Diciamolo una volta sola! Ripetere le parole non aiuta l’AI.
Let's say it once and for all! Repeating words doesn't help AI.
| INTELLIGENZA ARTIFICIALE | ELABORAZIONE DEL LINGUAGGIO NATURALE | LLMs
Come e perché la ripetizione di token danneggia i LLM? Perché questo è un problema?
I Large Language Models (LLM) hanno dimostrato le loro capacità e hanno conquistato il mondo. Ogni grande azienda ora ha un modello con un nome fantasioso. Ma, sotto il cofano, sono tutti transformer. Tutti sognano i trilioni di parametri, ma non c’è nessun limite?
In questo articolo, discutiamo di:
- È garantito che un modello più grande abbia prestazioni migliori di un modello più piccolo?
- Abbiamo i dati per modelli enormi?
- Cosa succede se invece di raccogliere nuovi dati si utilizzano nuovamente i dati?
Scalare verso il cielo: cosa sta danneggiando l’ala?
OpenAI ha definito la legge di scaling, affermando che le prestazioni del modello seguono una legge di potenza in base al numero di parametri utilizzati e al numero di punti dati. Ciò insieme alla ricerca di proprietà emergenti ha creato una corsa ai parametri: più grande è il modello, meglio è.
È vero? I modelli più grandi danno prestazioni migliori?
Recentemente, le proprietà emergenti sono entrate in crisi. Come dimostrano i ricercatori di Stanford, il concetto di proprietà emergente potrebbe non esistere.
Abilità emergenti in AI: stiamo inseguendo un mito?
Cambiare prospettiva sulle proprietà emergenti dei grandi modelli di linguaggio
towardsdatascience.com
La legge di scaling probabilmente assegna molto meno valore al dataset di quanto si pensi. DeepMind ha dimostrato con Chinchilla che non si dovrebbe solo pensare a scalare i parametri ma anche i dati. Infatti, Chinchilla dimostra di essere superiore in capacità a Gopher (70 B vs. 280 B di parametri)
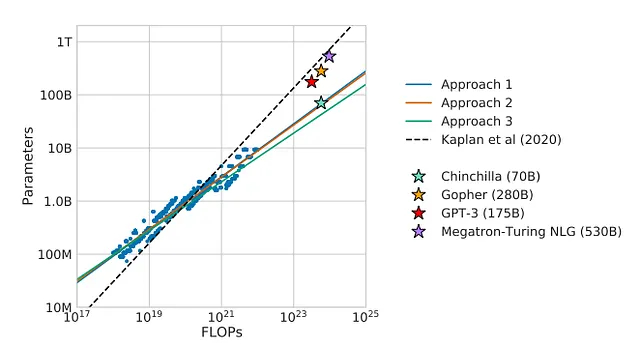
Recentemente, la comunità di machine learning si è entusiasmata per LLaMA non solo perché è open source, ma anche perché la versione di 65 B di parametri ha superato OPT 175 B.
LLaMA di META: un piccolo modello di linguaggio che batte i giganti
Il modello open source di META ci aiuterà a capire come si generano i bias nei LMs
Nisoo.com
Come afferma DeepMind nell’articolo Chinchilla, si può stimare quanti token sono necessari per addestrare completamente un LLM all’avanguardia. D’altra parte, si può anche stimare quanti token di alta qualità esistono. Recenti ricerche si sono chieste di questo argomento. Hanno concluso:
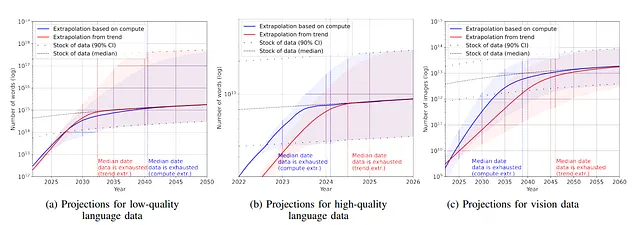
- I dataset di lingua sono cresciuti in modo esponenziale, con una crescita annua del 50% nella pubblicazione dei dataset di lingua (fino a 2e12 parole entro la fine del 2022). Ciò dimostra che la ricerca e la pubblicazione di nuovi dataset di lingua è un campo molto attivo.
- D’altra parte, il numero di parole su Internet (stock di parole) sta crescendo (e gli autori lo stimano tra 7e13 e 7e16 parole, quindi 1,5-4,5 ordini di grandezza).
- Tuttavia, poiché cercano di utilizzare un stock di parole di alta qualità, in realtà gli autori stimano il stock di qualità tra 4,6e12 e 1,7e13 parole. Gli autori affermano che tra il 2023 e il 2027 avremo esaurito il numero di parole di qualità e tra il 2030 e il 2050 l’intero stock.
- Lo stock di immagini non sta molto meglio (tre o quattro ordini di grandezza)
Perché sta accadendo?
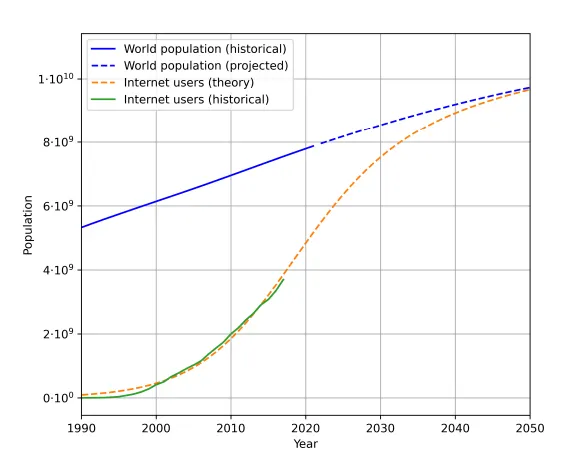
Bene, perché noi umani non siamo infiniti e non produciamo testo quanto ChatGPT. In effetti, le proiezioni del numero di utenti Internet (reali e previsti) parlano da sole:
In realtà, non tutti sono felici riguardo ai testi, al codice e ad altre fonti utilizzate per addestrare i modelli di intelligenza artificiale. Infatti, Wikipedia, Reddit e altre fonti storicamente utilizzate per addestrare i modelli vorrebbero che le aziende pagassero per utilizzare i loro dati. Al contrario, le aziende stanno invocando l’uso equo e al momento il panorama normativo non è chiaro.
Combinando i dati insieme, si può vedere chiaramente una tendenza. Il numero di token necessari per addestrare in modo ottimale un LLM sta crescendo più velocemente dei token disponibili.
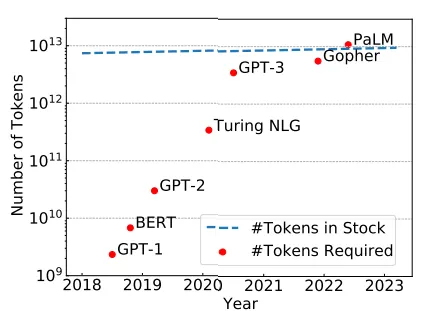
Secondo la legge di scala definita da Chinchilla (numero di token necessari per l’addestramento ottimale di LLM), abbiamo già superato il limite. Dal grafico, possiamo vedere che secondo queste stime con PaLM-540 B, abbiamo raggiunto il limite (10,8 trilioni di token necessari rispetto ai 9 trilioni disponibili).
Alcuni autori hanno chiamato questo problema “crisi dei token”. Inoltre, finora abbiamo considerato solo i token in lingua inglese, ma ci sono altre settemila lingue. Cinquantasei percento di tutto il web è in inglese, mentre il restante 44% appartiene solo a 100 altre lingue. E questo si riflette nelle prestazioni dei modelli in altre lingue.
Possiamo ottenere più dati?
Come abbiamo visto, più parametri non equivalgono a una migliore performance. Per una migliore performance, abbiamo bisogno di token di qualità (testi), ma questi sono in breve fornitura. Come possiamo ottenerli? Possiamo aiutarci con l’intelligenza artificiale?
Perché non usiamo Chat-GPT per produrre testo?
Se noi umani non produciamo abbastanza testo, perché non automatizzare questo processo? Uno studio recente mostra come questo processo non sia ottimale. Stanford Alpaca è stato addestrato utilizzando 52.000 esempi derivati da GPT-3, ma ha ottenuto solo una performance apparentemente simile. In realtà, il modello apprende lo stile del modello target ma non la sua conoscenza.
Perché non addestrare più a lungo?
Sia per PaLM, Gopher e LLaMA (ma anche per gli altri LLM) è chiaramente scritto che i modelli sono stati addestrati per poche epoche (una o comunque poche). Questo non è una limitazione del Transformer perché, ad esempio, i Vision Transformer (ViT) sono stati addestrati per 300 epoche su ImageNet (1 milione di immagini), come mostrato nella tabella:
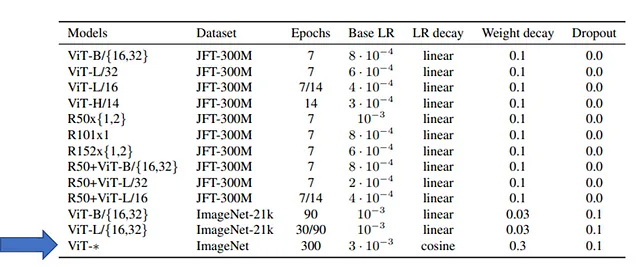
Perché è oltre ogni possibilità economica. Nell’articolo LLaMA, gli autori hanno addestrato solo per una epoca (e due epoche solo per una parte del dataset). Tuttavia, gli autori riportano:
Quando si addestra un modello con 65 miliardi di parametri, il nostro codice elabora circa 380 token/sec/GPU su 2048 GPU A100 con 80GB di RAM. Ciò significa che addestrare il nostro dataset contenente 1,4T di token richiede circa 21 giorni. ( fonte )
Allenare un LLM anche per poche epoche è estremamente costoso. Come calcolato da Dmytro Nikolaiev (Dimid) ciò significa 4,0 milioni di dollari se si allena un modello simile al LLaMA di META sulla piattaforma Google Cloud.
Quindi l’allenamento per altre epoche comporterebbe un aumento esponenziale dei costi. Inoltre, non sappiamo se questo ulteriore allenamento sia davvero utile: non l’abbiamo ancora testato.
Recentemente un gruppo di ricercatori dell’Università di Singapore ha studiato cosa succede se si allena un LLM per molte epoche:
Ripetere o non ripetere: insight dallo scaling di LLM in condizioni di crisi di token
Ricerche recenti hanno evidenziato l’importanza delle dimensioni del dataset nello scaling dei modelli di linguaggio. Tuttavia, il linguaggio…
arxiv.org
Repetita iuvant aut continuata secant
Fino ad ora sappiamo che le prestazioni di un modello derivano non solo dal numero di parametri, ma anche dal numero di token di qualità utilizzati per l’addestramento. D’altra parte, questi token di qualità non sono infiniti e ci stiamo avvicinando al limite. Se non riusciamo a trovare abbastanza token di qualità ed è un’opzione generarli con l’AI, cosa possiamo fare?
Possiamo usare lo stesso set di addestramento e addestrarlo più a lungo?
C’è una locuzione latina che dice che ripetere le cose fa bene (r epetita iuvant), ma nel tempo qualcuno ha aggiunto “ma continuare annoia” (continuata secant).
Lo stesso vale per le reti neurali: aumentare il numero di epoche migliora le prestazioni della rete (riduzione della perdita); ad un certo punto, tuttavia, mentre la perdita nel set di addestramento continua a diminuire, la perdita nel set di validazione inizia ad aumentare. La rete neurale è entrata in overfitting, iniziando a considerare schemi che sono presenti solo nel set di addestramento e perdendo la capacità di generalizzare.
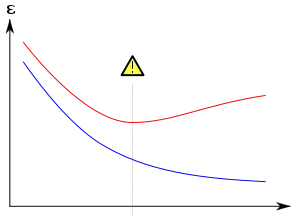
Ok, questo è stato ampiamente studiato per le piccole reti neurali, ma cosa succede per i grandi trasformatori?
Gli autori di questo studio hanno utilizzato il modello T5 (modello encoder-decoder) sul dataset C4. Gli autori hanno addestrato diverse versioni del modello, aumentando il numero di parametri fino a quando il modello più grande ha superato quello più piccolo (indicando che il modello più grande ha ricevuto un numero sufficiente di token, come la legge di Chinchilla). Gli autori hanno notato che c’era una relazione lineare tra il numero di token richiesti e la dimensione del modello (confermando ciò che DeepMind ha visto con Chinchilla).
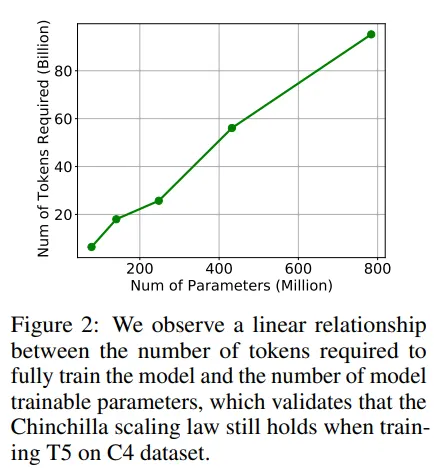
Il dataset C4 è limitato (non ha token infiniti) quindi per aumentare il numero di parametri gli autori si sono trovati in una condizione di scarsità di token. Così hanno deciso di simulare cosa succede se un LLM vede dati ripetuti. Hanno campionato un certo numero di token, quindi il modello si è trovato a vederli di nuovo nell’addestramento dei token. Ciò ha mostrato:
- I token ripetuti portano a una diminuzione delle prestazioni.
- I modelli più grandi sono più suscettibili all’overfitting in condizioni di scarsità di token (quindi anche se teoricamente consumano più risorse computazionali, ciò porta a una diminuzione delle prestazioni).
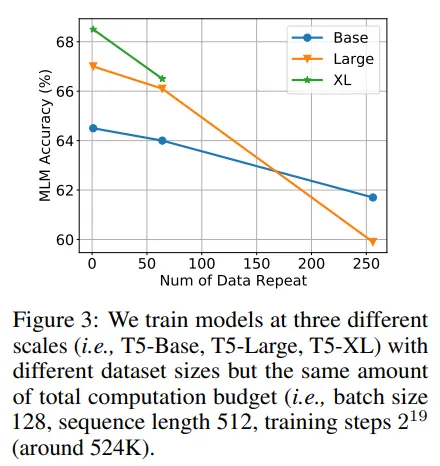
Inoltre, questi modelli sono utilizzati per compiti successivi. Spesso un LLM viene addestrato non supervisionato su una grande quantità di testo e poi viene affinato su un set di dati più piccolo per un compito successivo. Oppure può passare attraverso un processo chiamato allineamento (come nel caso di ChatGPT).
Quando un LLM viene addestrato su dati ripetuti anche se poi viene affinato su un altro set di dati, le prestazioni vengono degradate. Quindi anche i compiti successivi sono influenzati.
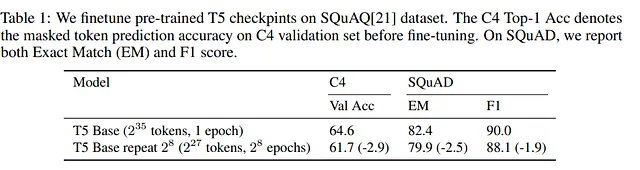
Perché i token ripetuti non sono una buona idea
Abbiamo appena visto che i token ripetuti danneggiano l’addestramento. Ma perché accade questo?
Gli autori hanno deciso di indagare mantenendo il numero di token ripetuti fisso e aumentando il numero totale di token nel set di dati. I risultati mostrano che un set di dati più grande allevia i problemi di degradazione multi-epoca.
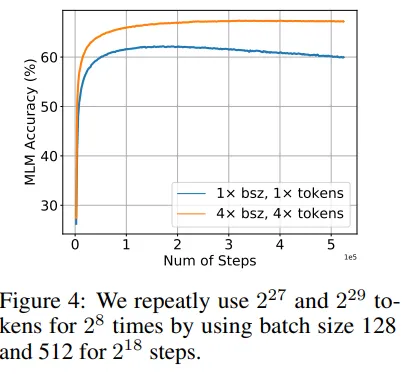
L’anno scorso è stato pubblicato Galactica (un modello che doveva aiutare gli scienziati ma è durato solo tre giorni). A parte il fallimento spettacolare, l’articolo ha suggerito che parte dei loro risultati provenisse dalla qualità dei dati. Secondo gli autori, la qualità dei dati ha ridotto il rischio di overfitting:
Siamo in grado di addestrarci su di esso per molte epoche senza overfitting, dove le prestazioni upstream e downstream migliorano con l’uso di token ripetuti. (fonte)
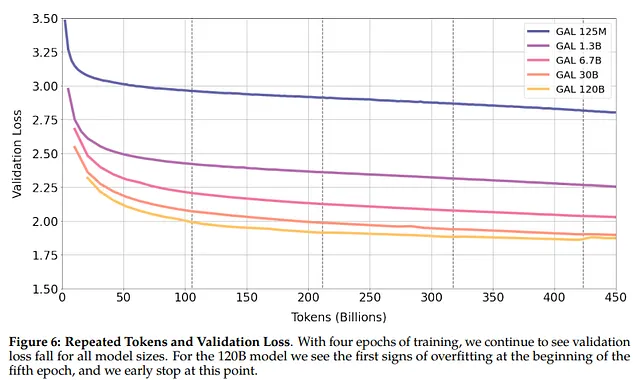
Per gli autori, i token ripetuti non solo non danneggiano l’addestramento del modello, ma migliorano effettivamente le prestazioni dei compiti successivi.
In questo nuovo studio, gli autori utilizzano il dataset di Wikipedia che è considerato un dataset di qualità superiore rispetto a C4, e aggiungono token ripetuti. I risultati mostrano che c’è un livello simile di degradazione, il che va contro quanto affermato nell’articolo di Galactica.

Gli autori hanno anche cercato di indagare se fosse dovuto anche al modello di scaling. Durante lo scaling di un modello, sia il numero di parametri che il costo computazionale aumentano. Gli autori hanno deciso di studiare questi due fattori individualmente:
- Mixture-of-Experts (MoE) perché anche se aumenta il numero di parametri, mantiene un costo computazionale simile.
- ParamShare, d’altra parte, riduce il numero di parametri ma mantiene lo stesso costo computazionale.
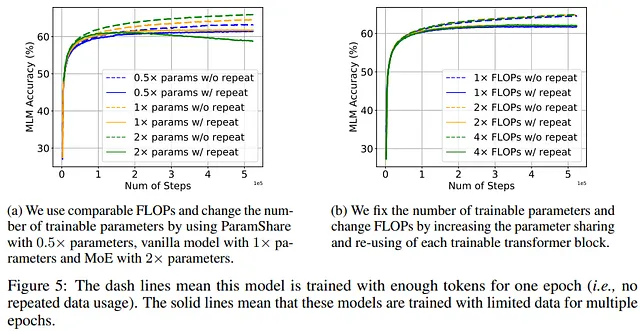
I risultati mostrano che il modello con meno parametri è meno influenzato dai token ripetuti. Al contrario, il modello MoE (maggiore numero di parametri) è più incline all’overfitting. Il risultato è interessante perché MoE è stato utilizzato con successo in molti modelli di intelligenza artificiale, quindi gli autori suggeriscono che, anche se MoE è una tecnica utile quando ci sono abbastanza dati, può danneggiare le prestazioni quando non ci sono abbastanza token.
Gli autori hanno anche esplorato se l’addestramento dell’obiettivo influisse sulla degradazione delle prestazioni. In generale, ci sono due obiettivi di addestramento:
- Next token prediction (dato una sequenza di token prevedi il prossimo nella sequenza).
- Masked language modeling, dove uno o più token sono mascherati e devono essere predetti.
Recentemente, con PaLM2-2, Google ha introdotto UL2 che è una combinazione tra questi due obiettivi di formazione. UL2 ha dimostrato di accelerare la formazione del modello tuttavia, interessantemente, UL2 è più incline all’overfitting e ha una maggiore degradazione multi-epoca.
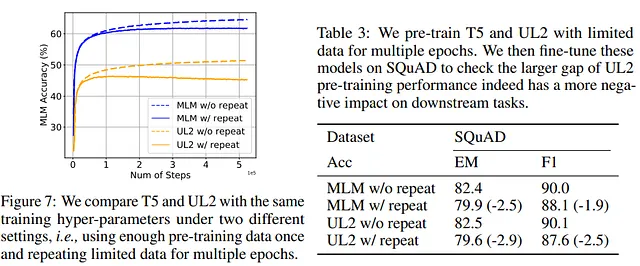
Gli autori hanno quindi esplorato come poter cercare di alleviare la degradazione multi-epoca. Dal momento che le tecniche di regolarizzazione sono utilizzate appositamente per prevenire l’overfitting, gli autori hanno testato se queste tecniche avessero anche un effetto benefico qui.
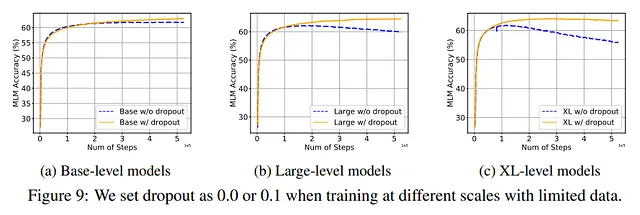
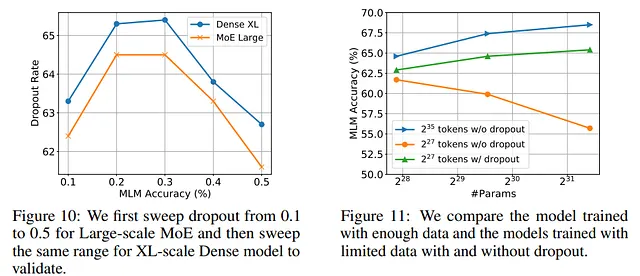
Dropout si è rivelata una delle tecniche più efficienti per alleviare il problema. Questo non è sorprendente perché è una delle tecniche di regolarizzazione più efficienti, è facilmente parallelizzabile ed è utilizzata dalla maggior parte dei modelli.

Inoltre, per gli autori funziona meglio iniziare senza dropout e solo in un secondo momento durante la formazione aggiungere dropout.

D’altra parte, gli autori notano che l’utilizzo di Dropout in alcuni modelli, specialmente quelli più grandi, può portare a una leggera riduzione delle prestazioni. Quindi, anche se può avere effetti benefici contro l’overfitting, potrebbe portare a comportamenti imprevisti in altri contesti. Tanto che i modelli GPT-3, PaLM, LLaMA, Chinchilla e Gopher non lo utilizzano nella loro architettura.
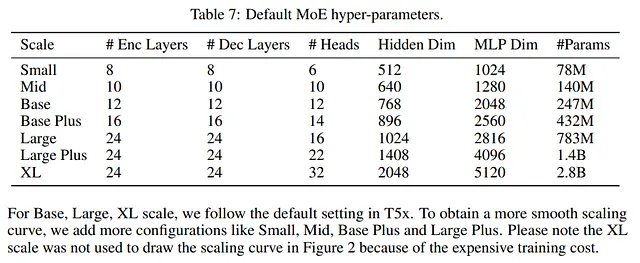
Come descritto nella tabella sottostante, gli autori hanno utilizzato per i loro esperimenti ciò che ora sono considerati modelli quasi piccoli. Pertanto, è costoso testare diversi iperparametri durante la progettazione di un LLM:
Ad esempio, nel nostro scenario specifico, la formazione di T5-XL cinque volte richiederebbe circa 37.000 USD per l’affitto di Google Cloud TPUs. Considerando modelli ancora più grandi come PaLM e GPT-4, addestrati su set di dati ancora più grandi, questo costo diventa ingestibile ( fonte )
Dal momento che nei loro esperimenti un modello Sparse MoE approssima il comportamento di un modello denso (che è più costoso dal punto di vista computazionale), si può utilizzarlo per cercare i migliori iperparametri.
Ad esempio, gli autori mostrano che è possibile testare diverse velocità di apprendimento per il modello MoE e che presenta le stesse prestazioni del modello denso equivalente. Quindi, per gli autori, è possibile testare diversi iperparametri con il modello MoE e quindi addestrare con i parametri scelti il modello denso, risparmiando così costi:
La scansione del modello MoE Large ha comportato una spesa di circa 10,6K USD sulla piattaforma Google Cloud. Al contrario, la formazione del modello Dense XL solo una volta ha richiesto 7,4K USD. Di conseguenza, l’intero processo di sviluppo, compresa la scansione, ha comportato un costo totale di 18K USD, ovvero solo lo 0,48% della spesa di sintonizzare direttamente il modello Dense XL ( fonte )
Pensieri finali
Negli ultimi anni c’è stata una corsa per avere il modello più grande. Da un lato, questa corsa è stata motivata dal fatto che ad una certa scala emergono proprietà che erano impossibili da prevedere con modelli più piccoli. D’altra parte, la legge di scaling di OpenAI affermava che le prestazioni sono una funzione del numero di parametri del modello.
Nell’ultimo anno questo paradigma è entrato in crisi.
Recentemente LlaMA ha mostrato l’importanza della qualità dei dati. Inoltre, Chinchilla ha mostrato una nuova regola per calcolare il numero di token necessari per addestrare un modello in modo ottimale. Infatti, un modello di un certo numero di parametri richiede un numero di dati per funzionare in modo ottimale.
Studi successivi hanno dimostrato che il numero di token di qualità non è infinito. D’altra parte, il numero di parametri del modello cresce più di quanti token noi umani possiamo generare.
Ciò ha portato alla domanda su come possiamo risolvere la crisi dei token. Studi recenti mostrano che l’utilizzo di LLM per generare token non è un modo valido. Questo nuovo lavoro mostra come l’utilizzo degli stessi token per molte epoche possa effettivamente deteriorare le prestazioni.
Lavori come questo sono importanti perché, anche se stiamo addestrando e utilizzando LLM sempre di più, ci sono molti aspetti anche basilari che non conosciamo. Questo lavoro risponde a una domanda che sembra basilare ma alla quale gli autori rispondono con dati sperimentali: cosa succede quando si addestra un LLM per molte epoche?
Inoltre, questo articolo fa parte di una fetta crescente di letteratura che mostra come un aumento acritico del numero di parametri non sia necessario. D’altra parte, modelli sempre più grandi sono sempre più costosi e consumano sempre più energia. Considerando che dobbiamo ottimizzare le risorse, questo articolo suggerisce che addestrare un enorme modello senza abbastanza dati sia solo uno spreco.
Questo articolo mostra ancora come abbiamo bisogno di nuove architetture che possano sostituire il transformer. È quindi il momento di concentrare la ricerca su nuove idee invece di continuare a scalare i modelli.
Se hai trovato questo interessante:
Puoi cercare i miei altri articoli, puoi anche iscriverti per ricevere una notifica quando pubblico degli articoli, puoi diventare un membro di Nisoo per accedere a tutte le sue storie (link affiliato della piattaforma per la quale ottengo piccole entrate senza costo per te) e puoi anche connetterti o contattarmi su LinkedIn.
Ecco il link al mio repository GitHub, dove sto pianificando di raccogliere codice e molte risorse relative all’apprendimento automatico, all’intelligenza artificiale e altro ancora.
GitHub – SalvatoreRa/tutorial: Tutorials on machine learning, artificial intelligence, data science…
Tutorials on machine learning, artificial intelligence, data science con spiegazioni matematiche e codice riutilizzabile (in python…
github.com
o potresti essere interessato a uno dei miei articoli recenti:
Scaling Isn’t Everything: How Bigger Models Fail Harder
Are Large Language Models really understanding programming languages?
salvatore-raieli.medium.com
META’S LIMA: Maria Kondo’s way for LLMs training
Less and tidy data to create a model capable to rival ChatGPT
levelup.gitconnected.com
Google Med-PaLM 2: is AI ready for medical residency?
Il nuovo modello di Google ottiene risultati impressionanti nel dominio medico
levelup.gitconnected.com
To AI or not to AI: come sopravvivere?
Con l’IA generativa che minaccia le attività e i lavori secondari, come puoi trovare spazio?
levelup.gitconnected.com
Riferimenti
Un elenco dei principali riferimenti consultati per questo articolo:
- Fuzhao Xue et al, 2023, To Repeat or Not To Repeat: Insights from Scaling LLM under Token-Crisis, link
- Hugo Touvron et all. 2023, LLaMA: Open and Efficient Foundation Language Models. link
- Arnav Gudibande et all, 2023, The False Promise of Imitating Proprietary LLMs. link
- PaLM 2, google blog, link
- Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance. Google Blog, link
- Buck Shlegeris et all, 2022, Language models are better than humans at next-token prediction, link
- Pablo Villalobos et. all, 2022, Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning. link
- Susan Zhang et al. 2022, OPT: Open Pre-trained Transformer Language Models. link
- Jordan Hoffmann et all, 2022, An empirical analysis of compute-optimal large language model training. link
- Ross Taylor et al, 2022, Galactica: A Large Language Model for Science, link
- Zixiang Chen et al, 2022, Towards Understanding Mixture of Experts in Deep Learning, link
- Jared Kaplan et all, 2020, Scaling Laws for Neural Language Models. link
- Come l’AI potrebbe alimentare il riscaldamento globale, TDS, link
- Masked language modeling, HuggingFace blog, link
- Mixture-of-Experts with Expert Choice Routing, Google Blog, link
- Why Meta’s latest large language model survived only three days online, MIT review, link
- Exploring Transfer Learning with T5: the Text-To-Text Transfer Transformer, Google Blog, link
- Scaling laws for reward model overoptimization, OpenAI blog, link
- An empirical analysis of compute-optimal large language model training, DeepMind blog, link
- Xiaonan Nie et al, 2022, EvoMoE: An Evolutional Mixture-of-Experts Training Framework via Dense-To-Sparse Gate. link
- Tianyu Chen et al, 2022, Task-Specific Expert Pruning for Sparse Mixture-of-Experts, link
- Bo Li et al, 2022, Sparse Mixture-of-Experts are Domain Generalizable Learners, link