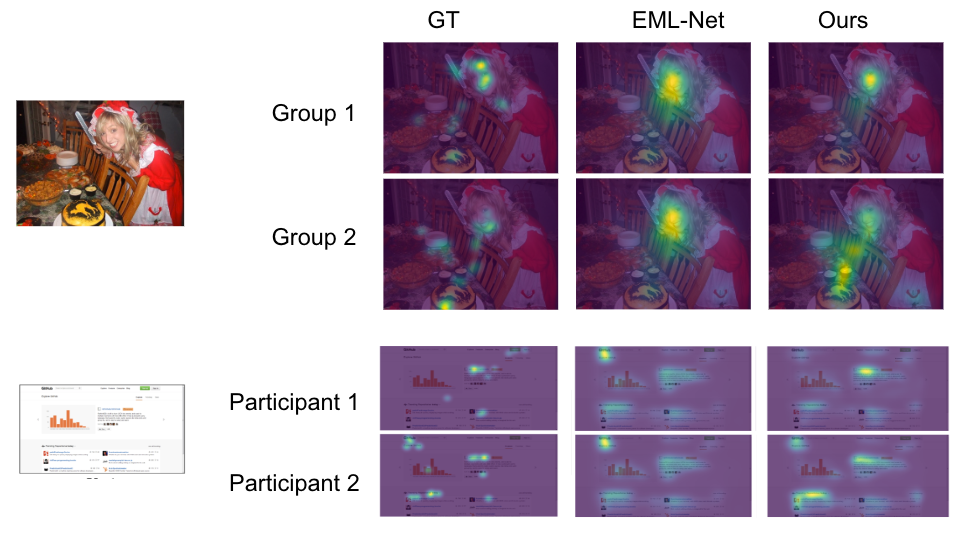 |
| Previsione dell’attenzione rispetto alla verità fondamentale (GT). EML-Net: previsioni da un modello all’avanguardia, che avrà le stesse previsioni per i due partecipanti/gruppi. Il nostro: previsioni dal nostro modello di salienza consapevole dell’utente proposto, che può prevedere correttamente la preferenza unica di ciascun partecipante/gruppo. La prima immagine proviene dal set di immagini OSIE, la seconda da FiWI. |
Decodifica progressiva dell’immagine incentrata sulle caratteristiche salienti
Oltre alla modifica dell’immagine, i modelli di attenzione umana possono anche migliorare l’esperienza di navigazione degli utenti. Una delle esperienze utente più frustranti e fastidiose durante la navigazione è l’attesa delle pagine web con le immagini da caricare, specialmente in condizioni di bassa connettività di rete. Un modo per migliorare l’esperienza dell’utente in tali casi è la decodifica progressiva delle immagini, che decodifica e visualizza sezioni di immagine a risoluzione sempre più elevata man mano che vengono scaricati i dati, fino a quando l’immagine a piena risoluzione non è pronta. La decodifica progressiva di solito procede in ordine sequenziale (ad es. da sinistra a destra, dall’alto in basso). Con un modello di attenzione predittiva ( 1 , 2 ), possiamo invece decodificare le immagini in base alla salienza, rendendo possibile inviare i dati necessari per visualizzare i dettagli delle regioni più salienti per prime. Ad esempio, in un ritratto, i byte per il viso possono essere prioritari rispetto a quelli per lo sfondo fuori fuoco. Di conseguenza, gli utenti percepiscono una migliore qualità dell’immagine inizialmente e hanno tempi di attesa significativamente ridotti. Maggiori dettagli possono essere trovati nei nostri post di blog open source ( post 1 , post 2 ). Pertanto, i modelli di attenzione predittiva possono aiutare con la compressione delle immagini e il caricamento più veloce delle pagine web con le immagini, migliorare il rendering per grandi immagini e applicazioni di streaming/VR.
Conclusione
Abbiamo dimostrato come i modelli predittivi dell’attenzione umana possano consentire esperienze utente piacevoli attraverso applicazioni come l’editing di immagini, che possono ridurre il disordine, le distrazioni o gli artefatti nelle immagini o nelle foto per gli utenti, e la decodifica progressiva delle immagini, che può ridurre notevolmente il tempo di attesa percepito dagli utenti mentre le immagini vengono completamente renderizzate. Il nostro modello di salienza basato sull’utente può personalizzare ulteriormente le applicazioni sopra menzionate per singoli utenti o gruppi, consentendo esperienze più ricche e uniche.
Un’altra direzione interessante per i modelli di attenzione predittiva è quella di capire se possano contribuire a migliorare la robustezza dei modelli di visione artificiale in compiti come la classificazione o la rilevazione degli oggetti. Ad esempio, in “Teacher-generated spatial-attention labels boost robustness and accuracy of contrastive models”, mostriamo che un modello predittivo dell’attenzione umana può guidare i modelli di apprendimento contrastivo per ottenere una rappresentazione migliore e migliorare l’accuratezza/robustezza dei compiti di classificazione (sui dataset ImageNet e ImageNet-C). Ulteriori ricerche in questa direzione potrebbero consentire applicazioni come l’utilizzo dell’attenzione del radiologo su immagini mediche per migliorare lo screening o la diagnosi della salute, o l’utilizzo dell’attenzione umana in scenari di guida complessi per guidare i sistemi di guida autonomi.
Ringraziamenti
Questo lavoro ha coinvolto sforzi collaborativi da parte di un team multidisciplinare di ingegneri del software, ricercatori e contributori cross-funzionali. Vorremmo ringraziare tutti i co-autori degli articoli/ricerche, tra cui Kfir Aberman, Gamaleldin F. Elsayed, Moritz Firsching, Shi Chen, Nachiappan Valliappan, Yushi Yao, Chang Ye, Yossi Gandelsman, Inbar Mosseri, David E. Jacobes, Yael Pritch, Shaolei Shen e Xinyu Ye. Vogliamo anche ringraziare i membri del team Oscar Ramirez, Venky Ramachandran e Tim Fujita per il loro aiuto. Infine, ringraziamo Vidhya Navalpakkam per la sua leadership tecnica nell’avviare e supervisionare questo lavoro.