Esplorare la ricerca sull’uguaglianza di genere con NLP e Elicit
Explore gender equality research with NLP and Elicit.
Introduzione
L’NLP (Elaborazione del Linguaggio Naturale) può aiutarci a comprendere enormi quantità di dati testuali. Invece di dover passare manualmente attraverso un’enorme quantità di documenti e leggerli a mano, possiamo utilizzare queste tecniche per accelerare la nostra comprensione e arrivare rapidamente ai messaggi principali. In questo articolo, approfondiremo la possibilità di utilizzare i data frame di panda e gli strumenti NLP in Python per avere un’idea di ciò che le persone hanno scritto durante la ricerca sull’uguaglianza di genere in Afghanistan utilizzando Elicit. Queste informazioni potrebbero aiutarci a capire cosa ha funzionato e cosa non ha funzionato nel promuovere l’uguaglianza di genere negli ultimi decenni in un paese considerato uno dei luoghi più difficili in cui essere donna o ragazza (World Economic Forum, 2023).
Obiettivo di Apprendimento
- Acquisire competenze nell’analisi del testo per testi in file CSV.
- Acquisire conoscenze su come fare elaborazione del linguaggio naturale in Python.
- Sviluppare competenze nella visualizzazione efficace dei dati per la comunicazione.
- Acquisire informazioni su come la ricerca sull’uguaglianza di genere in Afghanistan si è evoluta nel tempo.
Questo articolo è stato pubblicato come parte del Data Science Blogathon.
Utilizzo di Elicit per le Recensioni Bibliografiche
Per generare i dati di base, utilizzo Elicit, uno strumento basato sull’IA per le Recensioni Bibliografiche (Elicit). Chiedo allo strumento di generare un elenco di articoli correlati alla domanda: Perché l’uguaglianza di genere è fallita in Afghanistan? Successivamente scarico un elenco risultante di articoli (considero un numero casuale di più di 150 articoli) in formato CSV. Come si presenta questo dato? Diamo un’occhiata!
Analisi dei Dati CSV da Elicit in Python
Inizieremo leggendo il file CSV come un dataframe di pandas:
- Questa ricerca sull’intelligenza artificiale conferma che i modelli di lingua di grandi dimensioni basati su trasformatori sono universalmente computazionali quando vengono potenziati con una memoria esterna.
- Ricercatori a Stanford introducono Parsel un framework di Intelligenza Artificiale (IA) che consente l’implementazione automatica e la convalida di algoritmi complessi con grandi modelli di linguaggio (LLM) mediante codice.
- Un nuovo approccio di ricerca sull’Intelligenza Artificiale (IA) presenta l’apprendimento basato su prompt in contesto come un problema di apprendimento algoritmico da una prospettiva statistica.
import pandas as pd
#Identifica il percorso e il file csv
file_path = './elicit.csv'
#Leggi il file CSV
df = pd.read_csv(file_path)
#Forma del CSV
df.shape
#Output: (168, 15)
#Mostra le prime righe del dataframe
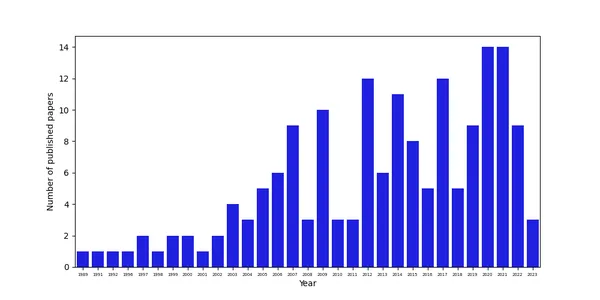
df.head()Il comando df.head() ci mostra le prime righe del dataframe di pandas risultante. Il dataframe è composto da 15 colonne e 168 righe. Generiamo queste informazioni con il comando df.shape. Esploriamo innanzitutto in quale anno sono stati pubblicati la maggior parte di questi studi. Per esplorare ciò, possiamo sfruttare la colonna che riporta l’anno di pubblicazione di ciascun articolo. Esistono vari strumenti per generare grafici in Python, ma affidiamoci qui alle librerie seaborn e matplotlib. Per analizzare in quale anno sono stati pubblicati principalmente gli articoli, possiamo sfruttare un cosiddetto countplot, e personalizzare anche le etichette degli assi e le tacche degli assi per renderlo bello da vedere:
Analisi della Distribuzione Temporale degli Articoli Pubblicati
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
#Imposta la dimensione della figura
plt.figure(figsize=(10,5))
#Genera un countplot
chart = sns.countplot(x=df["Year"], color='blue')
#Imposta le etichette
chart.set_xlabel('Anno')
chart.set_ylabel('Numero di articoli pubblicati')
#Cambia la dimensione delle tacche sull'asse x
# ottieni il testo dell'etichetta
_, xlabels = plt.xticks()
#imposta le etichette sull'asse x
chart.set_xticklabels(xlabels, size=5)
plt.show()I dati mostrano che il numero di articoli è aumentato nel tempo, probabilmente anche a causa di una maggiore disponibilità di dati e migliori possibilità di fare ricerca in Afghanistan dopo che i talebani hanno assunto il potere nel 2001.
Analisi dei Contenuti degli Articoli
Numero di Parole Scritte
Mentre questo ci fornisce una prima panoramica della ricerca condotta sull’uguaglianza di genere in Afghanistan, siamo principalmente interessati a ciò che gli studiosi hanno effettivamente scritto. Per avere un’idea dei contenuti di questi articoli, possiamo sfruttare l’abstract, che Elicit gentilmente ha incluso per noi nel file CSV generato dallo strumento. Per farlo, possiamo seguire procedure standard per l’analisi del testo, come quella descritta da Jan Kirenz in uno dei suoi blogpost. Iniziamo semplicemente contando il numero di parole in ogni abstract utilizzando un metodo lambda:
#Dividi il testo degli abstract in una lista di parole e calcola la lunghezza della lista
df["Numero di Parole"] = df["Abstract"].apply(lambda n: len(n.split()))
#Stampa le prime righe
print(df[["Abstract", "Numero di Parole"]].head())
#Output:
Abstract Numero di Parole
0 Come società tradizionale, l'Afghanistan ha se... 122
1 L'indice di disuguaglianza di genere in Afghan... 203
2 Le pratiche culturali e religiose sono crucial... 142
3 RIASSUNTO L'equità di genere può essere una qu... 193
4 Il crollo del regime talebano negli ultimi anni... 357
#Descrivi la colonna con il numero di parole
df["Numero di Parole"].describe()
count 168.000000
mean 213.654762
std 178.254746
min 15.000000
25% 126.000000
50% 168.000000
75% 230.000000
max 1541.000000Ottimo. La maggior parte degli abstract sembra essere ricca di parole. Hanno in media 213,7 parole. L’abstract minimo consiste solo di 15 parole, mentre l’abstract massimo ha 1.541 parole.
Di cosa scrivono i Ricercatori?
Ora che sappiamo che la maggior parte degli abstract è ricca di informazioni, chiediamoci di cosa principalmente scrivono. Possiamo farlo creando una distribuzione di frequenza per ogni parola scritta. Tuttavia, non siamo interessati a certe parole, come le stopwords. Di conseguenza, dobbiamo eseguire un’elaborazione del testo:
# Prima di tutto, trasforma tutto in minuscolo
df['Abstract_lower'] = df['Abstract'].astype(str).str.lower()
df.head(3)#importa csv
# Tokenizziamo la colonna
from nltk.tokenize import RegexpTokenizer
regexp = RegexpTokenizer('\w+')
df['text_token']=df['Abstract_lower'].apply(regexp.tokenize)
#Mostra le prime righe del nuovo dataset
df.head(3)
# Rimuovi le stopwords
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
# Crea una lista di stopwords in inglese
stopwords = nltk.corpus.stopwords.words("english")
# Aggiungi alla lista le tue stopwords personalizzate
my_stopwords = ['https']
stopwords.extend(my_stopwords)
# Rimuovi le stopwords con una funzione lambda
df['text_token'] = df['text_token'].apply(lambda x: [item for item in x if item not in stopwords])
#Mostra le prime righe del dataframe
df.head(3)
# Rimuovi le parole poco frequenti (parole più corte o uguali a due lettere)
df['text_string'] = df['text_token'].apply(lambda x: ' '.join([item for item in x if len(item)>2]))
#Mostra le prime righe del dataframe
df[['Abstract_lower', 'text_token', 'text_string']].head()Quello che facciamo qui è prima di tutto trasformare tutte le parole in minuscolo, e successivamente tokenizzarle tramite strumenti di elaborazione del linguaggio naturale. La tokenizzazione delle parole è un passaggio cruciale nell’elaborazione del linguaggio naturale e significa suddividere il testo in parole individuali (token). Utilizziamo il RegexpTokenizer e suddividiamo il testo dei nostri abstracts in base alle caratteristiche alfanumeriche (indicate da ‘\w+’). Memorizziamo i token risultanti nella colonna text_token. Rimuoviamo quindi le stopwords da questa lista di token utilizzando il dizionario del toolbox di elaborazione del linguaggio naturale di nltk, la libreria Python NLTK (Natural Language Toolkit). Elimina le parole più corte di due lettere. Questo tipo di elaborazione del testo ci aiuta a concentrare la nostra analisi su termini più significativi.
Genera una Word Cloud
Per analizzare visivamente la lista risultante di parole, generiamo una lista di stringhe dal testo che abbiamo elaborato, suddividiamo questa lista e quindi generiamo una word cloud:
from wordcloud import WordCloud
# Crea una lista di parole
tutte_le_parole = ' '.join([parola for parola in df['text_string']])
# Word Cloud
wordcloud = WordCloud(width=600,
height=400,
random_state=2,
max_font_size=100).generate(tutte_le_parole)
plt.figure(figsize=(10, 7))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off');
La word cloud mostra che le parole menzionate più frequentemente sono quelle che fanno parte anche della nostra query di ricerca: Afghanistan, genere, uguaglianza di genere. Tuttavia, altre parole che sono sinonimi fanno anche parte della lista delle parole più menzionate: donne e uomini. Queste parole di per sé non sono molto informative, ma altre lo sono: nella ricerca sull’uguaglianza di genere in Afghanistan, i ricercatori sembrano essere molto preoccupati dell’istruzione, dei diritti umani, della società e dello stato. Sorprendentemente, il Pakistan fa anche parte della lista. Ciò potrebbe significare che i risultati generati dalla query di ricerca sono imprecisi e includono anche ricerche sull’uguaglianza di genere in Afghanistan, anche se non l’abbiamo chiesto. In alternativa, potrebbe significare che l’uguaglianza di genere delle donne afghane è anche un importante argomento di ricerca in Pakistan, forse a causa del grande numero di afghani che si stabiliscono in Pakistan a causa della difficile situazione nel loro paese d’origine.
Analizza il Sentimento degli Autori
Idealemente, la ricerca dovrebbe essere neutrale e priva di emozioni o opinioni. Tuttavia, è nella nostra natura umana avere opinioni e sentimenti. Per indagare fino a che punto i ricercatori riflettono i loro sentimenti in ciò che scrivono, possiamo fare un’analisi del sentimento. Le analisi del sentimento sono metodi per analizzare se un insieme di testo è positivo, neutrale o negativo. Nel nostro esempio, useremo lo Strumento di Analisi del Sentimento VADER. VADER sta per Valence Aware Dictionary and Sentiment Reasoner ed è un strumento di analisi del sentimento basato su lessico e regole.
Come funziona lo strumento di analisi del sentimento VADER, è che utilizza un lessico di sentimento pre-costruito che consiste in un vasto numero di parole con sentimenti associati. Considera anche le regole grammaticali per rilevare la polarità del sentimento (positivo, neutro e negativo) dei brevi testi. Lo strumento restituisce un punteggio di sentimento (detto anche punteggio composito) basato sul sentimento di ogni parola e sulle regole grammaticali nel testo. Questo punteggio varia da -1 a 1. I valori superiori a zero sono positivi e i valori inferiori a zero sono negativi. Poiché lo strumento si basa su un lessico di sentimento pre-costruito, non richiede modelli di apprendimento automatico complessi o modelli estesi.
# Accesso al lessico richiesto contenente punteggi di sentimento per parole
nltk.download('vader_lexicon')
# Inizializza l'oggetto analizzatore di sentimento
from nltk.sentiment import SentimentIntensityAnalyzer
# Calcola i punteggi di polarità del sentimento con l'analizzatore
analyzer = SentimentIntensityAnalyzer()
# Metodo del punteggio di polarità - Assegna i risultati alla colonna Polarità
df['polarità'] = df['testo_stringa'].apply(lambda x: analyzer.polarity_scores(x))
df.tail(3)
# Cambia la struttura dei dati - Concatena il dataset originale con le nuove colonne
df = pd.concat(
[df,
df['polarità'].apply(pd.Series)], axis=1)
# Mostra la struttura della nuova colonna
df.head(3)
# Calcola il valore medio del punteggio composito
df.composito.mean()
# Output: 0.20964702380952382Il codice sopra genera un punteggio di polarità che varia da -1 a 1 per ogni abstract, qui indicato come punteggio composito. Il valore medio è superiore a zero, quindi la maggior parte delle ricerche ha una connotazione positiva. Come è cambiato nel tempo? Possiamo semplicemente tracciare i sentimenti per anno:
# Lineplot
g = sns.lineplot(x='Anno', y='composito', data=df)
# Regola etichette e titolo
g.set(title='Sentimento dell\'Abstract')
g.set(xlabel="Anno")
g.set(ylabel="Sentimento")
# Aggiungi una linea grigia per indicare lo zero (il punteggio neutro) per dividere i punteggi positivi e negativi
g.axhline(0, ls='--', c = 'grigio')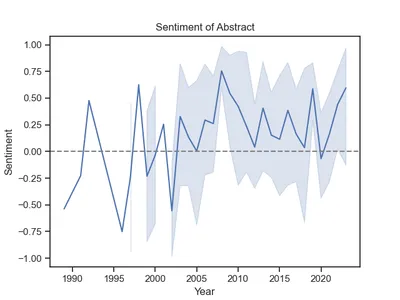
Interessante. La maggior parte delle ricerche era positiva a partire dal 2003. Prima di ciò, i sentimenti fluttuavano in modo più significativo e erano più negativi, in media, probabilmente a causa della difficile situazione delle donne in Afghanistan.
Conclusione
Il Natural Language Processing può aiutarci a generare informazioni preziose su grandi quantità di testo. Quello che abbiamo imparato qui da quasi 170 articoli è che l’educazione e i diritti umani erano gli argomenti più importanti negli articoli di ricerca raccolti da Elicit e che i ricercatori hanno iniziato a scrivere in modo più positivo sull’uguaglianza di genere in Afghanistan a partire dal 2003, poco dopo che i talebani hanno assunto il potere nel 2001.
Punti Chiave
- Possiamo utilizzare gli strumenti di Natural Language Processing per ottenere rapidamente informazioni sui principali argomenti studiati in un determinato campo di ricerca.
- Le nuvole di parole sono ottimi strumenti di visualizzazione per comprendere le parole più comunemente utilizzate in un testo.
- L’analisi del sentimento mostra che la ricerca potrebbe non essere così neutrale come ci si aspetta.
Spero che tu abbia trovato questo articolo informativo. Non esitare a contattarmi su LinkedIn. Connettiamoci e lavoriamo per sfruttare i dati per il bene!
Domande Frequenti
Riferimenti
- World Economic Forum. Global Gender Gap Report 2023.
- Elicit. Link: Perché l’uguaglianza di genere è fallita in Afghanistan | Ricerca | Elicit
- Jan Kirenz. Text Mining and Sentiment Analysis with NLTK and pandas in Python.
- Hutto, C.J. & Gilbert, E.E. (2014). VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. Eighth International Conference on Weblogs and Social Media (ICWSM-14). Ann Arbor, MI, June 2014.
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e vengono utilizzati a discrezione dell’autore.






